Convergence of Spectral Descent for Non-smooth Optimization
Pith reviewed 2026-06-29 19:26 UTC · model grok-4.3
The pith
Spectral Descent and Truncated Spectral Descent achieve global linear convergence in non-smooth convex optimization under convexity, Lipschitz continuity, and sharpness conditions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
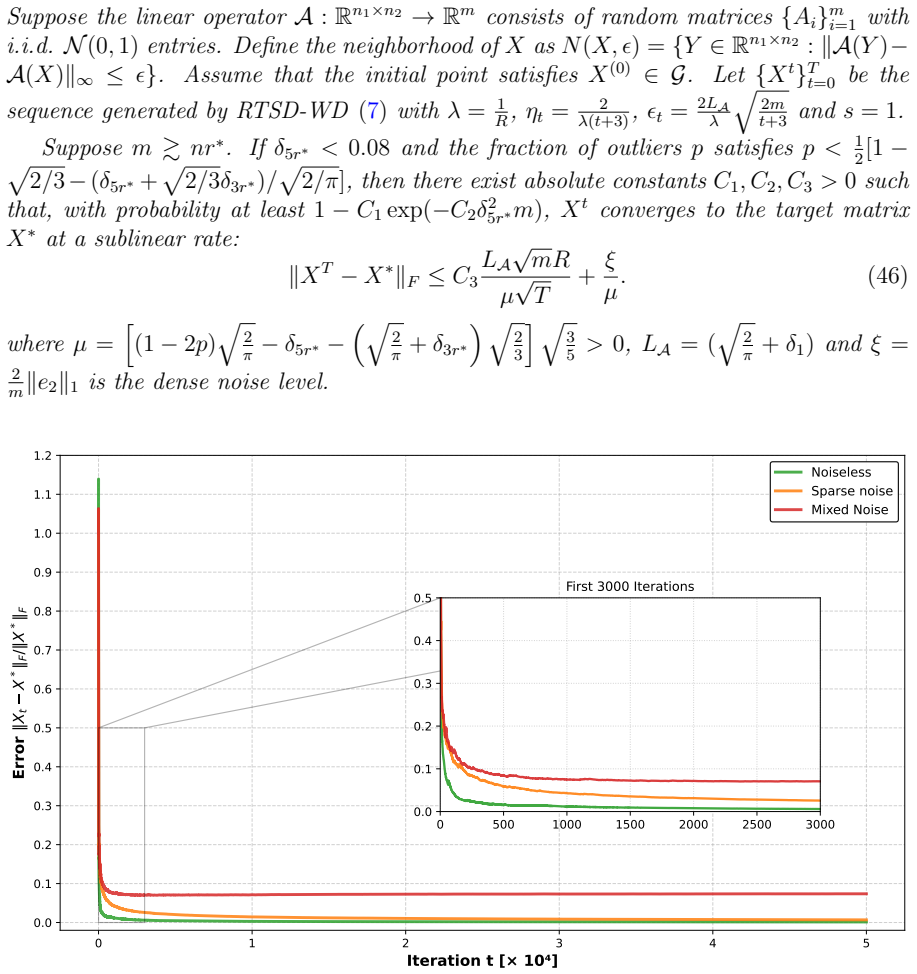
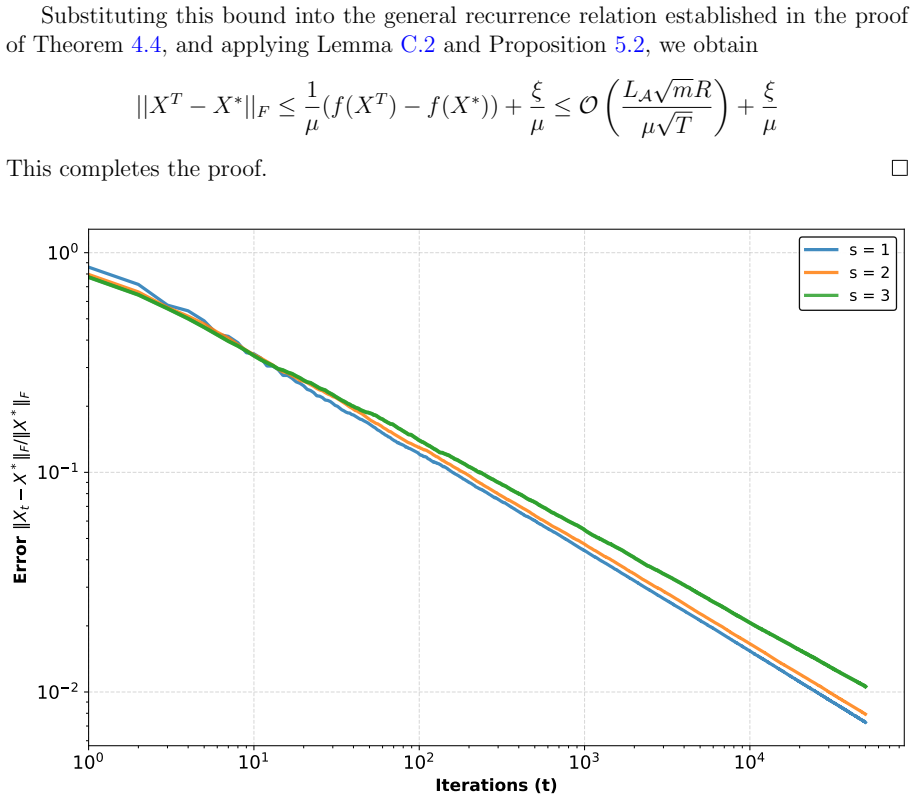
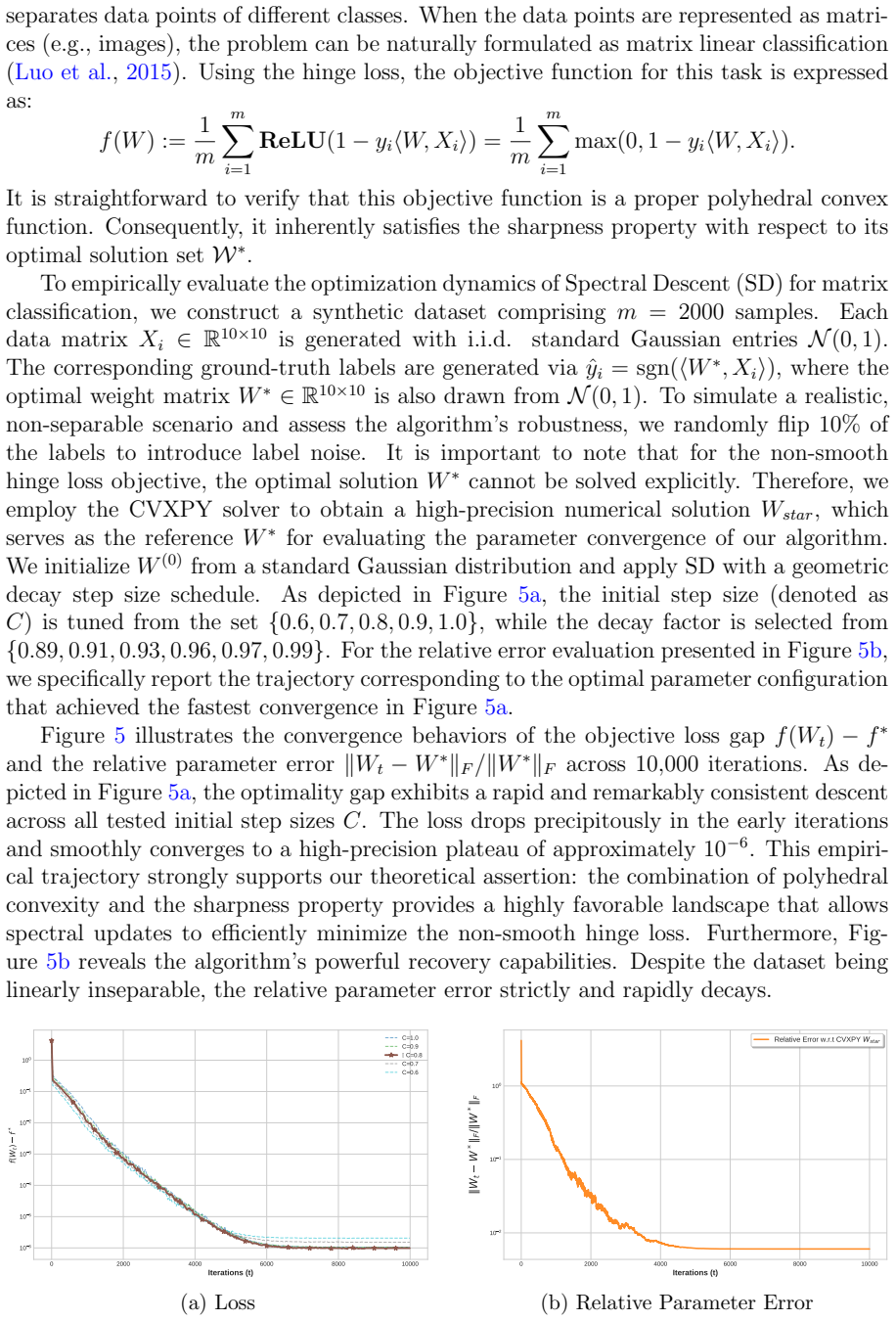
Under convexity, Lipschitz continuity, and sharpness conditions, both Spectral Descent and Truncated Spectral Descent exhibit global linear convergence in non-smooth convex problems. Regularized variants with decoupled weight decay obtain sublinear convergence guarantees through their explicit connection to Frank-Wolfe methods. The same analysis supplies rigorous recovery guarantees for robust low-rank matrix recovery under mixed sparse and dense noise.
What carries the argument
Spectral Descent (SD) and Truncated Spectral Descent (TSD), whose iteration rules produce linear convergence rates when the objective satisfies convexity, Lipschitz continuity, and sharpness.
If this is right
- Global linear convergence holds for both SD and TSD whenever the three conditions are met.
- Regularized versions equipped with decoupled weight decay converge sublinearly via the Frank-Wolfe connection.
- The framework directly yields recovery guarantees for robust low-rank matrix recovery under mixed sparse and dense noise.
