Q-GeoMem: Question-Guided Geometric Memory for Video Spatial Reasoning
Pith reviewed 2026-06-29 18:12 UTC · model grok-4.3
The pith
Question-guided scoring of geometric evidence in two memory banks enables state-of-the-art video spatial reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
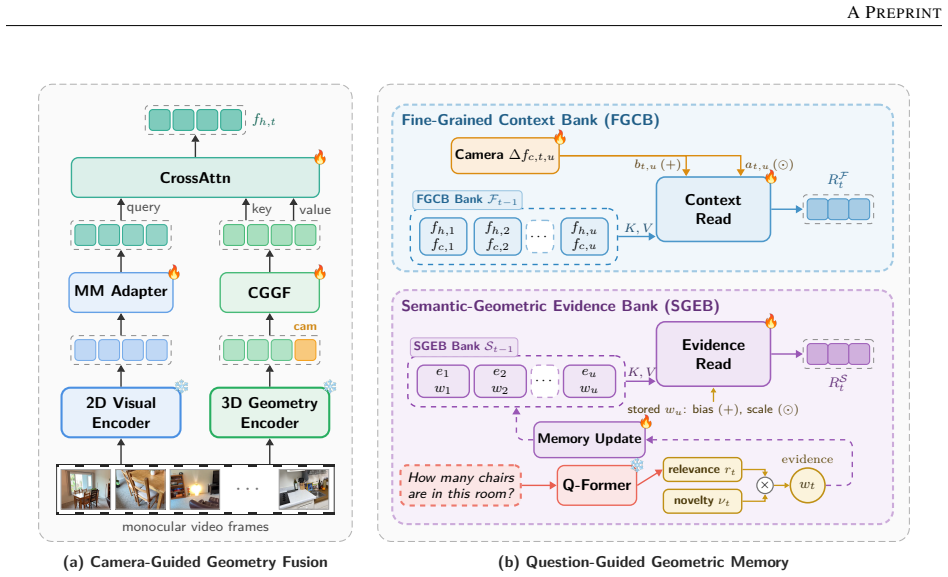
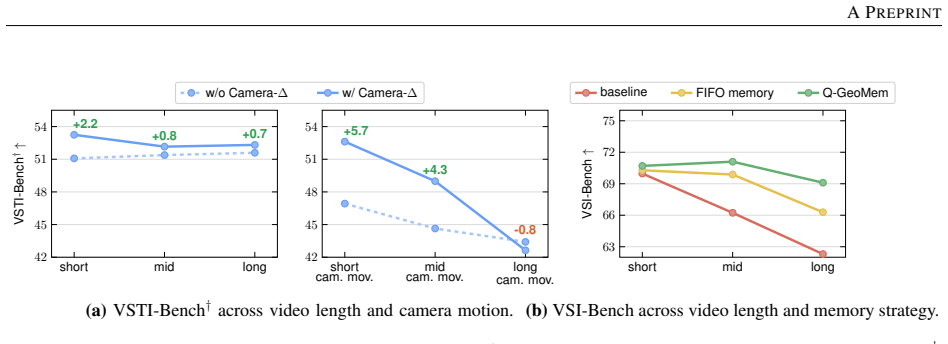
Q-GeoMem injects camera-conditioned geometry into visual tokens and maintains a Fine-Grained Context Bank for recent features plus a Semantic-Geometric Evidence Bank for long-range evidence. Each candidate frame receives a score equal to the product of its Q-Former question relevance and its novelty relative to the retained bank; the score is stored and the bank is kept compact by a capacity-based replacement rule. During reasoning the two memories are read before the update and adaptively fused with the current frame. On VSI-Bench and VSTI-Bench this produces state-of-the-art results among evaluated spatial reasoning models, with ablations confirming the scoring mechanism's contribution.
What carries the argument
The question-guided scoring mechanism that multiplies Q-Former relevance and novelty scores to decide which frames enter the Semantic-Geometric Evidence Bank.
If this is right
- The two-bank design separates recent dense context from compact long-range evidence, reducing redundancy while preserving question-useful geometry.
- Capacity-based replacement keeps memory size bounded without manual tuning of retention thresholds.
- Reading both banks before each update allows the current frame to be fused with prior evidence in a question-aware manner.
- Ablation results isolate the scoring step as a major contributor to the observed benchmark gains.
