IPIBench: Evaluating Interactive Proactive Intelligence of MLLMs under Continuous Streams
Pith reviewed 2026-06-29 18:22 UTC · model grok-4.3
The pith
Existing MLLMs show unstable proactive triggering and weak coordination in streaming video, which a training-free agent with control policies and temporal gating can stabilize.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
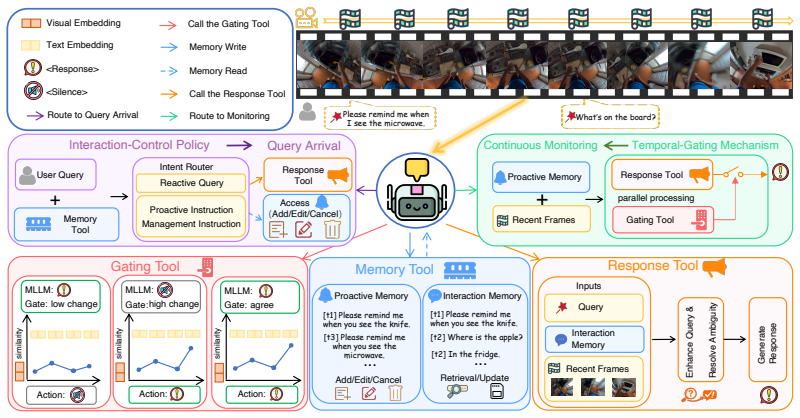
The paper claims that representative MLLMs exhibit two core limitations under continuous visual streams: unstable proactive triggering and weak coordination between reactive and proactive behaviors, and that IPI-Agent, built around an interaction-control policy and temporal-gating mechanism, consistently improves performance on all IPIBench settings without any model fine-tuning or task-specific adaptation.
What carries the argument
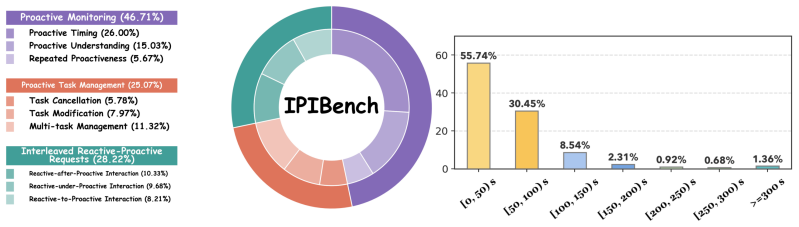
IPIBench benchmark covering proactive monitoring, proactive task management, and interleaved reactive-proactive requests in streaming video, paired with IPI-Agent, a training-free agentic framework that applies an interaction-control policy and temporal-gating mechanism to stabilize triggering and coordinate behaviors.
If this is right
- MLLMs equipped with IPI-Agent show measurable gains in proactive stability and behavioral coordination across all benchmark settings.
- The interaction-control policy enables reliable decision-making about when to initiate proactive actions during multi-turn streams.
- Temporal gating improves separation and integration of reactive queries with ongoing proactive monitoring.
- Existing models can reach better performance on dynamic streaming tasks without retraining.
- The benchmark provides a standardized way to measure progress on interactive proactive intelligence.
Where Pith is reading between the lines
- Similar control policies could be tested on audio or sensor streams to support always-on assistants in other modalities.
- Production systems might adopt the gating approach to lower false-positive proactive interventions without custom training data.
- The benchmark structure could guide creation of longer-horizon interaction datasets that track request history over extended sessions.
- If the mechanisms prove robust, they may reduce reliance on expensive fine-tuning loops for interaction-aware models.
Load-bearing premise
The interaction-control policy and temporal-gating mechanism can be applied generally to stabilize proactive triggering and coordinate behaviors across different MLLMs without model-specific fine-tuning or benchmark-specific adaptation.
What would settle it
Applying the IPI-Agent framework to an MLLM outside the original evaluation set on a new streaming video task where proactive triggering remains unstable or reactive-proactive coordination does not improve would falsify the general applicability claim.
