Gaussian Process-based learning with new MCMC-based implementation of Wishart prior on correlation matrix
Pith reviewed 2026-06-29 15:33 UTC · model grok-4.3
The pith
A self-assembled Wishart prior on the covariance matrix helps diagnose weakly informative inputs during Gaussian process learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
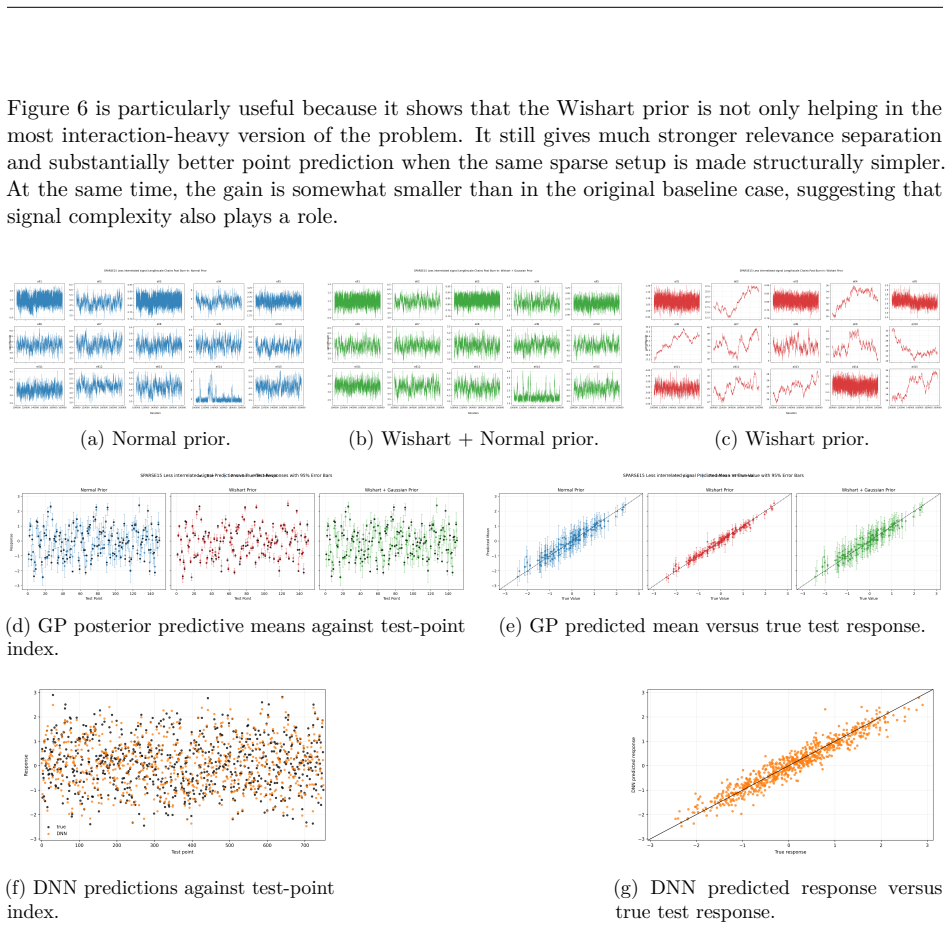
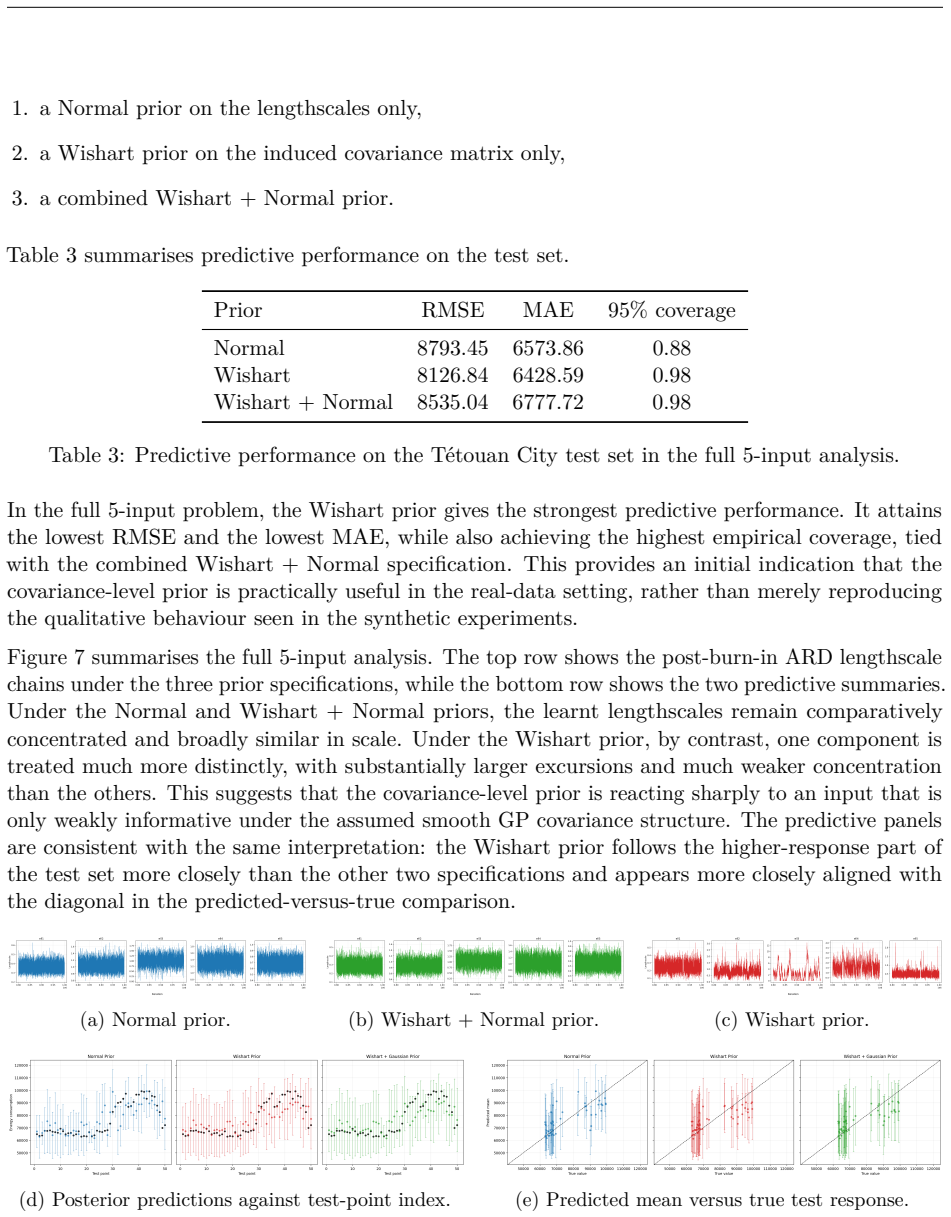
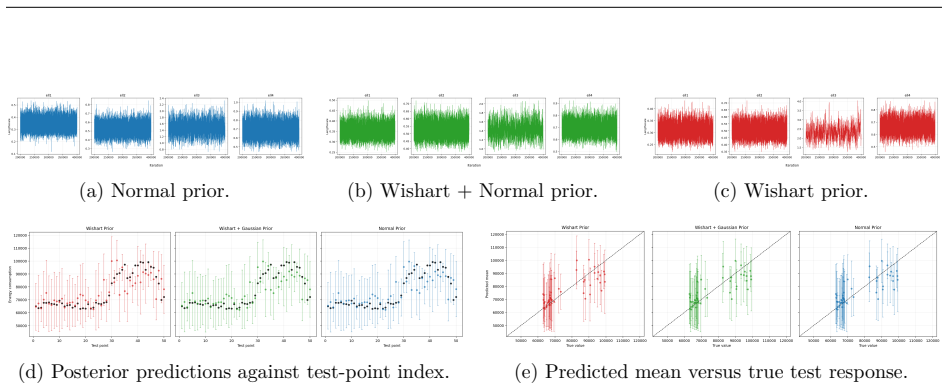
We develop a self-assembled Wishart prior for the covariance matrix while undertaking Bayesian inference on the kernel hyperparameters using MCMC. The construction uses a look-back window over recent MCMC iterations to define a time-step dependent scale matrix, thereby introducing adaptiveness to the chain. Results suggest that direct prior specification on the covariance matrix can be useful for diagnosing weakly informative inputs within the GP-based learning paradigm.