Where Pith is reading between the lines
- The same relevance-novelty product could be applied to other video tasks that need selective retention, such as action anticipation or object tracking over long sequences.
- If the Q-Former scoring generalizes across question types, the framework might extend to non-spatial video-language problems with only minor changes to the geometry injection step.
- Testing the method on videos longer than those in VSI-Bench would check whether the capacity rule continues to protect critical evidence as sequence length grows.
- Combining the memory banks with stronger camera-pose estimators could produce measurable further gains on benchmarks that stress viewpoint changes.
Load-bearing premise
The product of Q-Former question relevance and novelty scores reliably selects frames that supply useful geometric evidence without discarding information needed for long-horizon reasoning.
What would settle it
Replacing the relevance-novelty product with uniform or random frame selection on VSI-Bench and observing a drop below the reported performance would falsify the necessity of the question-guided scoring.
Figures

read the original abstract
Video spatial reasoning requires accumulating viewpoint-dependent evidence over time while retaining information useful to the question being asked. Existing spatial video-language models improve geometric perception and long-range context modeling, but often treat memory as a generic temporal cache, which can introduce redundant or irrelevant geometry and weaken long-horizon reasoning. We propose \textbf{\ours}, a question-guided geometric memory framework for video spatial reasoning. \ours injects camera-conditioned geometry into visual tokens and maintains two complementary memories: a Fine-Grained Context Bank for recent dense features and camera states, and a Semantic-Geometric Evidence Bank for compact long-range evidence. Each candidate frame is scored by the product of Q-Former-based question relevance and novelty with respect to the retained bank; this score is stored and reused during reading, while a capacity-based replacement rule keeps the bank compact. During reasoning, both memories are read before update and adaptively fused with the current frame representation. Experiments on VSI-Bench and VSTI-Bench show that \ours achieves state-of-the-art performance among evaluated spatial reasoning models, validating the effectiveness of question-guided geometric memory. Ablations further verify the contribution of the proposed evidence scoring mechanism.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Q-GeoMem, a question-guided geometric memory framework for video spatial reasoning. It injects camera-conditioned geometry into visual tokens and maintains two complementary memory structures: a Fine-Grained Context Bank storing recent dense features and camera states, and a Semantic-Geometric Evidence Bank holding compact long-range evidence. Candidate frames are scored by the product of Q-Former-based question relevance and novelty scores relative to the retained bank; a capacity-based replacement rule is applied, and both banks are read and adaptively fused during reasoning. The central claim is that this design yields state-of-the-art performance on VSI-Bench and VSTI-Bench, with ablations confirming the contribution of the evidence scoring mechanism.
Significance. If the empirical results hold, the work offers a concrete mechanism for making memory management question-dependent rather than generic, which could reduce redundancy in long-horizon video spatial reasoning. The dual-bank architecture together with the relevance-novelty product scoring rule constitutes a specific, testable design choice that directly targets the problem stated in the introduction. The paper supplies an empirical validation plan on two dedicated benchmarks and reports ablations on the scoring component.
major comments (2)
- [Abstract / Experiments] Abstract and experimental results section: the manuscript states that Q-GeoMem achieves state-of-the-art performance on VSI-Bench and VSTI-Bench and that ablations verify the scoring mechanism, yet supplies no numerical results, baseline comparisons, dataset statistics, or error bars. Without these data the central empirical claim cannot be assessed.
- [Ablations] The weakest assumption (product of Q-Former relevance and novelty reliably selects useful geometric evidence without discarding critical long-horizon information) is presented as validated by ablations, but no quantitative ablation isolating long-horizon cases or measuring information loss is described. This directly bears on whether the reported gains can be attributed to the proposed mechanism.
minor comments (2)
- [Introduction / Method] The terms 'Q-Former', 'Fine-Grained Context Bank', and 'Semantic-Geometric Evidence Bank' appear without an initial definition or citation on first use.
- [Method] Notation for the relevance-novelty product score and the capacity-based replacement rule should be introduced with explicit equations rather than prose description only.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and commit to revisions that strengthen the empirical presentation without altering the core claims.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and experimental results section: the manuscript states that Q-GeoMem achieves state-of-the-art performance on VSI-Bench and VSTI-Bench and that ablations verify the scoring mechanism, yet supplies no numerical results, baseline comparisons, dataset statistics, or error bars. Without these data the central empirical claim cannot be assessed.
