Adversarial Dual On-Policy Distillation from Expressive Teacher
Pith reviewed 2026-06-29 18:52 UTC · model grok-4.3
The pith
FA-OPD lets a flow-matching teacher co-train with a student policy to supply reward and action signals on visited states for better demonstration-based robot control.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
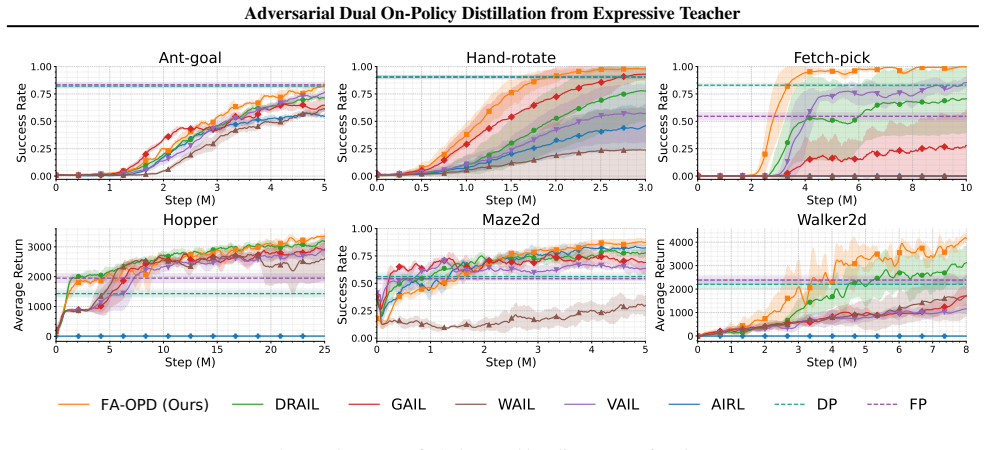
The central discovery is that coupling reward distillation for long-horizon optimization with action distillation for local guidance in an adversarial on-policy setup enables a demonstration-trained teacher to provide effective signals during student rollouts, leading to improved performance and robustness in embodied control tasks.
What carries the argument
The adversarial dual on-policy distillation, in which the flow-matching teacher provides both a reward channel over state-action pairs and an action channel at student-visited states.
If this is right
- Reward distillation enables generalization beyond point-wise demonstrations.
- Action distillation keeps exploration anchored near expert-like behavior.
- The approach beats strong baselines on six robot benchmarks.
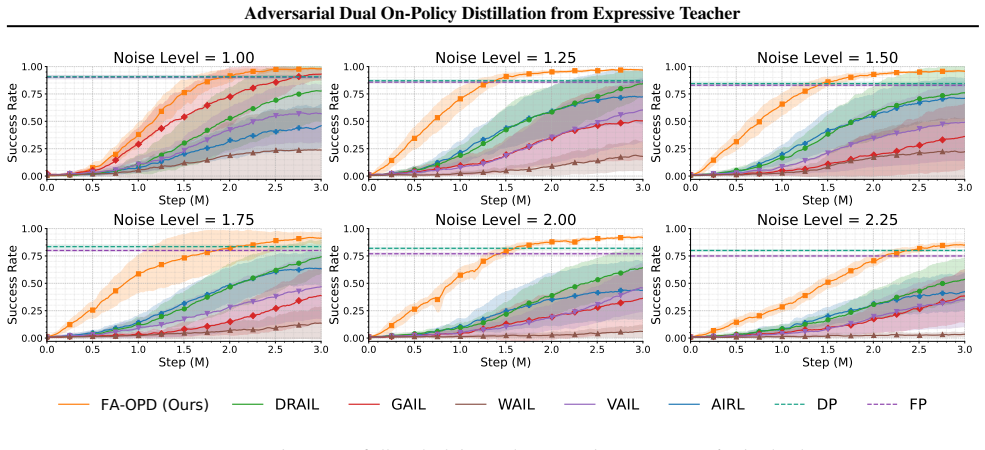
- It exhibits stronger robustness under noisy or limited demonstrations.
Where Pith is reading between the lines
- This dual signal mechanism might apply to other imitation learning settings where expert policies are not available at test time.
- Combining flow-matching with on-policy methods could address distribution shift in a wider range of control problems.
- The method's success suggests that teacher-student co-training can be more effective than fixed teacher distillation in demonstration-only scenarios.
Load-bearing premise
A flow-matching teacher trained solely on demonstrations can provide useful reward and action signals on states encountered by the student during its own rollouts.
