Accelerated Schr\"odinger-F\"ollmer samplers
Pith reviewed 2026-07-01 16:20 UTC · model grok-4.3
The pith
A stochastic Runge-Kutta scheme for the Schrödinger-Föllmer sampler reaches O(h^{3/2} |ln h|) convergence in L2-Wasserstein distance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
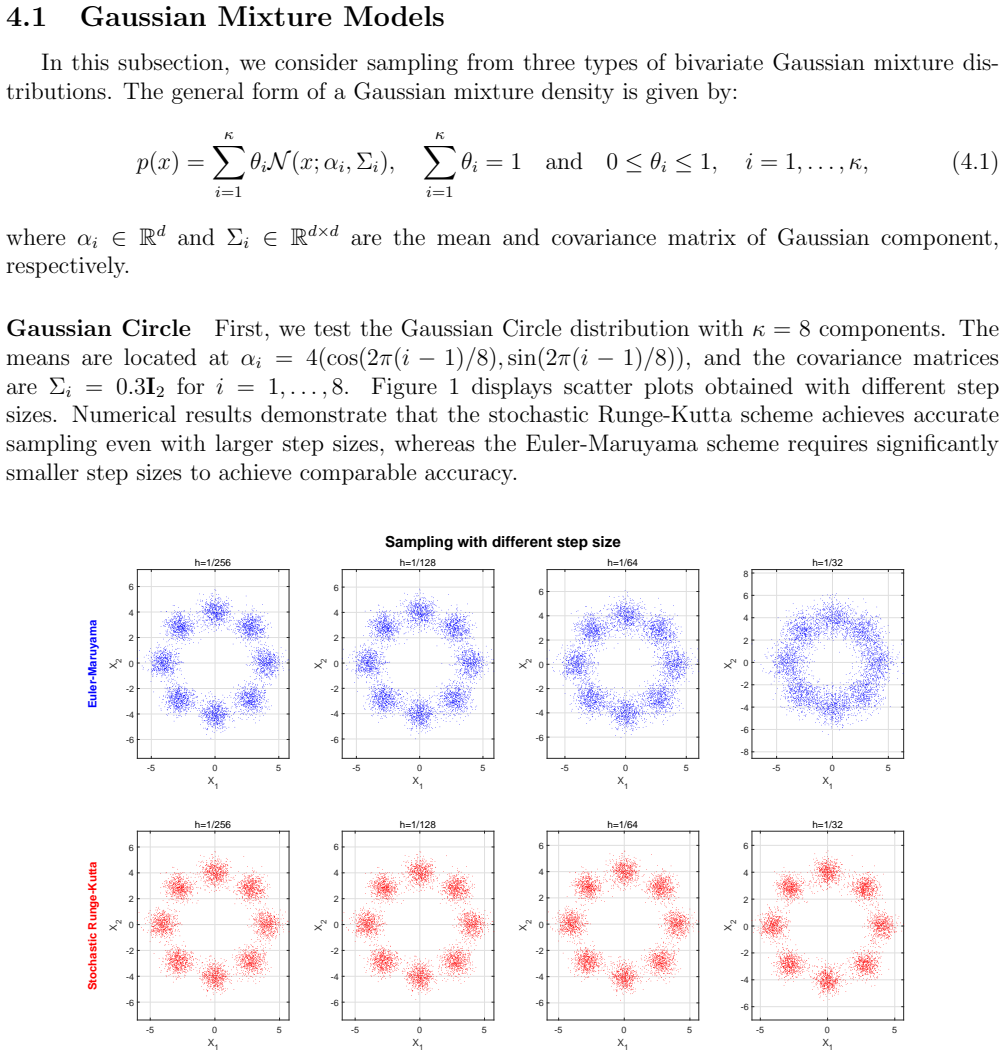
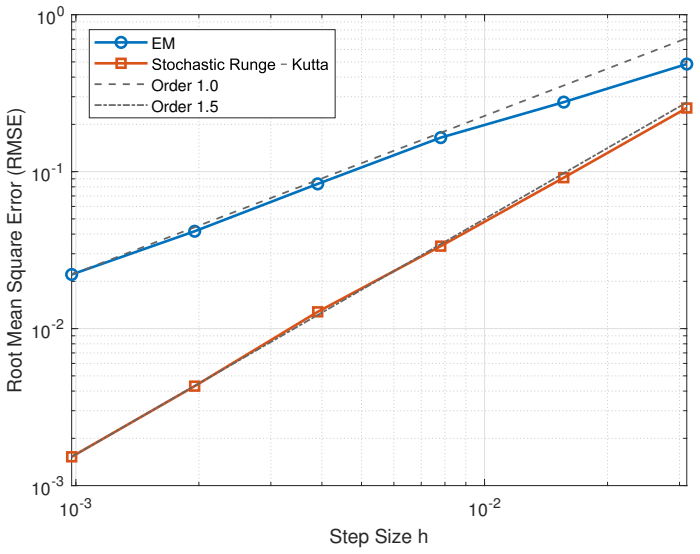
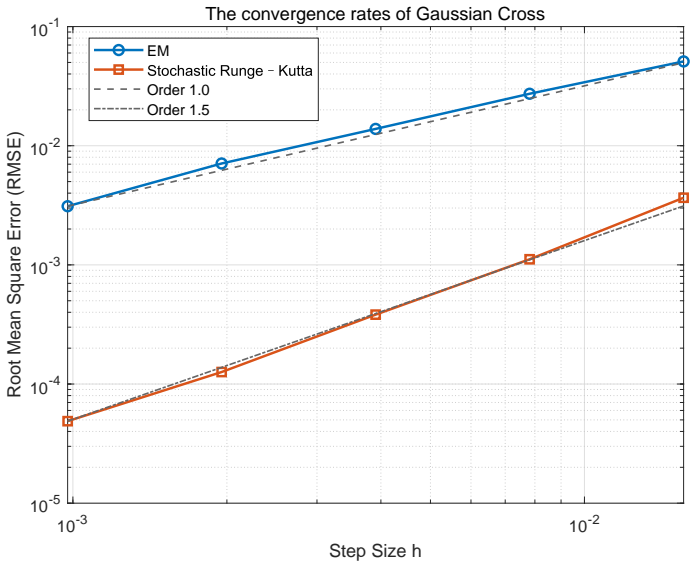
The stochastic Runge-Kutta Schrödinger-Föllmer sampler (SRKSFS) is proved to converge at rate O(h^{3/2} |ln h|) in the L2-Wasserstein distance. This rate holds for a diffusion whose drift is merely 1/2-Hölder continuous in time; the proof relies on delicate error estimates that control the singularities arising from time derivatives of the drift at the cost of the extra logarithmic factor. The construction is further extended to the case in which the target distribution is available only through samples rather than an explicit density.
What carries the argument
Stochastic Runge-Kutta discretization of the Schrödinger-Föllmer diffusion, paired with tailored error estimates that accommodate the 1/2-Hölder time regularity of the drift.
If this is right
- Fewer discretization steps are needed to reach a given accuracy level compared with Euler-based samplers.
- The method applies directly to high-dimensional multimodal targets without requiring differentiability of the drift in time.
- Data-driven sampling becomes feasible when only samples from the target are available.
- The same acceleration technique can be applied to other diffusion-based samplers that share similar regularity limitations.
Where Pith is reading between the lines
- The approach may lower the computational budget required for posterior sampling in Bayesian models with expensive likelihoods.
- Further rate improvements could be obtained by smoothing the drift or by using higher-order Runge-Kutta variants once additional regularity is available.
- The log factor suggests a natural next target: identifying conditions under which the logarithmic penalty can be removed entirely.
- Implementation in existing stochastic differential equation solvers would allow direct benchmarking against other accelerated samplers.
Load-bearing premise
The drift of the underlying diffusion is only 1/2-Hölder continuous in time and therefore not differentiable.
What would settle it
Numerical computation of the L2-Wasserstein distance between the law of the SRKSFS output and the target measure for a sequence of decreasing step sizes h, verifying whether the observed scaling follows O(h^{3/2} |ln h|) or falls back to a lower order.
