Natural Human Motion Recovery by Aligning High-Order Temporal Dynamics from Monocular Videos
Pith reviewed 2026-06-29 18:08 UTC · model grok-4.3
The pith
Estimating per-joint velocities and accelerations from monocular video refines existing human motion recovery into trajectories with realistic dynamics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
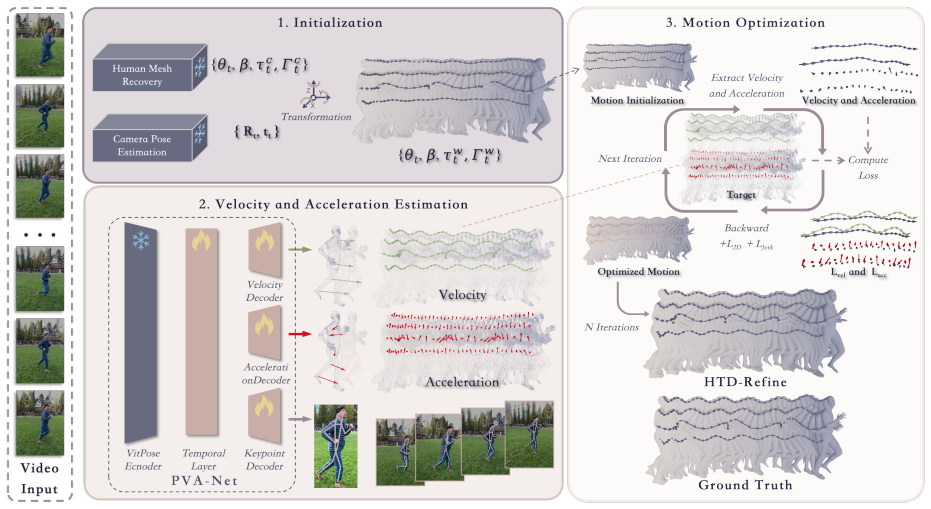
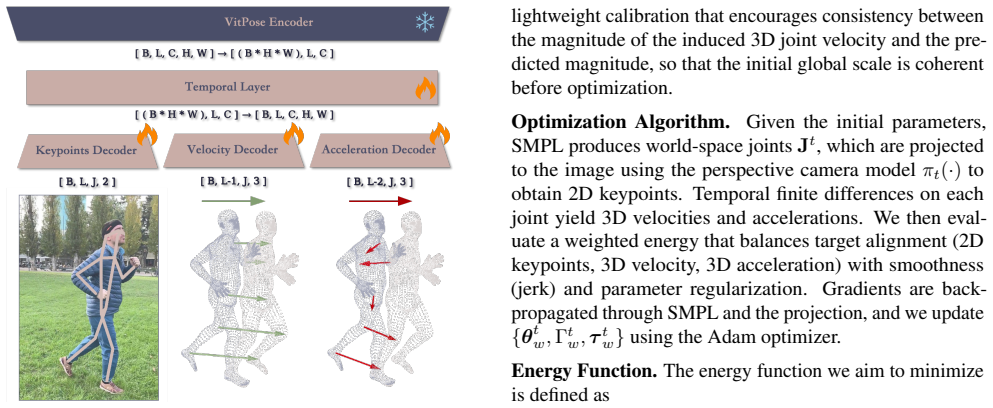
HTD-Refine augments any existing Human Motion Recovery pipeline by running PVA-Net, a temporal transformer, to output per-joint 2D positions together with 3D velocities and 3D accelerations; these quantities are then treated as soft constraints inside a global optimization that refines world-space trajectories and thereby reduces jitter while restoring physically plausible high-frequency detail.
What carries the argument
PVA-Net, a temporal transformer whose predicted 3D velocities and accelerations serve as soft constraints inside the global trajectory optimization.
