Genetic algorithm vs. gradient descent for training a neural network architecture dedicated to low data regimes in small medical datasets
Pith reviewed 2026-06-30 21:17 UTC · model grok-4.3
The pith
Genetic algorithm training outperforms gradient descent for distance-encoded biomorphic neural networks on small medical datasets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
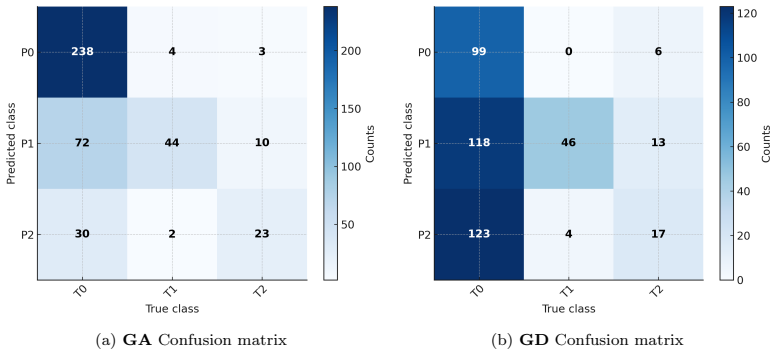
DEBI-NN defines connection weights via distances between neurons placed in Euclidean space, which reduces trainable parameters. When a spatial backpropagation scheme is used to train it with gradient descent, the optimizer consistently underperforms a genetic algorithm approach: accuracies reach only 83% versus 100% on synthetic data, 78% versus 83% on DLBCL, 67% versus 80% on HECKTOR, and 66% versus 81% on fetal data. The paper attributes the gap to entangled gradients arising from neuron interdependencies that limit classical backpropagation's effectiveness.
What carries the argument
DEBI-NN's distance-based spatial encoding of weights, combined with a custom spatial backpropagation scheme for gradient flow through those distances.
If this is right
- GA training enables DEBI-NN to capture non-linear patterns that GD misses in small medical datasets.
- Architectures with highly interdependent spatial parameters resist effective training by gradient methods.
- Genetic algorithms are more suitable than gradient descent for optimizing DEBI-NN in low-data regimes.
- The performance gap holds across synthetic two-moons data and real radiomic and cardiotocography datasets.
Where Pith is reading between the lines
- Similar distance-based or geometric neural networks might also benefit from evolutionary optimizers over backpropagation.
- Testing DEBI-NN with GA on larger datasets could reveal whether the advantage persists beyond low-data settings.
- Hybrid optimizers that combine elements of GA and GD might mitigate the gradient entanglement issue.
Load-bearing premise
The targeted hyperparameter searches for GA and GD were comparably exhaustive, and the spatial backpropagation scheme correctly propagates gradients through the distance-defined weights.
What would settle it
A follow-up experiment with more extensive random hyperparameter sampling or multiple independent runs in which GD matches or exceeds GA accuracy on the same datasets would falsify the superiority claim.
Figures




read the original abstract
Aim/Introduction: Distance-encoding biomorphic-informational neural network (DEBI-NN) is a recently proposed architecture in which connection weights are defined by the distances between neurons positioned in a Euclidian space. This approach drastically reduces the number of trainable parameters compared to classical neural networks in which weights are directly trained. The training process for DEBI-NN is based on a genetic algorithm (GA), rather than gradient descent (GD) which remains the prevailing optimization algorithm in deep learning. We aim to design and implement a GD learner for DEBI-NN and assess its performance compared to GA. Materials and Methods: We designed a spatial backpropagation scheme tailored to DEBI-NN and carried out a comparison between GD and GA for classification tasks, using a synthetic non-linear "two-moons" dataset, two clinical medical imaging radiomic datasets and a fetal cardiotocography dataset with a sample sizes ranging from n=85 to n=2126. Each optimizer was tuned through targeted hyperparameter searches adapted to each dataset. Results: Across all experiments, GA consistently produced superior decision boundaries and classification performance (Synthetic: 100% vs 83%; DLBCL: 83% vs 78%; HECKTOR: 80% vs 67%; Fetal: 81% vs 66%), whereas GD exhibited instability and failed to fully capture the non-linear patterns inherent to DEBI-NN's spatial encoding. The entangled gradients resulting from neuron interdependencies limit the effectiveness of classical backpropagation. Conclusion: These findings highlight fundamental limitations of gradient-based methods in architectures with highly interdependent spatial parameters and confirm the suitability of evolutionary strategies for training DEBI-NN.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a spatial backpropagation scheme to enable gradient descent (GD) training of the DEBI-NN architecture, in which neuron weights are defined by Euclidean distances between positioned neurons. It then empirically compares this GD implementation against the original genetic algorithm (GA) training on a synthetic two-moons dataset and three small medical datasets (DLBCL, HECKTOR, fetal cardiotocography), reporting that GA achieves higher accuracies (100% vs 83%, 83% vs 78%, 80% vs 67%, 81% vs 66%) while GD exhibits instability due to entangled gradients from spatial interdependencies. The conclusion is that evolutionary methods are better suited for this low-parameter architecture in low-data medical regimes.