Figures


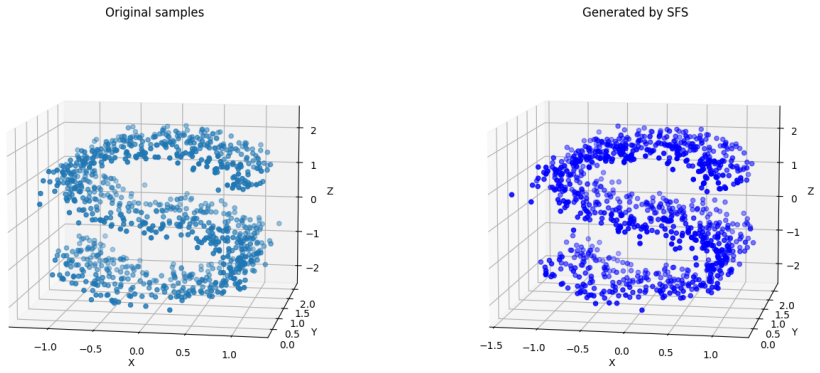


read the original abstract
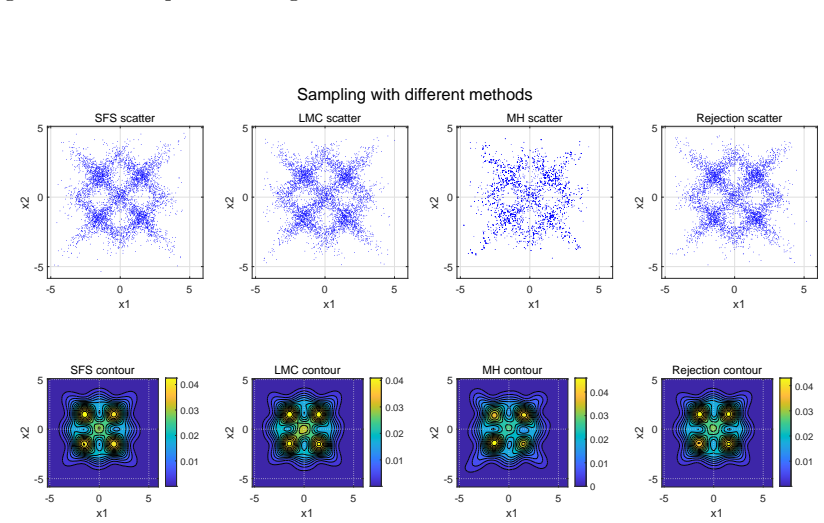
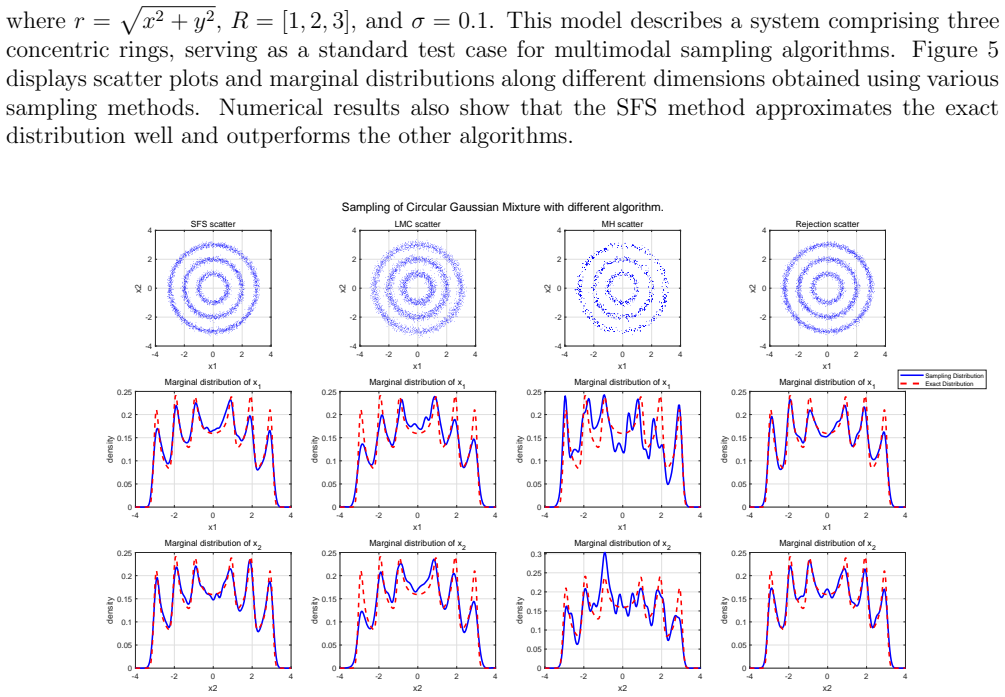
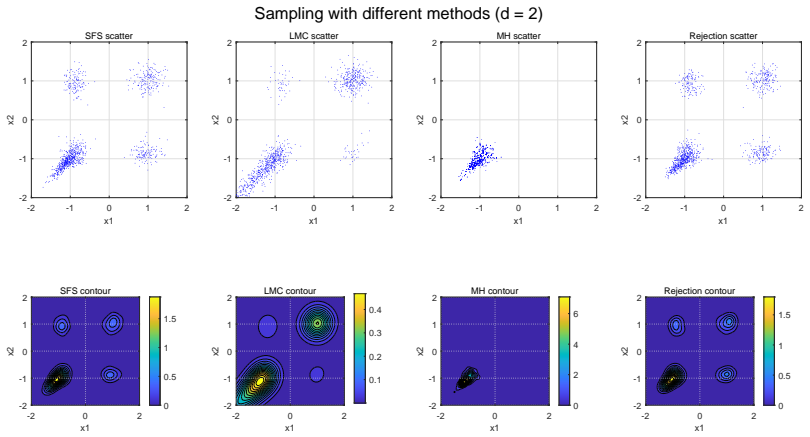
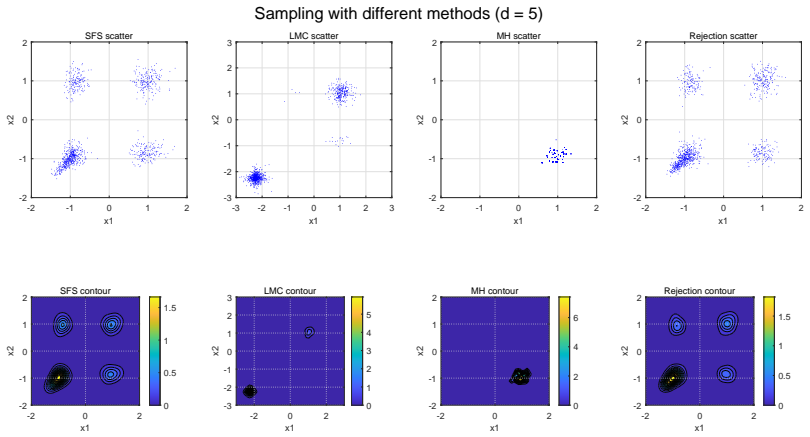
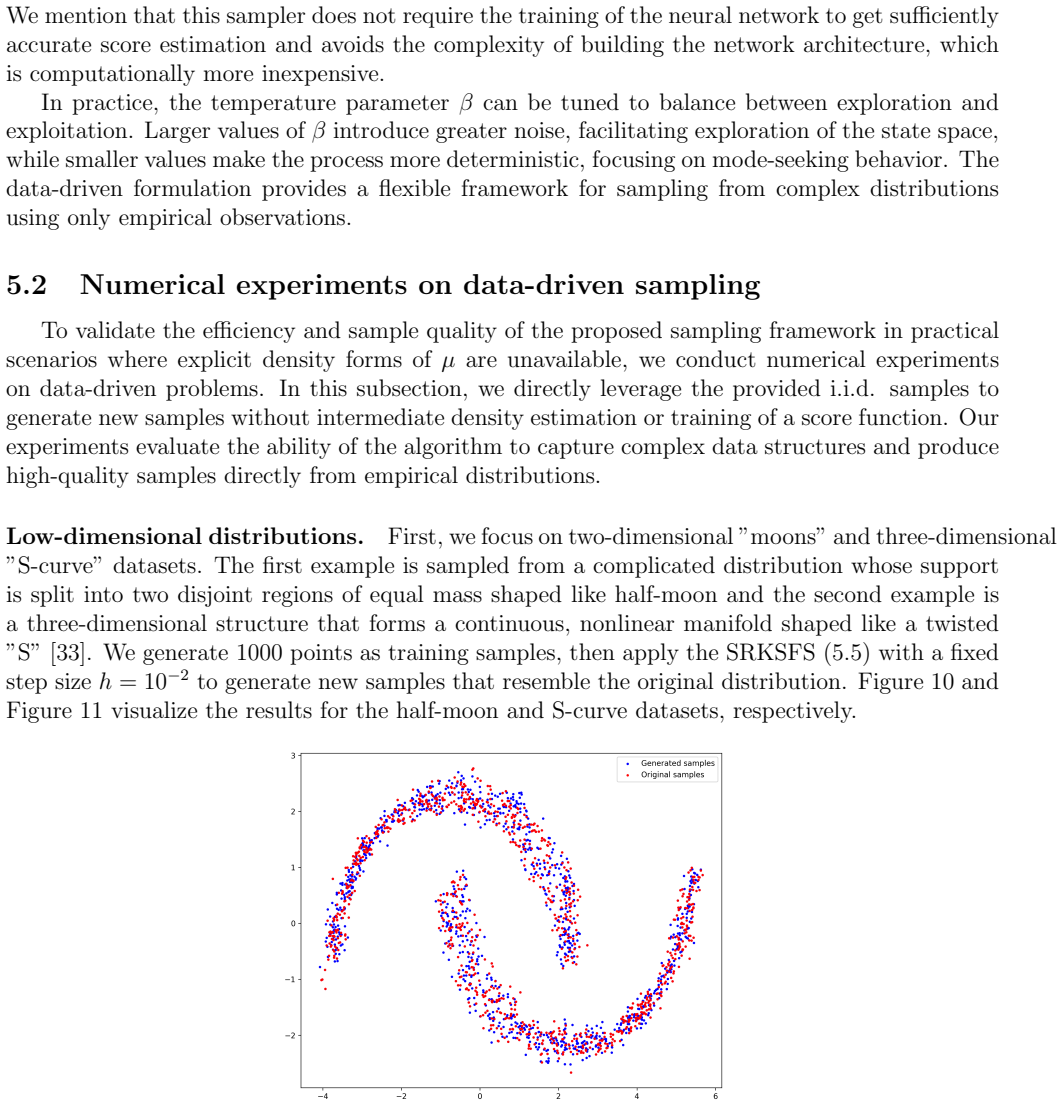
Sampling is a fundamental algorithmic task in wide-ranging applications across multiple disciplines such as scientific computing, statistics and machine learning. In this paper, an efficient stochastic Runge-Kutta scheme is proposed to accelerate the Schr\"odinger-F\"ollmer sampler, designed for sampling from complex and high-dimensional multimodal distributions. The resulting stochastic Runge-Kutta Schr\"odinger-F\"ollmer sampler (SRKSFS) is proved to achieve a convergence rate of order $\mathcal{O} ( h^{3/2} |\ln h|)$ in the $L^2$-Wasserstein distance, considerably improving the order $\mathcal{O}(h)$ of the existing Euler type sampler. Obtaining the enhanced convergence rate is, however, not trivial, by noting that the drift of the diffusion process is not differentiable but only $\frac{1}{2}$-H\"older continuity with respect to the time variable. To address the difficulty, we rely on delicate error estimates to overcome the singularity due to time derivatives of the drift, at the expense of the logarithmic factor. Furthermore, the framework is extended to