If this is right
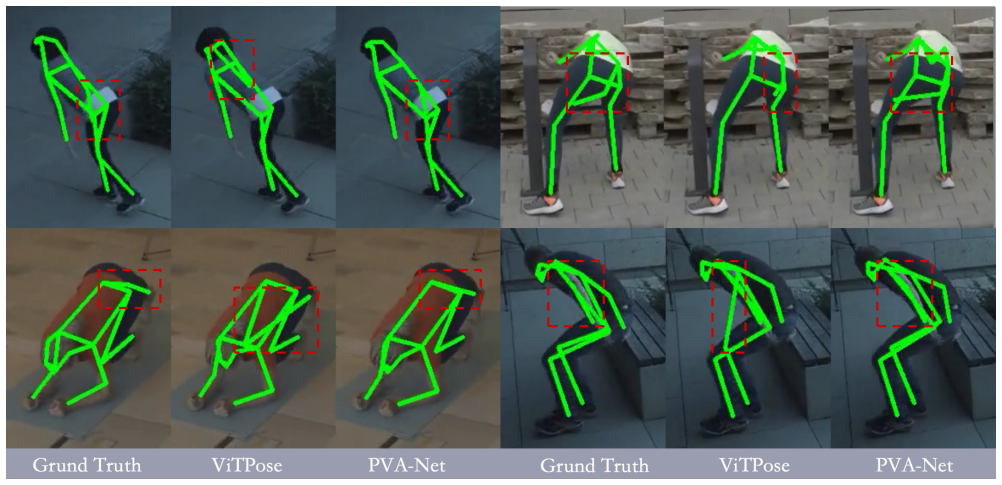
- State-of-the-art HMR methods obtain more accurate global trajectories after HTD-Refine post-processing.
- Recovered motions exhibit substantially more natural dynamics without any change to the original recovery network.
- Over-smoothing is suppressed while numerical accuracy on joint positions is preserved.
- High-order temporal modeling is shown to be essential for physically plausible monocular motion recovery.
Where Pith is reading between the lines
- The same soft-constraint approach could be applied to multi-view or RGB-D recovery systems that already produce position estimates.
- If PVA-Net predictions hold for longer untrimmed videos, the refinement might enable animation from ordinary handheld footage.
- The method invites direct tests on sequences with rapid motion or heavy occlusion to determine where the velocity estimates break.
Load-bearing premise
The velocities and accelerations predicted by PVA-Net remain sufficiently accurate and consistent across frames to act as useful soft constraints without introducing new artifacts.
What would settle it
Run HTD-Refine on a benchmark where PVA-Net's velocity and acceleration outputs are replaced by random or zero values and measure whether the refined motions become less natural or more erroneous than the unrefined baseline.
Figures



read the original abstract
Human motion recovered from monocular videos often appears overly smooth or dynamically inconsistent, even when joint positions are numerically accurate. We observe that this limitation stems from the absence of reliable high-order temporal cues -- velocity and acceleration -- which are essential for reconstructing motion that exhibits realistic momentum, timing, and high-frequency detail. We introduce HTD-Refine, a post-processing framework that augments existing Human Motion Recovery (HMR) pipelines using explicitly estimated high-order temporal dynamics. At the core of our system is PVA-Net, a temporal transformer that infers per-joint 2D positions, 3D velocities, and 3D accelerations directly from a monocular video. These predicted dynamics serve as soft yet informative constraints in a global optimization procedure that refines world-space trajectories, significantly reducing jitter, suppressing over-smoothing, and restoring physically plausible motion. Extensive experiments on challenging in-the-wild benchmarks show that HTD-Refine consistently improves state-of-the-art HMR methods, yielding more accurate global trajectories and substantially more natural motion dynamics. Our results highlight the critical role of high-order temporal modeling in advancing monocular human motion recovery.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces HTD-Refine, a post-processing framework for human motion recovery (HMR) from monocular videos. It uses PVA-Net, a temporal transformer, to predict per-joint 2D positions along with 3D velocities and accelerations, which are then applied as soft constraints in a global optimization to refine world-space trajectories from existing HMR methods, with the goal of reducing jitter, suppressing over-smoothing, and producing more natural dynamics. The abstract claims consistent improvements on in-the-wild benchmarks.
