CodecCap: High-Fidelity Codec-Inspired Residual Modeling for Dense Video Captioning
Pith reviewed 2026-06-29 18:49 UTC · model grok-4.3
The pith
CodecCap models videos as keyframe captions plus residual captions to raise dense video captioning fidelity over direct methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
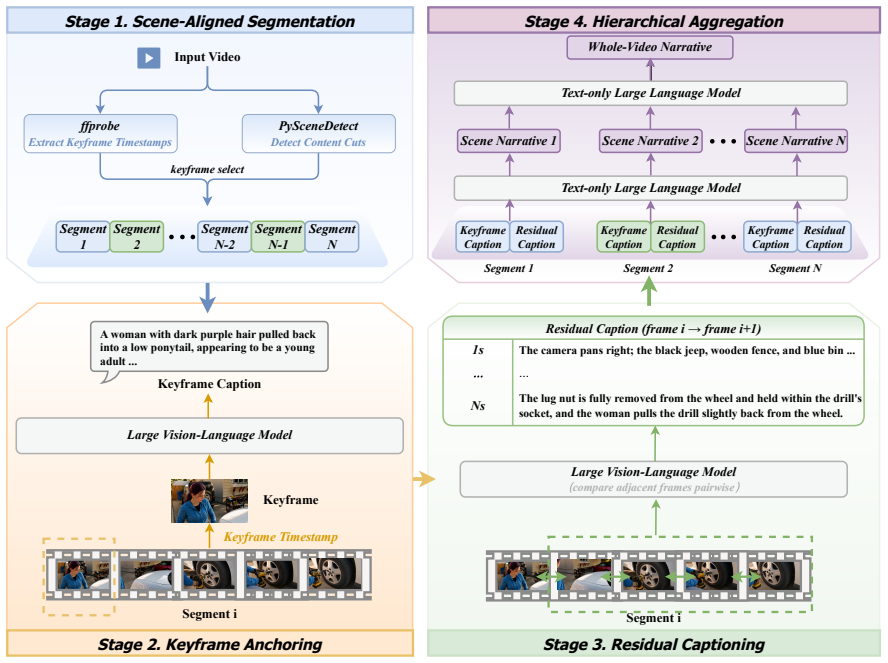
The paper claims that representing videos with keyframe captions that exhaustively encode stable visual context and residual captions that capture only temporally localized actions, motions, and changes preserves fine-grained visual evidence while reducing redundant descriptions, and that this codec-inspired decomposition yields captions of higher fidelity than those produced by direct captioning with the same underlying VLMs.
What carries the argument
Codec-inspired decomposition of video captions into keyframe captions for stable context and residual captions for localized temporal changes.
If this is right
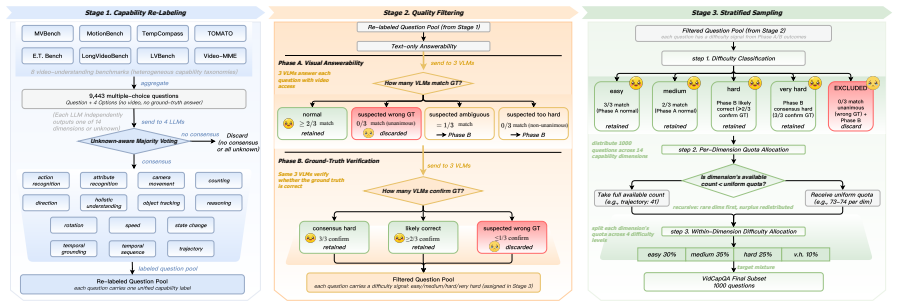
- CodecCap captions miss fewer visual details than direct generation by the same VLMs on the VidCapQA benchmark.
- The method supports construction of large-scale datasets such as CodecVDC-100K with anchor, residual, scene-level, and video-level supervision.
- Keyframe-residual captioning is presented as a route to higher-fidelity video-language supervision.
- Direct captions from strong VLMs still miss many visual details across the tested capability dimensions.
Where Pith is reading between the lines
- The same keyframe-residual split could be tested on video tasks beyond captioning such as action localization.
- VidCapQA might serve as an evaluation tool for captioning approaches that do not use the codec structure.
- The decomposition may suggest ways to compress other forms of video supervision for model training.
- If the assumption on exhaustive coverage holds, the method could reduce annotation cost for dense video datasets.
Load-bearing premise
Keyframe captions can exhaustively encode stable visual context while residual captions capture only temporally localized changes without omitting important details or creating new gaps in coverage.
What would settle it
A direct comparison on VidCapQA or a similar test set in which CodecCap captions miss as many visual details as direct VLM captions, or in which keyframe-residual splits are shown to omit key information.