- Numerical experiments are expected to confirm the predicted rates and practical performance on the matrix recovery task.
Where Pith is reading between the lines
- The linear-rate result could be checked on other non-smooth convex objectives, such as certain piecewise-linear losses, to see whether the same sharpness parameter controls the speed.
- The Frank-Wolfe link suggests that spectral updates might be hybridized with projection steps for constrained non-smooth problems.
- If the sharpness condition can be verified or relaxed in specific applications, the theory would predict faster practical behavior than standard subgradient methods.
Load-bearing premise
The sharpness conditions, together with the precise non-smooth convex formulation, are what permit the linear rate to be derived.
What would settle it
A concrete non-smooth convex objective that satisfies convexity, Lipschitz continuity, and the sharpness condition yet shows Spectral Descent failing to converge at the predicted linear rate would disprove the claim.
Figures

read the original abstract
The Muon optimizer has recently demonstrated remarkable empirical success in training large language models. However, the theoretical understanding of its mechanisms remains limited. Current convergence guarantees for Muon rely heavily on smoothness assumptions, leaving its non-smooth convergence behavior largely unexplored. In this work, we take a step toward bridging this gap by investigating Spectral Descent (SD), a simplified variant of Muon, together with its truncated counterpart, Truncated Spectral Descent (TSD). Under convexity, Lipschitz continuity, and sharpness conditions, we establish global linear convergence for both SD and TSD in non-smooth convex formulations. We also study regularized variants equipped with decoupled weight decay and derive sublinear convergence guarantees through their connection with Frank-Wolfe methods. Finally, we apply our theoretical framework to robust low-rank matrix recovery under mixed sparse and dense noise regimes and provide rigorous recovery guarantees. Numerical experiments support the theoretical findings and demonstrate the effectiveness of Muon-type methods for non-smooth optimization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies Spectral Descent (SD) and its truncated variant (TSD) as simplified forms of the Muon optimizer. Under convexity, Lipschitz continuity, and sharpness conditions it claims global linear convergence for non-smooth convex problems. Regularized versions with decoupled weight decay are shown to enjoy sublinear rates via a connection to Frank-Wolfe methods. The framework is applied to robust low-rank matrix recovery under mixed sparse/dense noise, yielding recovery guarantees, and the claims are supported by numerical experiments.
