Feedforward 3D Editing Learns from Semantic-Part Transformation
Pith reviewed 2026-06-29 17:54 UTC · model grok-4.3
The pith
Semantic-part transformations create high-quality paired data that trains feedforward 3D editors to state-of-the-art performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
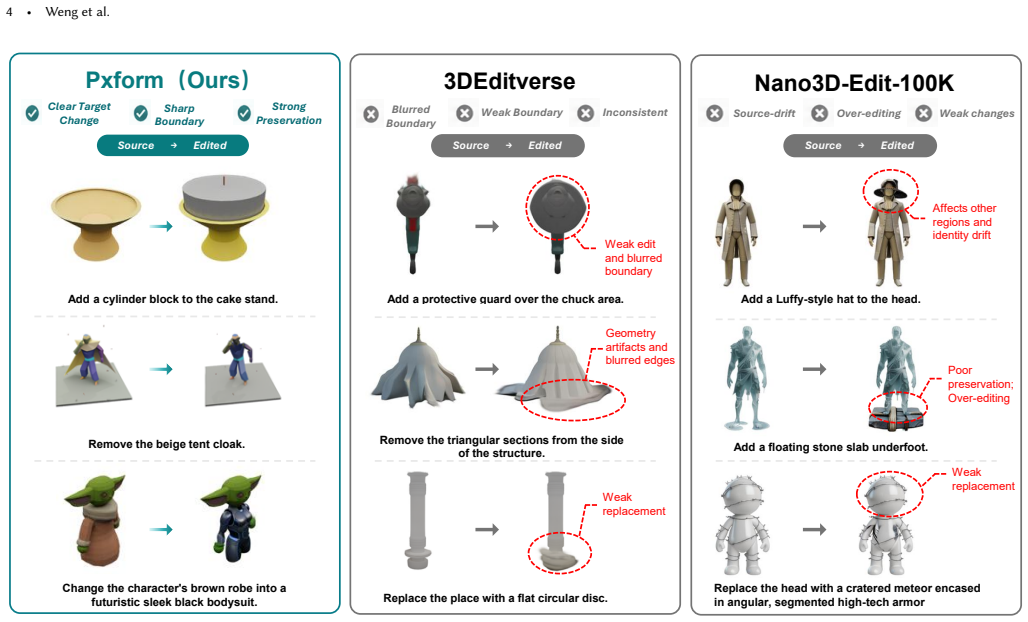
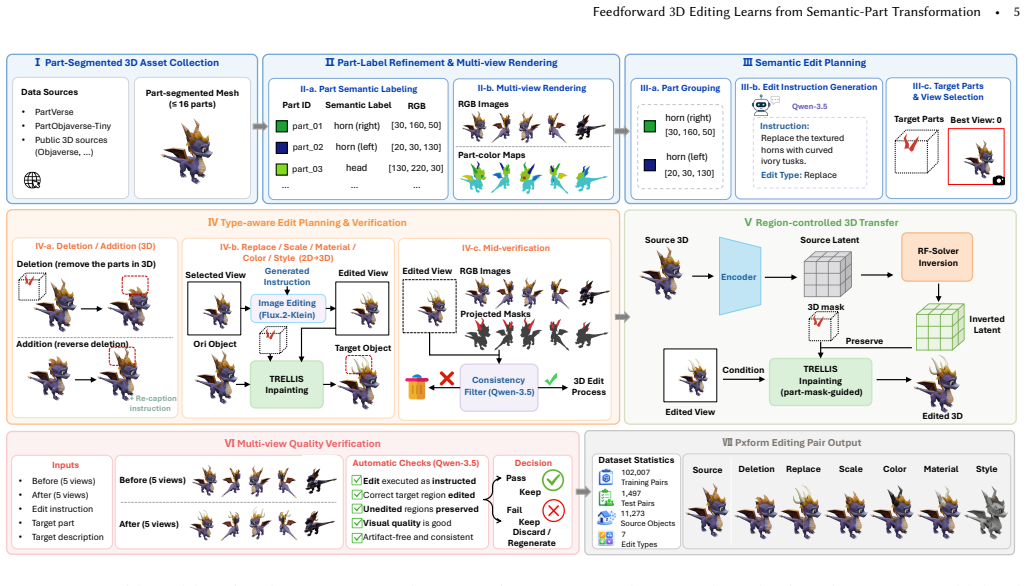
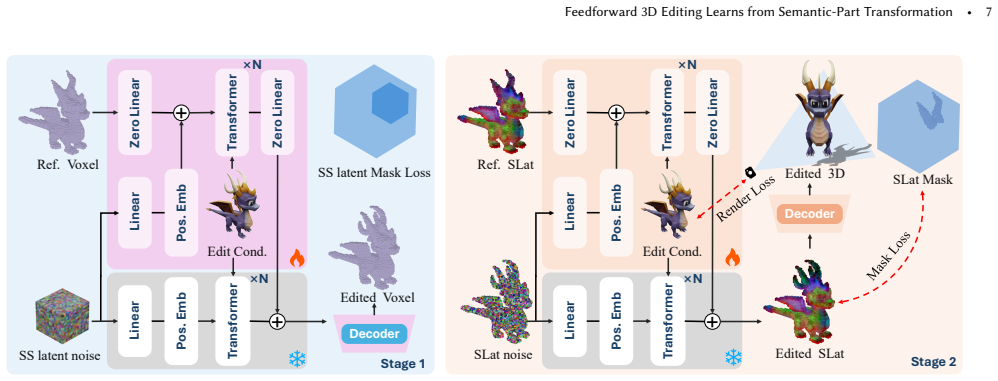
Scalable feedforward 3D editing should be learned from semantic-part transformations. The Pxform pipeline produces over 100K consistent before/after pairs by grounding edits in semantic 3D parts rather than unstructured shapes, overcoming inaccurate localization and weak preservation. PartFlow then adds source-aware latent control to pretrained 3D generative priors together with mask-aware velocity preservation and render-space consistency supervision, jointly raising edit fidelity and source preservation while requiring no 3D edit mask at inference and reaching state-of-the-art results on both geometric and appearance editing benchmarks.
What carries the argument
Pxform dataset pipeline that grounds edits in semantic 3D parts to generate consistent paired data, and PartFlow network that injects source-aware latent control into pretrained priors with mask-aware velocity preservation and render-space consistency supervision.
If this is right
- High-quality semantic-part supervision improves both edit fidelity and source preservation in feedforward models.
- PartFlow achieves state-of-the-art results on geometric and appearance editing benchmarks without 3D edit masks at inference.
- Grounding edits in semantic parts enables consistent multi-view pairs that support scalable training.
- The approach applies across seven edit types while maintaining structural coherence and localized controllability.
Where Pith is reading between the lines
- Part-based pairing strategies could be applied to other generative tasks such as 3D animation or scene composition where structural consistency matters.
- The emphasis on render-space consistency suggests that similar supervision might improve multi-view diffusion models used for 3D generation.
- If semantic parts drive performance, then explicit part segmentation modules inside editing networks could yield further gains on complex objects.
- Dataset construction methods like Pxform may transfer to text-conditioned or image-conditioned 3D editing by replacing manual part labels with automatic semantic extraction.
Load-bearing premise
Grounding edits in semantic 3D parts produces high-quality consistent before/after pairs that overcome the inaccurate localization and weak preservation of earlier datasets.
What would settle it
Training PartFlow on Pxform and evaluating it on standard geometric and appearance 3D editing benchmarks shows performance no better than existing training-free or feedforward methods.