Figures

read the original abstract
Recent multimodal large language models (MLLMs) achieve strong performance on reactive question answering, but real-world streaming assistants require proactive reasoning over continuous visual inputs. Existing benchmarks mainly study reactive or proactive interactions in isolated single-turn settings, overlooking dynamic multi-turn scenarios where users may add, modify, or cancel proactive requests alongside interleaved reactive queries. To address this gap, we introduce IPIBench, the first benchmark for evaluating Interactive Proactive Intelligence of MLLMs under streaming video settings. IPIBench covers proactive monitoring, proactive task management, and interleaved reactive-proactive requests. Evaluations on representative MLLMs reveal two major limitations: unstable proactive triggering and weak coordination between reactive and proactive behaviors. We further propose IPI-Agent, a training-free agentic framework with an interaction-control policy and a temporal-gating mechanism for stabilizing proactive triggering and coordinating multi-turn interactions. Experiments show that IPI-Agent consistently improves existing MLLMs across all benchmark settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces IPIBench as the first benchmark for evaluating interactive proactive intelligence of MLLMs under continuous streaming video inputs, covering proactive monitoring, task management, and interleaved reactive-proactive requests. It identifies two limitations in existing MLLMs (unstable proactive triggering and weak coordination between reactive and proactive behaviors) and proposes IPI-Agent, a training-free agentic framework using an interaction-control policy and temporal-gating mechanism, claiming consistent improvements across all benchmark settings.
Significance. If the benchmark construction, metrics, and experimental results hold up under scrutiny, the work would address a genuine gap in evaluating dynamic, multi-turn proactive capabilities for real-world streaming assistants, providing a new evaluation resource and a simple baseline agent framework.
major comments (2)
- No details are provided on IPIBench construction (dataset sources, video stream generation, annotation protocol, or task distribution statistics), which is load-bearing for the central claim that existing MLLMs exhibit the two stated limitations.
- The abstract states that IPI-Agent 'consistently improves existing MLLMs across all benchmark settings' but supplies no quantitative results, ablation studies on the interaction-control policy or temporal-gating mechanism, or comparison against fine-tuned baselines, preventing verification that the gains are not due to benchmark-specific tuning.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our work introducing IPIBench and the IPI-Agent framework. We address each major comment below with clarifications and plans for revision where appropriate.
read point-by-point responses
-
Referee: No details are provided on IPIBench construction (dataset sources, video stream generation, annotation protocol, or task distribution statistics), which is load-bearing for the central claim that existing MLLMs exhibit the two stated limitations.
Authors: We agree that additional details on benchmark construction would strengthen the paper and support the claims about MLLM limitations. The current manuscript provides an overview in Section 3, but we will expand it in revision to explicitly include: sources of the video streams (e.g., public datasets and synthetic generation methods), the protocol for creating continuous streaming inputs with interleaved requests, the full annotation guidelines and inter-annotator agreement, and detailed task distribution statistics (e.g., proportions of proactive monitoring, task management, and reactive-proactive interleaving). This will be added as a new subsection or appendix to ensure reproducibility. revision: yes
-
Referee: The abstract states that IPI-Agent 'consistently improves existing MLLMs across all benchmark settings' but supplies no quantitative results, ablation studies on the interaction-control policy or temporal-gating mechanism, or comparison against fine-tuned baselines, preventing verification that the gains are not due to benchmark-specific tuning.
Authors: The abstract summarizes the key finding, while the full quantitative results (including per-setting improvements for multiple MLLMs) are reported in Section 5 with accompanying tables. However, we acknowledge the value of component ablations and additional baselines. In the revised manuscript, we will add an ablation study isolating the interaction-control policy and temporal-gating mechanism, along with comparisons to relevant training-free and fine-tuned baselines where feasible. As IPI-Agent is explicitly training-free, we will clarify that the primary contribution is the agentic framework rather than end-to-end fine-tuning, but the added experiments will address concerns about benchmark-specific effects. revision: partial
Circularity Check
No significant circularity
full rationale
The paper introduces a new benchmark (IPIBench) and a training-free agentic framework (IPI-Agent) with an interaction-control policy and temporal-gating mechanism. No equations, derivations, fitted parameters, or self-citation chains are present in the provided abstract or description that reduce any claimed result to its inputs by construction. The central claims rest on empirical evaluations of existing MLLMs and the proposed framework's improvements, which are presented as independent experimental outcomes rather than self-referential definitions or renamings. This is a standard benchmark/framework paper with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
EgoSAT: A Comprehensive Benchmark of Egocentric Streaming Interaction Understanding
EgoSAT is the first benchmark unifying retrospective, online, and prospective reasoning tasks in egocentric streaming video to evaluate VLMs, revealing struggles with temporal modeling and mis-calibration.
