JLT: Clean-Latent Prediction in Latent Diffusion Transformers
Pith reviewed 2026-06-29 18:08 UTC · model grok-4.3
The pith
Clean-latent prediction damps low-variance directions in frozen VAE space while velocity regression amplifies them, producing a large FID gap despite algebraic equivalence of the targets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
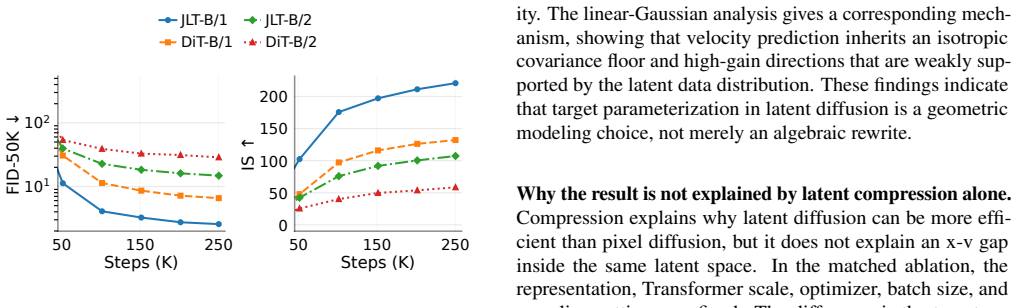
Although the variables x, epsilon, and v remain linearly convertible at any fixed corruption time, local Gaussian analysis reveals that velocity regression inherits an isotropic target-covariance floor and thereby amplifies low-variance latent directions, while clean prediction damps them. Under matched training conditions this geometric distinction produces a large performance gap: JLT-B/1 records FID-50K 2.50 with classifier-free guidance on ImageNet 256 imes256.
What carries the argument
Local Gaussian analysis of target covariances that distinguishes clean prediction's damping of low-variance directions from velocity regression's isotropic amplification floor.
If this is right
- Prediction targets in latent diffusion are representation-dependent geometric choices rather than interchangeable algebraic parameterizations.
- Clean prediction can continue to exploit low-dimensional structure after aggressive compression into VAE codes.
- Matched-target experiments under fixed backbone and schedule are required to expose performance differences hidden by algebraic equivalence.
- The advantage appears at the 130M-parameter scale on ImageNet 256 imes256.
Where Pith is reading between the lines
- The same covariance-floor argument may apply to other frozen autoencoders whose latent statistics deviate from isotropy.
- Target selection could be derived from an explicit estimate of the latent covariance spectrum rather than chosen by convention.
- The damping effect may interact with classifier-free guidance strength in ways not captured by the current matched-target runs.
Load-bearing premise
The frozen FLUX.2 VAE latent space behaves like a roughly isotropic Gaussian manifold in which low-variance directions are present and can be amplified or damped by the choice of regression target.
What would settle it
Training an otherwise identical velocity-prediction DiT on the same frozen FLUX.2 VAE codes and data and obtaining an FID-50K no higher than 2.50 with classifier-free guidance.
Figures

read the original abstract
Flow matching with clean-data prediction has shown that regressing the clean point can exploit low-dimensional structure more effectively than predicting an ambient noised quantity. We ask whether this principle remains useful after images are mapped into a learned latent space, where compression has already removed much of the raw pixel variability. We introduce JLT, a 130M latent diffusion Transformer over frozen FLUX.2 VAE codes, and compare clean-latent prediction with a matched velocity-prediction DiT under the same representation, backbone, and training settings. Although the three variables x, epsilon, and v are linearly convertible for a fixed corruption time, a local Gaussian analysis shows that velocity regression inherits an isotropic target-covariance floor and amplifies low-variance latent directions, while clean prediction damps them. On ImageNet 256 x 256, JLT-B/1 obtains FID-50K 2.50 with classifier-free guidance, with a large matched-target gap over velocity prediction. These results suggest that prediction targets in latent diffusion are representation-dependent geometric choices, rather than interchangeable algebraic parameterizations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces JLT, a 130M-parameter latent diffusion Transformer trained on frozen FLUX.2 VAE codes for ImageNet 256x256 generation. It compares clean-latent prediction against a matched velocity-prediction DiT under identical representation, backbone, and training settings. Although x, ε, and v are linearly convertible at fixed corruption time, a local Gaussian analysis is used to argue that velocity regression inherits an isotropic target-covariance floor and amplifies low-variance latent directions while clean prediction damps them. The authors report that JLT-B/1 achieves FID-50K of 2.50 with classifier-free guidance and a large matched-target gap over velocity prediction, concluding that prediction targets are representation-dependent geometric choices rather than interchangeable algebraic parameterizations.
