Causal Risk Minimization for High-Dimensional Treatments
Pith reviewed 2026-06-29 18:09 UTC · model grok-4.3
The pith
Under no unobserved confounding, causal error for high-dimensional treatments decomposes into moment-balancing errors of increasing order that can be optimized directly.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Under standard assumptions like no unobserved confounding, causal error decomposes into a series of moment-balancing errors of increasing order, and objectives are designed that directly improve causal estimation. The effect of a high-dimensional treatment can be projected onto lower-dimensional treatment attributes, allowing a single model to answer several causal questions without additional attribute-specific training.
What carries the argument
Decomposition of causal error into moment-balancing errors of increasing order, together with projection of high-dimensional treatment effects onto lower-dimensional attributes.
If this is right
- Optimizing higher-order moment-balancing objectives yields better causal estimates than standard methods in high-dimensional settings.
- A single trained model can produce projected causal estimates for multiple treatment attributes without retraining.
- The approach applies to continuous, discrete, and text-based treatments.
Where Pith is reading between the lines
- The decomposition may allow causal models to handle intervention spaces too large to enumerate, such as all possible text strings.
- If the moment-balancing view holds, similar error breakdowns could be derived for other high-dimensional inference tasks outside causal settings.
- Projection onto attributes could reduce the need for separate models when many related causal questions are asked about the same high-dimensional input.
Load-bearing premise
No unobserved confounding must hold so that the causal error decomposition into moment-balancing terms remains valid and the resulting objectives improve estimates.
What would settle it
Run the proposed objectives on data generated with known unobserved confounding and check whether the higher-order balance errors fail to decrease or the estimators underperform standard methods.
Figures

read the original abstract
Predicting the effect of interventions with many possible variations, e.g., therapeutic content that affects mental health outcomes or an earnings call transcript that drives movement in share price, is useful across several domains. However, classical causal estimators tend to assume that all possible interventions are observed, which is infeasible when interventions vary widely, for instance, in the space of all text strings. We adapt a well-known approach of recasting causal inference as a learning problem, to address high-dimensional treatment spaces. Specifically, under standard assumptions like no unobserved confounding, we show that causal error decomposes into a series of moment-balancing errors of increasing order, and design objectives that directly improve causal estimation. We also show how to project the effect of a high-dimensional treatment onto lower-dimensional treatment attributes, which allows a single model to answer several causal questions without additional attribute-specific training. We empirically evaluate our estimators in settings with high-dimensional continuous, discrete, and text treatments, the last of which used a semi-synthetic dataset of Amazon Reviews. Our experiments demonstrate the benefit of higher-order balance error optimization and competitive performance of projected causal estimates with attribute-specific estimators.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper adapts causal inference as a learning problem to high-dimensional treatment spaces (e.g., text). Under no unobserved confounding, it claims that causal error decomposes into a series of moment-balancing errors of increasing order, designs objectives to optimize these directly, and introduces a projection of high-dimensional treatment effects onto lower-dimensional attributes so that one model can answer multiple causal queries. Experiments on high-dimensional continuous, discrete, and text treatments (including a semi-synthetic Amazon Reviews dataset) show benefits from higher-order balancing and competitive performance versus attribute-specific estimators.
Significance. If the decomposition and objectives are correctly derived, the work offers a principled extension of balancing-based causal methods to regimes where the full treatment space cannot be enumerated, which is relevant for text and other complex interventions. The projection technique is a practical contribution that avoids retraining per attribute. The semi-synthetic text experiment is a concrete strength, as is the explicit comparison of first- versus higher-order balancing.
major comments (2)
- [§3.2] §3.2, the error decomposition into moment-balancing terms of increasing order: the step from the causal risk to the series of balancing conditions relies on an expansion whose remainder term is not bounded in the provided derivation; without an explicit rate or truncation argument, it is unclear whether optimizing only the first k terms yields consistent improvement in finite samples.