data-driven Schr\"odinger-F\"ollmer generation with empirical measures, enabling data-driven sampling without known density. A variety of numerical experiments are reported to validate the effectiveness of the proposed sampling algorithms.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a stochastic Runge-Kutta discretization (SRKSFS) of the Schrödinger-Föllmer diffusion to sample from complex multimodal distributions. It asserts a proof that this scheme attains an L²-Wasserstein convergence rate of O(h^{3/2} |ln h|), improving on the O(h) rate of the Euler-Maruyama sampler, despite the drift being merely 1/2-Hölder continuous in time. The framework is extended to data-driven sampling via empirical measures, and numerical experiments are provided to illustrate performance.
Significance. If the error estimates are correct, the result would constitute a concrete advance in high-order numerical methods for sampling, showing that Runge-Kutta schemes can recover an extra half-order (modulo log) even when the time regularity of the drift precludes standard Itô-Taylor expansions. The data-driven extension and the explicit handling of the time singularity are of interest to computational statistics and stochastic analysis.
major comments (1)
- [convergence analysis (Theorem establishing the SRKSFS rate)] The central convergence claim (abstract and the theorem establishing the O(h^{3/2}|ln h|) rate) rests entirely on bespoke error estimates that absorb the singularities arising from time derivatives of the 1/2-Hölder drift. The manuscript must supply the complete derivation of these estimates, including the precise application of the Burkholder-Davis-Gundy inequality to the stochastic integrals and the control of the Itô-Taylor remainder terms, so that it can be verified that no additional factors depending on the Hölder constant or on the time mesh enter the final bound.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The single major comment concerns the completeness of the convergence proof. We address it directly below and will incorporate the requested details in the revision.
read point-by-point responses
-
Referee: The central convergence claim (abstract and the theorem establishing the O(h^{3/2}|ln h|) rate) rests entirely on bespoke error estimates that absorb the singularities arising from time derivatives of the 1/2-Hölder drift. The manuscript must supply the complete derivation of these estimates, including the precise application of the Burkholder-Davis-Gundy inequality to the stochastic integrals and the control of the Itô-Taylor remainder terms, so that it can be verified that no additional factors depending on the Hölder constant or on the time mesh enter the final bound.
