REVERSE: Reinforcing Evidence Verification and Search for Agentic Image geo-localization
Pith reviewed 2026-06-29 18:16 UTC · model grok-4.3
The pith
REVERSE trains a 4B model to perform multi-turn evidence search and verification for image geo-localization, outperforming larger models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
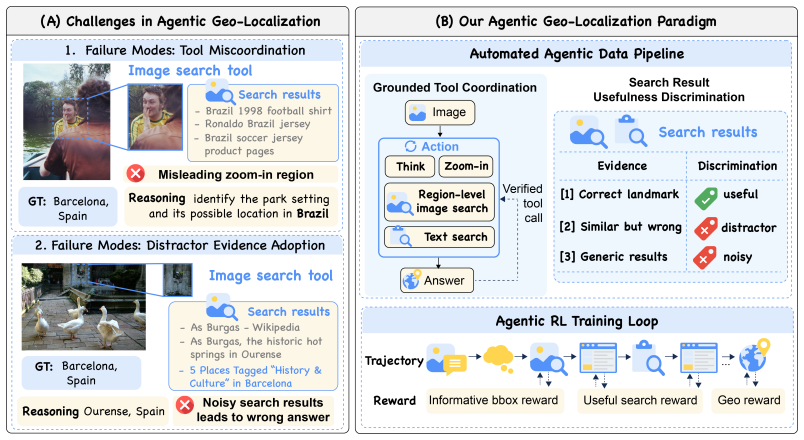
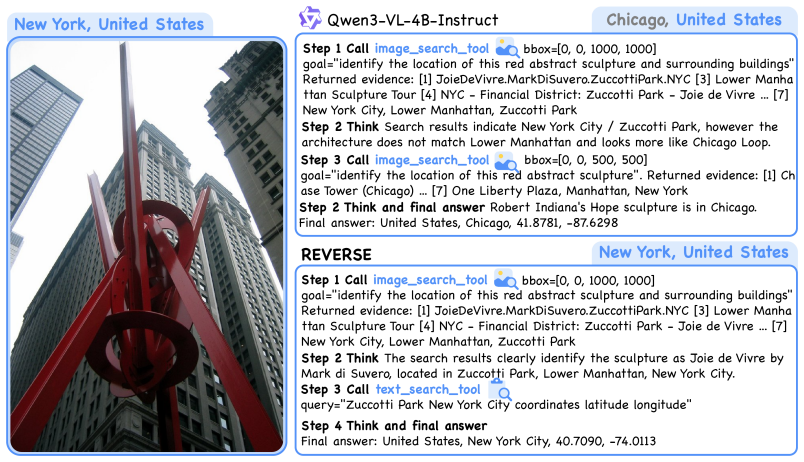
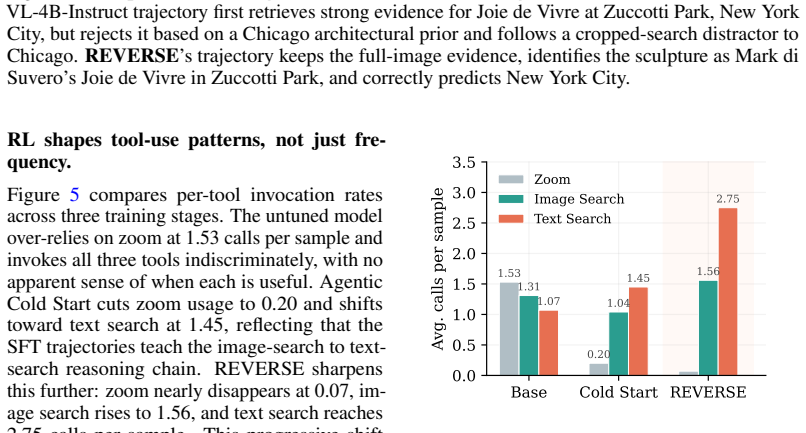
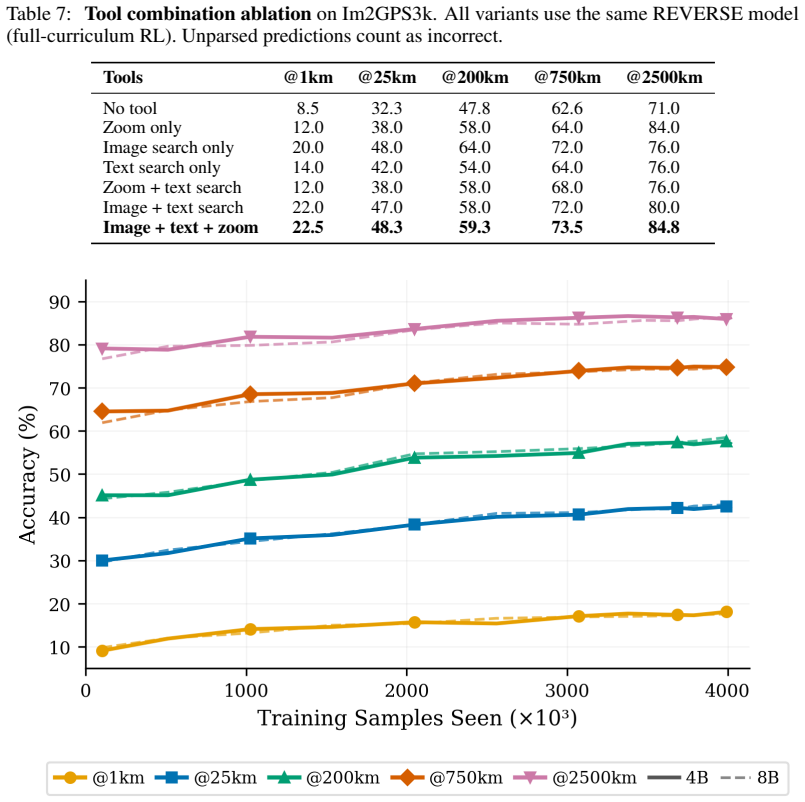
REVERSE reinforces the interplay between evidence search and verification to enable multi-turn agentic reasoning in image geo-localization. It teaches three intermediate decisions through tool-grounded trajectories annotated with region selections, search observations, and geo-informative evidence labels, along with process rewards for visual grounding, query utility, and evidence discrimination. An offline search cache stabilizes retrieval observations for dense supervision. A 4B model trained this way outperforms strong retrieval-augmented baselines and rivals substantially larger models on Im2GPS3k and YFCC4k.
What carries the argument
The REVERSE framework, which uses tool-grounded trajectories and process rewards to supervise the decisions of where to look, what to query, and what evidence to trust in an agentic reasoning loop.
If this is right
- Models can handle ambiguous images by revising judgments as new clues appear.
- Retrieval-augmented methods gain dense supervision on intermediate search decisions rather than only final accuracy.
- Smaller models achieve competitive geo-localization without scaling model size.
- Offline caches make reinforcement learning practical by reusing stable retrieval observations.
Where Pith is reading between the lines
- Similar reinforcement on search trajectories could extend to other agentic tasks like visual question answering or document analysis.
- The approach might reduce reliance on ever-larger models if the supervision generalizes across domains.
- Testing on images from underrepresented regions could reveal if the trajectories capture global geo-informative cues.
Load-bearing premise
The constructed tool-grounded trajectories with annotated region selections, search observations, and geo-informative evidence labels supply effective and unbiased supervision for the three intermediate decisions.
What would settle it
If a model trained with these trajectories shows no improvement over baselines when evaluated on a held-out set of images requiring novel search strategies not covered in the annotations, the supervision would be shown insufficient.