Significance. If PVA-Net's high-order predictions can be shown to be sufficiently accurate, the approach would address a recognized limitation in monocular HMR by explicitly enforcing velocity and acceleration consistency, potentially improving physical plausibility without requiring multi-view or sensor data. The post-processing design would allow broad applicability to existing pipelines.
major comments (2)
- [Abstract] Abstract: the central claim that 'HTD-Refine consistently improves state-of-the-art HMR methods' is stated without any quantitative metrics, error bars, ablation results, or dataset details, so the magnitude and reliability of the reported gains cannot be evaluated.
- [PVA-Net and optimization sections] PVA-Net and optimization sections: no independent quantitative validation (e.g., velocity or acceleration error on held-out 3D ground-truth data) is reported for PVA-Net's 3D dynamics predictions before they are used as soft constraints; because monocular 3D dynamics inference is severely underconstrained, any systematic bias would propagate directly into the refined trajectories, undermining the claim that the constraints improve rather than degrade results.
minor comments (1)
- [Method] The description of how 2D positions, 3D velocities, and 3D accelerations are jointly predicted and normalized could be made more precise with explicit equations or pseudocode.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which identify opportunities to strengthen the clarity of our claims and the rigor of our validation. We address each major comment below and commit to revisions where the points are valid.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'HTD-Refine consistently improves state-of-the-art HMR methods' is stated without any quantitative metrics, error bars, ablation results, or dataset details, so the magnitude and reliability of the reported gains cannot be evaluated.
Authors: We agree that the abstract presents the improvement claim at a high level. In the revised manuscript we will update the abstract to include concise quantitative highlights drawn from the results section, such as average improvements in global trajectory error and jitter reduction across the evaluated in-the-wild benchmarks and HMR baselines, together with the specific datasets used. This will allow readers to assess the scale of the gains directly from the abstract. revision: yes
-
Referee: [PVA-Net and optimization sections] PVA-Net and optimization sections: no independent quantitative validation (e.g., velocity or acceleration error on held-out 3D ground-truth data) is reported for PVA-Net's 3D dynamics predictions before they are used as soft constraints; because monocular 3D dynamics inference is severely underconstrained, any systematic bias would propagate directly into the refined trajectories, undermining the claim that the constraints improve rather than degrade results.
Authors: We acknowledge that the current manuscript relies on end-to-end system-level improvements rather than reporting separate accuracy metrics for PVA-Net's 3D velocity and acceleration predictions on held-out 3D ground truth. This leaves open the possibility of bias propagation. In revision we will add a dedicated quantitative validation subsection (or table) that measures PVA-Net's per-joint velocity and acceleration errors against 3D ground-truth data from standard motion-capture datasets, thereby directly addressing the concern about the reliability of the soft constraints. revision: yes
Circularity Check
No circularity: method relies on external PVA-Net predictions and benchmark validation without self-referential fitting or definitional loops