Authors: We agree that the full derivation must be supplied for independent verification. The current manuscript contains the main steps of the error analysis but omits some intermediate calculations involving the Burkholder-Davis-Gundy inequality and the precise bounding of the Itô-Taylor remainders under the 1/2-Hölder time regularity. In the revised version we will add a self-contained appendix that spells out these steps in full, confirming that the final O(h^{3/2}|ln h|) bound does not introduce extraneous factors depending on the Hölder constant or the mesh beyond the logarithmic term already stated. revision: yes
Circularity Check
No circularity: convergence proof rests on independent error estimates
full rationale
The paper derives the O(h^{3/2}|ln h|) L^2-Wasserstein rate for the stochastic Runge-Kutta Schrödinger-Föllmer sampler via bespoke error estimates that explicitly handle the 1/2-Hölder time singularity in the drift. No step reduces a claimed result to a fitted parameter, self-definition, or load-bearing self-citation; the analysis is presented as a direct (if delicate) application of stochastic analysis tools such as Burkholder-Davis-Gundy and Itô-Taylor expansions. The derivation chain is therefore self-contained against external mathematical benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Stochastic interpolants: A uni- fying framework for flows and diffusions.Journal of Machine Learning Research, 26(209):1–80, 2025
Michael Albergo, Nicholas M Boffi, and Eric Vanden-Eijnden. Stochastic interpolants: A uni- fying framework for flows and diffusions.Journal of Machine Learning Research, 26(209):1–80, 2025. 34 Figure 12: Samples and data from MNIST. Figure 13: Samples and data from CIFAR-10. 35
2025
-
[2]
Building Normalizing Flows with Stochastic In- terpolants
Michael Albergo and Eric Vanden-Eijnden. Building Normalizing Flows with Stochastic In- terpolants. InThe International Conference on Learning Representations, 2023
2023
-
[3]
Jason M Altschuler and Sinho Chewi. Shifted composition iii: Local error framework for kl divergence.arXiv preprint arXiv:2412.17997, 2024
-
[4]
Sam Bond-Taylor, Adam Leach, Yang Long, and Chris G Willcocks. Deep generative mod- elling: A comparative review of vaes, gans, normalizing flows, energy-based and autoregressive models.IEEE transactions on pattern analysis and machine intelligence, 44(11):7327–7347, 2021
2021
-
[5]
Your gan is secretly an energy-based model and you should use discrimi- nator driven latent sampling.Advances in Neural Information Processing Systems, 33:12275– 12287, 2020
Tong Che, Ruixiang Zhang, Jascha Sohl-Dickstein, Hugo Larochelle, Liam Paull, Yuan Cao, and Yoshua Bengio. Your gan is secretly an energy-based model and you should use discrimi- nator driven latent sampling.Advances in Neural Information Processing Systems, 33:12275– 12287, 2020
2020
- [6]
-
[7]
Global optimization via Schr¨ odinger-F¨ ollmer diffusion.SIAM J
Yin Dai, Yuling Jiao, Lican Kang, Xiliang Lu, and Jerry Zhijian Yang. Global optimization via Schr¨ odinger-F¨ ollmer diffusion.SIAM J. Control Optim., 61(5):2953–2980, 2023
2023
-
[8]
Arnak S Dalalyan. Theoretical guarantees for approximate sampling from smooth and log- concave densities.Journal of the Royal Statistical Society Series B: Statistical Methodology, 79(3):651–676, 2017
2017
-
[9]
The mnist database of handwritten digit images for machine learning research [best of the web].IEEE signal processing magazine, 29(6):141–142, 2012
Li Deng. The mnist database of handwritten digit images for machine learning research [best of the web].IEEE signal processing magazine, 29(6):141–142, 2012
2012
-
[10]
Nonasymptotic convergence analysis for the unadjusted Langevin algorithm.The Annals of Applied Probability, 27(3):1551, 2017
Alain Durmus and Eric Moulines. Nonasymptotic convergence analysis for the unadjusted Langevin algorithm.The Annals of Applied Probability, 27(3):1551, 2017
2017
-
[11]
High-dimensional Bayesian inference via the Unadjusted Langevin Algorithm.Bernoulli, 25(4A), 2019
Alain Durmus and ´Eric Moulines. High-dimensional Bayesian inference via the Unadjusted Langevin Algorithm.Bernoulli, 25(4A), 2019