Figures


read the original abstract
Image geo-localization aims to determine where a photograph was taken, a task that often requires more than recognizing visible landmarks. Human experts typically solve it through an iterative workflow: they inspect informative regions, form location hypotheses, seek external evidence, and revise their judgments as new clues appear. Existing methods only partially capture this process: direct prediction methods bypass evidence acquisition altogether, while retrieval-augmented methods introduce external evidence but usually provide limited supervision on the intermediate decisions of where to search, how to query, and how to filter noisy results. We present REVERSE, a framework that reinforces the interplay between evidence search and verification to enable multi-turn agentic reasoning. REVERSE teaches three intermediate decisions: where to look, what to query, and what evidence to trust. To support this, we construct tool-grounded trajectories with annotated region selections, search observations, and geo-informative evidence labels, and introduce process rewards for visual grounding, query utility, and evidence discrimination. An offline search cache makes retrieval observations stable and reusable during reinforcement learning, enabling dense supervision over noisy search results. With a 4B model, REVERSE outperforms strong retrieval-augmented baselines and rivals substantially larger models on Im2GPS3k and YFCC4k. Code is available at https://github.com/yonglleee/REVERSE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces REVERSE, a reinforcement learning framework for agentic image geo-localization. It constructs tool-grounded trajectories with annotated region selections, search observations, and geo-informative evidence labels to provide supervision for three intermediate decisions (where to look, what to query, what evidence to trust). Process rewards for visual grounding, query utility, and evidence discrimination are combined with an offline search cache to enable stable multi-turn reasoning. A 4B model is reported to outperform strong retrieval-augmented baselines and rival larger models on Im2GPS3k and YFCC4k.
Significance. If the gains prove robust, the work shows that dense process-level supervision on intermediate agentic decisions can allow smaller models to compete with much larger ones in tool-augmented visual reasoning. The public code release is a clear strength that supports reproducibility.
major comments (1)
- [Abstract] Abstract: the central claim that the 4B model outperforms retrieval baselines on Im2GPS3k and YFCC4k rests on the constructed trajectories supplying effective, unbiased supervision for the three decisions. No detail is given on how the offline cache and annotation process avoid embedding systematic biases in region choice, query formulation, or evidence filtering; if such biases exist, the process rewards would reinforce them rather than produce generalizable agentic behavior.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the single major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the 4B model outperforms retrieval baselines on Im2GPS3k and YFCC4k rests on the constructed trajectories supplying effective, unbiased supervision for the three decisions. No detail is given on how the offline cache and annotation process avoid embedding systematic biases in region choice, query formulation, or evidence filtering; if such biases exist, the process rewards would reinforce them rather than produce generalizable agentic behavior.
Authors: We agree that the abstract (and the current level of detail in the methods) does not sufficiently address potential biases in trajectory construction. The manuscript describes the use of annotated region selections, search observations, and geo-informative evidence labels together with an offline cache for stability, but provides no explicit analysis of how the annotation pipeline or cache construction avoids systematic biases in the three decisions. We will revise the abstract to note this limitation and add a dedicated subsection detailing the annotation protocol (including annotator diversity, validation against held-out geo-tags, and randomization steps) plus cache construction (e.g., uniform sampling across locations). This will allow readers to evaluate the risk that process rewards reinforce dataset-specific artifacts rather than generalizable reasoning. revision: yes
Circularity Check
No circularity; claims rest on external benchmarks
full rationale
The paper constructs custom tool-grounded trajectories and process rewards to train an agentic model for geo-localization decisions. Its central performance claims (4B model outperforming baselines on Im2GPS3k and YFCC4k) are evaluated against external, standard benchmarks rather than quantities defined inside the training loop. No equations, fitted parameters renamed as predictions, or self-citation chains are visible in the provided text that would reduce the reported results to the inputs by construction. The derivation chain remains self-contained against external evaluation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
On the opportunities and challenges of foundation models for GeoAI.ACM Transactions on Spatial Algorithms and Systems, 10(2):1–46, 2024
Gengchen Mai, Weiming Huang, Jin Sun, Suhang Song, Deepak Mishra, Ninghao Liu, Song Gao, Tianming Liu, Gao Cong, Yingjie Hu, Chris Cundy, Ziyuan Li, Rui Zhu, and Ni Lao. On the opportunities and challenges of foundation models for GeoAI.ACM Transactions on Spatial Algorithms and Systems, 10(2):1–46, 2024
2024
-
[2]
OpenStreetView-5M: The many roads to global visual geolocation
Guillaume Astruc, Nicolas Dufour, Ioannis Siglidis, Constantin Aronssohn, Nacim Bouia, Stephanie Fu, Romain Loiseau, Van Nguyen Nguyen, Charles Raude, Elliot Vincent, Lintao Xu, Hongyu Zhou, and Loic Landrieu. OpenStreetView-5M: The many roads to global visual geolocation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition...