- [§4.1, Eq. (8)] §4.1, Eq. (8) (projected estimator): the claim that the projection onto lower-dimensional attributes preserves identification under the no-unobserved-confounding assumption is stated without a supporting lemma showing that the conditional independence relations survive the projection operator; a short proof or counter-example would be needed to confirm this is not an additional assumption.
minor comments (2)
- [§2 and §4] Notation for the treatment space and the attribute map is introduced inconsistently between §2 and §4; a single table of symbols would improve readability.
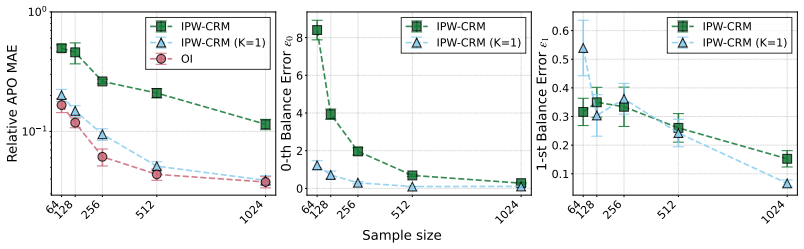
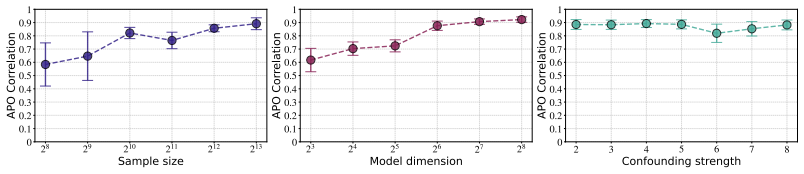
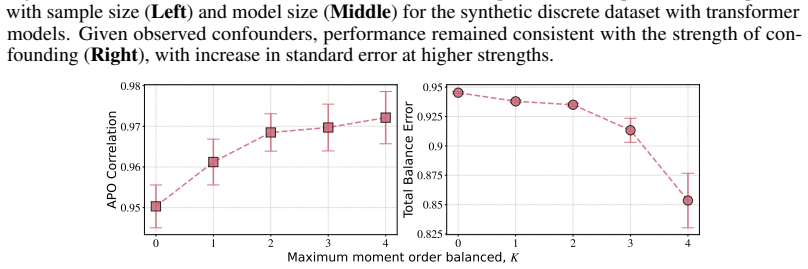
- [Figure 3] Figure 3 caption does not state the number of Monte Carlo replications or the precise definition of the error bars.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address each major comment below and will revise the manuscript accordingly to strengthen the theoretical foundations.
read point-by-point responses
-
Referee: [§3.2] §3.2, the error decomposition into moment-balancing terms of increasing order: the step from the causal risk to the series of balancing conditions relies on an expansion whose remainder term is not bounded in the provided derivation; without an explicit rate or truncation argument, it is unclear whether optimizing only the first k terms yields consistent improvement in finite samples.
Authors: We agree that the derivation in §3.2 expands the causal risk into a series of moment-balancing errors but does not explicitly bound the remainder term after k orders. In the revision we will add a supporting analysis that bounds the truncation error under standard moment conditions on the treatment distribution, and we will discuss the resulting finite-sample implications. This addition will directly address the concern while aligning with the empirical gains from higher-order balancing shown in our experiments. revision: yes
-
Referee: [§4.1, Eq. (8)] §4.1, Eq. (8) (projected estimator): the claim that the projection onto lower-dimensional attributes preserves identification under the no-unobserved-confounding assumption is stated without a supporting lemma showing that the conditional independence relations survive the projection operator; a short proof or counter-example would be needed to confirm this is not an additional assumption.
