Can VLA Models Learn from Real-World Data Continually without Forgetting?
Pith reviewed 2026-06-29 16:46 UTC · model grok-4.3
The pith
Vision-language-action models suffer significant catastrophic forgetting when continually trained on heterogeneous real-world robot demonstrations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
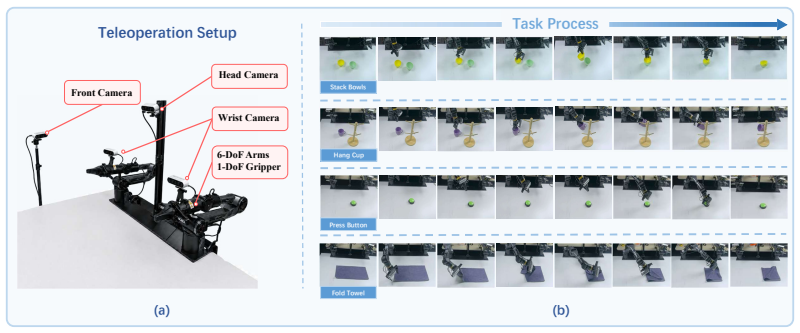
Using a new real-world dataset spanning rigid-object pick-and-place, contact-rich pressing, and deformable-object folding, the study shows that VLA models suffer significant catastrophic forgetting when continually learning from heterogeneous demonstrations; experience replay mitigates this only when specific implementation factors are addressed correctly.
What carries the argument
The real-world continual learning dataset of four sequential manipulation tasks, used as the testbed to quantify forgetting in VLA models and to assess experience replay.
Load-bearing premise
The four sequential manipulation tasks and the collected demonstrations are representative of the challenges that arise in broader real-world continual deployment of VLA models.
What would settle it
An experiment in which a VLA model trained sequentially on the four tasks shows no measurable performance decline on the first task after completing the later tasks would falsify the claim of significant forgetting.
Figures



read the original abstract
Vision-language-action (VLA) models provide a promising foundation for general-purpose robotics. However, their successful deployment in real-world scenarios requires the ability to continually acquire new skills while retaining previously learned behaviors. While pioneering research has studied the continual learning of VLA models in narrowly simulated environments, this challenge remains largely unexplored under realistic conditions. To address this limitation, we construct a real-world continual learning dataset comprising four sequential manipulation tasks, spanning rigid-object pick-and-place, contact-rich pressing, and deformable-object folding. Using this dataset, we conduct comprehensive experiments and find that VLA models suffer significant catastrophic forgetting when continually learning from heterogeneous real-world demonstrations. We then systematically evaluate experience replay and uncover key implementation factors that govern its success. In summary, this work provides the first empirical study of real-world continual VLA learning and offers practical guidance for deploying long-lived robot policies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates continual learning for Vision-Language-Action (VLA) models in real-world settings. It introduces a dataset of four sequential manipulation tasks (rigid-object pick-and-place, contact-rich pressing, deformable-object folding) and reports that VLA models exhibit significant catastrophic forgetting when trained sequentially on heterogeneous real-world demonstrations. The work then evaluates experience replay, identifies key implementation factors for its effectiveness, and positions the study as the first empirical examination of real-world continual VLA learning with practical guidance for long-lived policies.
Significance. If the empirical findings hold under broader conditions, the paper would be significant for highlighting a key obstacle to long-term deployment of VLA models outside simulation and for supplying concrete replay-based mitigation insights. It addresses a clear gap between existing simulated continual-learning studies and realistic robotics data.
major comments (2)
- [Dataset construction and experimental setup] The headline claim of significant catastrophic forgetting on heterogeneous real-world data rests on a benchmark of exactly four tasks. The manuscript should explicitly justify why this sequence adequately proxies the heterogeneity, long-horizon dependencies, sensor noise accumulation, and task-interference patterns expected in open-ended continual deployment; otherwise the measured forgetting may be an artifact of the narrow task set rather than a general property of VLA fine-tuning.