Significance. If the stated linear rates hold under the listed assumptions, the work would supply the first non-smooth convergence theory for Muon-type methods, which is relevant for large-scale training. The Frank-Wolfe link and the matrix-recovery application are natural extensions. The significance is tempered by the fact that the sharpness conditions appear to be the key load-bearing hypothesis whose realism and necessity cannot be assessed without the full derivations.
major comments (2)
- [Abstract] Abstract (convergence guarantees paragraph): the global linear rate is asserted under 'sharpness conditions' whose precise statement, relation to the non-smooth objective, and verification that they are not vacuous for the target problem class are not visible; this is the central assumption enabling the linear rate and must be inspected for restrictiveness.
- [Regularized variants] Regularized variants section: the sublinear guarantee is obtained 'through their connection with Frank-Wolfe methods'; it is unclear whether the rate is independently derived or simply inherits a known Frank-Wolfe bound, which would affect the novelty claim.
minor comments (1)
- The abstract states that numerical experiments 'support the theoretical findings' but supplies no information on problem dimensions, noise levels, or baseline comparisons; these details belong in the main text or appendix.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. Below we respond point-by-point to the two major comments, proposing clarifications where they improve readability without altering the technical claims.
read point-by-point responses
-
Referee: [Abstract] Abstract (convergence guarantees paragraph): the global linear rate is asserted under 'sharpness conditions' whose precise statement, relation to the non-smooth objective, and verification that they are not vacuous for the target problem class are not visible; this is the central assumption enabling the linear rate and must be inspected for restrictiveness.
Authors: The abstract is intentionally concise. The precise (α, β)-sharpness condition is stated in Definition 3.1 of the full manuscript and is the standard notion used in non-smooth convex optimization (function-value gap controlled by distance to the solution set). Theorem 3.2 proves linear convergence of SD and TSD under convexity, L-Lipschitz continuity, and this sharpness. Section 5 explicitly verifies that the condition holds with concrete constants for the robust low-rank matrix recovery problem. We will revise the abstract to add a parenthetical reference to Definition 3.1 and the verification section. revision: yes
-
Referee: [Regularized variants] Regularized variants section: the sublinear guarantee is obtained 'through their connection with Frank-Wolfe methods'; it is unclear whether the rate is independently derived or simply inherits a known Frank-Wolfe bound, which would affect the novelty claim.
Authors: The O(1/k) rate is inherited from the classical Frank-Wolfe analysis once we establish that the regularized SD update with decoupled weight decay coincides with a single FW step on an equivalent lifted problem. The technical contribution is therefore the identification of this equivalence, which had not been observed for Muon-type methods. We do not claim a faster rate than FW. We will insert one clarifying sentence in the section stating that the rate follows directly from the known FW bound via the newly established connection. revision: partial
Circularity Check
No significant circularity detected
full rationale