Authors: The referee is correct that the identification claim for the projected estimator in §4.1 lacks an explicit lemma. We will insert a short lemma proving that, under the maintained no-unobserved-confounding assumption, the projection onto lower-dimensional attributes preserves the relevant conditional independence relations required for identification. The lemma will confirm that no additional assumptions are introduced. revision: yes
Circularity Check
No significant circularity
full rationale
The paper's central claim is a mathematical decomposition of causal error into moment-balancing terms under standard no-unobserved-confounding assumptions, followed by the design of corresponding objectives. This is a direct derivation from the causal risk functional rather than a self-referential fit or imported uniqueness result. No equations or steps in the abstract reduce a prediction to its own inputs by construction, and no load-bearing self-citations are invoked to justify the decomposition. The projection onto lower-dimensional attributes is presented as a consequence of the same framework. The derivation is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption No unobserved confounding
Reference graph
Works this paper leans on
-
[1]
Althoff, T., Clark, K., and Leskovec, J. (2016). Large-scale analysis of counseling conversations: An application of natural language processing to mental health.Transactions of the Association for Computational Linguistics, 4:463–476
2016
-
[2]
W., and Wager, S
Athey, S., Imbens, G. W., and Wager, S. (2018). Approximate residual balancing: debiased inference of average treatment effects in high dimensions.Journal of the Royal Statistical Society Series B: Statistical Methodology, 80(4):597–623
2018
-
[3]
T., and Heckerman, D
Bahadori, T., Tchetgen, E. T., and Heckerman, D. (2022). End-to-end balancing for causal continuous treatment-effect estimation. InInternational conference on machine learning, pages 1313–1326. PMLR
2022
-
[4]
Bertagnolli, N. (2020). Counsel chat: Bootstrapping high-quality therapy data
2020
-
[5]
Capstick, A., Krishnan, R. G., and Barnaghi, P. (2025). Autoelicit: Using large language models for expert prior elicitation in predictive modelling, 2025.URL https://arxiv. org/abs/2411.17284
- [6]
-
[7]
A., Roh, L., Raja, N., Vangala, S., Modi, H., Pandya, S., Sloyan, M., and Croymans, D
Dai, H., Saccardo, S., Han, M. A., Roh, L., Raja, N., Vangala, S., Modi, H., Pandya, S., Sloyan, M., and Croymans, D. M. (2021). Behavioural nudges increase covid-19 vaccinations.Nature, 597(7876):404–409
2021
-
[8]
G., and Maddison, C
Dhawan, N., Cotta, L., Ullrich, K., Krishnan, R. G., and Maddison, C. J. (2024). End-to-end causal effect estimation from unstructured natural language data.Advances in Neural Information Processing Systems, 37:77165–77199
2024
-
[9]
Du, X., Sun, L., Duivesteijn, W., Nikolaev, A., and Pechenizkiy, M. (2021). Adversarial balancing-based representation learning for causal effect inference with observational data.Data Mining and Knowledge Discovery, 35(4):1713–1738
2021
-
[10]
P., Cummins, R., Tablan, V ., Bateup, S., Catarino, A., Martin, A
Ewbank, M. P., Cummins, R., Tablan, V ., Bateup, S., Catarino, A., Martin, A. J., and Blackwell, A. D. (2020). Quantifying the association between psychotherapy content and clinical outcomes using deep learning.JAMA psychiatry, 77(1):35–43
2020
-
[11]
A., Manzoor, E., Pryzant, R., Sridhar, D., Wood-Doughty, Z., Eisenstein, J., Grimmer, J., Reichart, R., Roberts, M
Feder, A., Keith, K. A., Manzoor, E., Pryzant, R., Sridhar, D., Wood-Doughty, Z., Eisenstein, J., Grimmer, J., Reichart, R., Roberts, M. E., et al. (2022). Causal inference in natural language processing: Estimation, prediction, interpretation and beyond.Transactions of the Association for Computational Linguistics, 10:1138–1158
2022
-
[12]
and Grimmer, J
Fong, C. and Grimmer, J. (2016). Discovery of treatments from text corpora. InProceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1600–1609
