Context Features Are Cheap: Rank-Aware Decomposition for Efficient Feature Interaction in Recommender Systems
Pith reviewed 2026-06-29 23:43 UTC · model grok-4.3
The pith
Any linear or bilinear operation on rank-partitioned features admits an exact block decomposition that computes context-only parts once per request instead of once per candidate.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
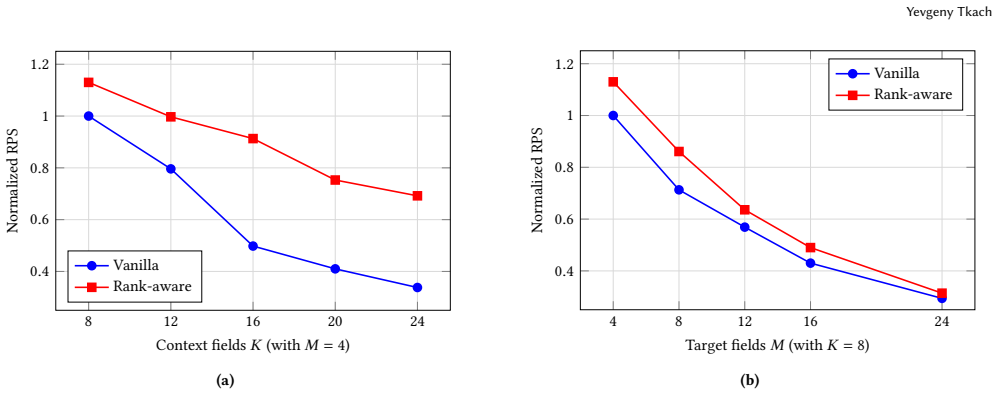
Any linear or bilinear operation over a rank-partitioned input admits an exact block decomposition that moves context-only computation from once-per-candidate to once-per-request, identity-equivalent to the original model. This holds for FM pairwise products, DCNv2 cross layers, self-attention, and FC projection layers. The identity-equivalent form applies only at the first layer because later layers mix ranks; rDCN is an architectural variant that maintains rank discipline across depth and matches DCNv2 accuracy within training noise.
What carries the argument
Rank-aware block decomposition of linear and bilinear interactions between user/context and item feature partitions.
If this is right
- Savings scale quadratically with the number of context features.
- Production DLRM-style ranker achieves 87.5 percent higher per-pod throughput.
- Peak pod count drops 47 percent at identical model predictions.
- rDCN variant matches DCNv2 accuracy within training noise at 67 percent fewer total FLOPs.
Where Pith is reading between the lines
- The same decomposition could apply to other multi-candidate scoring pipelines such as search or advertising rankers.
- Larger context feature sets become practical without proportional increase in per-candidate cost.
- Rank partitioning might extend to other partitioned input scenarios in deep models beyond recommenders.
Load-bearing premise
Model layers use only linear or bilinear operations that can be partitioned by rank without mixing that breaks the block structure after the first layer.
What would settle it
Execute the decomposed model and the original model on the same inputs and verify that their output scores or embeddings are numerically identical.
Figures

read the original abstract
Modern industrial recommender systems use a deep ranking model to score N candidates against the same user and context features. Standard implementations broadcast context features early in the forward pass, redundantly computing context-only operations N times per request. We present a rank-aware decomposition applicable to the dominant interaction mechanisms in modern recommender architectures-Factorization Machine (FM) pairwise products, Deep Cross Network (DCNv2) cross layers, self-attention, and fully connected (FC) projection layers-built on a single algebraic principle: any linear or bilinear operation over a rank-partitioned input admits an exact block decomposition that moves context-only computation from once-per-candidate to once-per-request, identity-equivalent to the original model. Closed-form analysis and controlled ablation verify that savings scale quadratically with the number of context features. Applied to a production DLRM-style ranker without any architectural change, the decomposition increases per-pod throughput by 87.5% (a 47% reduction in peak pod count) at identical model predictions. The identity-equivalent decomposition applies only at the first layer of cross networks and self-attention, since each layer mixes ranks in its output. To extend savings across depth, we further introduce rDCN, an architectural variant of DCNv2 that maintains rank discipline across depth and matches DCNv2 accuracy within training noise at 67% fewer total FLOPs, and sketch an analogous architectural variant for self-attention.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that any linear or bilinear operation over a rank-partitioned input (context/user features vs. item features) admits an exact block decomposition, moving context-only computation from per-candidate to per-request while preserving identical outputs. This is asserted to apply to FM pairwise products, DCNv2 cross layers, self-attention, and FC projections. Closed-form analysis shows quadratic savings with context feature count; a production DLRM-style model sees 87.5% throughput gain at identical predictions. For depth, rDCN is introduced as a rank-disciplined DCNv2 variant matching accuracy at 67% fewer FLOPs, with a sketch for attention.