Significance. If the GD implementation is verifiably correct and the hyperparameter searches are shown to be comparably exhaustive, the result would provide useful evidence on the limitations of gradient-based optimization for distance-encoded networks and support the use of GA for small medical imaging datasets. The work is grounded in real clinical data and directly tests an alternative optimizer on a parameter-efficient architecture.
major comments (3)
- [Abstract/Results] Abstract and Results: Performance is reported as single-point accuracies (e.g., Synthetic 100% vs 83%) with no error bars, standard deviations, or statistics from multiple independent runs using different random seeds. This directly undermines the claim of consistent superiority across all experiments, as the observed gaps could arise from optimization variance rather than intrinsic optimizer suitability.
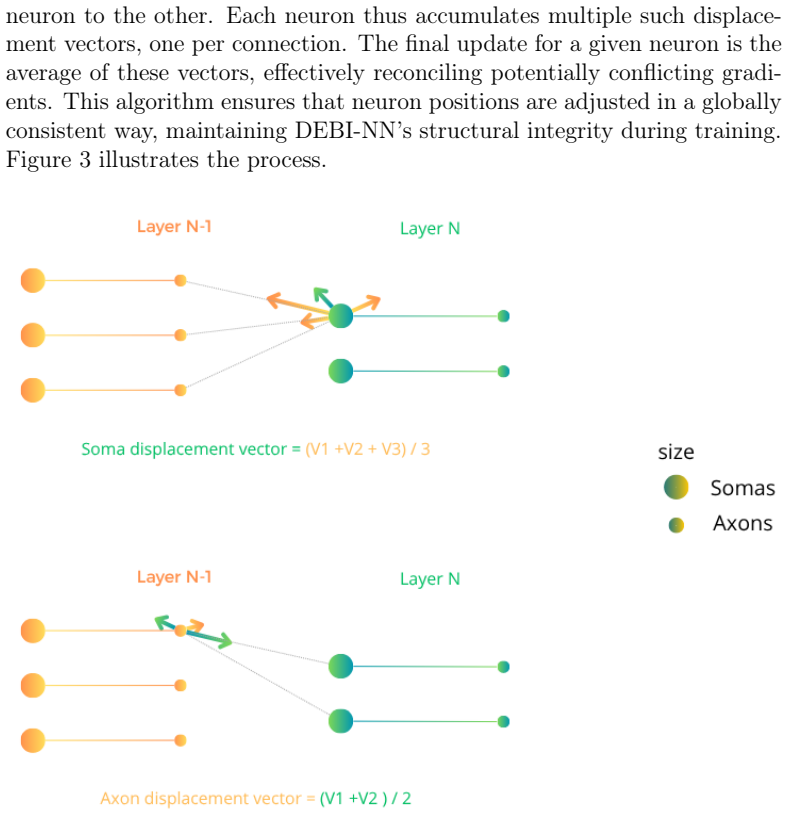
- [Materials and Methods] Materials and Methods: The spatial backpropagation scheme is introduced to handle gradients through distance-to-weight mappings, but no derivation, update equations, or pseudocode is supplied to confirm that gradients correctly flow through the interdependent neuron positions. Without this, the reported GD failures (e.g., failure to capture non-linear patterns) cannot be attributed to the architecture rather than an implementation error.
- [Materials and Methods] Materials and Methods: Hyperparameters for GA (population size, mutation rate, generations) and GD (learning rate, batch size, epochs) were each tuned via 'targeted hyperparameter searches adapted to each dataset.' No details on search budgets, ranges, or validation procedures are given, so it is impossible to rule out unequal tuning effort as the source of the performance gaps.
minor comments (1)
- [Abstract] The abstract states sample sizes range from n=85 to n=2126 but does not clarify which dataset corresponds to which size or whether class imbalance was addressed in the reported accuracies.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and will revise the manuscript to improve transparency and statistical rigor.
read point-by-point responses
-
Referee: [Abstract/Results] Abstract and Results: Performance is reported as single-point accuracies (e.g., Synthetic 100% vs 83%) with no error bars, standard deviations, or statistics from multiple independent runs using different random seeds. This directly undermines the claim of consistent superiority across all experiments, as the observed gaps could arise from optimization variance rather than intrinsic optimizer suitability.