Figures











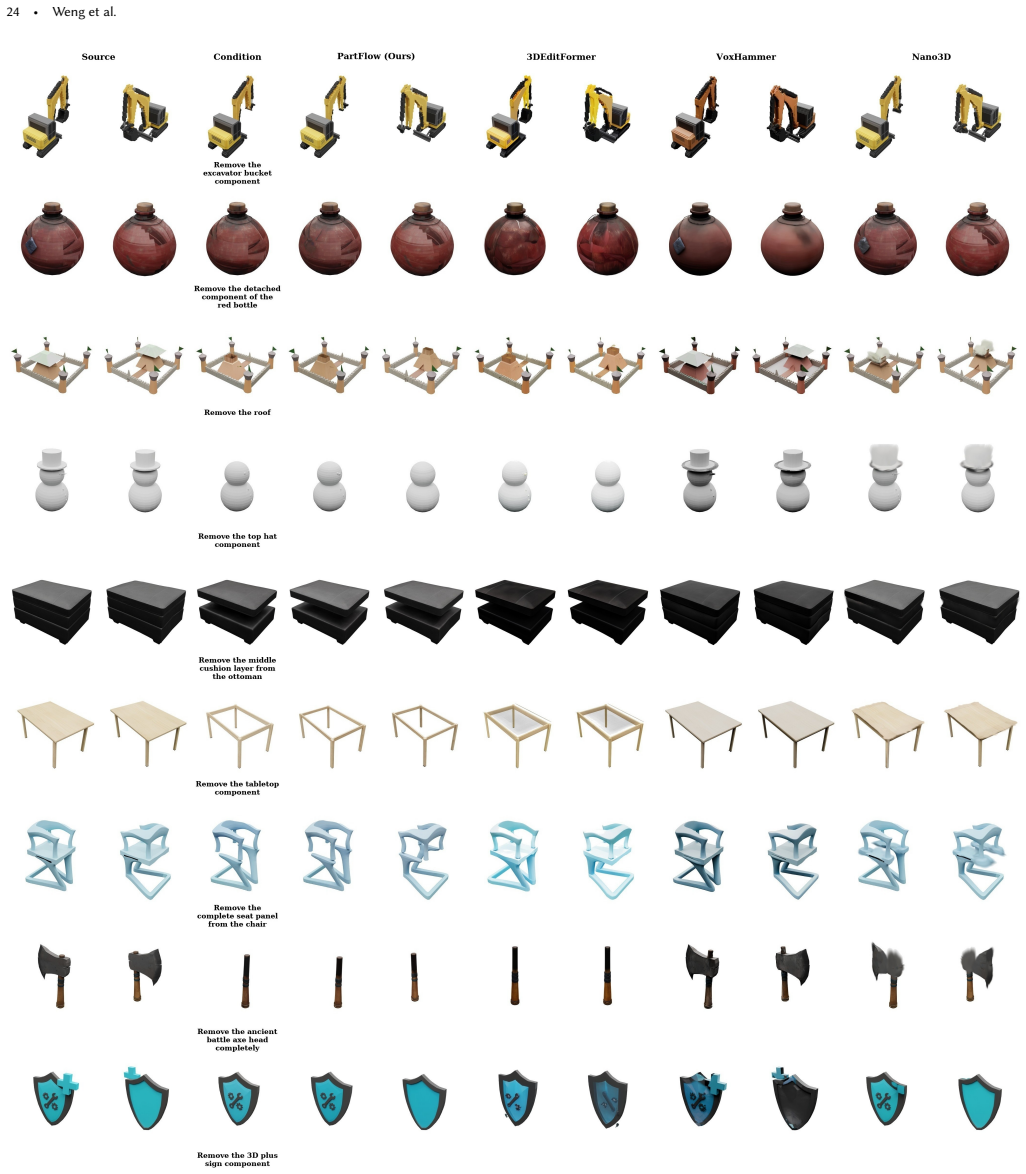







read the original abstract
3D editing is a fundamental capability for scalable 3D content creation. While image editing has rapidly evolved toward large-scale feedforward generative paradigms, 3D AI generation remains dominated by training-free editing pipelines. A central challenge of feedforward 3D editing lies in the lack of high-quality paired supervision. Editable 3D assets require simultaneous preservation of geometry, multi-view consistency, structural coherence, and localized edit controllability. Existing 3D editing datasets often rely on independently generated assets, image-mediated reconstruction or narrow edit taxonomies, leading to inaccurate localization, weak preservation, blurred edit boundaries, and limited semantic consistency. In this work, we introduce a new perspective: scalable feedforward 3D editing should be learned from semantic-part transformations. Based on this insight, we propose Pxform, a high-quality 3D editing dataset with over 100K consistent before/after editing pairs across seven edit types. Instead of treating objects as unstructured shapes, our pipeline grounds edits directly in semantic 3D parts. Built upon Pxform, we further propose PartFlow, a feedforward 3D editing network that injects source-aware latent control into pretrained 3D generative priors. PartFlow introduces mask-aware velocity preservation and render-space consistency supervision to jointly improve edit fidelity and source preservation, while requiring no 3D edit mask during inference. Extensive experiments demonstrate that high-quality semantic-part supervision substantially improves scalable 3D editing, enabling PartFlow to achieve state-of-the-art performance on both geometric and appearance editing benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that grounding 3D edits in semantic parts enables construction of a high-quality paired dataset (Pxform) with >100K before/after pairs across seven edit types, which in turn supports training of a feedforward model (PartFlow). PartFlow injects source-aware latent control into pretrained 3D generative priors and adds mask-aware velocity preservation plus render-space consistency supervision; the resulting model reaches SOTA on geometric and appearance editing benchmarks while requiring no 3D edit mask at inference. The central motivation is that prior datasets suffer from inaccurate localization, weak preservation, and blurred boundaries, problems that semantic-part grounding is asserted to solve.