What would settle it
Observing that FA-OPD fails to outperform the baselines or loses robustness on the robot navigation, manipulation, and locomotion benchmarks when demonstrations are noisy would falsify the claim.
Figures




read the original abstract
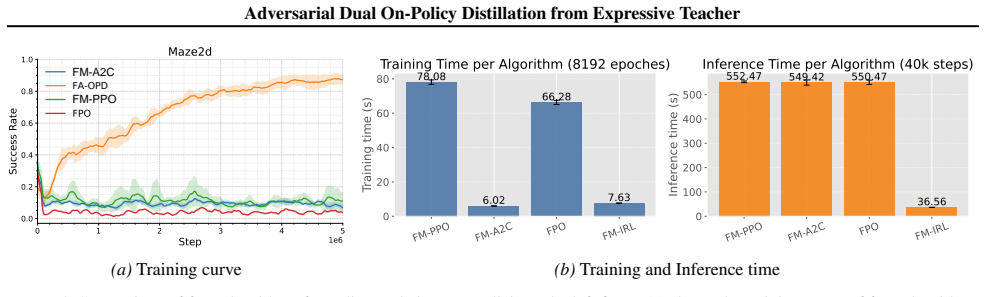
Learning from demonstrations in embodied control is often cast as behavioral cloning, and recent diffusion or flow-matching policies improve this paradigm by modeling multi-modal expert actions. Yet these methods remain offline supervised learners: the policy is trained only on expert states and receives no corrective signal on the states it actually visits. On-policy distillation (OPD) offers a natural remedy, but standard OPD assumes a strong fixed teacher, which is unavailable in demonstration-only control. We propose \textbf{FA-OPD}, an \emph{adversarial dual on-policy distillation} method in which a Flow Matching (FM) teacher is learned from demonstrations and co-trained with a lightweight MLP student. The teacher provides two complementary signals on student rollouts. The reward channel learns an expert-likeness objective over state-action pairs and drives online exploration through long-horizon policy optimization. The action channel supplies dense local targets at student-visited states, stabilizing exploitation. FA-OPD couples them so that reward distillation enables generalization beyond point-wise demonstrations, while action distillation keeps exploration anchored near expert-like behavior. Across six robot navigation, manipulation, and locomotion benchmarks, FA-OPD beats strong baselines and shows much stronger robustness under noisy or limited demonstrations. Source code: https://github.com/vanzll/FA-OPD.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes FA-OPD, an adversarial dual on-policy distillation method in which a flow-matching teacher is trained from demonstrations and co-trained with a lightweight MLP student policy. The teacher supplies a reward signal (expert-likeness over state-action pairs) for long-horizon policy optimization on student rollouts and dense action targets for stabilization. The approach is claimed to enable generalization beyond demonstration states while remaining anchored near expert behavior, yielding superior performance and robustness on six robot navigation, manipulation, and locomotion benchmarks compared to strong baselines, especially under noisy or limited demonstrations.
Significance. If the empirical claims hold and the teacher generalization assumption is validated, the work would offer a concrete mechanism for combining offline expressive generative models with on-policy corrective signals, addressing a recognized limitation of pure behavioral cloning and fixed-teacher OPD in demonstration-only settings. The dual-channel design (reward for exploration, action for exploitation) is a plausible way to mitigate distribution shift, and the reported robustness gains under limited/noisy data would be of practical interest in embodied control.
major comments (3)
- [Abstract] Abstract: the central empirical claim (superiority on six benchmarks plus stronger robustness under noisy/limited demos) is stated without any metrics, baseline names, statistical tests, or ablation results, rendering the primary contribution unevaluable from the provided text.
- [Abstract] Abstract and method description: the key assumption that the flow-matching teacher (trained only on demonstrations) supplies reliable, non-misleading reward and action signals on states visited by the student during on-policy rollouts is not supported by any OOD diagnostics, density estimation checks, or ablations; this assumption is load-bearing for both the generalization and robustness claims.
- [Abstract] Method description: no equations, objective functions, or training algorithm are supplied for the adversarial coupling of the reward and action channels, preventing assessment of whether the dual objective avoids reward hacking, mode collapse, or circular dependence on the student distribution.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on clarity and validation. We address each major point below and have revised the manuscript to incorporate additional details, metrics, and analyses where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim (superiority on six benchmarks plus stronger robustness under noisy/limited demos) is stated without any metrics, baseline names, statistical tests, or ablation results, rendering the primary contribution unevaluable from the provided text.