The abstract states global linear convergence under convexity, Lipschitz continuity, and sharpness conditions for SD and TSD, plus sublinear rates for regularized variants via Frank-Wolfe connection, and recovery guarantees for matrix recovery. No full manuscript equations, proofs, or self-citations are provided in the visible text that would allow identification of any reduction by construction (self-definitional, fitted-input prediction, or load-bearing self-citation). The derivation chain cannot be walked to exhibit equivalence to inputs, so the result is treated as self-contained against the stated assumptions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption convexity, Lipschitz continuity, and sharpness conditions
Reference graph
Works this paper leans on
-
[1]
Dion: Distributed orthonormalized updates
Kwangjun Ahn, Byron Xu, Natalie Abreu, Ying Fan, Gagik Magakyan, Pratyusha Sharma, Zheng Zhan, and John Langford. Dion: Distributed orthonormalized updates. arXiv:2504.05295,
-
[2]
The Polar Express: Optimal Matrix Sign Methods and Their Application to the Muon Algorithm
Noah Amsel, David Persson, Christopher Musco, and Robert M Gower. The polar ex- press: Optimal matrix sign methods and their application to the Muon algorithm. arXiv:2505.16932,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
ASGO: Adaptive structured gradient optimization.arXiv:2503.20762,
Kang An, Yuxing Liu, Rui Pan, Yi Ren, Shiqian Ma, Donald Goldfarb, and Tong Zhang. ASGO: Adaptive structured gradient optimization.arXiv:2503.20762,
-
[4]
Old Optimizer, New Norm: An Anthology
28 Jeremy Bernstein and Laker Newhouse. Old optimizer, new norm: An anthology. arXiv:2409.20325,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Spectral gradient descent mitigates anisotropy-driven misalignment: A case study in phase retrieval
Guillaume Braun, Han Bao, Wei Huang, and Masaaki Imaizumi. Spectral gradient descent mitigates anisotropy-driven misalignment: A case study in phase retrieval. arXiv:2601.22652,
-
[6]
Language models are few-shot learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. InAdvances in Neural Information Processing Systems, volume 33, pages 1877–1901,
1901
-
[7]
Muon optimizes under spectral norm constraints
Lizhang Chen, Jonathan Li, and Qiang Liu. Muon optimizes under spectral norm con- straints.arXiv:2506.15054,
-
[8]
Lijun Ding and Alex L Wang. Sharpness and well-conditioning of nonsmooth convex formulations in statistical signal recovery.arXiv:2307.06873,
-
[9]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: A family of highly capable multimodal models.arXiv:2312.11805,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
The Implicit Bias of Adam and Muon on Smooth Homogeneous Neural Networks
Eitan Gronich and Gal Vardi. The implicit bias of Adam and Muon on smooth homoge- neous neural networks.arXiv:2602.16340,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv:1412.6980,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Ky Fan Norms and Beyond: Dual Norms and Combinations for Matrix Optimization
Alexey Kravatskiy, Ivan Kozyrev, Nikolai Kozlov, Alexander Vinogradov, Daniil Merkulov, and Ivan Oseledets. The Ky Fan norms and beyond: Dual norms and combinations for matrix optimization.arXiv:2512.09678,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
30 Tim Tsz-Kit Lau, Qi Long, and Weijie Su. PolarGrad: A class of matrix-gradient opti- mizers from a unifying preconditioning perspective.arXiv:2505.21799,
-
[15]
Jichu Li, Xuan Tang, and Difan Zou
URLhttps://arxiv.org/abs/2502.02900. Jichu Li, Xuan Tang, and Difan Zou. The implicit bias of steepest descent with mini-batch stochastic gradient.arXiv:2602.11557,
-
[16]
Muon is Scalable for LLM Training
Jingyuan Liu, Jianlin Su, Xingcheng Yao, Zhejun Jiang, Guokun Lai, Yulun Du, Yidao Qin, Weixin Xu, Enzhe Lu, Junjie Yan, et al. Muon is scalable for LLM training. arXiv:2502.16982, 2025a. Liming Liu, Zhenghao Xu, Zixuan Zhang, Hao Kang, Zichong Li, Chen Liang, Weizhu Chen, and Tuo Zhao. Cosmos: A hybrid adaptive optimizer for memory-efficient train- ing o...
