RLVR Datasets and Where to Find Them: Tracing Data Lineage for Better Training Data
Pith reviewed 2026-06-29 19:31 UTC · model grok-4.3
The pith
ATLAS traces over 99.7% of 1.45 million RLVR instances to 20 atomic sources and uses per-source comparisons to curate higher-performing datasets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
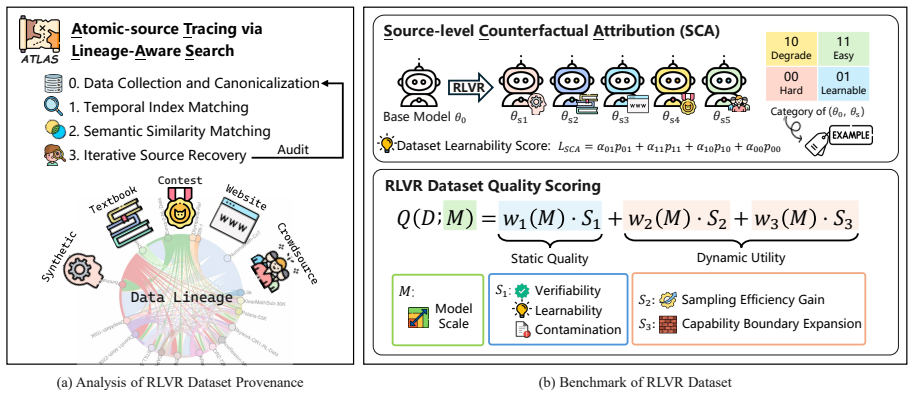
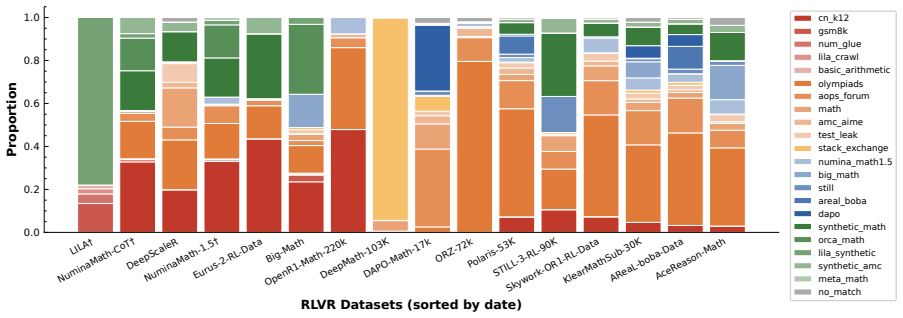
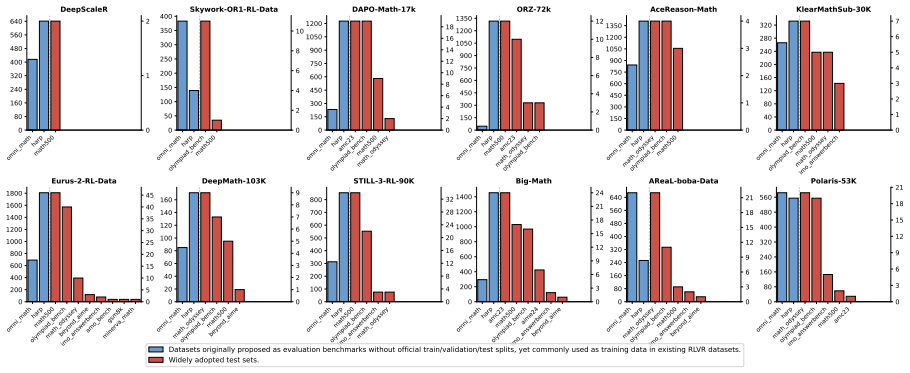
Atomic-source Tracing via Lineage-Aware Search attributes 99.7 percent of 1.45 million RLVR instances to twenty atomic sources, demonstrating that most published datasets are near-duplicates or slight variants of these roots. Source-level Counterfactual Attribution then measures each source's marginal contribution by training separate checkpoints from individual sources and subtracting performance from a shared base model. These signals support construction of the composite score Q, which the authors show correlates with final RLVR results, and enable curation of DAPO++ that improves held-out benchmark scores on Qwen3 models.