- [Results] The abstract asserts the forgetting result and replay findings yet supplies no quantitative metrics, controls, statistical details, or dataset size. The results section must include these (e.g., per-task success rates before/after sequential training, replay buffer sizes, statistical significance) for the central empirical claim to be evaluable.
minor comments (1)
- [Dataset] Clarify the precise number of demonstrations collected per task and any balancing procedures used across the four tasks.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our study of continual learning for VLA models in real-world settings. We address each major comment below.
read point-by-point responses
-
Referee: [Dataset construction and experimental setup] The headline claim of significant catastrophic forgetting on heterogeneous real-world data rests on a benchmark of exactly four tasks. The manuscript should explicitly justify why this sequence adequately proxies the heterogeneity, long-horizon dependencies, sensor noise accumulation, and task-interference patterns expected in open-ended continual deployment; otherwise the measured forgetting may be an artifact of the narrow task set rather than a general property of VLA fine-tuning.
Authors: We agree that four tasks constitute a limited benchmark and cannot fully represent all aspects of open-ended deployment. The sequence was deliberately constructed to span distinct heterogeneity dimensions (rigid vs. deformable objects; pick-and-place vs. contact-rich pressing vs. folding) that induce measurable task interference. In revision we will insert an explicit justification paragraph in the dataset section, framing the benchmark as a minimal yet representative real-world proxy while noting its scope limitations and the value of future larger-scale studies. revision: yes
-
Referee: [Results] The abstract asserts the forgetting result and replay findings yet supplies no quantitative metrics, controls, statistical details, or dataset size. The results section must include these (e.g., per-task success rates before/after sequential training, replay buffer sizes, statistical significance) for the central empirical claim to be evaluable.
Authors: Abstracts are intentionally concise and omit detailed metrics by design. We acknowledge that the results section must supply all requested quantitative elements for evaluability. The manuscript already reports per-task success rates and replay buffer sizes; we will expand the section with explicit before/after tables, dataset sizes, additional controls, and statistical significance tests in the revised version. revision: yes
Circularity Check
No circularity: purely empirical study with no derivations or self-referential predictions
full rationale
The paper constructs a real-world dataset of four sequential manipulation tasks and reports experimental observations of catastrophic forgetting in VLA models along with evaluations of experience replay. No equations, fitted parameters presented as predictions, uniqueness theorems, or self-citation chains appear in the abstract or described methodology. All claims rest on direct empirical measurement rather than any derivation that reduces to its own inputs by construction, rendering the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
LargeMonitor: Monitoring Online Task-Free Continual Learning via Large Pretrained Models
LargeMonitor introduces a decoupled framework using large pretrained models for robust drift detection and semantic diagnosis to improve online task-free continual learning.
Reference graph
Works this paper leans on
-
[1]
A Survey on Vision-Language-Action Models for Embodied AI
Yueen Ma, Zixing Song, Yuzheng Zhuang, Jianye Hao, and Irwin King. A survey on vision- language-action models for embodied ai.arXiv preprint arXiv:2405.14093, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Openvla: An open-source vision-language-action model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan P Foster, Pannag R Sanketi, Quan Vuong, et al. Openvla: An open-source vision-language-action model. InConference on Robot Learning, pages 2679–2713. PMLR, 2025
2025
-
[3]
Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Robert Equi, Chelsea Finn, Niccolo Fusai, Manuel Y . Galliker, Dibya Ghosh, Lachy Groom, Karol Hausman, brian ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Devin LeBlanc, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsch, Allen Z. Ren,...
