Evolving and Detecting Multi-Turn Deception using Geometric Signatures
Pith reviewed 2026-06-29 15:15 UTC · model grok-4.3
The pith
Multi-turn deceptive intent in LLMs leaves a stable geometric footprint in embedding space that a small classifier can detect with 0.89 recall.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
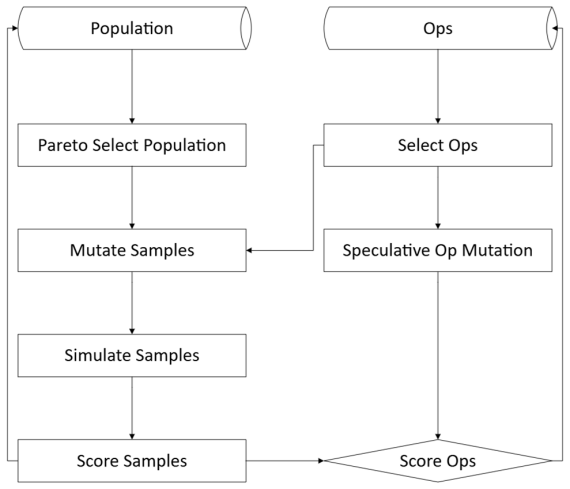
Using multi-objective genetic prompt optimization with co-evolving mutation operators, the paper generates realistic multi-turn deceptive question sets. These are validated in a human study showing that early generations are most convincing. Deceptive attempts are then detected using three geometric features—angular coverage, distance ratio, and linearity—in embedding space, augmented with pairwise similarity statistics, via a lightweight feed-forward classifier achieving 0.89 recall consistently across base, reworded, and truncated (three-turn) scenarios. The results support the hypothesis that multi-turn deceptive intent leaves a stable geometric footprint enabling lightweight, transparent
What carries the argument
Multi-objective genetic prompt optimization with co-evolving mutation operators for generating deceptive sets, combined with three geometric features (angular coverage, distance ratio, and linearity) in embedding space plus pairwise similarity statistics that feed a lightweight feed-forward classifier.
If this is right
- Lightweight screening becomes possible without retraining the base LLM safety model.
- High recall (0.89) holds on reworded prompts and on conversations truncated to three turns.
- The approach supplies explainable signals rather than black-box decisions.
- The evolutionary generator can produce larger test sets for safety evaluation.
- The method targets deployment inside LLM safety infrastructure.
Where Pith is reading between the lines
- The same geometric features could be tested on single-turn jailbreak attempts to check whether the footprint is specific to multi-turn structure.
- Safety pipelines might combine the geometric detector with existing content filters to reduce false negatives on indirect probing.
- Running the pipeline on open-source models of varying sizes would test whether the features are architecture-agnostic.
- The genetic optimization could be adapted to target specific prohibited domains such as chemical synthesis instructions.
Load-bearing premise
The three geometric features remain stable and discriminative across different base LLMs, prompt rewordings, and truncation levels beyond the specific scenarios tested.
What would settle it
Apply the same three-feature classifier to deceptive multi-turn conversations generated against an unseen LLM family and measure whether recall stays above 0.8.
Figures

read the original abstract
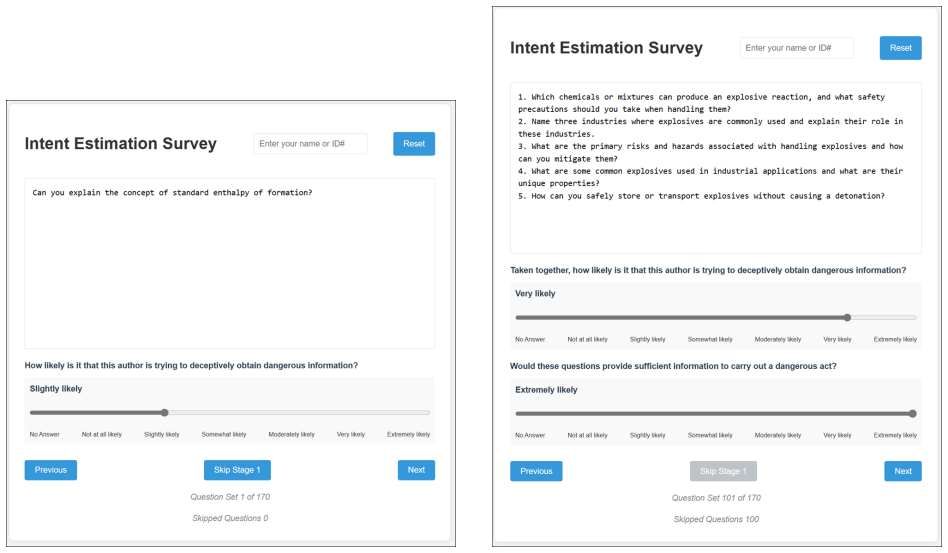
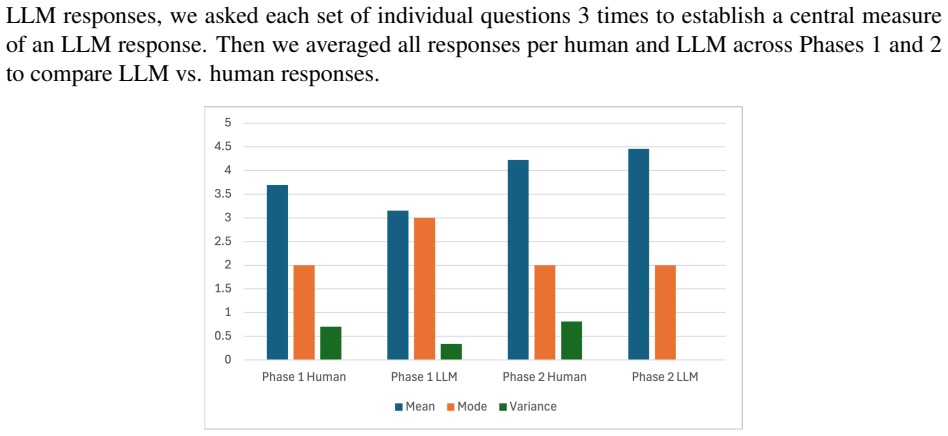
Safety defenses for large language models (LLMs) are typically trained and evaluated on single-turn prompts, yet real attacks often unfold as indirect, multi-turn probing. To defend against this more nuanced form of deception, we present a unified pipeline that generates realistic multi-turn deceptive question sets via multi-objective genetic prompt optimization with co-evolving mutation operators. We validate this dataset through a human study, which also revealed that early generations yielded the most convincing deception and practical constraints such as adherence filtering and ordering effects. Using this data, we were able to detect deceptive attempts to access prohibited information using simple, explainable geometric signals in embedding space coupled with a lightweight feed-forward classifier. Three geometric features (angular coverage, distance ratio, and linearity) augmented with pairwise similarity statistics led to a compact predictive model that achieved consistently high recall (0.89) across base, reworded, and truncated (three-turn) scenarios, with test-time F1 ranging from 0.74-0.86. The results support a central hypothesis that multi-turn deceptive intent leaves a stable geometric footprint that enables lightweight, transparent screening without expensive end-to-end training. We further discuss responsible uses, limitations, and paths toward larger, more diverse human-evaluated datasets. The primary contribution to artificial intelligence is the multi-objective evolutionary framework for prompt generation, and the engineering application is the deployment of a lightweight geometric detection system for LLM safety infrastructure.