full rationale
The abstract and description introduce PVA-Net as a temporal transformer that directly infers 2D positions, 3D velocities and accelerations from monocular video, then apply those outputs as soft constraints inside a separate global optimization stage. No equations, fitting procedures, or self-citations are shown that would make any claimed prediction equivalent to its own inputs by construction. The central claim is supported by reported improvements on external in-the-wild benchmarks rather than by internal re-labeling of fitted quantities. This satisfies the default expectation of a self-contained derivation against external data.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
https : / / www
Optitrack: Motion capture systems. https : / / www . optitrack.com/. 2
-
[2]
ZoeDepth: Zero-shot Transfer by Combining Relative and Metric Depth
Shariq Farooq Bhat, Reiner Birkl, Diana Wofk, Peter Wonka, and Matthias M ¨uller. Zoedepth: Zero-shot trans- fer by combining relative and metric depth.arXiv preprint arXiv:2302.12288, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Black, Priyanka Patel, Joachim Tesch, and Jinlong Yang
Michael J. Black, Priyanka Patel, Joachim Tesch, and Jinlong Yang. BEDLAM: A synthetic dataset of bodies exhibiting detailed lifelike animated motion. InIEEE Conf. Comput. Vis. Pattern Recog., 2023-06. 4, 11
2023
-
[4]
Federica Bogo, Angjoo Kanazawa, Christoph Lassner, Peter Gehler, Javier Romero, and Michael J. Black. Keep it SMPL: Automatic estimation of 3D human pose and shape from a single image. InEur. Conf. Comput. Vis., 2016-10. 2, 3
2016
-
[5]
Realtime multi-person 2d pose estimation using part affinity fields
Zhe Cao, Tomas Simon, Shih-En Wei, and Yaser Sheikh. Realtime multi-person 2d pose estimation using part affinity fields. InIEEE Conf. Comput. Vis. Pattern Recog., 2019. 2
2019
-
[6]
Video depth anything: Consistent depth estimation for super-long videos
Sili Chen, Hengkai Guo, Shengnan Zhu, Feihu Zhang, Zilong Huang, Jiashi Feng, and Bingyi Kang. Video depth anything: Consistent depth estimation for super-long videos. InPro- ceedings of the Computer Vision and Pattern Recognition Conference, pages 22831–22840, 2025. 5
2025
-
[7]
arXiv preprint arXiv:2510.06219 , year=
Yue Chen, Xingyu Chen, Yuxuan Xue, Anpei Chen, Yuliang Xiu, and Gerard Pons-Moll. Human3R: Everyone everywhere all at once.arXiv preprint arXiv:2510.06219, 2025. 1, 2, 6
-
[8]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Syl- vain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. InInt. Conf. Learn. Represent., 2021. 2
2021
-
[9]
Tokenhmr: Advancing human mesh re- covery with a tokenized pose representation
Sai Kumar Dwivedi, Yu Sun, Priyanka Patel, Yao Feng, and Michael J Black. Tokenhmr: Advancing human mesh re- covery with a tokenized pose representation. InIEEE Conf. Comput. Vis. Pattern Recog., 2024. 2
2024
-
[10]
Humans in 4D: Re- constructing and tracking humans with transformers
Shubham Goel, Georgios Pavlakos, Jathushan Rajasegaran, Angjoo Kanazawa, and Jitendra Malik. Humans in 4D: Re- constructing and tracking humans with transformers. InInt. Conf. Comput. Vis., 2023. 1, 2
2023
-
[11]
Generating diverse and natural 3d human motions from text
Chuan Guo, Shihao Zou, Xinxin Zuo, Sen Wang, Wei Ji, Xingyu Li, and Li Cheng. Generating diverse and natural 3d human motions from text. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5152–5161, 2022. 1, 2
2022
-
[12]
NeMF: Neural motion fields for kinematic ani- mation.Advances in Neural Information Processing Systems, 35:4244–4256, 2022