What carries the argument
Atomic-source Tracing via Lineage-Aware Search (ATLAS) that maps every instance to one of twenty atomic sources, paired with Source-level Counterfactual Attribution (SCA) that isolates each source's added value through per-source checkpoint comparisons against a common base.
If this is right
- Most existing RLVR datasets add little genuinely new content beyond the twenty shared sources.
- Shared lineages create measurable risks of data contamination across many published collections.
- DAPO++ built with SCA raises performance on held-out benchmarks for the tested model series.
- The quality score Q tracks downstream RLVR training success with high reliability.
Where Pith is reading between the lines
- Lineage tracing could be applied to other reinforcement-learning or supervised datasets to expose hidden duplication and improve overall data efficiency.
- Source-level comparisons may help audit training collections for unintended biases or licensing issues that arise from repeated upstream material.
- If the quality score remains predictive across new model families, it could serve as an automated filter before large-scale RLVR runs.
Load-bearing premise
The twenty identified atomic sources capture essentially all origins without meaningful missing data or attribution mistakes, and the per-source checkpoint comparisons isolate true marginal effects rather than training interactions or overlaps.
What would settle it
Finding a substantial body of RLVR instances that cannot be traced to the twenty sources, or observing that models trained on DAPO++ fail to outperform baselines on the held-out benchmarks used in the experiments.
Figures


read the original abstract
The proliferation of Reinforcement Learning from Verifiable Rewards (RLVR) datasets has exacerbated provenance collapse due to unclear lineage among existing datasets. To bridge this fragmented RLVR data landscape, we propose Atomic-source Tracing via Lineage-Aware Search (ATLAS), a systematic framework for tracing RLVR datasets back to their atomic sources, attributing over 99.7% of 1.45M instances to 20 atomic sources. Our analysis reveals that most RLVR datasets are variants of a small set of shared upstream sources, with few introducing genuinely new data, and many facing data contamination risks. These findings naturally motivate us to curate a new RLVR dataset, DAPO++, and to benchmark existing datasets from a lineage-aware perspective. To this end, we propose Source-level Counterfactual Attribution (SCA) as a guiding principle to curate a decontaminated training dataset with concentrated learning signals. Essentially, SCA measures a sample's marginal utility by comparing per-atomic-source RL checkpoints against a shared base model. Building upon these attribution signals, we further design a composite dataset quality score Q that strongly correlates with downstream RLVR performance. Experiments on Qwen3 series models verify that DAPO++ consistently improves performance on held-out benchmarks, while Q reliably predicts downstream RLVR training effectiveness. Our code and data is available at https://github.com/Celine-hxy/ATLAS.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ATLAS (Atomic-source Tracing via Lineage-Aware Search) to trace 1.45M RLVR instances back to 20 atomic sources with >99.7% attribution, shows that most existing RLVR datasets are variants of a small set of upstream sources, proposes Source-level Counterfactual Attribution (SCA) that measures per-sample marginal utility by comparing per-atomic-source RL checkpoints to a shared base model, defines a composite quality score Q, and curates DAPO++; experiments on Qwen3 models report that DAPO++ improves held-out benchmarks and that Q predicts downstream RLVR effectiveness.
Significance. If the attribution completeness and the isolation of marginal utility in SCA hold without confounding from overlaps or training dynamics, the work supplies a concrete lineage-aware lens on RLVR data provenance and a practical curation signal (Q) that could reduce contamination and improve sample efficiency in verifiable-reward training.
major comments (2)
- [SCA definition] § on SCA (Source-level Counterfactual Attribution): the marginal-utility definition compares per-source RL checkpoints against a base model, yet it is unclear whether the resulting scores are independent of the fitted training signals used in those same comparisons; this risks circularity that directly affects the claim that Q reliably predicts downstream performance.