Authors: We agree that the abstract would benefit from more concrete details. In the revised manuscript, we have updated the abstract to include specific performance metrics (e.g., success rates and robustness improvements on the six benchmarks), names of the primary baselines, and references to statistical tests and ablations demonstrating the robustness gains under noisy/limited demonstrations. revision: yes
-
Referee: [Abstract] Abstract and method description: the key assumption that the flow-matching teacher (trained only on demonstrations) supplies reliable, non-misleading reward and action signals on states visited by the student during on-policy rollouts is not supported by any OOD diagnostics, density estimation checks, or ablations; this assumption is load-bearing for both the generalization and robustness claims.
Authors: This is a fair critique of the load-bearing assumption. While the reported robustness results under noisy and limited data offer indirect empirical support, we did not provide explicit OOD diagnostics. We have added a new analysis subsection with density estimation on student-visited states and an ablation isolating the reward channel to directly validate the teacher's generalization behavior. revision: yes
-
Referee: [Abstract] Method description: no equations, objective functions, or training algorithm are supplied for the adversarial coupling of the reward and action channels, preventing assessment of whether the dual objective avoids reward hacking, mode collapse, or circular dependence on the student distribution.
Authors: We acknowledge the abstract's brevity omitted these details. The full manuscript already contains the reward and action objectives plus the co-training procedure; we have now added a concise overview of the dual objective and its adversarial coupling to the abstract, along with explicit discussion in the method section of how the design mitigates reward hacking and mode collapse via on-policy anchoring. revision: partial
Circularity Check
No circularity: new method combination with external benchmark validation
full rationale
The paper introduces FA-OPD as an empirical combination of a flow-matching teacher (trained on demonstrations) with adversarial dual on-policy distillation signals. No equations, derivations, or 'predictions' are presented that reduce by construction to fitted inputs or self-citations. The central claims rest on reported performance across six robot benchmarks under noisy/limited demos, which are external to any internal fitting loop. The generalization assumption about the teacher on student states is an empirical hypothesis, not a definitional tautology. This matches the default case of a self-contained empirical proposal.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A flow-matching model trained on demonstrations can generate useful expert-likeness rewards and action targets on out-of-distribution states visited by a student policy.
Reference graph
Works this paper leans on
-
[1]
Agarwal, R., Vieillard, N., Zhou, Y ., Stanczyk, P., Garea, S. R., Geist, M., and Bachem, O. On-policy distillation of language models: Learning from self-generated mistakes. arXiv preprint arXiv:2306.13649,
-
[2]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
URL https: //arxiv.org/abs/2410.24164. Braun, M., Jaquier, N., Rozo, L., and Asfour, T. Riemannian flow matching policy for robot motion learning. In2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 5144–5151,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Diffusion Policy: Visuomotor Policy Learning via Action Diffusion
URL https://arxiv.org/abs/2303.04137. DeepSeek-AI. DeepSeek-V4: Towards highly efficient million-token context intelligence,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Fu, J., Luo, K., and Levine, S
URL https: //arxiv.org/abs/2502.06061. Fu, J., Luo, K., and Levine, S. Learning robust rewards with adversarial inverse reinforcement learning.arXiv preprint arXiv:1710.11248,
-
[5]
Fujimoto, S., Meger, D., and Precup, D
URL https://openreview.net/ forum?id=px0-N3_KjA. Fujimoto, S., Meger, D., and Precup, D. Off-policy deep reinforcement learning without exploration. InInterna- tional Conference on Machine Learning, pp. 2052–2062. PMLR,
2052
-
[6]
IDQL: Implicit Q-Learning as an Actor-Critic Method with Diffusion Policies
URL https://arxiv.org/abs/2304.10573. Hinton, G., Vinyals, O., and Dean, J. Distilling the knowledge in a neural network.arXiv preprint arXiv:1503.02531,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