Significance. If the local Gaussian analysis is empirically supported and the matched comparison is fair, the result would be significant for latent diffusion design: it would demonstrate that the choice of regression target interacts with the variance structure of the compressed latent space in ways that affect sample quality, even when targets are algebraically equivalent. The matched-target experimental protocol (same VAE, backbone, and settings) is a clear strength that isolates the target choice.
major comments (2)
- [Local Gaussian analysis] Local Gaussian analysis (abstract and theory section): the claimed geometric distinction—velocity regression amplifying low-variance directions while clean prediction damps them—holds only under the unverified premise that the frozen FLUX.2 VAE latent codes behave like a roughly isotropic Gaussian manifold with exploitable variance disparities. No direct measurement of the latent covariance spectrum or confirmation that low-variance directions are amplified under velocity targets on the actual codes is reported; this assumption is load-bearing for both the explanation of the FID gap and the broader claim that algebraic convertibility does not imply equivalent dynamics.
- [Results] Results section (FID-50K comparison): the large matched-target gap is presented as evidence, but without the precise definition of matched training settings (optimizer, schedule, batch size, number of steps) and statistical significance testing of the FID difference, it is difficult to assess whether the gap is robust or could be explained by minor implementation differences.
minor comments (2)
- [Abstract] The abstract and introduction could more explicitly state the precise architectural differences (if any) between JLT-B/1 and the velocity baseline beyond the prediction target.
- [Theory] Notation for the three targets (x, ε, v) and the local Gaussian analysis would benefit from an explicit equation block showing the target-covariance expressions.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We provide point-by-point responses below and will revise the manuscript accordingly to address the concerns raised.
read point-by-point responses
-
Referee: [Local Gaussian analysis] Local Gaussian analysis (abstract and theory section): the claimed geometric distinction—velocity regression amplifying low-variance directions while clean prediction damps them—holds only under the unverified premise that the frozen FLUX.2 VAE latent codes behave like a roughly isotropic Gaussian manifold with exploitable variance disparities. No direct measurement of the latent covariance spectrum or confirmation that low-variance directions are amplified under velocity targets on the actual codes is reported; this assumption is load-bearing for both the explanation of the FID gap and the broader claim that algebraic convertibility does not imply equivalent dynamics.
Authors: We acknowledge that the manuscript would benefit from empirical support for the latent space assumptions. In the revision, we will add a new figure in the appendix showing the eigenvalue spectrum of the covariance matrix computed over the FLUX.2 VAE latents from ImageNet. This will confirm the variance disparities. We will also include a brief analysis or experiment demonstrating the differential effect on low-variance directions for the two prediction targets, thereby grounding the local Gaussian analysis in the actual data distribution. revision: yes
-
Referee: [Results] Results section (FID-50K comparison): the large matched-target gap is presented as evidence, but without the precise definition of matched training settings (optimizer, schedule, batch size, number of steps) and statistical significance testing of the FID difference, it is difficult to assess whether the gap is robust or could be explained by minor implementation differences.