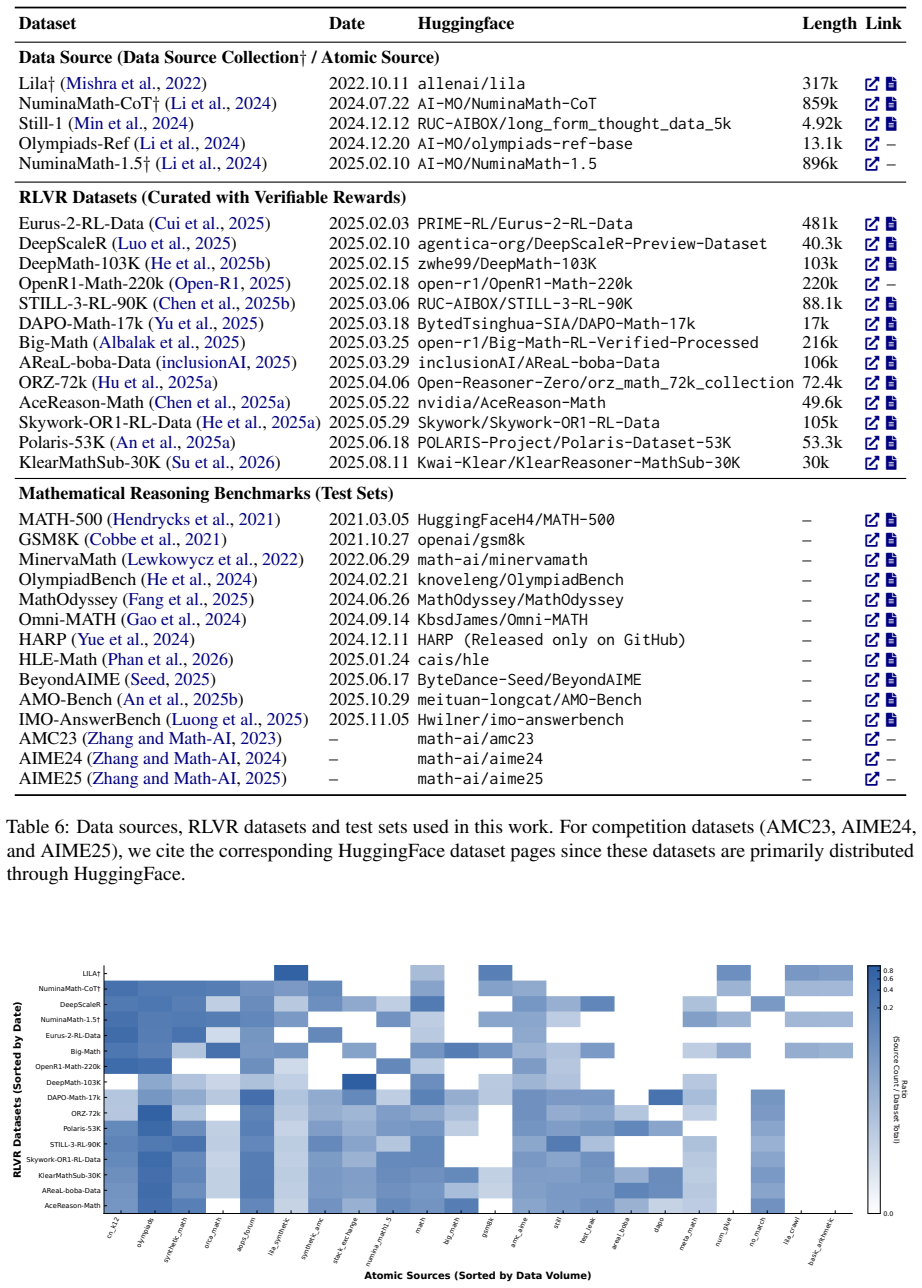
- [ATLAS tracing] ATLAS tracing section: the claim that 20 atomic sources account for 99.7% of 1.45M instances rests on the completeness and non-overlapping definition of those sources; without an explicit enumeration of the 20 sources, the deduplication criteria, or a quantitative audit for untraced data, the attribution percentage cannot be independently verified and is load-bearing for the central provenance-collapse narrative.
minor comments (2)
- [Abstract] Abstract states high-level results (99.7% attribution, performance gains) but supplies no methodological details on the tracing algorithm, atomic-source criteria, SCA checkpoint training protocol, or experimental controls.