URL https://arxiv.org/abs/2412.03603. Lai, C.-M., Wang, H.-C., Hsieh, P.-C., Wang, F., Chen, M.- H., and Sun, S.-H. Diffusion-reward adversarial imitation learning.Advances in Neural Information Processing Systems, 37:95456–95487,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Flow Matching for Generative Modeling
Lipman, Y ., Chen, R. T., Ben-Hamu, H., Nickel, M., and Le, M. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Flow-GRPO: Training Flow Matching Models via Online RL
Liu, J., Liu, G., Liang, J., Li, Y ., Liu, J., Wang, X., Wan, P., Zhang, D., and Ouyang, W. Flow-GRPO: Train- ing flow matching models via online rl.arXiv preprint arXiv:2505.05470,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
M., Weber, E., Choi, H., Feng, H., and Kanazawa, A
McAllister, D., Ge, S., Yi, B., Kim, C. M., Weber, E., Choi, H., Feng, H., and Kanazawa, A. Flow matching policy gradients.arXiv preprint arXiv:2507.21053,
-
[11]
Park, S., Li, Q., and Levine, S
URL https://arxiv.org/abs/ 2602.00743. Park, S., Li, Q., and Levine, S. Flow q-learning.arXiv preprint arXiv:2502.02538,
-
[12]
URL https://arxiv. org/abs/2301.10677. Peng, X. B., Kanazawa, A., Toyer, S., Abbeel, P., and Levine, S. Variational discriminator bottleneck: Improv- ing imitation learning, inverse RL, and gans by constrain- ing information flow.arXiv preprint arXiv:1810.00821,
- [13]
-
[14]
Diffusion Policy Policy Optimization
URL https://arxiv.org/abs/2409.00588. Reuss, M., Li, M., Jia, X., and Lioutikov, R. Goal- conditioned imitation learning using score-based diffu- sion policies,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Ross, S., Gordon, G., and Bagnell, D
URL https://arxiv.org/ abs/2304.02532. Ross, S., Gordon, G., and Bagnell, D. A reduction of imita- tion learning and structured prediction to no-regret online learning. InProceedings of the fourteenth international conference on artificial intelligence and statistics, pp. 627–635. JMLR Workshop and Conference Proceedings,
- [16]
-
[17]
Behavioral Cloning from Observation
Torabi, F., Warnell, G., and Stone, P. Behavioral cloning from observation.arXiv preprint arXiv:1805.01954,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Gymnasium: A Standard Interface for Reinforcement Learning Environments
Towers, M., Kwiatkowski, A., Terry, J., Balis, J. U., De Cola, G., Deleu, T., Goul˜ao, M., Kallinteris, A., Krimmel, M., 11 Adversarial Dual On-Policy Distillation from Expressive Teacher KG, A., et al. Gymnasium: A standard interface for reinforcement learning environments.arXiv preprint arXiv:2407.17032,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan, T., Wang, A., Ai, B., Wen, B., Mao, C., Xie, C.-W., Chen, D., Yu, F., Zhao, H., Yang, J., Zeng, J., Wang, J., Zhang, J., Zhou, J., Wang, J., Chen, J., Zhu, K., Zhao, K., Yan, K., Huang, L., Feng, M., Zhang, N., Li, P., Wu, P., Chu, R., Feng, R., Zhang, S., Sun, S., Fang, T., Wang, T., Gui, T., Weng, T., Shen, T., Lin, W., Wang, W., Wang, W., Zhou, W....
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
URL https://arxiv.org/abs/2410. 06151v1. Wan, Z., Gao, A., Yu, X., Chao, P., Song, J., and Ran, M. POI recommendation via multi-objective adversarial imi- tation learning. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pp. 12676–12684, 2025b. doi: 10.1609/aaai.v39i12.33382. Wan, Z., Yu, X., Bossens, D. M., Lyu, Y ., Guo, Q., F...
-
[21]
Diffusion Policies as an Expressive Policy Class for Offline Reinforcement Learning
URL https://arxiv.org/abs/ 2208.06193. Xiao, H., Herman, M., Wagner, J., Ziesche, S., Etesami, J., and Linh, T. H. Wasserstein adversarial imitation learning. arXiv preprint arXiv:1906.08113,
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[22]
URL https://arxiv. org/abs/2411.06965. Ze, Y ., Zhang, G., Zhang, K., Hu, C., Wang, M., and Xu, H. 3d diffusion policy: Generalizable visuomotor pol- icy learning via simple 3d representations,
-
[23]
3D Diffusion Policy: Generalizable Visuomotor Policy Learning via Simple 3D Representations
URL https://arxiv.org/abs/2403.03954. Zhang, C., Wan, Z., Chen, F., Yang, F., Feng, L., Zhou, Y ., Yu, X., You, Y ., Tsang, I., and An, B. Evolving diffusion and flow matching policies for online reinforcement learn- ing,
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Zhang, Q., Liu, Z., Fan, H., Liu, G., Zeng, B., and Liu, S
URL https: //arxiv.org/abs/2409.01083. Zhang, Q., Liu, Z., Fan, H., Liu, G., Zeng, B., and Liu, S. Flowpolicy: Enabling fast and robust 3d flow-based policy via consistency flow matching for robot manipula- tion. InProceedings of the AAAI Conference on Artificial Intelligence, pp. 14754–14762, 2025a. Zhang, T., Yu, C., Su, S., and Wang, Y . Reinflow: Fine...