2019
-
[12]
Reflection couplings and contraction rates for diffusions.Probability theory and related fields, 166(3):851–886, 2016
Andreas Eberle. Reflection couplings and contraction rates for diffusions.Probability theory and related fields, 166(3):851–886, 2016
2016
-
[13]
An entropy approach to the time reversal of diffusion processes
Hans F¨ ollmer. An entropy approach to the time reversal of diffusion processes. InStochas- tic Differential Systems Filtering and Control: Proceedings of the IFIP-WG 7/1 Working Conference Marseille-Luminy, France, March 12–17, 1984, pages 156–163. Springer, 2005
1984
-
[14]
Random fields and diffusion processes
Hans F¨ ollmer. Random fields and diffusion processes. In ´Ecole d’ ´Et´ e de Probabilit´ es de Saint-Flour XV–XVII, 1985–87, pages 101–203. Springer, 2006
1985
-
[15]
OUP Oxford, 2002
Paul H Garthwaite, Ian T Jolliffe, and Byron Jones.Statistical inference. OUP Oxford, 2002
2002
-
[16]
Chapman and Hall/CRC, 1995
Andrew Gelman, John B Carlin, Hal S Stern, and Donald B Rubin.Bayesian data analysis. Chapman and Hall/CRC, 1995. 36
1995
-
[17]
Number 25
Jack K Hale.Asymptotic behavior of dissipative systems. Number 25. American Mathematical Soc., 2010
2010
-
[18]
One-step data-driven generative model via schr¨ odinger bridge.arXiv preprint arXiv:2405.12453, 2024
Hanwen Huang. One-step data-driven generative model via schr¨ odinger bridge.arXiv preprint arXiv:2405.12453, 2024
-
[19]
Schr¨ odinger-F¨ ollmer sampler.IEEE Trans
Jian Huang, Yuling Jiao, Lican Kang, Xu Liao, Jin Liu, and Yanyan Liu. Schr¨ odinger-F¨ ollmer sampler.IEEE Trans. Inform. Theory, 71(2):1283–1299, 2025
2025
-
[20]
Multimodal conditional image synthesis with product-of-experts gans
Xun Huang, Arun Mallya, Ting-Chun Wang, and Ming-Yu Liu. Multimodal conditional image synthesis with product-of-experts gans. InEuropean conference on computer vision, pages 91–109. Springer, 2022
2022
-
[21]
World Scientific Publishing Company, 2012
Fima C Klebaner.Introduction to stochastic calculus with applications. World Scientific Publishing Company, 2012
2012
-
[22]
Kloeden and Eckhard Platen.Numerical Solution of Stochastic Differential Equa- tions
Peter E. Kloeden and Eckhard Platen.Numerical Solution of Stochastic Differential Equa- tions. Springer, Berlin, Heidelberg, 1992
1992
-
[23]
Learning multiple layers of features from tiny images
Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images. 2009
2009
-
[24]
A sharp uniform-in-time error estimate for Stochastic Gradient Langevin Dynamics.CSIAM Transactions on Applied Mathematics, 6(4):711–759, 2025
Lei Li and Yuliang Wang. A sharp uniform-in-time error estimate for Stochastic Gradient Langevin Dynamics.CSIAM Transactions on Applied Mathematics, 6(4):711–759, 2025
2025
-
[25]
Sqrt (d) dimension dependence of Langevin monte carlo.The International Conference on Learning Representations, 2022
Ruilin Li, Hongyuan Zha, and Molei Tao. Sqrt (d) dimension dependence of Langevin monte carlo.The International Conference on Learning Representations, 2022
2022
-
[26]
Stochastic runge-kutta accelerates langevin monte carlo and beyond.Advances in neural information processing systems, 32, 2019
Xuechen Li, Yi Wu, Lester Mackey, and Murat A Erdogdu. Stochastic runge-kutta accelerates langevin monte carlo and beyond.Advances in neural information processing systems, 32, 2019
2019
-
[27]
Elsevier, 2007
Xuerong Mao.Stochastic differential equations and applications. Elsevier, 2007
2007
-
[28]
Springer, 2004
Grigori N Milstein and Michael V Tretyakov.Stochastic numerics for mathematical physics, volume 39. Springer, 2004
2004
-
[29]
Im- proved bounds for discretization of Langevin diffusions: Near-optimal rates without convexity
Wenlong Mou, Nicolas Flammarion, Martin J Wainwright, and Peter L Bartlett. Im- proved bounds for discretization of Langevin diffusions: Near-optimal rates without convexity. Bernoulli, 28(3):1577–1601, 2022
2022
-
[30]
Springer, 2006
Roger B Nelsen.An introduction to copulas. Springer, 2006
2006
-
[31]
Learning latent space energy-based prior model.Advances in Neural Information Processing Systems, 33:21994– 22008, 2020