Authors: We agree that single-point accuracies without variability measures from multiple runs limit the strength of the superiority claims. In the revision we will execute at least 10 independent runs per optimizer with distinct random seeds on each dataset, reporting mean accuracy, standard deviation, and where appropriate statistical tests to quantify the observed differences. revision: yes
-
Referee: [Materials and Methods] Materials and Methods: The spatial backpropagation scheme is introduced to handle gradients through distance-to-weight mappings, but no derivation, update equations, or pseudocode is supplied to confirm that gradients correctly flow through the interdependent neuron positions. Without this, the reported GD failures (e.g., failure to capture non-linear patterns) cannot be attributed to the architecture rather than an implementation error.
Authors: We acknowledge that the absence of explicit derivation and pseudocode prevents independent verification of the spatial backpropagation implementation. The revised Materials and Methods section will include the full gradient derivation with respect to neuron coordinates, the chain-rule expressions for distance-to-weight mappings, and pseudocode for the complete forward and backward passes. revision: yes
-
Referee: [Materials and Methods] Materials and Methods: Hyperparameters for GA (population size, mutation rate, generations) and GD (learning rate, batch size, epochs) were each tuned via 'targeted hyperparameter searches adapted to each dataset.' No details on search budgets, ranges, or validation procedures are given, so it is impossible to rule out unequal tuning effort as the source of the performance gaps.
Authors: We recognize that insufficient documentation of the hyperparameter searches precludes assessment of tuning equity. The revision will detail the exact search ranges, search method, number of evaluated configurations, computational budget, and validation procedure (e.g., k-fold cross-validation) used for both GA and GD on each dataset. revision: yes
Circularity Check
No circularity: purely empirical comparison with no derivation chain
full rationale
The paper reports direct experimental results comparing GA and GD optimizers on DEBI-NN across four datasets, with performance numbers (e.g., accuracies) obtained from runs rather than any algebraic derivation. No equations, uniqueness theorems, or first-principles claims are advanced that could reduce to fitted inputs or self-citations by construction. The architecture itself is cited as prior work, but the load-bearing content is the measured classification gaps and stability observations, which stand independently of any internal redefinition. This matches the default case of an empirical study whose central claims do not collapse into their own inputs.
Axiom & Free-Parameter Ledger
free parameters (2)
- GA population size, mutation rate, generations
- GD learning rate, batch size, epochs
Reference graph
Works this paper leans on
-
[1]
J. Kaplan, S. McCandlish, T. Henighan, T. B. Brown, B. Chess, R. Child, et al., Scaling laws for neural language models, arXiv preprint arXiv:2001.08361 (2020)
Pith/arXiv arXiv 2001
-
[2]
Sevilla, P
J. Sevilla, P. Villalobos, J. Cerón, Parameter counts in machine learning, in: AI Alignment Forum, 2021
2021
-
[3]
Celard, E
P. Celard, E. L. Iglesias, J. M. Sorribes-Fdez, R. Romero, A. S. Vieira, L. Borrajo, A survey on deep learning applied to medical images: from simple artificial neural networks to generative models, Neural Comput- ing and Applications 35 (3) (2023) 2291–2323
2023
-
[4]
Takahashi, Y
S. Takahashi, Y. Sakaguchi, N. Kouno, K. Takasawa, K. Ishizu, Y. Ak- agi, et al., Comparison of vision transformers and convolutional neural networks in medical image analysis: a systematic review, Journal of Medical Systems 48 (1) (2024) 84
2024
-
[5]
Raghu, C