What carries the argument
The self-assembled Wishart prior whose scale matrix is updated at each MCMC step from a look-back window of recent samples, allowing direct prior specification on the covariance matrix.
If this is right
- Multiple lengthscale parameters become easier to infer jointly when the covariance receives a direct prior.
- Weakly informative inputs can be flagged by inspecting the posterior induced by the covariance prior.
- The adaptive MCMC sampler supports reliable hyperparameter learning for highly multivariate target functions.
- The same prior construction applies equally to synthetic and real-world GP regression tasks.
Where Pith is reading between the lines
- The look-back construction might be transferred to other positive-definite matrix priors used in multivariate Bayesian models.
- Input diagnosis performed this way could reduce reliance on separate variable-selection procedures before fitting a GP.
- Varying the length of the look-back window offers a tunable knob that future experiments could optimize for different data regimes.
Load-bearing premise
Defining the scale matrix from a look-back window of recent MCMC iterations produces a useful adaptive prior without destabilizing the sampler or introducing unwanted bias.
What would settle it
If the posterior on the covariance matrix fails to assign low weight to known irrelevant inputs in the synthetic data experiment, or if the adaptive chain mixes worse than a non-adaptive Wishart prior on the same data, the claimed diagnostic utility would not hold.
Figures
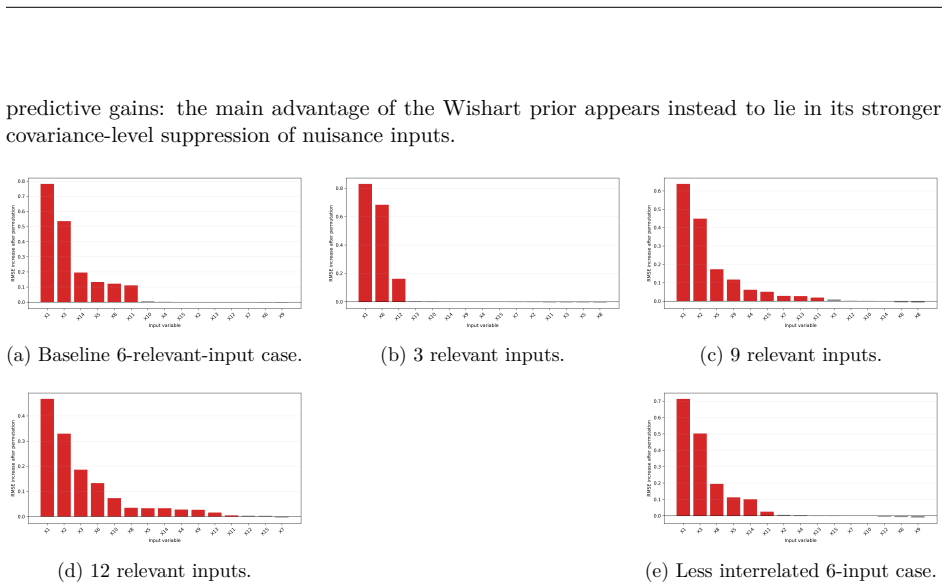
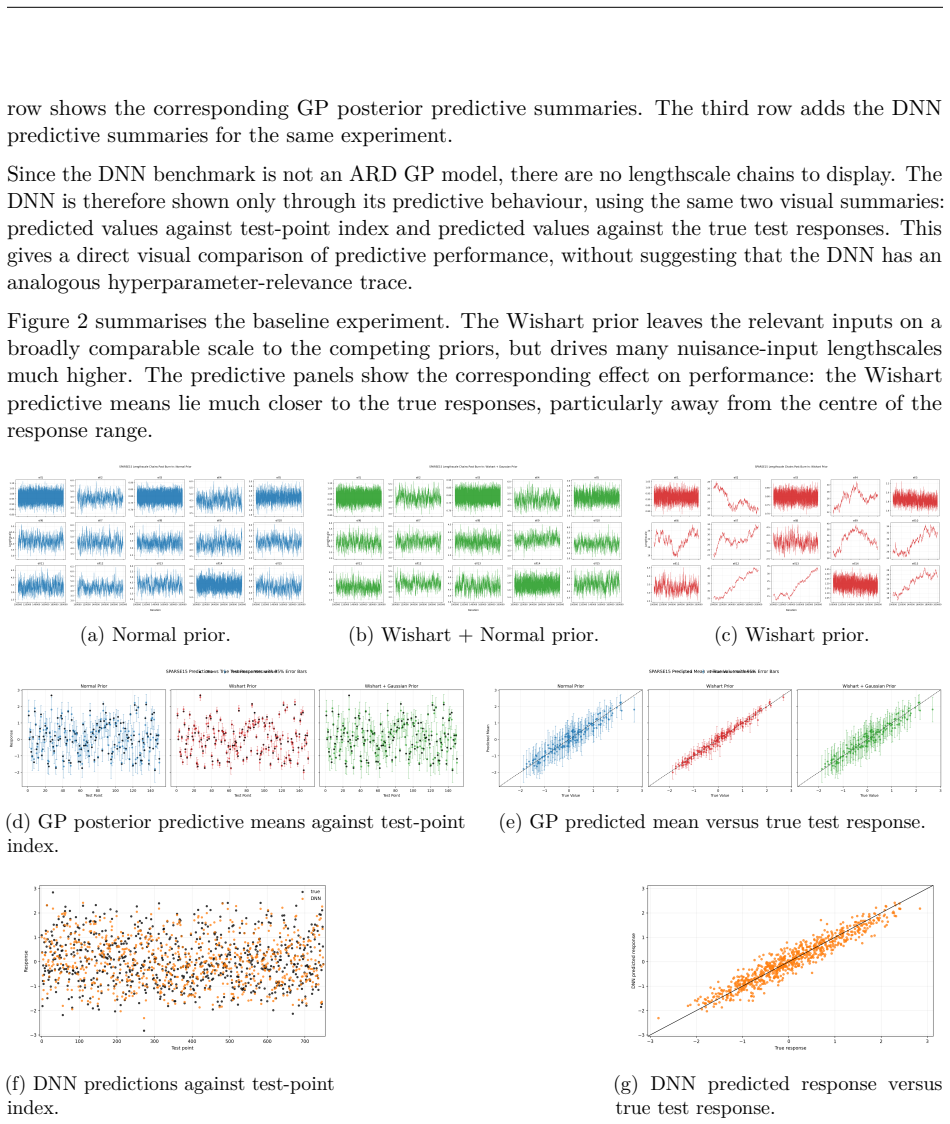

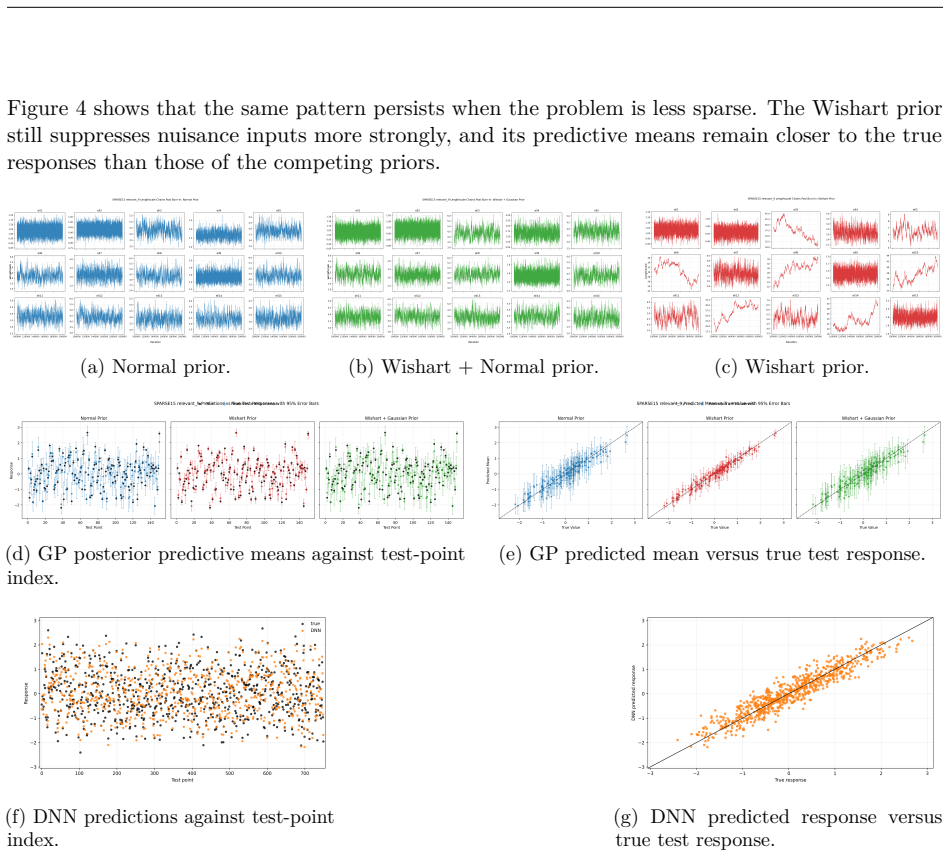
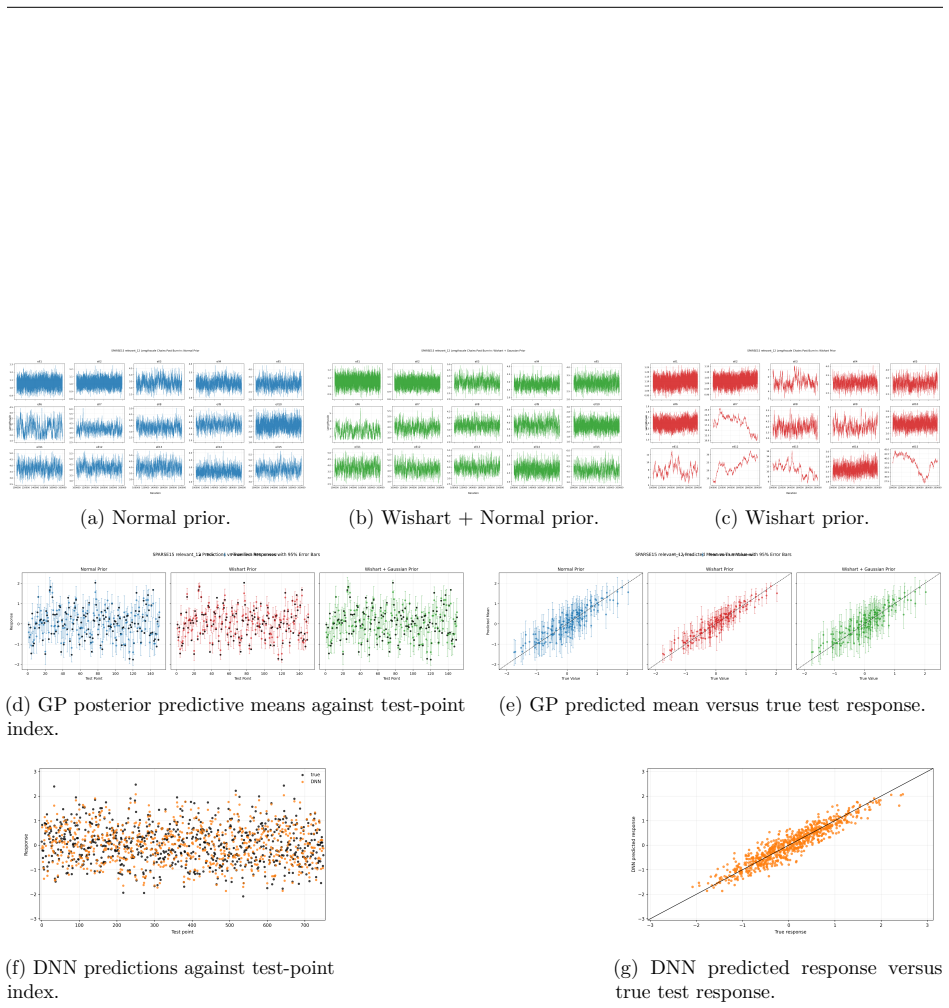
read the original abstract
In probabilstic supervised learning of an input-output relationship - as a sample function of a Gaussian Process (GP) - priors are typically specified for the hyperparameters of the kernel that parametrises the covariance function of the GP, where the induced covariance matrix of the (resulting multivariate Normal) likelihood, governs the learning and prediction. When the sought function is highly multivariate, multiple lengthscale parameters must be learnt simultaneously, making inference difficult. We develop a ``self-assembled'' Wishart prior for the covariance matrix, while undertaking Bayesian inference on the kernel hyperparameters using MCMC. The construction uses a look-back window over recent MCMC iterations to define a time-step dependent scale matrix, thereby introducing adaptiveness to the chain. Results suggest that direct prior specification on the covariance matrix can be useful for diagnosing weakly informative inputs within the GP-based learning paradigm. We support our prior development with two distinct empirical illustrations - one on synthetic data, and another on a real-world dataset.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript develops a 'self-assembled' Wishart prior on the covariance matrix for Gaussian Process models in probabilistic supervised learning. It implements this via MCMC on kernel hyperparameters, where the scale matrix is constructed adaptively from a look-back window over recent MCMC iterations, introducing time-step dependence. The approach is illustrated on synthetic data and a real-world dataset, with results suggesting utility for diagnosing weakly informative inputs when multiple lengthscales must be learned simultaneously.