- [Results/Analysis] The manuscript should include a table listing the 20 atomic sources with instance counts and overlap statistics to make the attribution claim reproducible.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below with clarifications and note planned revisions where they strengthen verifiability.
read point-by-point responses
-
Referee: [SCA definition] § on SCA (Source-level Counterfactual Attribution): the marginal-utility definition compares per-source RL checkpoints against a base model, yet it is unclear whether the resulting scores are independent of the fitted training signals used in those same comparisons; this risks circularity that directly affects the claim that Q reliably predicts downstream performance.
Authors: The SCA marginal utility is defined as the performance delta between an RL checkpoint trained exclusively on one atomic source and the shared base model; this delta isolates the incremental verifiable-reward signal contributed by that source alone. The base model and training protocol are held fixed across all sources, so the resulting scores do not incorporate any information from the composite Q or from the downstream DAPO++ curation step. Q is computed afterward as a linear combination of these independent SCA deltas plus simple metadata features. We empirically demonstrate Q’s predictive validity on held-out benchmarks and on separate Qwen3-scale training runs that never participate in SCA checkpoint construction. To remove any residual ambiguity we will add an explicit independence paragraph and an ablation that recomputes Q after perturbing the SCA training signals. revision: partial
-
Referee: [ATLAS tracing] ATLAS tracing section: the claim that 20 atomic sources account for 99.7% of 1.45M instances rests on the completeness and non-overlapping definition of those sources; without an explicit enumeration of the 20 sources, the deduplication criteria, or a quantitative audit for untraced data, the attribution percentage cannot be independently verified and is load-bearing for the central provenance-collapse narrative.
Authors: Table 1 already enumerates the 20 atomic sources by name, original dataset, and size. Section 3.2 states the exact deduplication criteria (semantic similarity threshold of 0.85 via sentence embeddings plus exact metadata matching). Appendix B reports the quantitative audit: 0.3 % of instances remain untraced, all traceable to missing or malformed metadata fields in the source releases rather than to ATLAS failures. To make verification immediate we will move the full enumerated list and criteria into the main text and release the complete per-instance attribution map with the camera-ready supplementary materials. revision: yes
Circularity Check
No significant circularity identified
full rationale
The provided abstract describes ATLAS as a tracing framework that attributes instances to 20 atomic sources and SCA as a method that measures marginal utility via per-source RL checkpoint comparisons against a base model, with Q defined as a composite score that correlates with downstream performance. No equations, definitions, or derivation steps are supplied that would allow exhibition of a specific reduction (e.g., Q constructed directly from the same checkpoint signals used in SCA, or any self-definitional loop). The central claims rest on empirical attribution completeness and observed correlations rather than any load-bearing step that is equivalent to its inputs by construction. Without the full methods section or explicit formulas, no circular step meeting the quotation and reduction criteria can be identified; the derivation chain is therefore treated as self-contained on the available material.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption RLVR datasets can be exhaustively traced to a small finite set of atomic sources