Reference graph
Works this paper leans on
- [1]
-
[2]
S. Bai, Y . Cai, R. Chen, K. Chen, X. Chen, Z. Cheng, L. Deng, W. Ding, C. Gao, C. Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
S. Bai, K. Chen, X. Liu, J. Wang, W. Ge, S. Song, K. Dang, P. Wang, S. Wang, J. Tang, H. Zhong, Y . Zhu, M. Yang, Z. Li, J. Wan, P. Wang, W. Ding, Z. Fu, Y . Xu, J. Ye, X. Zhang, T. Xie, Z. Cheng, H. Zhang, Z. Yang, H. Xu, and J. Lin. Qwen2.5-vl technical report.ArXiv, abs/2502.13923, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Bärmann and A
L. Bärmann and A. Waibel. Where did i leave my keys?-episodic-memory-based question answering on egocentric videos. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1560–1568, 2022
2022
- [5]
-
[6]
J. Chen, Z. Lv, S. Wu, K. Q. Lin, C. Song, D. Gao, J.-W. Liu, Z. Gao, D. Mao, and M. Z. Shou. Videollm-online: Online video large language model for streaming video. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18407–18418, 2024
2024
-
[7]
Z. Chen, J. Wu, W. Wang, W. Su, G. Chen, S. Xing, M. Zhong, Q. Zhang, X. Zhu, L. Lu, et al. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 24185–24198, 2024
2024
-
[8]
G. Comanici, E. Bieber, M. Schaekermann, I. Pasupat, N. Sachdeva, I. Dhillon, M. Blistein, O. Ram, D. Zhang, E. Rosen, et al. Gemini 2.5: Pushing the frontier with advanced rea- soning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
X. Ding, H. Wu, Y . Yang, S. Jiang, Q. Zhang, D. Bai, Z. Chen, and T. Cao. Streammind: Un- locking full frame rate streaming video dialogue through event-gated cognition. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 13448–13459, 2025
2025
-
[10]
Driess, F
D. Driess, F. Xia, M. S. M. Sajjadi, C. Lynch, A. Chowdhery, B. Ichter, A. Wahid, J. Tompson, Q. Vuong, T. Yu, W. Huang, Y . Chebotar, P. Sermanet, D. Duckworth, S. Levine, V . Vanhoucke, K. Hausman, M. Toussaint, K. Greff, A. Zeng, I. Mordatch, and P. Florence. Palm-e: An embodied multimodal language model, 2023
2023
-
[11]
Epstein, B
D. Epstein, B. Chen, and C. V ondrick. Oops! predicting unintentional action in video. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 919–929, 2020
2020
-
[12]
J. Gao, C. Sun, Z. Yang, and R. Nevatia. Tall: Temporal activity localization via language query. InProceedings of the IEEE international conference on computer vision, pages 5267–5275, 2017
2017
-
[13]
Grauman, A
K. Grauman, A. Westbury, E. Byrne, Z. Chavis, A. Furnari, R. Girdhar, J. Hamburger, H. Jiang, M. Liu, X. Liu, et al. Ego4d: Around the world in 3,000 hours of egocentric video. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 18995–19012, 2022
2022
-
[14]
C. Gu, C. Sun, D. A. Ross, C. V ondrick, C. Pantofaru, Y . Li, S. Vijayanarasimhan, G. Toderici, S. Ricco, R. Sukthankar, et al. Ava: A video dataset of spatio-temporally localized atomic visual actions. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 6047–6056, 2018. 10
2018
-
[15]
W. Hong, W. Yu, X. Gu, G. Wang, G. Gan, H. Tang, J. Cheng, J. Qi, J. Ji, L. Pan, et al. Glm-4.5 v and glm-4.1 v-thinking: Towards versatile multimodal reasoning with scalable reinforcement learning.arXiv preprint arXiv:2507.01006, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Y . Hu, Z. Yang, S. Wang, S. Qian, B. Wen, F. Yang, T. Gao, and C. Xu. Streamingcot: A dataset for temporal dynamics and multimodal chain-of-thought reasoning in streaming videoqa. In Proceedings of the 33rd ACM International Conference on Multimedia, pages 13464–13470, 2025
2025
-
[17]
Huang, X
Z. Huang, X. Li, J. Li, J. Wang, X. Zeng, C. Liang, T. Wu, X. Chen, L. Li, and L. Wang. Online video understanding: Ovbench and videochat-online. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 3328–3338, 2025
2025
-
[18]
A. Hurst, A. Lerer, A. P. Goucher, A. Perelman, A. Ramesh, A. Clark, A. Ostrow, A. Welihinda, A. Hayes, A. Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
in the wild