Authors: The full manuscript's Experiments section contains tables reporting numerical results on VSI-Bench and VSTI-Bench, baseline comparisons, and ablation studies. We acknowledge that the abstract and the high-level experimental summary do not foreground these numbers. In the revision we will update the abstract to include key quantitative results and ensure the experimental results section explicitly presents dataset statistics, baseline tables, and error bars to allow direct assessment of the SOTA claim. revision: yes
-
Referee: [Ablations] The weakest assumption (product of Q-Former relevance and novelty reliably selects useful geometric evidence without discarding critical long-horizon information) is presented as validated by ablations, but no quantitative ablation isolating long-horizon cases or measuring information loss is described. This directly bears on whether the reported gains can be attributed to the proposed mechanism.
Authors: The manuscript already includes quantitative ablations that isolate the contribution of the relevance-novelty scoring rule through controlled comparisons. We agree that explicit long-horizon isolation and information-loss metrics would further strengthen attribution. The revised version will add a dedicated long-horizon ablation and report retention metrics, while retaining the existing ablation results. revision: partial
Circularity Check
No significant circularity
full rationale
The paper describes an empirical architecture consisting of camera-conditioned geometry injection, dual memory banks, and a Q-Former-based scoring rule for frame selection. No equations, derivations, or predictions are presented that reduce the claimed SOTA performance to a quantity defined by the authors' own prior work or by construction. The central claim rests on benchmark experiments and ablations rather than any self-referential mathematical step. This is the most common honest finding for a design-and-evaluation paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Scoring frames by the product of question relevance and novelty selects evidence that improves spatial reasoning performance
invented entities (2)
-
Fine-Grained Context Bank
no independent evidence
-
Semantic-Geometric Evidence Bank
no independent evidence
Reference graph
Works this paper leans on
-
[1]
HierarQ: Task-aware hierarchical Q-former for enhanced video understanding
Shehreen Azad, Vibhav Vineet, and Yogesh Singh Rawat. HierarQ: Task-aware hierarchical Q-former for enhanced video understanding. In2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 8545–8556, 2025. 9 A PREPRINT
2025
-
[2]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-VL technical report.ar...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Flexible frame selection for efficient video reasoning
Shyamal Buch, Arsha Nagrani, Anurag Arnab, and Cordelia Schmid. Flexible frame selection for efficient video reasoning. In2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 29071–29082, 2025
2025
-
[4]
LongVILA: Scaling Long-Context Visual Language Models for Long Videos
Yukang Chen, Fuzhao Xue, Dacheng Li, Qinghao Hu, Ligeng Zhu, Xiuyu Li, Yunhao Fang, Haotian Tang, Shang Yang, Zhijian Liu, Ethan He, Hongxu Yin, Pavlo Molchanov, Jan Kautz, Linxi Fan, Yuke Zhu, Yao Lu, and Song Han. LongVILA: Scaling long-context visual language models for long videos.arXiv:2408.10188, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
How Far Are We to GPT-4V? Closing the Gap to Commercial Multimodal Models with Open-Source Suites
Zhe Chen, Weiyun Wang, Hao Tian, Shenglong Ye, Zhangwei Gao, Erfei Cui, Wenwen Tong, Kongzhi Hu, Jiapeng Luo, Zheng Ma, Ji Ma, Jiaqi Wang, Xiaoyi Dong, Hang Yan, Hewei Guo, Conghui He, Botian Shi, Zhenjiang Jin, Chao Xu, Bin Wang, Xingjian Wei, Wei Li, Wenjian Zhang, Bo Zhang, Pinlong Cai, Licheng Wen, Xiangchao Yan, Min Dou, Lewei Lu, Xizhou Zhu, Tong Lu...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