Significance. If the adaptive construction is valid, the method could enable direct prior specification on the full covariance matrix rather than individual kernel parameters, offering a diagnostic tool for input relevance in high-dimensional GP settings. The two empirical illustrations provide initial support for this use case.
major comments (1)
- [Abstract] Abstract (construction paragraph): the adaptive MCMC defines a time-step dependent scale matrix via a look-back window over recent iterations. Standard adaptive MCMC theory requires conditions such as diminishing adaptation (adaptation rate → 0) to guarantee convergence to the target posterior; the manuscript gives no indication that these conditions hold for the window scheme or that they were verified, which is load-bearing for the validity of all reported results.
minor comments (1)
- [Abstract] Abstract, first sentence: 'probabilstic' is a typo and should be 'probabilistic'.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive feedback. We address the single major comment below, indicating the revision that will be incorporated.
read point-by-point responses
-
Referee: [Abstract] Abstract (construction paragraph): the adaptive MCMC defines a time-step dependent scale matrix via a look-back window over recent iterations. Standard adaptive MCMC theory requires conditions such as diminishing adaptation (adaptation rate → 0) to guarantee convergence to the target posterior; the manuscript gives no indication that these conditions hold for the window scheme or that they were verified, which is load-bearing for the validity of all reported results.
Authors: We agree that the adaptive construction of the scale matrix via a fixed look-back window renders the target distribution time-dependent and that the manuscript provides no discussion or verification of standard adaptive MCMC conditions such as diminishing adaptation. The approach is presented as an empirical construction for prior specification and input diagnosis rather than a theoretically convergent sampler. We will revise the manuscript to explicitly state the heuristic character of the scheme, note the lack of formal convergence guarantees, and add a brief discussion of this point (with reference to the empirical results on synthetic and real data) in the methods and/or a new limitations subsection. revision: yes
Circularity Check
No significant circularity; method is explicitly constructed as adaptive MCMC.
full rationale
The paper defines its Wishart prior construction explicitly via a look-back window on MCMC iterations to create a time-dependent scale matrix. This is presented as the method itself (an adaptive prior), with empirical illustrations on synthetic and real data to suggest utility for diagnosing weakly informative inputs. No derivation chain is claimed that reduces a 'prediction' or result to its inputs by construction, no self-citations are invoked as load-bearing, and no uniqueness theorems or ansatzes are smuggled. The central claim remains an empirical suggestion about the prior's usefulness rather than a tautological output. This is self-contained as a methodological proposal.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Carl Edward Rasmussen and Christopher K
doi: 10.1198/TECH.2011.10148. Carl Edward Rasmussen and Christopher K. I. Williams.Gaussian Processes for Machine Learning. MIT Press, Cambridge, MA, 2006. Gareth O. Roberts and Jeffrey S. Rosenthal. Coupling and ergodicity of adaptive markov chain monte carlo algorithms.Journal of Applied Probability, 44(2):458–475, 2007. Michael L. Stein.Interpolation o...
-
[2]
doi: 10.1007/978-1-4612-1494-6. S. Sundararajan and S. Sathiya Keerthi. Predictive approaches for choosing hyperparameters in gaus- sian processes.Neural Computation, 13(5):1103–1118, 2001. doi: 10.1162/089976601300014312. Christopher K. I. Williams. Gaussian processes for regression. In Christopher M. Bishop, editor, Neural Networks for Machine Learning,...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.