Bo Pang, Tian Han, Erik Nijkamp, Song-Chun Zhu, and Ying Nian Wu. Learning latent space energy-based prior model.Advances in Neural Information Processing Systems, 33:21994– 22008, 2020
2020
-
[32]
Projected Langevin Monte Carlo algorithms in non-convex and super-linear setting.Journal of Computational Physics, 526:113754, 2025
Chenxu Pang, Xiaojie Wang, and Yue Wu. Projected Langevin Monte Carlo algorithms in non-convex and super-linear setting.Journal of Computational Physics, 526:113754, 2025. 37
2025
-
[33]
Scikit-learn: Machine learning in python.The Journal of Machine Learning Research, 12:2825–2830, 2011
Fabian Pedregosa, Ga¨ el Varoquaux, Alexandre Gramfort, Vincent Michel, Bertrand Thirion, Olivier Grisel, Mathieu Blondel, Peter Prettenhofer, Ron Weiss, Vincent Dubourg, et al. Scikit-learn: Machine learning in python.The Journal of Machine Learning Research, 12:2825–2830, 2011
2011
-
[34]
Efficient multimodal sampling via tempered distribution flow
Yixuan Qiu and Xiao Wang. Efficient multimodal sampling via tempered distribution flow. Journal of the American Statistical Association, 119(546):1446–1460, 2024
2024
-
[35]
Unbiased estimation using a class of diffusion processes.Journal of Computational Physics, 472:111643, 2023
Hamza Ruzayqat, Alexandros Beskos, Dan Crisan, Ajay Jasra, and Nikolas Kantas. Unbiased estimation using a class of diffusion processes.Journal of Computational Physics, 472:111643, 2023
2023
-
[36]
Learning deep generative models.Annual Review of Statistics and Its Application, 2(1):361–385, 2015
Ruslan Salakhutdinov. Learning deep generative models.Annual Review of Statistics and Its Application, 2(1):361–385, 2015
2015
-
[37]
Sur la th´ eorie relativiste de l’´ electron et l’interpr´ etation de la m´ ecanique quantique
Erwin Schr¨ odinger. Sur la th´ eorie relativiste de l’´ electron et l’interpr´ etation de la m´ ecanique quantique. InAnnales de l’institut Henri Poincar´ e, volume 2, pages 269–310, 1932
1932
-
[38]
Katharina Schuh and Peter A Whalley. Convergence of kinetic Langevin samplers for non- convex potentials.arXiv preprint arXiv:2405.09992, 2024
-
[39]
Springer, 2015
Timothy John Sullivan.Introduction to uncertainty quantification, volume 63. Springer, 2015
2015
-
[40]
Multimodal sampling via Schr¨ odinger-F¨ ollmer samplers with temperatures.Journal of Complexity, 96:102052, 2026
Xiaojie Wang and Xiaoyan Zhang. Multimodal sampling via Schr¨ odinger-F¨ ollmer samplers with temperatures.Journal of Complexity, 96:102052, 2026
2026
-
[41]
Fashion-MNIST: a Novel Image Dataset for Benchmarking Machine Learning Algorithms
Han Xiao, Kashif Rasul, and Roland Vollgraf. Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms.arXiv preprint arXiv:1708.07747, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[42]
Bin Yang and Xiaojie Wang. Non-asymptotic Error Bounds inW 2-Distance with Sqrt(d) Dimension Dependence and First Order Convergence for Langevin Monte Carlo beyond Log- Concavity.International Conference on Machine Learning, 2025
2025
-
[43]
Accelerating Langevin Monte Carlo via Efficient Stochastic Runge--Kutta Methods beyond Log-Concavity
Bin Yang and Xiaojie Wang. Accelerating Langevin Monte Carlo via Efficient Stochastic Runge–Kutta Methods beyond Log-Concavity.arXiv preprint arXiv:2605.07939, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[44]
Diffusion models: A comprehensive survey of methods and applications.ACM computing surveys, 56(4):1–39, 2023
Ling Yang, Zhilong Zhang, Yang Song, Shenda Hong, Runsheng Xu, Yue Zhao, Wentao Zhang, Bin Cui, and Ming-Hsuan Yang. Diffusion models: A comprehensive survey of methods and applications.ACM computing surveys, 56(4):1–39, 2023
2023
-
[45]
Deep generative molecular design reshapes drug discovery.Cell Reports Medicine, 3(12), 2022
Xiangxiang Zeng, Fei Wang, Yuan Luo, Seung-gu Kang, Jian Tang, Felice C Lightstone, Evandro F Fang, Wendy Cornell, Ruth Nussinov, and Feixiong Cheng. Deep generative molecular design reshapes drug discovery.Cell Reports Medicine, 3(12), 2022. 38 A Proof of Proposition 3.2 Proof.By assumptions, the functiong β is of classC 4, and moreover,g β,∇g β,∇ 2gβ,∇ ...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.