ReWind: Understanding long videos with instructed learnable memory.arXiv:2411.15556, 2025
Anxhelo Diko, Tinghuai Wang, Wassim Swaileh, Shiyan Sun, and Ioannis Patras. ReWind: Understanding long videos with instructed learnable memory.arXiv:2411.15556, 2025
-
[7]
VLM-3R: Vision-Language Models Augmented with Instruction-Aligned 3D Reconstruction
Zhiwen Fan, Jian Zhang, Renjie Li, Junge Zhang, Runjin Chen, Hezhen Hu, Kevin Wang, Huaizhi Qu, Dilin Wang, Zhicheng Yan, Hongyu Xu, Justin Theiss, Tianlong Chen, Jiachen Li, Zhengzhong Tu, Zhangyang Wang, and Rakesh Ranjan. VLM-3R: Vision-Language Models Augmented with Instruction-Aligned 3D Reconstruction. arXiv:2505.20279, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
M-LLM based video frame selection for efficient video understanding
Kai Hu, Feng Gao, Xiaohan Nie, Peng Zhou, Son Tran, Tal Neiman, Lingyun Wang, Mubarak Shah, Raffay Hamid, Bing Yin, and Trishul Chilimbi. M-LLM based video frame selection for efficient video understanding. In 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 13702–13712, 2025
2025
-
[9]
Online video understanding: OVBench and VideoChat-online
Zhenpeng Huang, Xinhao Li, Jiaqi Li, Jing Wang, Xiangyu Zeng, Cheng Liang, Tao Wu, Xi Chen, Liang Li, and Limin Wang. Online video understanding: OVBench and VideoChat-online. In2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 3328–3338, 2025
2025
-
[10]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Mengdi Jia, Zekun Qi, Shaochen Zhang, Wenyao Zhang, Xinqiang Yu, Jiawei He, He Wang, and Li Yi. Om- niSpatial: Towards comprehensive spatial reasoning benchmark for vision language models.arXiv:2506.03135, 2026
-
[12]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, and Chunyuan Li. Llava-onevision: Easy visual task transfer.arXiv preprint arXiv:2408.03326, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Thinking with Geometry: Active Geometry Integration for Spatial Reasoning
Haoyuan Li, Qihang Cao, Tao Tang, Kun Xiang, Zihan Guo, Jianhua Han, Hang Xu, and Xiaodan Liang. Thinking with Geometry: Active Geometry Integration for Spatial Reasoning.arXiv:2602.06037, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[14]
Hongxing Li, Dingming Li, Zixuan Wang, Yuchen Yan, Hang Wu, Wenqi Zhang, Yongliang Shen, Weiming Lu, Jun Xiao, and Yueting Zhuang. SpatialLadder: Progressive training for spatial reasoning in vision-language models.arXiv:2510.08531, 2025
-
[15]
STI-Bench: Are MLLMs Ready for Precise Spatial-Temporal World Understanding?arXiv:2503.23765, 2025
Yun Li, Yiming Zhang, Tao Lin, Xiangrui Liu, Wenxiao Cai, Zheng Liu, and Bo Zhao. STI-Bench: Are MLLMs Ready for Precise Spatial-Temporal World Understanding?arXiv:2503.23765, 2025
-
[16]
VILA: On pre-training for visual language models.arXiv:2312.07533, 2024
Ji Lin, Hongxu Yin, Wei Ping, Yao Lu, Pavlo Molchanov, Andrew Tao, Huizi Mao, Jan Kautz, Mohammad Shoeybi, and Song Han. VILA: On pre-training for visual language models.arXiv:2312.07533, 2024
-
[17]
Vision-Language Memory for Spatial Reasoning.arXiv:2511.20644, 2025
Zuntao Liu, Yi Du, Taimeng Fu, Shaoshu Su, Cherie Ho, and Chen Wang. Vision-Language Memory for Spatial Reasoning.arXiv:2511.20644, 2025
-
[18]
SpaceR: Reinforcing MLLMs in Video Spatial Reasoning
Kun Ouyang, Yuanxin Liu, Haoning Wu, Yi Liu, Hao Zhou, Jie Zhou, Fandong Meng, and Xu Sun. SpaceR: Reinforcing MLLMs in video spatial reasoning.arXiv:2504.01805, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Streaming long video understanding with large language models.Advances in Neural Information Processing Systems, 37: 119336–119360, 2024
Rui Qian, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Shuangrui Ding, Dahua Lin, and Jiaqi Wang. Streaming long video understanding with large language models.Advances in Neural Information Processing Systems, 37: 119336–119360, 2024. 10 A PREPRINT
2024
-
[20]