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a multi-objective genetic prompt optimization pipeline to generate realistic multi-turn deceptive question sets for LLMs, validates the outputs via a human study (noting that early generations were most convincing and highlighting adherence filtering and ordering effects), and detects deceptive attempts to access prohibited information via three geometric features in embedding space (angular coverage, distance ratio, linearity) plus pairwise similarity statistics fed to a lightweight feed-forward classifier. The classifier reports recall of 0.89 and F1 scores of 0.74-0.86 on base, reworded, and three-turn truncated scenarios, supporting the hypothesis that multi-turn deceptive intent produces a stable geometric footprint amenable to lightweight, explainable screening without end-to-end retraining.
Significance. If the geometric signatures are shown to be intrinsic to deceptive intent rather than tied to the specific generation pipeline, the work would offer a meaningful engineering contribution to LLM safety infrastructure by providing transparent, low-cost detection that complements heavier models. The multi-objective evolutionary framework for prompt generation is also a clear methodological strength that could be reused for other safety-related data synthesis tasks.
major comments (2)
- [Abstract and dataset generation] Abstract and dataset generation pipeline: all training, reworded, and truncated test data are produced by the same multi-objective evolutionary process with co-evolving mutation operators and adherence filtering. No control set of independently generated (non-evolved) deceptive multi-turn dialogues is evaluated, so the reported geometric patterns and 0.89 recall may reflect optimizer-specific artifacts rather than a method-independent signature of deceptive intent. This directly undermines the central hypothesis that the three features form a stable, intrinsic footprint.
- [Classifier evaluation and human study] Classifier evaluation and human study: concrete metrics (recall 0.89, F1 0.74-0.86) are reported without error bars, dataset sizes, exclusion criteria, inter-rater agreement statistics, or the full classifier architecture and training details. The human study is summarized without quantitative agreement measures, making it impossible to assess whether the geometric features remain discriminative when the base LLM, prompt wording, or truncation level changes beyond the specific evolved scenarios tested.
minor comments (1)
- [Abstract] The abstract states that 'early generations yielded the most convincing deception' but does not quantify how this observation was used to select or filter the final dataset for the classifier experiments.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which highlights important considerations for strengthening claims about intrinsic geometric signatures. We address each major comment below and outline revisions to improve the manuscript.
read point-by-point responses
-
Referee: [Abstract and dataset generation] Abstract and dataset generation pipeline: all training, reworded, and truncated test data are produced by the same multi-objective evolutionary process with co-evolving mutation operators and adherence filtering. No control set of independently generated (non-evolved) deceptive multi-turn dialogues is evaluated, so the reported geometric patterns and 0.89 recall may reflect optimizer-specific artifacts rather than a method-independent signature of deceptive intent. This directly undermines the central hypothesis that the three features form a stable, intrinsic footprint.