2025
-
[4]
A continual learning survey: Defying forgetting in classification tasks.IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(7):3366–3385, 2021
Matthias De Lange, Rahaf Aljundi, Marc Masana, Sarah Parisot, Xu Jia, Aleš Leonardis, Gregory Slabaugh, and Tinne Tuytelaars. A continual learning survey: Defying forgetting in classification tasks.IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(7):3366–3385, 2021
2021
-
[5]
A comprehensive survey of continual learning: Theory, method and application.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(8):5362–5383, 2024
Liyuan Wang, Xingxing Zhang, Hang Su, and Jun Zhu. A comprehensive survey of continual learning: Theory, method and application.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(8):5362–5383, 2024
2024
-
[6]
Huihan Liu, Changyeon Kim, Bo Liu, Minghuan Liu, and Yuke Zhu. Pretrained vision- language-action models are surprisingly resistant to forgetting in continual learning.arXiv preprint arXiv:2603.03818, 2026
-
[7]
Jiaheng Hu, Jay Shim, Chen Tang, Yoonchang Sung, Bo Liu, Peter Stone, and Roberto Martin- Martin. Simple recipe works: Vision-language-action models are natural continual learners with reinforcement learning.arXiv preprint arXiv:2603.11653, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[8]
Ralf Römer, Yi Zhang, and Angela P Schoellig. Clare: Continual learning for vision-language- action models via autonomous adapter routing and expansion.arXiv preprint arXiv:2601.09512, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[9]
Towards Long-Lived Robots: Continual Learning VLA Models via Reinforcement Fine-Tuning
Yuan Liu, Haoran Li, Shuai Tian, Yuxing Qin, Yuhui Chen, Yupeng Zheng, Yongzhen Huang, and Dongbin Zhao. Towards long-lived robots: Continual learning vla models via reinforcement fine-tuning.arXiv preprint arXiv:2602.10503, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[10]
Libero: Benchmarking knowledge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36:44776–44791, 2023
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. Libero: Benchmarking knowledge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36:44776–44791, 2023
2023
-
[11]
Openvla: An open-source vision-language-action model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan P Foster, Pannag R Sanketi, Quan Vuong, et al. Openvla: An open-source vision-language-action model. In8th Annual Conference on Robot Learning, 2024
2024
-
[12]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al. π0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Robert Equi, Chelsea Finn, Niccolo Fusai, Manuel Y . Galliker, et al.π0.5: a vision- language-action model with open-world generalization.arXiv preprint arXiv:2504.16054, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Rdt-1b: a diffusion foundation model for bimanual manipulation
Songming Liu, Lingxuan Wu, Bangguo Li, Hengkai Tan, Huayu Chen, Zhengyi Wang, Ke Xu, Hang Su, and Jun Zhu. Rdt-1b: a diffusion foundation model for bimanual manipulation. In The Thirteenth International Conference on Learning Representations, 2024. 9
2024
-
[15]
X-VLA: Soft-Prompted Transformer as Scalable Cross-Embodiment Vision-Language-Action Model
Jiandong Zheng, Junfeng Li, Ziyang Wang, Dawei Liu, Xiang Kang, Yejin Feng, et al. X-vla: Soft-prompted transformer as scalable cross-embodiment vision-language-action model.arXiv preprint arXiv:2510.10274, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
WorldVLA: Towards Autoregressive Action World Model
Jun Cen, Chaohui Yu, Hangjie Yuan, Yuming Jiang, Siteng Huang, Jiayan Guo, Xin Li, Yibing Song, Hao Luo, Fan Wang, et al. Worldvla: Towards autoregressive action world model.arXiv preprint arXiv:2506.21539, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Wenxuan Song, Jiayi Chen, Xiaoquan Sun, Huashuo Lei, Yikai Qin, Wei Zhao, Pengxiang Ding, Han Zhao, Tongxin Wang, Pengxu Hou, Zhide Zhong, Haodong Yan, Donglin Wang, Jun Ma, and Haoang Li. Rethinking the practicality of vision-language-action model: A comprehensive benchmark and an improved baseline.arXiv preprint arXiv:2602.22663, 2026
-
[18]
Xiaoquan Sun, Zetian Xu, Chen Cao, Zonghe Liu, Yihan Sun, Jingrui Pang, Ruijian Zhang, Zhen Yang, Kang Pang, Dingxin He, et al. Atomvla: Scalable post-training for robotic manipulation via predictive latent world models.arXiv preprint arXiv:2603.08519, 2026
-
[19]
Continual learning of large language models: A comprehensive survey.ACM Computing Surveys, 58(5):1–42, 2025
Haizhou Shi, Zihao Xu, Hengyi Wang, Weiyi Qin, Wenyuan Wang, Yibin Wang, Zifeng Wang, Sayna Ebrahimi, and Hao Wang. Continual learning of large language models: A comprehensive survey.ACM Computing Surveys, 58(5):1–42, 2025