Chengan He, Jun Saito, James Zachary, Holly Rushmeier, and Yi Zhou. NeMF: Neural motion fields for kinematic ani- mation.Advances in Neural Information Processing Systems, 35:4244–4256, 2022. 7
2022
-
[13]
Asap: Aligning simulation and real- world physics for learning agile humanoid whole-body skills
Tairan He, Jiawei Gao, Wenli Xiao, Yuanhang Zhang, Zi Wang, Jiashun Wang, Zhengyi Luo, Guanqi He, Nikhil Soban- bab, Chaoyi Pan, et al. Asap: Aligning simulation and real- world physics for learning agile humanoid whole-body skills. arXiv preprint arXiv:2502.01143, 2025. 2
-
[14]
A causal convolutional neural network for multi-subject motion modeling and generation.Computational Visual Media, 10 (1):45–59, 2024
Shuaiying Hou, Congyi Wang, Wenlin Zhuang, Yu Chen, Yangang Wang, Hujun Bao, Jinxiang Chai, and Weiwei Xu. A causal convolutional neural network for multi-subject motion modeling and generation.Computational Visual Media, 10 (1):45–59, 2024. 1
2024
-
[15]
Huang, Hongwei Yi, Markus H¨oschle, Matvey Safroshkin, Tsvetelina Alexiadis, Senya Polikovsky, Daniel Scharstein, and Michael J
Chun-Hao P. Huang, Hongwei Yi, Markus H¨oschle, Matvey Safroshkin, Tsvetelina Alexiadis, Senya Polikovsky, Daniel Scharstein, and Michael J. Black. Capturing and inferring dense full-body human-scene contact. InIEEE Conf. Comput. Vis. Pattern Recog., 2022-06. 4, 6, 7, 11
2022
-
[16]
Human3.6m: Large scale datasets and predic- tive methods for 3d human sensing in natural environments
Catalin Ionescu, Dragos Papava, Vlad Olaru, and Cristian Sminchisescu. Human3.6m: Large scale datasets and predic- tive methods for 3d human sensing in natural environments. IEEE transactions on pattern analysis and machine intelli- gence, 36(7):1325–1339, 2013. 4, 11, 13
2013
-
[17]
EMDB: The Electromagnetic Database of Global 3D Human Pose and Shape in the Wild
Manuel Kaufmann, Jie Song, Chen Guo, Kaiyue Shen, Tian- jian Jiang, Chengcheng Tang, Juan Jos´e Z´arate, and Otmar Hilliges. EMDB: The Electromagnetic Database of Global 3D Human Pose and Shape in the Wild. InInt. Conf. Comput. Vis., 2023. 6, 8
2023
-
[18]
From skin to skeleton: Towards biomechanically accurate 3D digital humans.ACM Trans
Marilyn Keller, Keenon Werling, Soyong Shin, Scott Delp, Sergi Pujades, C Karen Liu, and Michael J Black. From skin to skeleton: Towards biomechanically accurate 3D digital humans.ACM Trans. Graph., 42(6):1–12, 2023. 1
2023
-
[19]
Black, Otmar Hilliges, Jan Kautz, and Umar Iqbal
Muhammed Kocabas, Ye Yuan, Pavlo Molchanov, Yunrong Guo, Michael J. Black, Otmar Hilliges, Jan Kautz, and Umar Iqbal. PACE: Human and motion estimation from in-the-wild videos. In3DV, 2024. 7
2024
-
[20]
Learning to reconstruct 3d human pose and shape via model-fitting in the loop
Nikos Kolotouros, Georgios Pavlakos, Michael J Black, and Kostas Daniilidis. Learning to reconstruct 3d human pose and shape via model-fitting in the loop. InInt. Conf. Comput. Vis., 2019. 2
2019
-
[21]
Cliff: Carrying location information in full frames into human pose and shape estimation
Zhihao Li, Jianzhuang Liu, Zhensong Zhang, Songcen Xu, and Youliang Yan. Cliff: Carrying location information in full frames into human pose and shape estimation. InEur. Conf. Comput. Vis., 2022. 2
2022
-
[22]
BeyondMimic: From Motion Tracking to Versatile Humanoid Control via Guided Diffusion
Qiayuan Liao, Takara E Truong, Xiaoyu Huang, Guy Tevet, Koushil Sreenath, and C Karen Liu. Beyondmimic: From motion tracking to versatile humanoid control via guided diffusion.arXiv preprint arXiv:2508.08241, 2025. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Geometry-aware 3d pose transfer using transformer autoen- coder.Computational Visual Media, 10(1):1–18, 2024