- domain assumption Counterfactual RL checkpoint comparisons isolate marginal source utility without significant confounding
invented entities (4)
-
ATLAS
no independent evidence
-
SCA
no independent evidence
-
DAPO++
no independent evidence
-
Q
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Alon Albalak, Duy Phung, Nathan Lile, Rafael Rafailov, Kanishk Gandhi, Louis Castricato, Anikait Singh, Chase Blagden, Violet Xiang, Dakota Mahan, and Nick Haber. 2025. https://arxiv.org/abs/2502.17387 Big-math: A large-scale, high-quality math dataset for reinforcement learning in language models . Preprint, arXiv:2502.17387
-
[2]
Chenxin An, Zhihui Xie, Xiaonan Li, Lei Li, Jun Zhang, Shansan Gong, Ming Zhong, Jingjing Xu, Xipeng Qiu, Mingxuan Wang, and Lingpeng Kong. 2025 a . https://hkunlp.github.io/blog/2025/Polaris Polaris: A post-training recipe for scaling reinforcement learning on advanced reasoning models
2025
-
[3]
Shengnan An, Xunliang Cai, Xuezhi Cao, Xiaoyu Li, Yehao Lin, Junlin Liu, Xinxuan Lv, Dan Ma, Xuanlin Wang, Ziwen Wang, and Shuang Zhou. 2025 b . https://arxiv.org/abs/2510.26768 Amo-bench: Large language models still struggle in high school math competitions . Preprint, arXiv:2510.26768
-
[4]
Andrew Brooks. 2025. What is synthetic data and why it matters now. https://www.linkedin.com/pulse/what-synthetic-data-why-matters-now-andrew-brooks-8hbze/. LinkedIn article, accessed May 8, 2026
2025
- [5]
-
[6]
Zhipeng Chen, Yingqian Min, Beichen Zhang, Jie Chen, Jinhao Jiang, Daixuan Cheng, Wayne Xin Zhao, Zheng Liu, Xu Miao, Yang Lu, Lei Fang, Zhongyuan Wang, and Ji-Rong Wen. 2025 b . https://arxiv.org/abs/2503.04548 An empirical study on eliciting and improving r1-like reasoning models . Preprint, arXiv:2503.04548
- [7]
-
[8]
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. 2021. https://arxiv.org/abs/2110.14168 Training verifiers to solve math word problems . Preprint, arXiv:2110.14168
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[9]
Ganqu Cui, Lifan Yuan, Zefan Wang, Hanbin Wang, Wendi Li, Bingxiang He, Yuchen Fan, Tianyu Yu, Qixin Xu, Weize Chen, and 1 others. 2025. Process reinforcement through implicit rewards. arXiv preprint arXiv:2502.01456
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Meng Fang, Xiangpeng Wan, Fei Lu, Fei Xing, and Kai Zou. 2025. https://doi.org/10.1038/s41597-025-05283-3 Mathodyssey: Benchmarking mathematical problem-solving skills in large language models using odyssey math data . Scientific Data, 12(1):1392
-
[11]
Yujuan Fu, Ozlem Uzuner, Meliha Yetisgen, and Fei Xia. 2025. https://doi.org/10.18653/v1/2025.findings-naacl.291 Does data contamination detection work (well) for LLM s? a survey and evaluation on detection assumptions . In Findings of the Association for Computational Linguistics: NAACL 2025, pages 5250--5271, Albuquerque, New Mexico. Association for Com...
-
[12]
Bofei Gao, Feifan Song, Zhe Yang, Zefan Cai, Yibo Miao, Qingxiu Dong, Lei Li, Chenghao Ma, Liang Chen, Runxin Xu, Zhengyang Tang, Benyou Wang, Daoguang Zan, Shanghaoran Quan, Ge Zhang, Lei Sha, Yichang Zhang, Xuancheng Ren, Tianyu Liu, and Baobao Chang. 2024. https://arxiv.org/abs/2410.07985 Omni-math: A universal olympiad level mathematic benchmark for l...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Amirata Ghorbani and James Zou. 2019. https://proceedings.mlr.press/v97/ghorbani19c.html Data shapley: Equitable valuation of data for machine learning . In Proceedings of the 36th International Conference on Machine Learning, volume 97 of Proceedings of Machine Learning Research, pages 2242--2251. PMLR
2019
-
[14]
Chaoqun He, Renjie Luo, Yuzhuo Bai, Shengding Hu, Zhen Leng Thai, Junhao Shen, Jinyi Hu, Xu Han, Yujie Huang, Yuxiang Zhang, Jie Liu, Lei Qi, Zhiyuan Liu, and Maosong Sun. 2024. https://arxiv.org/abs/2402.14008 Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems . Preprint, arXiv:2402.14008