2025
-
[20]
Expe- rience replay for continual learning.Advances in neural information processing systems, 32, 2019
David Rolnick, Arun Ahuja, Jonathan Schwarz, Timothy Lillicrap, and Gregory Wayne. Expe- rience replay for continual learning.Advances in neural information processing systems, 32, 2019
2019
-
[21]
Loss of plasticity in deep continual learning.Nature, 632(8026):768–774, 2024
Shibhansh Dohare, J Fernando Hernandez-Garcia, Qingfeng Lan, Parash Rahman, A Rupam Mahmood, and Richard S Sutton. Loss of plasticity in deep continual learning.Nature, 632(8026):768–774, 2024
2024
-
[22]
Theory on forgetting and generalization of continual learning
Sen Lin, Peizhong Ju, Yingbin Liang, and Ness Shroff. Theory on forgetting and generalization of continual learning. InInternational Conference on Machine Learning, pages 21078–21100. PMLR, 2023
2023
-
[23]
icarl: Incremental classifier and representation learning
Sylvestre-Alvise Rebuffi, Alexander Kolesnikov, Georg Sperl, and Christoph H Lampert. icarl: Incremental classifier and representation learning. InProceedings of the IEEE conference on Computer Vision and Pattern Recognition, pages 2001–2010, 2017
2001
-
[24]
Gradient episodic memory for continual learning
David Lopez-Paz and Marc’Aurelio Ranzato. Gradient episodic memory for continual learning. Advances in neural information processing systems, 30, 2017
2017
-
[25]
Efficient lifelong learning with a-GEM
Arslan Chaudhry, Marc’Aurelio Ranzato, Marcus Rohrbach, and Mohamed Elhoseiny. Efficient lifelong learning with a-GEM. InInternational Conference on Learning Representations, 2019
2019
-
[26]
Online continual learning with maximal interfered retrieval
Rahaf Aljundi, Eugene Belilovsky, Tinne Tuytelaars, Laurent Charlin, Massimo Caccia, Min Lin, and Lucas Page-Caccia. Online continual learning with maximal interfered retrieval. Advances in neural information processing systems, 32, 2019
2019
-
[27]
Dark experience for general continual learning: a strong, simple baseline.Advances in neural information processing systems, 33:15920–15930, 2020
Pietro Buzzega, Matteo Boschini, Angelo Porrello, Davide Abati, and Simone Calderara. Dark experience for general continual learning: a strong, simple baseline.Advances in neural information processing systems, 33:15920–15930, 2020
2020
-
[28]
Partially observable markov decision processes
Matthijs TJ Spaan. Partially observable markov decision processes. InReinforcement learning: State-of-the-art, pages 387–414. Springer, 2012. 10 A Detailed Task Scoring Rubrics Unlike binary success/failure metrics commonly used in simulation benchmarks, we adopt a fine- grained multi-stage evaluation protocol for all tasks. This design serves two purpose...
2012
-
[29]
The gripper approaches the yellow bowl within 3 cm
-
[30]
The robot successfully grasps the yellow bowl
-
[31]
The robot moves the bowl above the green bowl
-
[32]
A penalty of−0.5is applied if the target bowl is knocked over during execution
The robot successfully places the yellow bowl into the green bowl. A penalty of−0.5is applied if the target bowl is knocked over during execution. A.2 Hang Cup (D2) The robot must grasp a purple cup and hang it onto a mug rack. The task is evaluated using four intermediate checkpoints (maximum score: 4):
-
[33]
The robot correctly locates and grasps the cup
-
[34]
The robot moves the cup near the mug rack (within 3 cm)
-
[35]
The robot performs a valid hanging attempt with inward insertion motion
-
[36]
A.3 Press Button (D3) The robot must identify a green button, move the end-effector toward it, and press it successfully
The cup is successfully hung onto the rack. A.3 Press Button (D3) The robot must identify a green button, move the end-effector toward it, and press it successfully. The task is evaluated using three intermediate checkpoints (maximum score: 3):
-
[37]
The robot correctly localizes the button with proper end-effector orientation
-
[38]
The end-effector moves near the button (within 3 cm)
-
[39]
A.4 Fold Towel (D4) The robot must fold a gray towel corner-to-corner
The robot successfully presses the button. A.4 Fold Towel (D4) The robot must fold a gray towel corner-to-corner. The task is evaluated using five intermediate checkpoints (maximum score: 5):
-
[40]
The robot correctly locates the top-right towel corner
-
[41]
The robot successfully grasps the corner
-
[42]
The robot folds the corner toward the top-left corner
-
[43]
The robot correctly locates the bottom-right corner
-
[44]
The robot completes the final towel alignment and tidying behavior. 11
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.