2024
-
[3]
PlaNet - photo geolocation with convolu- tional neural networks
Tobias Weyand, Ilya Kostrikov, and James Philbin. PlaNet - photo geolocation with convolu- tional neural networks. InEuropean Conference on Computer Vision (ECCV), 2016
2016
-
[4]
CPlaNet: Enhancing image geolocalization by combinatorial partitioning of maps
Paul Hongsuck Seo, Tobias Weyand, Jack Sim, and Bohyung Han. CPlaNet: Enhancing image geolocalization by combinatorial partitioning of maps. InEuropean Conference on Computer Vision (ECCV), 2018
2018
-
[5]
Geolocation estimation of photos using a hierarchical model and scene classification
Eric Müller-Budack, Kader Pustu-Iren, and Ralph Ewerth. Geolocation estimation of photos using a hierarchical model and scene classification. InEuropean Conference on Computer Vision (ECCV), 2018
2018
-
[6]
Vivanco Cepeda, Gaurav Kumar Nayak, and Mubarak Shah
V . Vivanco Cepeda, Gaurav Kumar Nayak, and Mubarak Shah. GeoCLIP: Clip-inspired alignment between locations and images for effective worldwide geo-localization. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[7]
PIGEON: Predicting image geolocations
Lukas Haas, Michal Skreta, Silas Alberti, and Chelsea Finn. PIGEON: Predicting image geolocations. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[8]
Img2Loc: Revisiting image geolocalization using multi-modality foundation models and image-based retrieval-augmented generation
Zhongliang Zhou, Jielu Zhang, Zihan Guan, Jiayu Hu, Shuwei Lao, Kaiye Mu, Yunqi Li, and Gengchen Mai. Img2Loc: Revisiting image geolocalization using multi-modality foundation models and image-based retrieval-augmented generation. InProceedings of the 47th Interna- tional ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR), 2024
2024
-
[9]
G3: An effective and adaptive framework for worldwide geolocalization using large multi-modality models
Pengyue Jia, Yiding Liu, Xiaopeng Li, Yuhao Wang, Yantong Du, Xiao Han, Xuetao Wei, Shuaiqiang Wang, Dawei Yin, and Xiangyu Zhao. G3: An effective and adaptive framework for worldwide geolocalization using large multi-modality models. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[10]
Vision-language reasoning for geolocalization: A reinforcement learning approach
Biao Wu, Meng Fang, Ling Chen, Ke Xu, Tao Cheng, and Jun Wang. Vision-language reasoning for geolocalization: A reinforcement learning approach. InProceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2026
2026
-
[11]
Modi Jin, Yiming Zhang, Boyuan Sun, Dingwen Zhang, MingMing Cheng, and Qibin Hou. Geoagent: Learning to geolocate everywhere with reinforced geographic characteristics.arXiv preprint arXiv:2602.12617, 2026
-
[12]
Furong Jia, Ling Dai, Wenjin Deng, Fan Zhang, Chen Hu, Daxin Jiang, and Yu Liu. Spotagent: Grounding visual geo-localization in large vision-language models through agentic reasoning. arXiv preprint arXiv:2602.09463, 2026
-
[13]
Yuxiang Ji, Yong Wang, Ziyu Ma, Yiming Hu, Hailang Huang, Xuecai Hu, Guanhua Chen, Liaoni Wu, and Xiangxiang Chu. Thinking with map: Reinforced parallel map-augmented agent for geolocalization.arXiv preprint arXiv:2601.05432, 2026
-
[14]
Swarm intelligence in geo-localization: A multi-agent large vision-language model collaborative framework
Xiao Han, Chen Zhu, Xiangyu Zhao, and Hengshu Zhu. Swarm intelligence in geo-localization: A multi-agent large vision-language model collaborative framework. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 2, pages 814–825, 2025. 10