Significance. If the exact identity equivalence holds for the listed mechanisms and the production results are as stated, the work offers a practical, zero-accuracy-loss optimization for industrial ranking models that scales with context dimensionality and requires no retraining or architectural overhaul beyond the optional rDCN variant.
major comments (1)
- [Abstract; self-attention mechanism description] Abstract and self-attention discussion: the claim that the decomposition applies to self-attention via the same linear/bilinear principle is load-bearing for the four-mechanism scope, yet the row-wise softmax in attention normalizes over the full key set (mixing context-context, context-item, item-context, and item-item blocks). This alters per-item normalization factors when context blocks are precomputed, breaking exact equivalence for the full layer even at the first layer. The paper notes the first-layer restriction and sketches a variant, but does not demonstrate or claim a restructuring that restores identity equivalence.
minor comments (2)
- [Abstract] The production claim is for a DLRM-style ranker; clarify whether this model includes self-attention layers or only FM/DCNv2/FC components, as this affects how broadly the self-attention result applies.
- [rDCN ablation section] The rDCN accuracy match is stated as 'within training noise'; provide the exact delta and variance from the ablation table to allow readers to assess equivalence.
Simulated Author's Rebuttal
We thank the referee for the careful and precise reading. The comment correctly identifies a subtlety in the self-attention claim that requires clarification. We address it below.
read point-by-point responses
-
Referee: [Abstract; self-attention mechanism description] Abstract and self-attention discussion: the claim that the decomposition applies to self-attention via the same linear/bilinear principle is load-bearing for the four-mechanism scope, yet the row-wise softmax in attention normalizes over the full key set (mixing context-context, context-item, item-context, and item-item blocks). This alters per-item normalization factors when context blocks are precomputed, breaking exact equivalence for the full layer even at the first layer. The paper notes the first-layer restriction and sketches a variant, but does not demonstrate or claim a restructuring that restores identity equivalence.
Authors: We agree that the row-wise softmax breaks exact identity equivalence even at the first layer, because normalization constants depend on the full key set (including context-context blocks). The core algebraic principle in the paper is stated for linear and bilinear operations; the abstract lists self-attention among the mechanisms to which the overall approach applies, but the body text already restricts identity equivalence to the first layer and introduces a sketched architectural variant (analogous to rDCN) rather than claiming a direct block decomposition that preserves the softmax output. We will revise the abstract to state more precisely that the identity-equivalent decomposition covers linear and bilinear operations (FM, DCNv2 cross, FC) while self-attention is handled via the rank-disciplined variant. We will also expand the self-attention discussion to explicitly note the softmax normalization issue and the distinction between the linear projections and the full attention layer. revision: partial
Circularity Check
Algebraic identity for block decomposition holds independently of fitted values or self-referential definitions.
full rationale
The paper derives its central result from the algebraic property that linear and bilinear operations on rank-partitioned inputs admit exact block decompositions, which follows directly from matrix partitioning rules without reference to model parameters, training data, or prior self-citations. The limitation to the first layer and the introduction of rDCN are presented as explicit architectural adjustments rather than tautological redefinitions. No steps reduce a claimed prediction to a fitted input by construction, and the verification is described as closed-form analysis plus ablation, keeping the derivation self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Linear and bilinear operations over rank-partitioned inputs admit exact block decomposition.