Shanghuan Liu, Shaoyan Gai, Feipeng Da, and Fazal Waris. Geometry-aware 3d pose transfer using transformer autoen- coder.Computational Visual Media, 10(1):1–18, 2024. 1
2024
-
[24]
Heuris- tic weakly supervised 3d human pose estimation.Computa- tional Visual Media, 11(6):1399–1406, 2025
Shuangjun Liu, Michael Wan, and Sarah Ostadabbas. Heuris- tic weakly supervised 3d human pose estimation.Computa- tional Visual Media, 11(6):1399–1406, 2025. 1
2025
-
[25]
Joint optimization for 4D human-scene reconstruction in the wild
Zhizheng Liu, Joe Lin, Wayne Wu, and Bolei Zhou. Joint optimization for 4D human-scene reconstruction in the wild. arXiv:2501.02158, 2025. 2 9
-
[26]
Troje, Ger- ard Pons-Moll, and Michael J
Naureen Mahmood, Nima Ghorbani, Nikolaus F. Troje, Ger- ard Pons-Moll, and Michael J. Black. AMASS: Archive of motion capture as surface shapes. InInt. Conf. Comput. Vis.,
-
[27]
Georgios Pavlakos, Vasileios Choutas, Nima Ghorbani, Timo Bolkart, Ahmed A. A. Osman, Dimitrios Tzionas, and Michael J. Black. Expressive body capture: 3D hands, face, and body from a single image. InIEEE Conf. Comput. Vis. Pattern Recog., 2019. 2, 3
2019
-
[28]
Davis Rempe, Tolga Birdal, Aaron Hertzmann, Jimei Yang, Srinath Sridhar, and Leonidas J. Guibas. HuMoR: 3D hu- man motion model for robust pose estimation. InInt. Conf. Comput. Vis., 2021. 2, 3
2021
-
[29]
World-grounded human motion recovery via gravity-view co- ordinates
Zehong Shen, Huaijin Pi, Yan Xia, Zhi Cen, Sida Peng, Zechen Hu, Hujun Bao, Ruizhen Hu, and Xiaowei Zhou. World-grounded human motion recovery via gravity-view co- ordinates. InSIGGRAPH Asia Conference Proceedings, 2024. 1, 2, 4, 6, 13
2024
-
[30]
Phasemp: Robust 3d pose estimation via phase-conditioned human motion prior
Mingyi Shi, Sebastian Starke, Yuting Ye, Taku Komura, and Jungdam Won. Phasemp: Robust 3d pose estimation via phase-conditioned human motion prior. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 14725–14737, 2023. 3
2023
-
[31]
Gener- ating diverse clothed 3d human animations via a generative model.Computational Visual Media, 10(2):261–277, 2024
Min Shi, Wenke Feng, Lin Gao, and Dengming Zhu. Gener- ating diverse clothed 3d human animations via a generative model.Computational Visual Media, 10(2):261–277, 2024. 1
2024
-
[32]
Wham: Reconstructing world-grounded humans with accu- rate 3d motion
Soyong Shin, Juyong Kim, Eni Halilaj, and Michael J Black. Wham: Reconstructing world-grounded humans with accu- rate 3d motion. InIEEE Conf. Comput. Vis. Pattern Recog.,
-
[33]
Applications of pose estimation in human health and performance across the lifespan.Sensors, 21(21):7315, 2021
Jan Stenum, Kendra M Cherry-Allen, Connor O Pyles, Rachel D Reetzke, Michael F Vignos, and Ryan T Roem- mich. Applications of pose estimation in human health and performance across the lifespan.Sensors, 21(21):7315, 2021. 1
2021
-
[34]
RoFormer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063,
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. RoFormer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063,
-
[35]
Neural localizer fields for continuous 3d human pose and shape estimation
Istv´an S´ar´andi and Gerard Pons-Moll. Neural localizer fields for continuous 3d human pose and shape estimation. In NeurIPS, 2024. 1
2024
-
[36]
DROID-SLAM: Deep Visual SLAM for Monocular, Stereo, and RGB-D Cameras
Zachary Teed and Jia Deng. DROID-SLAM: Deep Visual SLAM for Monocular, Stereo, and RGB-D Cameras. In NeurIPS, 2021. 4
2021
-
[37]
Human motion diffusion model
Guy Tevet, Sigal Raab, Brian Gordon, Yoni Shafir, Daniel Cohen-or, and Amit Haim Bermano. Human motion diffusion model. InInt. Conf. Learn. Represent., 2023. 2