2025
-
[15]
Yikun Wang, Zuyan Liu, Ziyi Wang, Han Hu, Pengfei Liu, and Yongming Rao. GeoVista: Web-augmented agentic visual reasoning for geolocalization.arXiv preprint arXiv:2511.15705, 2025
-
[16]
Revisiting IM2GPS in the deep learning era
Nam V o, Nathan Jacobs, and James Hays. Revisiting IM2GPS in the deep learning era. InIEEE International Conference on Computer Vision (ICCV), 2017
2017
-
[17]
Shamma, Gerald Friedland, Benjamin Elizalde, Karl Ni, Douglas Poland, Damian Borth, and Li-Jia Li
Bart Thomee, David A. Shamma, Gerald Friedland, Benjamin Elizalde, Karl Ni, Douglas Poland, Damian Borth, and Li-Jia Li. YFCC100M: The new data in multimedia research. In Communications of the ACM, 2016
2016
-
[18]
Nowara, Joshua Gleason, Carlos D
Shraman Pramanick, Ewa M. Nowara, Joshua Gleason, Carlos D. Castillo, and Rama Chellappa. Where in the world is this image? Transformer-based geo-localization in the wild. InEuropean Conference on Computer Vision (ECCV), 2022
2022
-
[19]
Where we are and what we’re looking at: Query based worldwide image geo-localization using hierarchies and scenes
Brandon Clark, Alec Kerrigan, Parth Parag Kulkarni, Vicente Vivanco Cepeda, and Mubarak Shah. Where we are and what we’re looking at: Query based worldwide image geo-localization using hierarchies and scenes. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 23182–23190, 2023
2023
-
[20]
GeoRanker: Distance- aware ranking for worldwide image geolocalization
Pengyue Jia, Seongheon Park, Song Gao, Xiangyu Zhao, and Sharon Li. GeoRanker: Distance- aware ranking for worldwide image geolocalization. InAdvances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[21]
Ling Li, Yao Zhou, Yuxuan Liang, Fugee Tsung, and Jiaheng Wei. Recognition through reasoning: Reinforcing image geo-localization with large vision-language models.arXiv preprint arXiv:2506.14674, 2025
-
[22]
ReAct: Synergizing Reasoning and Acting in Language Models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models.arXiv preprint arXiv:2210.03629, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[23]
Toolformer: Language models can teach themselves to use tools.Advances in neural information processing systems, 36: 68539–68551, 2023
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools.Advances in neural information processing systems, 36: 68539–68551, 2023
2023
-
[24]
Vipergpt: Visual inference via python execution for reasoning
Dídac Surís, Sachit Menon, and Carl V ondrick. Vipergpt: Visual inference via python execution for reasoning. InProceedings of the IEEE/CVF international conference on computer vision, pages 11888–11898, 2023
2023
-
[25]
MM-REACT: Prompting ChatGPT for Multimodal Reasoning and Action
Zhengyuan Yang, Linjie Li, Jianfeng Wang, Kevin Lin, Ehsan Azarnasab, Faisal Ahmed, Zicheng Liu, Ce Liu, Michael Zeng, and Lijuan Wang. Mm-react: Prompting chatgpt for multimodal reasoning and action.arXiv preprint arXiv:2303.11381, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
V?: Guided visual search as a core mechanism in multimodal llms
Penghao Wu and Saining Xie. V?: Guided visual search as a core mechanism in multimodal llms. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13084–13094, 2024
2024
-
[27]
DeepEyesV2: Toward Agentic Multimodal Model