2016
-
[13]
Fong, C., Hazlett, C., and Imai, K. (2018). Covariate balancing propensity score for a continuous treatment: Application to the efficacy of political advertisements.The Annals of Applied Statistics, 12(1):156–177
2018
-
[14]
L., Knuth, D
Graham, R. L., Knuth, D. E., and Patashnik, O. (1994).Concrete mathematics: a foundation for computer science. Addison-Wesley, 2nd edition. 10
1994
-
[15]
G., Morstatter, F., and Lerman, K
Guo, S., Marmarelis, M. G., Morstatter, F., and Lerman, K. (2024). Estimating causal effects of text interventions leveraging llms.arXiv preprint arXiv:2410.21474
-
[16]
Hainmueller, J. (2012). Entropy balancing for causal effects: A multivariate reweighting method to produce balanced samples in observational studies.Political analysis, 20(1):25–46
2012
-
[17]
Hassan, T. A. (2020). Firm-level exposure to epidemic diseases: Covid-19, sars, and h1n1 tarek a. hassan, stephan hollander, laurence van lent, and ahmed tahoun
2020
-
[18]
and Greiner, R
Hassanpour, N. and Greiner, R. (2019). Counterfactual regression with importance sampling weights. InIJCAI, pages 5880–5887. Macao
2019
-
[19]
and Imbens, G
Hirano, K. and Imbens, G. (2005).The Propensity Score with Continuous Treatments, pages 73–84. Wiley-Blackwell
2005
-
[20]
W., and Ridder, G
Hirano, K., Imbens, G. W., and Ridder, G. (2003). Efficient estimation of average treatment effects using the estimated propensity score.Econometrica, 71(4):1161–1189
2003
-
[21]
Holland, P. W. (1986). Statistics and causal inference.Journal of the American statistical Association, 81(396):945–960
1986
-
[22]
Horvitz, D. G. and Thompson, D. J. (1952). A generalization of sampling without replacement from a finite universe.Journal of the American statistical Association, 47(260):663–685
1952
-
[23]
Hou, Y ., Li, J., He, Z., Yan, A., Chen, X., and McAuley, J. (2024). Bridging language and items for retrieval and recommendation.arXiv preprint arXiv:2403.03952
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Causal Inference with Generative Artificial Intelligence: Application to Texts as Treatments
Imai, K. and Nakamura, K. (2024). Causal representation learning with generative artificial intelligence: Application to texts as treatments.arXiv preprint arXiv:2410.00903
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
and Ratkovic, M
Imai, K. and Ratkovic, M. (2014). Covariate balancing propensity score.Journal of the Royal Statistical Society Series B: Statistical Methodology, 76(1):243–263
2014
-
[26]
Jung, Y ., Tian, J., and Bareinboim, E. (2020). Learning causal effects via weighted empirical risk minimization.Advances in neural information processing systems, 33:12697–12709
2020
-
[27]
Kallus, N. (2020a). Deepmatch: Balancing deep covariate representations for causal inference using adversarial training. InInternational Conference on Machine Learning, pages 5067–5077. PMLR
-
[28]
Kallus, N. (2020b). Generalized optimal matching methods for causal inference.Journal of Machine Learning Research, 21(62):1–54
-
[29]
and Ester, M
Kazemi, A. and Ester, M. (2024). Adversarially balanced representation for continuous treatment effect estimation. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 13085–13093
2024
-
[30]
Lopez, M. J. and Gutman, R. (2017). Estimation of causal effects with multiple treatments: a review and new ideas.Statistical Science, pages 432–454
2017
- [31]
-
[32]
L., Patel, M
Milkman, K. L., Patel, M. S., Gandhi, L., Graci, H. N., Gromet, D. M., Ho, H., Kay, J. S., Lee, T. W., Akinola, M., Beshears, J., et al. (2021). A megastudy of text-based nudges encouraging patients to get vaccinated at an upcoming doctor’s appointment.Proceedings of the National Academy of Sciences, 118(20):e2101165118
2021
-
[33]
Ongsakul, V ., Chatjuthamard, P., Chintrakarn, P., and Jiraporn, P. (2025). Leveraging the pandemic: exploring how covid exposure shapes capital structure using a text-based approach. Review of Behavioral Finance, 17(2):272–297