Significance. If the dataset construction and experimental claims hold, the work supplies a concrete, scalable source of paired supervision for feedforward 3D editing—an area currently dominated by training-free pipelines. The explicit linkage between semantic-part transformations, preservation mechanisms, and benchmark gains is a coherent contribution that could accelerate controllable 3D content creation. The paper ships a new dataset and an inference-efficient architecture; these are the primary assets that would be evaluated by the community.
minor comments (3)
- The abstract states that PartFlow 'requires no 3D edit mask during inference,' yet the training procedure relies on mask-aware velocity preservation; a short paragraph clarifying how the mask signal is obtained or approximated at training time would improve reproducibility.
- The seven edit types are listed but not enumerated; adding a table or figure that shows one representative pair per type (with the semantic part highlighted) would make the dataset construction more transparent.
- The claim of 'state-of-the-art performance on both geometric and appearance editing benchmarks' would be strengthened by an explicit statement of the exact metrics and baselines used, even if the numbers appear later in the experimental section.
Simulated Author's Rebuttal
We thank the referee for the positive summary of our work and the recommendation for minor revision. The report does not list any specific major comments, so there are no individual points requiring a point-by-point response.
Circularity Check
No significant circularity detected
full rationale
The paper introduces a dataset construction pipeline (Pxform) grounded in semantic 3D parts and a feedforward editing network (PartFlow) that adds mask-aware velocity preservation and render-space consistency. No equations, fitted parameters, or derivations appear in the provided text. The central claims rest on the explicit design choices that target documented weaknesses of prior datasets (inaccurate localization, weak preservation), without any reduction of outputs to inputs by construction, self-citation load-bearing premises, or ansatzes smuggled via prior work. This is a standard empirical dataset-plus-model contribution whose value is external to any internal definitional loop.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Objaverse: A Universe of Annotated 3D Objects. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 13142–13153. https://arxiv.org/abs/2212.08051 Shaocong Dong, Lihe Ding, Xiao Chen, Yaokun Li, Yuxin Wang, Yucheng Wang, Qi Wang, Jaehyeok Kim, Chenjian Gao, Zhanpeng Huang, Zibin Wang, Tianfan Xue, and Dan Xu. 2025. From One ...