H. Idrees, A. R. Zamir, Y .-G. Jiang, A. Gorban, I. Laptev, R. Sukthankar, and M. Shah. The thumos challenge on action recognition for videos “in the wild”.Computer Vision and Image Understanding, 155:1–23, 2017
2017
-
[20]
J. Kim, M. S. Kim, J. Chung, J. Cho, J. Kim, S. Kim, G. Sim, and Y . Yu. Egospeak: learning when to speak for egocentric conversational agents in the wild. InFindings of the Association for Computational Linguistics: NAACL 2025, pages 2990–3005, 2025
2025
-
[21]
J. Lei, T. L. Berg, and M. Bansal. Detecting moments and highlights in videos via natural language queries.Advances in Neural Information Processing Systems, 34:11846–11858, 2021
2021
-
[22]
B. Li, Y . Zhang, D. Guo, R. Zhang, F. Li, H. Zhang, K. Zhang, P. Zhang, Y . Li, Z. Liu, et al. Llava-onevision: Easy visual task transfer.arXiv preprint arXiv:2408.03326, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
M. Li, Y . Zhang, D. Long, K. Chen, S. Song, S. Bai, Z. Yang, P. Xie, A. Yang, D. Liu, et al. Qwen3-vl-embedding and qwen3-vl-reranker: A unified framework for state-of-the-art multimodal retrieval and ranking.arXiv preprint arXiv:2601.04720, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[24]
W. Li, B. Hu, R. Shao, L. Shen, and L. Nie. Lion-fs: Fast & slow video-language thinker as online video assistant. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3240–3251, 2025
2025
-
[25]
J. Lin, Z. Fang, C. Chen, H. Cheng, Z. Wan, F. Luo, Z. Wang, P. Li, Y . Liu, and M. Sun. Streamingbench: Assessing the gap for mllms to achieve streaming video understanding. In ICASSP 2026-2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 12147–12151. IEEE, 2026
2026
-
[26]
H. Liu, C. Li, Q. Wu, and Y . J. Lee. Visual instruction tuning, 2023
2023
-
[27]
Z. Liu, Y . Dong, Z. Liu, W. Hu, J. Lu, and Y . Rao. Oryx mllm: On-demand spatial-temporal understanding at arbitrary resolution. InThe Thirteenth International Conference on Learning Representations
-
[28]
M. Maaz, H. Rasheed, S. Khan, and F. Khan. Video-chatgpt: Towards detailed video under- standing via large vision and language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 12585–12602, 2024
2024
- [29]
-
[30]
J. Niu, Y . Li, Z. Miao, C. Ge, Y . Zhou, Q. He, X. Dong, H. Duan, S. Ding, R. Qian, et al. Ovo-bench: How far is your video-llms from real-world online video understanding? In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 18902–18913, 2025. 11
2025
-
[31]
R. Qian, S. Ding, X. Dong, P. Zhang, Y . Zang, Y . Cao, D. Lin, and J. Wang. Dispider: Enabling video llms with active real-time interaction via disentangled perception, decision, and reaction. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 24045–24055, 2025
2025
-
[32]
R. Qian, S. Ding, X. Dong, P. Zhang, Y . Zang, Y . Cao, D. Lin, and J. Wang. Dispider: Enabling video llms with active real-time interaction via disentangled perception, decision, and reaction, 2025
2025
-
[33]
Y . Shi, Q. Zhao, T. Jiang, X. Zeng, Y . Wang, and L. Wang. River: A real-time interaction bench- mark for video llms. InThe Fourteenth International Conference on Learning Representations
-
[34]
A. Singh, A. Fry, A. Perelman, A. Tart, A. Ganesh, A. El-Kishky, A. McLaughlin, A. Low, A. Ostrow, A. Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
H. Tang, K. J. Liang, K. Grauman, M. Feiszli, and W. Wang. Egotracks: A long-term egocentric visual object tracking dataset.Advances in Neural Information Processing Systems, 36:75716– 75739, 2023
2023
-
[36]
Y . Tang, D. Ding, Y . Rao, Y . Zheng, D. Zhang, L. Zhao, J. Lu, and J. Zhou. Coin: A large- scale dataset for comprehensive instructional video analysis. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1207–1216, 2019
2019
-
[37]
G. Team, R. Anil, S. Borgeaud, J.-B. Alayrac, J. Yu, R. Soricut, J. Schalkwyk, A. M. Dai, A. Hauth, K. Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[38]
Q. Team. Qwen3. 5-omni technical report.arXiv preprint arXiv:2604.15804, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[39]