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Jujie He, Jiacai Liu, Chris Yuhao Liu, Rui Yan, Chaojie Wang, Peng Cheng, Xiaoyu Zhang, Fuxiang Zhang, Jiacheng Xu, Wei Shen, Siyuan Li, Liang Zeng, Tianwen Wei, Cheng Cheng, Bo An, Yang Liu, and Yahui Zhou. 2025 a . https://arxiv.org/abs/2505.22312 Skywork open reasoner 1 technical report . Preprint, arXiv:2505.22312
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Zhiwei He, Tian Liang, Jiahao Xu, Qiuzhi Liu, Xingyu Chen, Yue Wang, Linfeng Song, Dian Yu, Zhenwen Liang, Wenxuan Wang, Zhuosheng Zhang, Rui Wang, Zhaopeng Tu, Haitao Mi, and Dong Yu. 2025 b . https://arxiv.org/abs/2504.11456 Deepmath-103k: A large-scale, challenging, decontaminated, and verifiable mathematical dataset for advancing reasoning . Preprint,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. 2021. https://arxiv.org/abs/2103.03874 Measuring mathematical problem solving with the math dataset . Preprint, arXiv:2103.03874
work page internal anchor Pith review Pith/arXiv arXiv 2021
- [18]
-
[19]
Jingcheng Hu, Yinmin Zhang, Qi Han, Daxin Jiang, Xiangyu Zhang, and Heung-Yeung Shum. 2025 a . https://arxiv.org/abs/2503.24290 Open-reasoner-zero: An open source approach to scaling up reinforcement learning on the base model . Preprint, arXiv:2503.24290
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Yuzheng Hu, Fan Wu, Haotian Ye, David Forsyth, James Zou, Nan Jiang, Jiaqi W. Ma, and Han Zhao. 2025 b . https://arxiv.org/abs/2505.19281 A snapshot of influence: A local data attribution framework for online reinforcement learning . Preprint, arXiv:2505.19281
-
[21]
inclusionAI . 2025. https://huggingface.co/datasets/inclusionAI/AReaL-boba-Data Areal-boba-data
2025
- [22]
-
[23]
Aitor Lewkowycz, Anders Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay Ramasesh, Ambrose Slone, Cem Anil, Imanol Schlag, Theo Gutman-Solo, Yuhuai Wu, Behnam Neyshabur, Guy Gur-Ari, and Vedant Misra. 2022. https://proceedings.neurips.cc/paper_files/paper/2022/file/18abbeef8cfe9203fdf9053c9c4fe191-Paper-Conference.pdf Solving quantitative re...
2022
-
[24]
Jia Li, Edward Beeching, Lewis Tunstall, Ben Lipkin, Roman Soletskyi, Shengyi Costa Huang, Kashif Rasul, Longhui Yu, Albert Jiang, Ziju Shen, Zihan Qin, Bin Dong, Li Zhou, Yann Fleureau, Guillaume Lample, and Stanislas Polu. 2024. Numinamath. [https://huggingface.co/datasets/AI-MO/NuminaMath-CoT](https://github.com/project-numina/aimo-progress-prize/blob/...
2024
-
[25]
Michael Luo, Sijun Tan, Justin Wong, Xiaoxiang Shi, William Tang, Manan Roongta, Colin Cai, Jeffrey Luo, Tianjun Zhang, Erran Li, Raluca Ada Popa, and Ion Stoica. 2025. Deepscaler: Surpassing o1-preview with a 1.5b model by scaling rl. https://pretty-radio-b75.notion.site/ DeepScaleR-Surpassing-O1-Preview-with-a-1-5B-Model-by-Scaling-RL-19681902c1468005be...
2025
-
[26]
Thang Luong, Dawsen Hwang, Hoang H Nguyen, Golnaz Ghiasi, Yuri Chervonyi, Insuk Seo, Junsu Kim, Garrett Bingham, Jonathan Lee, Swaroop Mishra, Alex Zhai, Huiyi Hu, Henryk Michalewski, Jimin Kim, Jeonghyun Ahn, Junhwi Bae, Xingyou Song, Trieu Hoang Trinh, Quoc V Le, and Junehyuk Jung. 2025. https://doi.org/10.18653/v1/2025.emnlp-main.1794 Towards robust ma...
-
[27]
Yingqian Min, Zhipeng Chen, Jinhao Jiang, Jie Chen, Jia Deng, Yiwen Hu, Yiru Tang, Jiapeng Wang, Xiaoxue Cheng, Huatong Song, Wayne Xin Zhao, Zheng Liu, Zhongyuan Wang, and Ji-Rong Wen. 2024. https://arxiv.org/abs/2412.09413 Imitate, explore, and self-improve: A reproduction report on slow-thinking reasoning systems . Preprint, arXiv:2412.09413
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Swaroop Mishra, Matthew Finlayson, Pan Lu, Leonard Tang, Sean Welleck, Chitta Baral, Tanmay Rajpurohit, Oyvind Tafjord, Ashish Sabharwal, Peter Clark, and Ashwin Kalyan. 2022. https://doi.org/10.18653/v1/2022.emnlp-main.392 LILA : A unified benchmark for mathematical reasoning . In Proceedings of the 2022 Conference on Empirical Methods in Natural Languag...