2023
-
[38]
VGGT: Vi- sual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. VGGT: Vi- sual geometry grounded transformer. InIEEE Conf. Comput. Vis. Pattern Recog., 2025. 2
2025
-
[39]
TRAM: Global trajectory and motion of 3D humans from in-the-wild videos
Yufu Wang, Ziyun Wang, Lingjie Liu, and Kostas Daniilidis. TRAM: Global trajectory and motion of 3D humans from in-the-wild videos. InEur. Conf. Comput. Vis., 2024. 1, 2, 3, 4, 6, 7, 13
2024
-
[40]
PromptHMR: Promptable human mesh recovery
Yufu Wang, Yu Sun, Priyanka Patel, Kostas Daniilidis, Michael J Black, and Muhammed Kocabas. PromptHMR: Promptable human mesh recovery. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 1148–1159, 2025. 1
2025
-
[41]
ViTPose: Simple vision transformer baselines for human pose estimation
Yufei Xu, Jing Zhang, Qiming Zhang, and Dacheng Tao. ViTPose: Simple vision transformer baselines for human pose estimation. InNeurIPS, 2022. 2, 3, 4, 12
2022
-
[42]
Decoupling human and camera motion from videos in the wild
Vickie Ye, Georgios Pavlakos, Jitendra Malik, and Angjoo Kanazawa. Decoupling human and camera motion from videos in the wild. InIEEE Conf. Comput. Vis. Pattern Recog.,
-
[43]
Whac: World-grounded humans and cameras
Wanqi Yin, Zhongang Cai, Ruisi Wang, Fanzhou Wang, Chen Wei, Haiyi Mei, Weiye Xiao, Zhitao Yang, Qingping Sun, Atsushi Yamashita, et al. Whac: World-grounded humans and cameras. InEur. Conf. Comput. Vis., 2024. 2
2024
-
[44]
GLAMR: Global occlusion-aware human mesh recovery with dynamic cameras
Ye Yuan, Umar Iqbal, Pavlo Molchanov, Kris Kitani, and Jan Kautz. GLAMR: Global occlusion-aware human mesh recovery with dynamic cameras. InIEEE Conf. Comput. Vis. Pattern Recog., 2022. 3
2022
-
[45]
Twist: Teleoperated whole-body imitation system,
Yanjie Ze, Zixuan Chen, Jo ˜ao Pedro Ara ´ujo, Zi ang Cao, Xue Bin Peng, Jiajun Wu, and C. Karen Liu. Twist: Teleoperated whole-body imitation system.arXiv preprint arXiv:2505.02833, 2025. 1, 2
-
[46]
3d hand pose and shape estimation from monocular rgb via efficient 2d cues.Computational Visual Media, 10(1):79–96, 2024
Fenghao Zhang, Lin Zhao, Shengling Li, Wanjuan Su, Liman Liu, and Wenbing Tao. 3d hand pose and shape estimation from monocular rgb via efficient 2d cues.Computational Visual Media, 10(1):79–96, 2024. 1
2024
-
[47]
Hu- man pose estimation with general contact.Computational Visual Media, 11(6):1247–1262, 2025
He Zhang, Jianhui Zhao, Fan Li, Yitian Wu, Chao Tan, Shuangpeng Sun, Yaohua Wu, You Li, and Tao Yu. Hu- man pose estimation with general contact.Computational Visual Media, 11(6):1247–1262, 2025. 1
2025
-
[48]
Jianrong Zhang, Yangsong Zhang, Xiaodong Cun, Shaoli Huang, Yong Zhang, Hongwei Zhao, Hongtao Lu, and Xi Shen. T2m-gpt: Generating human motion from textual descriptions with discrete representations.arXiv preprint arXiv:2301.06052, 2023. 2
-
[49]
Learning motion prior for 4d human body capture in 3d scenes
Siwei Zhang, Yan Zhang, Federica Bogo, Marc Pollefeys, and Siyu Tang. Learning motion prior for 4d human body capture in 3d scenes. InInt. Conf. Comput. Vis., 2021. 3
2021
-
[50]
RoHM: Robust human motion reconstruction via diffusion
Siwei Zhang, Bharat Lal Bhatnagar, Yuanlu Xu, Alexan- der Winkler, Petr Kadlecek, Siyu Tang, and Federica Bogo. RoHM: Robust human motion reconstruction via diffusion. InIEEE Conf. Comput. Vis. Pattern Recog., 2024. 2, 3, 7 10 Supplementary Material A. Overview In this supplementary material, we provide additional imple- mentation details of PV A-Net (Sec...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.