G. Tom, M. Mathew, S. Garcia-Bordils, D. Karatzas, and C. Jawahar. Reading between the lanes: Text videoqa on the road. InInternational Conference on Document Analysis and Recognition, pages 137–154. Springer, 2023
2023
-
[40]
P. Wang, S. Bai, S. Tan, S. Wang, Z. Fan, J. Bai, K. Chen, X. Liu, J. Wang, W. Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
Y . Wang, X. Li, Z. Yan, Y . He, J. Yu, X. Zeng, C. Wang, C. Ma, H. Huang, J. Gao, et al. Internvideo2. 5: Empowering video mllms with long and rich context modeling.arXiv preprint arXiv:2501.12386, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [42]
- [43]
- [44]
-
[45]
Y . Wang, Y . Wang, B. Chen, T. Wu, D. Zhao, and Z. Zheng. Omnimmi: A comprehensive multi- modal interaction benchmark in streaming video contexts. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18925–18935, 2025
2025
-
[46]
Z. Wen, Y . Wang, C. Liao, B. Yang, J. Li, W. Liu, H. He, B. Feng, X. Liu, Y . Lyu, X. Zheng, X. Hu, and L. Zhang. Ai for service: Proactive assistance with ai glasses, 2025
2025
-
[47]
J. Wu, R. Antonova, A. Kan, M. Lepert, A. Zeng, S. Song, J. Bohg, S. Rusinkiewicz, and T. Funkhouser. Tidybot: personalized robot assistance with large language models.Autonomous Robots, 47(8):1087–1102, Nov. 2023. 12
2023
-
[48]
S. Wu, J. Chen, K. Q. Lin, Q. Wang, Y . Gao, Q. Xu, T. Xu, Y . Hu, E. Chen, and M. Z. Shou. Videollm-mod: Efficient video-language streaming with mixture-of-depths vision computation. Advances in Neural Information Processing Systems, 37:109922–109947, 2024
2024
-
[49]
J. Xia, P. Chen, M. Zhang, X. Sun, and K. Zhou. Streaming video instruction tuning.arXiv preprint arXiv:2512.21334, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[50]
H. Xiong, Z. Yang, J. Yu, Y . Zhuge, L. Zhang, J. Zhu, and H. Lu. Streaming video un- derstanding and multi-round interaction with memory-enhanced knowledge.arXiv preprint arXiv:2501.13468, 2025
- [51]
-
[52]
R. Xu, G. Xiao, Y . Chen, L. He, K. Peng, Y . Lu, and S. Han. Streamingvlm: Real-time understanding for infinite video streams, 2025
2025
-
[53]
S. Xun, S. Tao, J. Li, Y . Shi, Z. Lin, Z. Zhu, Y . Yan, H. Li, L. Zhang, S. Wang, et al. Rtv-bench: Benchmarking mllm continuous perception, understanding and reasoning through real-time video. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track
- [54]
-
[55]
H. Yang, F. Tang, L. Zhao, X. An, M. Hu, H. Li, X. Zhuang, Y . Lu, X. Zhang, A. Swikir, et al. Streamagent: Towards anticipatory agents for streaming video understanding.arXiv preprint arXiv:2508.01875, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[56]
Y . Yang, Z. Zhao, S. N. Shukla, A. Singh, S. K. Mishra, L. Zhang, and M. Ren. Streammem: Query-agnostic kv cache memory for streaming video understanding, 2025
2025
- [57]
- [58]
-
[59]
Long Context Transfer from Language to Vision
P. Zhang, K. Zhang, B. Li, G. Zeng, J. Yang, Y . Zhang, Z. Wang, H. Tan, C. Li, and Z. Liu. Long context transfer from language to vision.arXiv preprint arXiv:2406.16852, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[60]
Zhang, X
Y . Zhang, X. L. Dong, Z. Lin, A. Madotto, A. Kumar, B. Damavandi, J. Chai, and S. Moon. Proactive assistant dialogue generation from streaming egocentric videos. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 12055–12079, 2025
2025
-
[61]
arXiv preprint arXiv:2510.14560 (2025) 8 20 P
Y . Zhang, C. Shi, Y . Wang, and S. Yang. Eyes wide open: Ego proactive video-llm for streaming video.arXiv preprint arXiv:2510.14560, 2025
-
[62]
L. Zhou, C. Xu, and J. Corso. Towards automatic learning of procedures from web instructional videos. InProceedings of the AAAI conference on artificial intelligence, volume 32, 2018
2018
-
[63]
J. Zhu, W. Wang, Z. Chen, Z. Liu, S. Ye, L. Gu, H. Tian, Y . Duan, W. Su, J. Shao, et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479, 2025. 13
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.