M. Raghu, C. Zhang, J. Kleinberg, S. Bengio, Transfusion: Understand- ing transfer learning for medical imaging, Advances in neural informa- tion processing systems 32 (2019). 22
2019
-
[6]
Nayem, S
J. Nayem, S. S. Hasan, N. Amina, B. Das, M. S. Ali, M. M. Ahsan, et al., Few shot learning for medical imaging: A comparative analysis of methodologies and formal mathematical framework, in: Data Driven Approaches on Medical Imaging, Springer, 2023, pp. 69–90
2023
-
[7]
Y. He, F. Huang, X. Jiang, Y. Nie, M. Wang, J. Wang, et al., Foundation model for advancing healthcare: challenges, opportunities and future directions, IEEE Reviews in Biomedical Engineering (2024)
2024
-
[8]
L. Papp, D. Haberl, B. Ecsedi, C. P. Spielvogel, D. Krajnc, M. Graho- vac, et al., Debi-nn: Distance-encoding biomorphic-informational neu- ral networks for minimizing the number of trainable parameters, Neural Networks 167 (2023) 517–532
2023
-
[9]
B. Ecsedi, A. Boukhari, C. P. Spielvogel, D. Haberl, Z. Ritter, R. A. Bundschuh, C. Lapa, M. Hacker, M. Hatt, L. Papp, Impact of regular- ization in optimizing distance-encoding biomorphic-informational neu- ral networks for small nuclear medicine datasets, EANM Innovation 1 (2025) 100008. doi:https://doi.org/10.1016/j.eanmi.2025.100008
-
[10]
M. Atad, G. Gruber, M. Ribeiro, L. F. Nicolini, R. Graf, H. Möller, K. Nispel, I. Ezhov, D. Rueckert, J. S. Kirschke, Neural network surro- gate and projected gradient descent for fast and reliable finite element model calibration: A case study on an intervertebral disc, Computers in Biology and Medicine 186 (2025) 109646
2025
-
[11]
D. Campos, J. Bernardes, Cardiotocography, UCI Machine Learning Repository, DOI: https://doi.org/10.24432/C51S4N (2000)
-
[12]
Andrearczyk, V
V. Andrearczyk, V. Oreiller, M. Abobakr, A. Akhavanallaf, P. Balermpas, S. Boughdad, et al, Overview of the hecktor challenge at miccai 2022: Automatic head and neck tumor segmentation and out- come prediction in pet/ct, in: V. Andrearczyk, V. Oreiller, M. Hatt, A. Depeursinge (Eds.), Head and Neck Tumor Segmentation and Out- come Prediction, Springer Nat...
2022
-
[13]
V. Andrearczyk, V. Oreiller, S. Boughdad, C. C. Le Rest, O. Tankyevych, H. Elhalawani, M. Jreige, J. O. Prior, M. Val- lières, D. Visvikis, M. Hatt, A. Depeursinge, Automatic head and neck tumor segmentation and outcome prediction relying 23 on fdg-pet/ct images: Findings from the second edition of the hecktor challenge, Medical Image Analysis 90 (2023) 1...
-
[14]
Zwanenburg, M
A. Zwanenburg, M. Vallières, M. A. Abdalah, H. J. Aerts, V. Andrea- rczyk, A. Apte, et al., The image biomarker standardization initiative: standardized quantitative radiomics for high-throughput image-based phenotyping, Radiology 295 (2) (2020) 328–338
2020
-
[15]
Ritter, L
Z. Ritter, L. Papp, K. Zámbó, Z. Tóth, D. Dezső, D. S. Veres, et al., Two-year event-free survival prediction in dlbcl patients based on in vivo radiomics and clinical parameters, Frontiers in Oncology 12 (2022) 820136
2022
-
[16]
a. boukhari, b. ecsedi, l. papp, m. hatt, Debi-nn: Genetic algorithm vs. gradient descent data (2025). doi:10.17632/8KWN35PPCD. URLhttps://data.mendeley.com/datasets/8kwn35ppcd
-
[17]
Papp, Mastering Distance-Encoding Biomorphic Neural Networks – The DEBI-NN Handbook, Zenodo, 2025
L. Papp, Mastering Distance-Encoding Biomorphic Neural Networks – The DEBI-NN Handbook, Zenodo, 2025. doi:10.5281/zenodo.17224628. URLhttps://doi.org/10.5281/zenodo.17224628
-
[18]
Abuqaddom, B
I. Abuqaddom, B. A. Mahafzah, H. Faris, Oriented stochastic loss de- scent algorithm to train very deep multi-layer neural networks without vanishing gradients, Knowledge-Based Systems 230 (2021) 107391
2021
-
[19]
D. Liu, Y. Wang, C. Luo, J. Ma, An improved autoencoder for rec- ommendation to alleviate the vanishing gradient problem, Knowledge- Based Systems 263 (2023) 110254
2023
-
[20]
Y. Wu, K. He, Group normalization (2018). arXiv:1803.08494. URLhttps://arxiv.org/abs/1803.08494 24
Pith/arXiv arXiv 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.