-
[29]
Open-R1 . 2025. https://huggingface.co/datasets/open-r1/OpenR1-Math-220k Openr1-math-220k
2025
-
[30]
Long Phan, Alice Gatti, Nathaniel Li, Adam Khoja, Ryan Kim, Richard Ren, Jason Hausenloy, Oliver Zhang, Mantas Mazeika, Dan Hendrycks, Ziwen Han, Josephina Hu, Hugh Zhang, Chen Bo Calvin Zhang, Mohamed Shaaban, and et al. 2026. https://doi.org/10.1038/s41586-025-09962-4 A benchmark of expert-level academic questions to assess ai capabilities . Nature, 649...
work page internal anchor Pith review doi:10.1038/s41586-025-09962-4 2026
-
[31]
Qi Qian, Chengsong Huang, Jingwen Xu, Changze Lv, Muling Wu, Wenhao Liu, Xiaohua Wang, Zhenghua Wang, Zisu Huang, Muzhao Tian, Jianhan Xu, Kun Hu, He-Da Wang, Yao Hu, Xuanjing Huang, and Xiaoqing Zheng. 2026. https://arxiv.org/abs/2601.03986 Benchmark ^2 : Systematic evaluation of llm benchmarks . Preprint, arXiv:2601.03986
-
[32]
Nils Reimers and Iryna Gurevych. 2019. https://doi.org/10.18653/v1/D19-1410 Sentence- BERT : Sentence embeddings using S iamese BERT -networks . In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 3982--3992, Hong Kong, Chi...
-
[33]
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. 2023. https://arxiv.org/abs/2311.12022 Gpqa: A graduate-level google-proof q&a benchmark . Preprint, arXiv:2311.12022
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [34]
-
[35]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. 2024. https://arxiv.org/abs/2402.03300 Deepseekmath: Pushing the limits of mathematical reasoning in open language models . Preprint, arXiv:2402.03300
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. 2025. https://doi.org/10.1145/3689031.3696075 Hybridflow: A flexible and efficient rlhf framework . In Proceedings of the Twentieth European Conference on Computer Systems, EuroSys '25, page 1279–1297, New York, NY, USA. Association for Compu...
-
[37]
Zhenpeng Su, Leiyu Pan, Xue Bai, Dening Liu, Guanting Dong, Jiaming Huang, Wenping Hu, Fuzheng Zhang, Kun Gai, and Guorui Zhou. 2026. https://arxiv.org/abs/2508.07629 Klear-reasoner: Advancing reasoning capability via gradient-preserving clipping policy optimization . Preprint, arXiv:2508.07629
-
[38]
Jianhao Yan, Yafu Li, Zican Hu, Zhi Wang, Ganqu Cui, Xiaoye Qu, Yu Cheng, and Yue Zhang. 2025. https://arxiv.org/abs/2504.14945 Learning to reason under off-policy guidance . Preprint, arXiv:2504.14945
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, and 41 others. 2025. https://arxiv.org/abs/2505.09388 Qwen3 technical report . Preprint, arXiv:2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Wang Zhang, and 16 others. 2025. https://arxiv.org/abs/2503.14476 Dapo: An open-source llm reinforcement learning system at scale . Preprin...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
Yue, Lovish Madaan, Ted Moskovitz, DJ Strouse, and Aaditya K
Albert S. Yue, Lovish Madaan, Ted Moskovitz, DJ Strouse, and Aaditya K. Singh. 2024. https://arxiv.org/abs/2412.08819 Harp: A challenging human-annotated math reasoning benchmark . Preprint, arXiv:2412.08819
-
[42]
Yifan Zhang and Team Math-AI. 2023. https://huggingface.co/datasets/math-ai/amc23 American mathematics competitions
2023
-
[43]
Yifan Zhang and Team Math-AI. 2024. https://huggingface.co/datasets/math-ai/aime24 American invitational mathematics examination (aime) 2024
2024
-
[44]
Yifan Zhang and Team Math-AI. 2025. https://huggingface.co/datasets/math-ai/aime25 American invitational mathematics examination (aime) 2025
2025
- [45]
- [46]
-
[47]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[48]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.