invented entities (1)
-
rDCN
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Jianxin Chang, Chenbin Zhang, Zhiyi Fu, Xiaoxue Zang, Lin Guan, Jing Lu, Yiqun Hui, Dewei Leng, Yanan Niu, Yang Song, and Kun Gai. 2023. TWIN: TWo-stage Interest Network for Lifelong User Behavior Modeling in CTR Prediction at Kuaishou. In Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD)
2023
-
[2]
Huifeng Guo, Ruiming Tang, Yunming Ye, Zhenguo Li, and Xiuqiang He. 2017. DeepFM: A Factorization-Machine based Neural Network for CTR Prediction. In Proceedings of the 26th International Joint Conference on Artificial Intelligence (IJCAI). 1725–1731
2017
- [3]
-
[4]
Xiangnan He and Tat-Seng Chua. 2017. Neural Factorization Machines for Sparse Predictive Analytics. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval . 355–364. https: //doi.org/10.1145/3077136.3080777
-
[5]
Jui-Ting Huang, Ashish Sharma, Shuying Sun, Li Xia, David Zhang, Philip Pronin, Janani Padmanabhan, Giuseppe Ottaviano, and Linjun Yang. 2020. Embedding- Based Retrieval in Facebook Search. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining . 2553–2561. https://doi.org/10.1145/3394486.3403305
-
[6]
Tongwen Huang, Zhiqi Zhang, and Junlin Zhang. 2019. FiBiNET: Combining Feature Importance and Bilinear Feature Interaction for Click-Through Rate Prediction. In Proceedings of the 13th ACM Conference on Recommender Systems (RecSys). 169–177. https://doi.org/10.1145/3298689.3347043
-
[7]
Yusheng Huang, Pengbo Xu, Shen Wang, Changxin Lao, Jiangxia Cao, Shuang Wen, Shuang Yang, Zhaojie Liu, Han Li, and Kun Gai. 2026. MaRI: Accelerating Ranking Model Inference via Structural Re-parameterization in Large Scale Recommendation Systems. arXiv preprint arXiv:2602.23105 (2026)
- [8]
- [9]
-
[10]
Weijiang Lai, Beihong Jin, Jiongyan Zhang, Yiyuan Zheng, Jian Dong, Jia Cheng, Jun Lei, and Xingxing Wang. 2025. Exploring Scaling Laws of CTR Model for Online Performance Improvement. In Proceedings of the Nineteenth ACM Conference on Recommender Systems (RecSys ’25). https://doi.org/10.1145/3705328. 3748046
- [11]
-
[12]
Zeyu Li, Wei Cheng, Yang Chen, Haifeng Chen, and Wei Wang. 2020. Inter- pretable Click-Through Rate Prediction through Hierarchical Attention. In Pro- ceedings of the 13th International Conference on Web Search and Data Mining (WSDM). 313–321
2020
-
[13]
Jianxun Lian, Xiaohuan Zhou, Fuzheng Zhang, Zhongxia Chen, Xing Xie, and Guangzhong Sun. 2018. xDeepFM: Combining Explicit and Implicit Feature Interactions for Recommender Systems. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining . 1754–1763. https://doi.org/10.1145/3219819.3220023
-
[14]
Deep Learning Recommendation Model for Personalization and Recommendation Systems
Maxim Naumov, Dheevatsa Mudigere, Hao-Jun Michael Shi, Jianyu Huang, Narayanan Sundaraman, Jongsoo Park, Xiaodong Wang, Udit Gupta, Carole-Jean Wu, Alisson G. Azzolini, et al. 2019. Deep Learning Recommendation Model for Personalization and Recommendation Systems. arXiv preprint arXiv:1906.00091 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[15]
Junwei Pan, Jian Xu, Alfonso Lobos Ruiz, Wenliang Zhao, Shengjun Pan, Yu Sun, and Quan Lu. 2018. Field-weighted Factorization Machines for Click-Through Rate Prediction in Display Advertising. In Proceedings of the 2018 World Wide Web Conference. 1349–1357. https://doi.org/10.1145/3178876.3186040
- [16]
-