Dispider: Enabling video LLMs with active real-time interaction via disentangled perception, decision, and reaction
Rui Qian, Shuangrui Ding, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Yuhang Cao, Dahua Lin, and Jiaqi Wang. Dispider: Enabling video LLMs with active real-time interaction via disentangled perception, decision, and reaction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 24045–24055, 2025
2025
-
[21]
Adaptive Keyframe Sampling for Long Video Understanding.arXiv:2502.21271, 2025
Xi Tang, Jihao Qiu, Lingxi Xie, Yunjie Tian, Jianbin Jiao, and Qixiang Ye. Adaptive Keyframe Sampling for Long Video Understanding.arXiv:2502.21271, 2025
-
[22]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Gemini Team, Petko Georgiev, Ving Ian Lei, Ryan Burnell, Libin Bai, Anmol Gulati, Garrett Tanzer, Damien Vincent, Zhufeng Pan, Shibo Wang, et al. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context.arXiv preprint arXiv:2403.05530, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
VideoLLaMB: Long Streaming Video Understanding with Recurrent Memory Bridges.arXiv:2409.01071, 2025
Yuxuan Wang, Yiqi Song, Cihang Xie, Yang Liu, and Zilong Zheng. VideoLLaMB: Long Streaming Video Understanding with Recurrent Memory Bridges.arXiv:2409.01071, 2025
-
[24]
Haomiao Xiong, Zongxin Yang, Jiazuo Yu, Yunzhi Zhuge, Lu Zhang, Jiawen Zhu, and Huchuan Lu. Streaming video understanding and multi-round interaction with memory-enhanced knowledge.arXiv:2501.13468, 2025
-
[25]
Gupta, Rilyn Han, Li Fei-Fei, and Saining Xie
Jihan Yang, Shusheng Yang, Anjali W. Gupta, Rilyn Han, Li Fei-Fei, and Saining Xie. Thinking in Space: How Multimodal Large Language Models See, Remember, and Recall Spaces. In2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10632–10643, 2025
2025
-
[26]
Visual spatial tuning.arXiv preprint arXiv:2511.05491, 2025
Rui Yang, Ziyu Zhu, Yanwei Li, Jingjia Huang, Shen Yan, Siyuan Zhou, Zhe Liu, Xiangtai Li, Shuangye Li, Wenqian Wang, Yi Lin, and Hengshuang Zhao. Visual spatial tuning.arXiv:2511.05491, 2025
-
[27]
MMSI-Bench: A Benchmark for Multi-Image Spatial Intelligence
Sihan Yang, Runsen Xu, Yiman Xie, Sizhe Yang, Mo Li, Jingli Lin, Chenming Zhu, Xiaochen Chen, Haodong Duan, Xiangyu Yue, Dahua Lin, Tai Wang, and Jiangmiao Pang. MMSI-Bench: A Benchmark for Multi-Image Spatial Intelligence.arXiv:2505.23764, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Flash-VStream: Efficient real-time understanding for long video streams
Haoji Zhang, Yiqin Wang, Yansong Tang, Yong Liu, Jiashi Feng, and Xiaojie Jin. Flash-VStream: Efficient real-time understanding for long video streams. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 21059–21069, 2025
2025
-
[29]
Long Context Transfer from Language to Vision
Peiyuan Zhang, Kaichen Zhang, Bo Li, Guangtao Zeng, Jingkang Yang, Yuanhan Zhang, Ziyue Wang, Haoran Tan, Chunyuan Li, and Ziwei Liu. Long context transfer from language to vision.arXiv:2406.16852, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
Llava-next: A strong zero-shot video understanding model
Yuanhan Zhang, Bo Li, Haotian Liu, Yong Jae Lee, Liangke Gui, Di Fu, Jiashi Feng, Ziwei Liu, and Chunyuan Li. Llava-next: A strong zero-shot video understanding model. LLaV A Blog, https://llava-vl.github.io/ blog/2024-04-30-llava-next-video, 2024
2024
-
[31]
SpaceMind: Camera-Guided Modality Fusion for Spatial Reasoning in Vision-Language Models
Ruosen Zhao, Zhikang Zhang, Jialei Xu, Jiahao Chang, Dong Chen, Lingyun Li, Weijian Sun, and Zizhuang Wei. SpaceMind: Camera-Guided Modality Fusion for Spatial Reasoning in Vision-Language Models. arXiv:2511.23075, 2025
-
[32]
Duo Zheng, Shijia Huang, Yanyang Li, and Liwei Wang. Learning from Videos for 3D World: Enhancing MLLMs with 3D Vision Geometry Priors.arXiv:2505.24625, 2025
-
[33]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shenglong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479, 2025. 11
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.