2025
- [34]
- [35]
-
[36]
Pryzant, R., Shen, K., Jurafsky, D., and Wagner, S. (2018). Deconfounded lexicon induction for interpretable social science. InProceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), pages 1615–1625
2018
-
[37]
M., Hernan, M
Robins, J. M., Hernan, M. A., and Brumback, B. (2000). Marginal structural models and causal inference in epidemiology
2000
-
[38]
Rosenbaum, P. R. (1987). Model-based direct adjustment.Journal of the American statistical Association, 82(398):387–394
1987
-
[39]
Rubin, D. B. (1977). Assignment to treatment group on the basis of a covariate.Journal of educational Statistics, 2(1):1–26
1977
-
[40]
Rubin, D. B. (1980). Randomization analysis of experimental data: The fisher randomization test comment.Journal of the American statistical association, 75(371):591–593
1980
-
[41]
Sharma, A., Gupta, G., Prasad, R., Chatterjee, A., Vig, L., and Shroff, G. (2020). Hi-ci: Deep causal inference in high dimensions. InProceedings of the 2020 KDD Workshop on Causal Discovery, pages 39–61. PMLR
2020
-
[42]
Shi, C., Blei, D., and Veitch, V . (2019). Adapting neural networks for the estimation of treatment effects.Advances in neural information processing systems, 32
2019
-
[43]
Singh, A., Fry, A., Perelman, A., Tart, A., Ganesh, A., El-Kishky, A., McLaughlin, A., Low, A., Ostrow, A., Ananthram, A., et al. (2025). Openai gpt-5 system card.arXiv preprint arXiv:2601.03267
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
and Joachims, T
Swaminathan, A. and Joachims, T. (2015). Counterfactual risk minimization: Learning from logged bandit feedback. InInternational conference on machine learning, pages 814–823. PMLR
2015
-
[45]
Wang, Y ., Li, H., Zhu, M., Wu, A., Li, B., Yin, K., Xiong, R., Wu, F., and Kuang, K. (2026). Causal inference with complex treatments: A survey.ACM Computing Surveys, 58(9):1–36
2026
-
[46]
L., Gugger, S., Drame, M., Lhoest, Q., and Rush, A
Wolf, T., Debut, L., Sanh, V ., Chaumond, J., Delangue, C., Moi, A., Cistac, P., Rault, T., Louf, R., Funtowicz, M., Davison, J., Shleifer, S., von Platen, P., Ma, C., Jernite, Y ., Plu, J., Xu, C., Scao, T. L., Gugger, S., Drame, M., Lhoest, Q., and Rush, A. M. (2020). Transformers: State-of-the-art natural language processing. InProceedings of the 2020 ...
2020
-
[47]
Wong, R. K. and Chan, K. C. G. (2018). Kernel-based covariate functional balancing for observational studies.Biometrika, 105(1):199–213
2018
-
[48]
Wood-Doughty, Z., Shpitser, I., and Dredze, M. (2018). Challenges of using text classifiers for causal inference. InProceedings of the 2018 conference on empirical methods in natural language processing, pages 4586–4598
2018
- [49]
-
[50]
and Shen, B
Yang, Z. and Shen, B. (2025). Estimating textual treatment effect via causal disentangled representation learning.The Journal of Supercomputing, 81(2):386
2025
-
[51]
Zhang, J., Mullainathan, S., and Danescu-Niculescu-Mizil, C. (2020). Quantifying the causal effects of conversational tendencies.Proceedings of the ACM on Human-Computer Interaction, 4(CSCW2):1–24
2020
-
[52]
Zhou, Y . and He, Y . (2023). Causal inference from text: Unveiling interactions between variables.arXiv preprint arXiv:2311.05286. 12 Appendix A Notation X Random variable corresponding to confounders. T Random variable corresponding to high-dimensional treatment. T ′ Random variable corresponding to low-dimensional treatment attribute. Y Random variable...
-
[53]
Rating: the rating out of5, e.g."4/5",
-
[54]
very positive
Sentiment:"very positive"if rating>4, else"negative or neutral",
-
[55]
more than 100 words
Length:"more than 100 words"or"less than 100 words". 17 D Experimental Details All hyperparameters were chosen on a validation split for each dataset and model. D.1 Linear Continuous Setting We used linear networks for the conditional outcome model and the APO model that maps treatments to APO targets, each trained with the Adam optimizer at learning rate...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.