Jack Hong, Chenxiao Zhao, ChengLin Zhu, Weiheng Lu, Guohai Xu, and Xing Yu. Deepeyesv2: Toward agentic multimodal model.arXiv preprint arXiv:2511.05271, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Wenxuan Huang, Yu Zeng, Qiuchen Wang, Zhen Fang, Shaosheng Cao, Zheng Chu, Qingyu Yin, Shuang Chen, Zhenfei Yin, Lin Chen, Zehui Chen, Xu Tang, Yao Hu, Shaohui Lin, Philip Torr, Feng Zhao, and Wanli Ouyang. Vision-deepresearch: Incentivizing deepresearch capability in multimodal large language models.arXiv preprint arXiv:2601.22060, 2026
-
[29]
Yu Zeng, Wenxuan Huang, Zhen Fang, Shuang Chen, Yufan Shen, Yishuo Cai, Xiaoman Wang, Zhenfei Yin, Lin Chen, Zehui Chen, Shiting Huang, Yiming Zhao, Xu Tang, Yao Hu, Philip Torr, Wanli Ouyang, and Shaosheng Cao. Vision-deepresearch benchmark: Rethinking visual and textual search for multimodal large language models.arXiv preprint arXiv:2602.02185, 2026. 11
-
[30]
Zeyi Huang, Yuyang Ji, Anirudh Sundara Rajan, Zefan Cai, Wen Xiao, Haohan Wang, Junjie Hu, and Yong Jae Lee. Visualtoolagent (vista): A reinforcement learning framework for visual tool selection.arXiv preprint arXiv:2505.20289, 2025
-
[31]
Visual Reasoning through Tool-supervised Reinforcement Learning
Qihua Dong, Gozde Sahin, Pei Wang, Zhaowei Cai, Robik Shrestha, Hao Yang, and Davide Modolo. Visual reasoning through tool-supervised reinforcement learning.arXiv preprint arXiv:2604.19945, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[32]
Chain-of-focus: Adaptive visual search and zooming for multimodal reasoning via rl.arXiv e-prints, pages arXiv–2505, 2025
Xintong Zhang, Zhi Gao, Bofei Zhang, Pengxiang Li, Xiaowen Zhang, Yang Liu, Tao Yuan, Yuwei Wu, Yunde Jia, Song-Chun Zhu, and Qing Li. Chain-of-focus: Adaptive visual search and zooming for multimodal reasoning via rl.arXiv e-prints, pages arXiv–2505, 2025
2025
-
[33]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y .K. Li, Y . Wu, and Daya Guo. DeepSeekMath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
GeoToken: Hierar- chical geolocalization of images via next token prediction
Narges Ghasemi, Amir Ziashahabi, Salman Avestimehr, and Cyrus Shahabi. GeoToken: Hierar- chical geolocalization of images via next token prediction. InIEEE International Conference on Data Mining (ICDM), 2025
2025
-
[36]
Where we are and what we’re looking at: Query based worldwide image geo-localization using hierarchies and scenes
Brandon Clark, Alec Kerrigan, Parth Parag Kulkarni, Vicente Vivanco Cepeda, and Mubarak Shah. Where we are and what we’re looking at: Query based worldwide image geo-localization using hierarchies and scenes. InIEEE/CVF International Conference on Computer Vision (ICCV), 2023
2023
-
[37]
GeoBayes: Probabilistic image geo-localization inference via sequential bayesian updating
Weimin Shi, Xiang Li, Kaige Li, Junhao Fang, Qiang Zhou, Qichuan Geng, and Zhong Zhou. GeoBayes: Probabilistic image geo-localization inference via sequential bayesian updating. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2026
2026
-
[38]
HybridFlow: A Flexible and Efficient RLHF Framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. HybridFlow: A flexible and efficient RLHF framework. arXiv preprint arXiv:2409.19256, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
SGLang: Efficient Execution of Structured Language Model Programs
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E. Gonzalez, Clark Barrett, and Ying Sheng. SGLang: Efficient execution of structured language model programs.arXiv preprint arXiv:2312.07104, 2023. 12 A Agent Implementation Details A.1 Prompt To ensure consistency between t...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.