Authors: The manuscript emphasizes that the DiT baseline uses identical settings, but we agree that explicit enumeration improves clarity. We will update the experimental setup section to detail the optimizer (AdamW), learning rate, schedule, batch size, and training steps used for both models. For the FID gap, we note that such differences are typically evaluated by magnitude in the literature; however, we will report results from multiple seeds to indicate robustness and discuss the absence of formal statistical tests due to the high computational cost of FID evaluation. revision: partial
Circularity Check
No circularity: empirical FID gap and local Gaussian analysis are independent of training inputs
full rationale
The paper reports an empirical FID-50K comparison between clean-latent and velocity prediction under matched architecture and data, with the algebraic equivalence of x/ε/v explicitly acknowledged. The local Gaussian analysis derives target-covariance properties from the stated Gaussian manifold assumption on the frozen VAE latents rather than from any fitted parameter or self-referential definition. No equation reduces the reported performance gap to a quantity defined by the training data itself, and no self-citation chain or ansatz smuggling is present. The result is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
FLUX.2 Small Decoder
Black Forest Labs. FLUX.2 Small Decoder. https : / / huggingface . co / black-forest-labs / FLUX . 2-small-decoder, 2026. 4
2026
-
[2]
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei. ImageNet: A large-scale hierarchical image database. InCVPR, pages 248–255, 2009
2009
-
[3]
Dhariwal and A
P. Dhariwal and A. Q. Nichol. Diffusion models beat GANs on image synthesis. InNeurIPS, 2021
2021
-
[4]
Dosovitskiy, L
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. InICLR, 2021
2021
-
[5]
Gagneux, S
A. Gagneux, S. Martin, R. Gribonval, and M. Massias. Training flow matching: The role of weighting and parameterization. In 2nd DeLTa Workshop at ICLR, 2026
2026
-
[6]
Heusel, H
M. Heusel, H. Ramsauer, T. Unterthiner, B. Nessler, and S. Hochreiter. GANs trained by a two time-scale update rule converge to a local Nash equilibrium. InNeurIPS, 2017
2017
-
[7]
J. Ho, A. Jain, and P. Abbeel. Denoising diffusion probabilistic models. InNeurIPS, 2020
2020
-
[8]
Classifier-Free Diffusion Guidance
J. Ho and T. Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[9]
Jabri, D
A. Jabri, D. J. Fleet, and T. Chen. Scalable adaptive computation for iterative generation. InICML, pages 14569–14589, 2023
2023
- [10]
-
[11]
Karras, M
T. Karras, M. Aittala, T. Aila, and S. Laine. Elucidating the design space of diffusion-based generative models. InNeurIPS, 2022
2022
-
[12]
Back to Basics: Let Denoising Generative Models Denoise
T. Li and K. He. Back to basics: Let denoising generative models denoise.arXiv preprint arXiv:2511.13720, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Li and K
T. Li and K. He. JiT: Just image transformer implementation. https://github.com/LTH14/JiT, 2025
2025
-
[14]
Lipman, R
Y . Lipman, R. T. Q. Chen, H. Ben-Hamu, M. Nickel, and M. Le. Flow matching for generative modeling. InICLR, 2023
2023
-
[15]
X. Liu, C. Gong, and Q. Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. InICLR, 2023
2023
-
[16]
N. Ma, M. Goldstein, M. S. Albergo, N. M. Boffi, E. Vanden- Eijnden, and S. Xie. SiT: Exploring flow and diffusion-based generative models with scalable interpolant transformers. In ECCV, 2024
2024
-
[17]
Peebles and S
W. Peebles and S. Xie. Scalable diffusion models with trans- formers. InICCV, 2023
2023
-
[18]
Rombach, A
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer. High-resolution image synthesis with latent diffusion models. InCVPR, pages 10684–10695, 2022
2022
-
[19]
Russakovsky, J
O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, A. C. Berg, and L. Fei-Fei. ImageNet large scale visual recognition challenge.In- ternational Journal of Computer Vision, 115(3):211–252, 2015
2015
-
[20]
Salimans, I
T. Salimans, I. Goodfellow, W. Zaremba, V . Cheung, A. Radford, and X. Chen. Improved techniques for training GANs. In NeurIPS, 2016
2016
-
[21]
Salimans and J
T. Salimans and J. Ho. Progressive distillation for fast sampling of diffusion models. InICLR, 2022
2022
-
[22]
Vaswani, N
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin. Attention is all you need. InNeurIPS, 2017
2017
-
[23]
Vincent, H
P. Vincent, H. Larochelle, Y . Bengio, and P.-A. Manzagol. Ex- tracting and composing robust features with denoising autoen- coders. InICML, pages 1096–1103, 2008
2008
-
[24]
Vincent, H
P. Vincent, H. Larochelle, I. Lajoie, Y . Bengio, and P.-A. Man- zagol. Stacked denoising autoencoders: Learning useful rep- resentations in a deep network with a local denoising criterion. Journal of Machine Learning Research, 11:3371–3408, 2010
2010
-
[25]
S. Yu, S. Kwak, H. Jang, J. Jeong, J. Huang, J. Shin, and S. Xie. Representation alignment for generation: Training diffusion transformers is easier than you think. InICLR, 2025
2025
-
[26]
RiT: Vanilla Diffusion Transformers Suffice in Representation Space
L. Zhang, N. Mang, and A. Agrawal. RiT: Vanilla diffusion transformers suffice in representation space.arXiv preprint arXiv:2605.21981, 2026. 5 Appendix A Target Conversions and Error Scal- ing For fixed t, any one of the targets in Eq. (2) determines the other two endpoint variables by an affine readout from the predicted target and the known mixture zt....
work page internal anchor Pith review Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.