-
[25]
URL https://arxiv.org/ abs/2311.13443. 12 Adversarial Dual On-Policy Distillation from Expressive Teacher A. Discussion This sections provides the answers to possible questions about FA-OPD framework and the experiment results in Q&A format below. A.1. Query about Experiment Results Q&A Q. Why the performance improvement of FA-OPD is marginal in Navigatio...
-
[26]
yields a principled reward signal for AIRL, rather than a heuristic distance, thus providing theoretical understanding of why a flow-based discriminator outperforms its diffusion-based counterpartgiven the same computational budget. The argument proceeds in three steps: (i) the per- sample FM loss is, up to a data-only constant, the negative of a variatio...
2023
-
[27]
Operationally, smaller Dist implies a tighter likelihood lower bound, so Dist is a calibrated proxy for the negative log-likelihood under thec-conditioned model
state the same equivalence directly in the flow-matching regime. Operationally, smaller Dist implies a tighter likelihood lower bound, so Dist is a calibrated proxy for the negative log-likelihood under thec-conditioned model. Proposition D.2(AIRL reward as a log density ratio).Let DFM,θ be the Softmax discriminator of Eq. (10). The AIRL log-ratio reward ...
2017
-
[28]
and DRAIL (Lai et al., 2024), consistent with the empirical gap in Table
2024
-
[29]
Under the OPD lens of Sec. 2.3, Propositions D.1–D.2 together justify the FM teacher as awell-calibrated OPD scorer: its per-action score is tightly tied to expert log-likelihood, and the bound is tighter than that of any diffusion-based teacher under the same compute budget. E. Implementation Details The experiment environments are customized and adapted...
2024
-
[30]
All experiments are conducted on a Linux server equipped with four NVIDIA A40 (48GB) GPUs and an AMD EPYC 7543P 32-core CPU
and DRAIL (Lai et al., 2024). All experiments are conducted on a Linux server equipped with four NVIDIA A40 (48GB) GPUs and an AMD EPYC 7543P 32-core CPU. We show the algorithmic and experimental implementation details below. 18 Adversarial Dual On-Policy Distillation from Expressive Teacher E.1. Algorithmic Details E.1.1. CHOICE OFCONDITIONALPROBABILITYP...
2024
-
[31]
20 Adversarial Dual On-Policy Distillation from Expressive Teacher Table 2.Details of hyperparameters in FA-OPD
They cover the FM-enhanced discriminator, the FM vector field, distance-based reward, and training logistics. 20 Adversarial Dual On-Policy Distillation from Expressive Teacher Table 2.Details of hyperparameters in FA-OPD. Name Value Meaning fm num steps 100 FM time discretization steps (used for t indexing in discriminator and for FM-based generation). d...
1993
-
[32]
larger β always better
21 Adversarial Dual On-Policy Distillation from Expressive Teacher F.2. Hyperparameter Study The hyperparameter β in Eq. 11 weights the action-distillation term against the reward-distillation term, and therefore controls the trade-off between the two distillation modes. As shown in Figure 6, we conducted an ablation study on β in the Fetch-pick environme...
2084
-
[33]
Similar conclusions as in Section 4.2 could be derived based on these results. F.4. Controlled comparison of policy heads under a shared learned reward To isolate the policy head from the reward signal, all methods here share thesamelearned reward from our FM-enhanced discriminator; the only varied factor is the policy architecture. We additionally includ...
2024
-
[34]
realness
2 .(41) At test time, a1 is obtained by numerically integrating the ODE from a0 ∼ N(0, I) . FP is a supervise learning approach to clone the expert behavior. GAIL (Ho & Ermon, 2016).GAIL frames imitation as matching occupancy measures via an adversarial game between policyπ ϕ and discriminatorD ψ: min ψ max ϕ E(s,a)∼ρπϕ logD ψ(s, a) +E (s,a)∼ρE log(1−D ψ(...
2016
-
[35]
Why the IRL setting is the practically interesting one.A common implicit assumption in much of the online-FM RL literature is that the environment reward is known
is a sibling framework conceptually adjacent to all of these but operates on language-model outputs with a pre-trained teacher, so it is omitted from the table for clarity; FA-OPD can be read as the natural extension of OPD to control with a learned, co-trained teacher. Why the IRL setting is the practically interesting one.A common implicit assumption in...
2011
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.