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Preconditioning benefits of spectral orthogonalization in Muon.arXiv:2601.13474,
Jianhao Ma, Yu Huang, Yuejie Chi, and Yuxin Chen. Preconditioning benefits of spectral orthogonalization in Muon.arXiv:2601.13474,
-
[18]
HTMuon: Improving Muon via Heavy-Tailed Spectral Correction
Tianyu Pang, Yujie Fang, Zihang Liu, Shenyang Deng, Lei Hsiung, Shuhua Yu, and Yaoqing Yang. HTMuon: Improving Muon via heavy-tailed spectral correction. arXiv:2603.10067,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Training Deep Learning Models with Norm-Constrained LMOs
Thomas Pethick, Wanyun Xie, Kimon Antonakopoulos, Zhenyu Zhu, Antonio Silveti- Falls, and Volkan Cevher. Training deep learning models with norm-constrained LMOs. arXiv:2502.07529,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Lions and Muons: Optimization via stochastic Frank-Wolfe.arXiv:2506.04192,
Maria-Eleni Sfyraki and Jun-Kun Wang. Lions and Muons: Optimization via stochastic Frank-Wolfe.arXiv:2506.04192,
-
[21]
Practical efficiency of Muon for pretraining.arXiv:2505.02222,
Ishaan Shah, Anthony M Polloreno, Karl Stratos, Philip Monk, Adarsh Chaluvaraju, An- drew Hojel, Andrew Ma, Anil Thomas, Ashish Tanwer, Darsh J Shah, et al. Practical efficiency of Muon for pretraining.arXiv:2505.02222,
-
[22]
On the Convergence Analysis of Muon
Wei Shen, Ruichuan Huang, Minhui Huang, Cong Shen, and Jiawei Zhang. On the convergence analysis of Muon.arXiv:2505.23737,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
AdaMuon: Adaptive Muon optimizer
Chongjie Si, Debing Zhang, and Wei Shen. AdaMuon: Adaptive Muon optimizer. arXiv:2507.11005,
-
[24]
Muon optimizer accelerates grokking
Amund Tveit, Bjørn Remseth, and Arve Skogvold. Muon optimizer accelerates grokking. arXiv:2504.16041,
-
[25]
Conda: Column-normalized Adam for training large language models faster.arXiv:2509.24218,
Junjie Wang, Pan Zhou, Yiming Dong, Huan Li, Jia Li, Xun Zhou, Qicheng Lao, Cong Fang, and Zhouchen Lin. Conda: Column-normalized Adam for training large language models faster.arXiv:2509.24218,
-
[26]
Manifold constrained steepest descent.arXiv:2601.21487,
Kaiwei Yang and Lexiao Lai. Manifold constrained steepest descent.arXiv:2601.21487,
-
[27]
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Aohan Zeng, Xin Lv, Qinkai Zheng, Zhenyu Hou, Bin Chen, Chengxing Xie, Cunxiang Wang, Da Yin, Hao Zeng, Jiajie Zhang, et al. GLM-4.5: Agentic, reasoning, and coding (ARC) foundation models.arXiv:2508.06471,
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
AdaGrad meets Muon: Adaptive stepsizes for orthogonal updates.arXiv:2509.02981,
Minxin Zhang, Yuxuan Liu, and Hayden Schaeffer. AdaGrad meets Muon: Adaptive stepsizes for orthogonal updates.arXiv:2509.02981,
-
[29]
Adaptive algorithms for robust phase retrieval.arXiv:2409.19162,
32 Zhong Zheng, Necdet Serhat Aybat, Shiqian Ma, and Lingzhou Xue. Adaptive algorithms for robust phase retrieval.arXiv:2409.19162,
-
[30]
The inner optimal value (60) becomesf(r, γ) = R r (µγ− p s−γ 2 p r2 −µ 2)
Letγ:=c ⊤d. The inner optimal value (60) becomesf(r, γ) = R r (µγ− p s−γ 2 p r2 −µ 2). Since ∂f ∂r <0 and ∂f ∂γ >0, minimizingf(r, γ) requires maximizingrand minimizingγ. We trivially obtainr ∗ =L. Minimizingγequates to solvingγ ∗ = min ∥d∥2=1,d∈K c⊤d, whereKis the cone of non-increasing non-negative vectors. Applying the variable changey=d/(c ⊤d), this i...
1958
-
[31]
By the Mean Value Theorem, there exists some pointZon the open segment (X, Y) such that f(Y)−f(X) =⟨Y−X,G Z⟩.(61) Here,G Z ∈∂f(Z) is a subgradient atZ
for convex Lipschitz functions. By the Mean Value Theorem, there exists some pointZon the open segment (X, Y) such that f(Y)−f(X) =⟨Y−X,G Z⟩.(61) Here,G Z ∈∂f(Z) is a subgradient atZ. SinceZlies on the segment [X, Y] and ∥Y−X∥ F ≤ϵ, it follows geometrically that∥Z−X∥ F ≤ ∥Y−X∥ F ≤ϵ. Thus, Z∈N(X, ϵ), which implies thatG Z ∈T(X, ϵ). We can selectG=G Z. Subs...
1992
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.