[17]
Yanru Qu, Han Cai, Kan Ren, Weinan Zhang, Yong Yu, Ying Wen, and Jun Wang
-
[18]
In2016 IEEE 16th International Conference on Data Mining (ICDM)
Product-based Neural Networks for User Response Prediction. In2016 IEEE 16th International Conference on Data Mining (ICDM) . 1149–1154. Context Features Are Cheap
-
[19]
Steffen Rendle. 2010. Factorization Machines. In 2010 IEEE International Con- ference on Data Mining (ICDM) . IEEE, 995–1000. https://doi.org/10.1109/ICDM. 2010.127
- [20]
-
[21]
Weiping Song, Chence Shi, Zhiping Xiao, Zhijian Duan, Yewen Xu, Ming Zhang, and Jian Tang. 2019. AutoInt: Automatic Feature Interaction Learning via Self-Attentive Neural Networks. In Proceedings of the 28th ACM Interna- tional Conference on Information and Knowledge Management (CIKM) . 1161–1170. https://doi.org/10.1145/3357384.3357925
-
[22]
Fangye Wang, Yingxu Wang, Dongsheng Li, Hansu Gu, Tun Lu, Peng Zhang, and Ning Gu. 2023. Towards Deeper, Lighter and Interpretable Cross Network for CTR Prediction. In Proceedings of the 32nd ACM International Conference on Information and Knowledge Management (CIKM)
2023
-
[23]
Ruoxi Wang, Bin Fu, Gang Fu, and Mingliang Wang. 2017. Deep & Cross Network for Ad Click Predictions. In Proceedings of the ADKDD’17 Workshop at KDD . https://doi.org/10.1145/3124749.3124754
-
[24]
Ruoxi Wang, Rakesh Shivanna, Derek Cheng, Sagar Jain, Dong Lin, Lichan Hong, and Ed Chi. 2021. DCN V2: Improved Deep & Cross Network and Practical Lessons for Web-scale Learning to Rank Systems. In Proceedings of the Web Conference 2021 (WWW) . 1785–1797. https://doi.org/10.1145/3442381.3450078
-
[25]
Zhiqiang Wang, Qingyun She, and Junlin Zhang. 2021. MaskNet: Introducing Feature-Wise Multiplication to CTR Ranking Models by Instance-Guided Mask. In DLP-KDD 2021 Workshop at KDD
2021
-
[26]
Xue Xia, Pong Eksombatchai, Nikil Pancha, Dhruvil Deven Badani, Po-Wei Wang, Neng Gu, Saurabh Vishwas Joshi, Nazanin Farahpour, Zhiyuan Zhang, and Andrew Zhai. 2023. TransAct: Transformer-based Realtime User Action Model for Recommendation at Pinterest. In Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD) . https:/...
-
[27]
Xinyang Yi, Ji Yang, Lichan Hong, Derek Zhiyuan Cheng, Lukasz Heldt, Aditee Kumthekar, Zhe Zhao, Li Wei, and Ed Chi. 2019. Sampling-Bias-Corrected Neural Modeling for Large Corpus Item Recommendations. In Proceedings of the 13th ACM Conference on Recommender Systems (RecSys) . 269–277. https: //doi.org/10.1145/3298689.3346996
-
[28]
Buyun Zhang, Liang Luo, Xi Liu, Jay Li, Zeliang Chen, Weilin Zhang, Xiaohan Wei, Yuchen Hao, Michael Tsang, Wenjun Wang, Yang Liu, Huayu Li, Yasmine Badr, Jongsoo Park, Jiyan Yang, Dheevatsa Mudigere, and Ellie Wen. 2022. DHEN: A Deep and Hierarchical Ensemble Network for Large-Scale Click-Through Rate Prediction. In DLP-KDD 2022 Workshop at KDD
2022
-
[29]
Guorui Zhou, Xiaoqiang Zhu, Chenru Song, Ying Fan, Han Zhu, Xiao Ma, Yanghui Yan, Junqi Jin, Han Li, and Kun Gai. 2018. Deep Interest Network for Click- Through Rate Prediction. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining . 1059–1068
2018
-
[30]
Jieming Zhu, Qinglin Jia, Guohao Cai, Quanyu Dai, Jingjie Li, Zhenhua Dong, Ruiming Tang, and Rui Zhang. 2023. FinalMLP: An Enhanced Two-Stream MLP Model for CTR Prediction. In Proceedings of the AAAI Conference on Artificial Intelligence
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.