Figures


read the original abstract
Existing video captioning methods struggle to balance visual fidelity and redundancy: holistic captions are compact but lose fine-grained evidence, whereas segment-wise captions improve coverage but introduce heavy redundancy. We propose CodecCap, a codec-inspired framework for high-fidelity dense video captioning. Analogous to video codecs, CodecCap represents videos using keyframe and residual captions. Keyframe captions exhaustively encode stable visual context, while residual captions capture temporally only localized actions, motions and changes. This effectively preserves fine-grained visual evidence while reducing redundant descriptions. To quantify the fidelity of captions, we introduce VidCapQA, a caption-then-QA benchmark with 1,000 questions across 14 capability dimensions. Results on VidCapQA show that captions directly generated by strong VLMs still miss many visual details, highlighting caption representation as a critical bottleneck. Experiments show that CodecCap significantly surpasses direct captioning with the same underlying VLMs, suggesting keyframe-residual captioning a way for high-fidelity video-language supervision. We further use CodecCap to construct CodecVDC-100K, a large-scale dense captioning dataset with anchor, residual, scene-level, and video-level supervision.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CodecCap, a codec-inspired residual modeling framework for dense video captioning. Videos are decomposed into keyframe captions that exhaustively encode stable visual context and residual captions that capture only temporally localized actions, motions, and changes. This is claimed to preserve fine-grained evidence while reducing redundancy compared to holistic or segment-wise captions. The authors introduce VidCapQA, a caption-then-QA benchmark consisting of 1,000 questions across 14 capability dimensions, to quantify fidelity. Experiments assert that CodecCap significantly outperforms direct captioning using the same VLMs; the method is further used to construct the CodecVDC-100K dataset providing anchor, residual, scene-level, and video-level supervision.
Significance. If the empirical gains hold after addressing verification gaps, the work supplies a practical decomposition strategy for high-fidelity video-language supervision that could benefit downstream tasks such as video QA and retrieval. The VidCapQA benchmark offers a new diagnostic tool for caption completeness beyond standard metrics, and the released CodecVDC-100K dataset constitutes a concrete resource for training denser models.
major comments (1)
- [Abstract and framework description (codec analogy paragraph)] Abstract and framework description (codec analogy paragraph): the claim that the keyframe+residual split preserves all visual evidence without gaps or omissions is load-bearing for attributing VidCapQA gains to residual modeling rather than increased prompt length or VLM call count. No mechanism, ablation, or explicit check is described that verifies the combined captions answer every question missed by direct captions; if a localized action is misclassified as stable (or vice versa), the fidelity advantage disappears.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed feedback. We address the major comment below.
read point-by-point responses
-
Referee: Abstract and framework description (codec analogy paragraph): the claim that the keyframe+residual split preserves all visual evidence without gaps or omissions is load-bearing for attributing VidCapQA gains to residual modeling rather than increased prompt length or VLM call count. No mechanism, ablation, or explicit check is described that verifies the combined captions answer every question missed by direct captions; if a localized action is misclassified as stable (or vice versa), the fidelity advantage disappears.
Authors: We agree that the preservation claim is central and that an explicit verification mechanism would strengthen the attribution of gains specifically to the residual modeling. The framework is designed so that keyframe captions exhaustively describe stable context while residual captions target only localized temporal changes, ensuring by construction that the union covers the full visual evidence when the assignment is accurate. The VidCapQA results provide indirect empirical support through higher answer rates, but we acknowledge the manuscript does not include a direct check (e.g., per-question coverage analysis or misclassification ablation). In the revision we will add such an analysis, including quantitative comparison of question coverage between direct captions and the keyframe+residual union, plus discussion of potential assignment errors. revision: yes
Circularity Check
No circularity: empirical framework with independent benchmark results
full rationale
The paper introduces CodecCap as an analogy-based framework (keyframe + residual captions) and evaluates it via the new VidCapQA benchmark and direct comparisons to baseline VLM captioning. No equations, fitted parameters, self-citations, or derivations are present in the provided text. The central claim rests on experimental deltas rather than any reduction to inputs by construction. The codec analogy is presented as a modeling choice, not a derived result. This is a standard non-circular empirical proposal.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Noah: Benchmarking narrative prior driven hallucination and omission in video large language models.arXiv preprint arXiv:2511.06475. Boyi Li, Ligeng Zhu, Ran Tian, Shuhan Tan, Yuxiao Chen, Yao Lu, Yin Cui, Sushant Veer, Max Ehrlich, Jonah Philion, and 1 others. 2024a. Wolf: Captioning everything with a world summarization framework. InWorkshop on Video-La...
-
[2]
Hallucination localization in video captioning. arXiv preprint arXiv:2510.25225. Ziqi Pang and Yu-Xiong Wang. 2025. Mr. video:" mapreduce" is the principle for long video under- standing.arXiv preprint arXiv:2504.16082. Kishore Papineni, Salim Roukos, Todd Ward, and Wei- Jing Zhu. 2002. Bleu: a method for automatic evalu- ation of machine translation. InP...
-
[3]
arXiv preprint arXiv:2512.03405 (2025) 4
Longvideobench: A benchmark for long- context interleaved video-language understanding. Advances in Neural Information Processing Systems, 37:28828–28857. Jiangtao Wu, Shihao Li, Zhaozhou Bian, Jialu Chen, Runzhe Wen, An Ping, Yiwen He, Jiakai Wang, Yuanxing Zhang, and Jiaheng Liu. 2025. Vidic: Video difference captioning.arXiv preprint arXiv:2512.03405. ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.