-
[2]
Efros, Aleksander Holynski, and Angjoo Kanazawa
https://openaccess.thecvf.com/content_ICCV_2019/html/Gkioxari_Mesh_R- CNN_ICCV_2019_paper.html Ayaan Haque, Matthew Tancik, Alexei A. Efros, Aleksander Holynski, and Angjoo Kanazawa. 2023. Instruct-NeRF2NeRF: Editing 3D Scenes with Instructions. In Proceedings of the IEEE/CVF International Conference on Computer Vision. Zexin He and Tengfei Wang. 2023. Op...
-
[3]
arXiv:2512.21185 [cs.CV] https: //arxiv.org/abs/2512.21185 Heewoo Jun and Alex Nichol
UltraShape 1.0: High-Fidelity 3D Shape Generation via Scalable Geometric Refinement.arXiv preprint arXiv:2512.21185(2025). arXiv:2512.21185 [cs.CV] https: //arxiv.org/abs/2512.21185 Heewoo Jun and Alex Nichol. 2023. Shap-E: Generating Conditional 3D Implicit Functions.arXiv preprint arXiv:2305.02463(2023). Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühl...
-
[4]
arXiv preprint arXiv:2412.08629(2024)
FlowEdit: Inversion-Free Text-Based Editing Using Pre-Trained Flow Models. arXiv preprint arXiv:2412.08629(2024). arXiv:2412.08629 [cs.CV] https://arxiv.org/ abs/2412.08629 Zeqiang Lai, Yunfei Zhao, Zibo Zhao, Haolin Liu, Qingxiang Lin, Jingwei Huang, Chunchao Guo, and Xiangyu Yue. 2025. LATTICE: Democratize High-Fidelity 3D Generation at Scale.arXiv prep...
-
[5]
InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wonder3D: Single Image to 3D using Cross-Domain Diffusion. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Changfeng Ma, Yang Li, Xinhao Yan, Jiachen Xu, Yunhan Yang, Chunshi Wang, Zibo Zhao, Yanwen Guo, Zhuo Chen, and Chunchao Guo. 2025b. P3-SAM: Native 3D Part Segmentation. arXiv:2509.06784 [cs.CV] doi:10.48550/arXiv...
-
[6]
PartNeXt: A Next-Generation Dataset for Fine-Grained and Hierarchical 3D Part Understanding. arXiv:2510.20155 [cs.CV] doi:10.48550/arXiv.2510.20155 Yuxuan Wang, Xuanyu Yi, Zike Wu, Na Zhao, Long Chen, and Hanwang Zhang. 2024c. View-consistent 3d editing with gaussian splatting. InEuropean conference on computer vision. Springer, 404–420. Zhou Wang, Alan C...
-
[7]
Native and Compact Structured Latents for 3D Generation
Native and Compact Structured Latents for 3D Generation.arXiv preprint arXiv:2512.14692(2025). arXiv:2512.14692 [cs.CV] https://arxiv.org/abs/2512.14692 Jianfeng Xiang, Zelong Lv, Sicheng Xu, Yu Deng, Ruicheng Wang, Bowen Zhang, Dong Chen, Xin Tong, and Jiaolong Yang. 2024. Structured 3D Latents for Scalable and Versatile 3D Generation.arXiv preprint arXi...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2509.08643 2025
-
[8]
Generate exactly the requested number of edits according to the quota
-
[9]
Select valid target parts from the supplied part list
-
[10]
Group repeated instances into one edit when they form a semantic unit, e.g., both wheels or all chair legs
-
[11]
Group semantically coupled components when appropriate, e.g., eyes, nose, and mouth as a head-level edit
-
[12]
Avoid deleting the primary structural body of the object
-
[13]
Use clear English imperative edit instructions
-
[14]
new_part_desc
Produce target descriptions and after-edit descriptions suitable for downstream editing and verification. Rules: R1. selected_part_ids must be a subset of the input part list. R2. No two edits may share the same (edit_type, selected_part_ids) pair. R3. Global edits must use selected_part_ids = []. R4. Deletion cannot target the primary structural body. R5...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.