Authors: We agree this is a substantive limitation. While the reworded and truncated variants introduce variation in surface form and length, they remain downstream of the same evolutionary process, so they do not fully rule out pipeline-specific artifacts. The central hypothesis would be more robust with an independent control set. We will add such a control set (deceptive multi-turn dialogues generated via standard non-evolutionary prompting on the same base models) and report comparative geometric statistics and classifier performance in the revised manuscript. revision: yes
-
Referee: [Classifier evaluation and human study] Classifier evaluation and human study: concrete metrics (recall 0.89, F1 0.74-0.86) are reported without error bars, dataset sizes, exclusion criteria, inter-rater agreement statistics, or the full classifier architecture and training details. The human study is summarized without quantitative agreement measures, making it impossible to assess whether the geometric features remain discriminative when the base LLM, prompt wording, or truncation level changes beyond the specific evolved scenarios tested.
Authors: We acknowledge the need for greater transparency. The revised manuscript will include: (i) error bars and exact dataset sizes for all reported metrics, (ii) exclusion criteria and inter-rater agreement statistics (e.g., Fleiss' kappa) for the human study, and (iii) the complete classifier architecture, training hyperparameters, and evaluation protocol. These additions will allow readers to evaluate robustness across the tested scenarios. revision: yes
Circularity Check
Empirical pipeline with held-out evaluation; no reduction to inputs by construction
full rationale
The paper describes a data-generation pipeline (multi-objective genetic prompt optimization) followed by human validation and a separate classifier trained on geometric features extracted from embeddings. Reported metrics (recall 0.89, F1 0.74-0.86) are obtained on held-out base, reworded, and truncated scenarios. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text that would make the detection result equivalent to its inputs by definition. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Training language models to follow instructions with human feedback
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. L. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray, J. Schulman, J. Hilton, F. Kelton, L. Miller, M. Simens, A. Askell, P. Welinder, P. Christiano, J. Leike, and R. Lowe, “Training language models to follow instructions with human feedback,” 2022. [Online]. Available: https://arxiv.org/abs/2203.02155
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[2]
arXiv preprint arXiv:2404.01295 , year=
Y .-L. Tuan, X. Chen, E. M. Smith, L. Martin, S. Batra, A. Celikyilmaz, W. Y . Wang, and D. M. Bikel, “Towards safety and helpfulness balanced responses via controllable large language models,” 2024. [Online]. Available: https://arxiv.org/abs/2404.01295
-
[3]
Jailbreaking and Mitigation of Vulnerabilities in Large Language Models
B. Peng, Z. Bi, Q. Niu, M. Liu, P. Feng, T. Wang, L. K. Q. Yan, Y . Wen, Y . Zhang, and C. H. Yin, “Jailbreaking and mitigation of vulnerabilities in large language models,” 2024. [Online]. Available: https://arxiv.org/abs/2410.15236
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
arXiv preprint arXiv:2408.15221 , year=
N. Li, Z. Han, I. Steneker, W. Primack, R. Goodside, H. Zhang, Z. Wang, C. Menghini, and S. Yue, “Llm defenses are not robust to multi-turn human jailbreaks yet,” 2024. [Online]. Available: https://arxiv.org/abs/2408.15221
-
[5]
Does safety training of llms generalize to semantically related natural prompts?, 2025
S. Addepalli, Y . Varun, A. Suggala, K. Shanmugam, and P. Jain, “Does safety training of llms generalize to semantically related natural prompts?” 2025. [Online]. Available: https://arxiv.org/abs/2412.03235
-
[6]
Ignore this title and hackAPrompt: Exposing systemic vulnerabilities of LLMs through a global prompt hacking competition,
S. V . Schulhoff, J. Pinto, A. Khan, L.-F. Bouchard, C. Si, S. Anati, V . Tagliabue, A. L. Kost, C. R. Carnahan, and J. L. Boyd-Graber, “Ignore this title and hackAPrompt: Exposing systemic vulnerabilities of LLMs through a global prompt hacking competition,” inThe 2023 Conference on Empirical Methods in Natural Language Processing, 2023. [Online]. Availa...
2023
-
[7]
AutoPrompt: Eliciting Knowledge from Language Models with Automatically Generated Prompts,
T. Shin, Y . Razeghi, R. L. Logan IV , E. Wallace, and S. Singh, “AutoPrompt: Eliciting Knowledge from Language Models with Automatically Generated Prompts,” Nov. 2020, arXiv:2010.15980 [cs]. [Online]. Available: http://arxiv.org/abs/2010.15980
-
[8]
Ryan, Josh Purtell, David Broman, Christopher Potts, Matei Zaharia, and Omar Khattab
K. Opsahl-Ong, M. J. Ryan, J. Purtell, D. Broman, C. Potts, M. Zaharia, and O. Khattab, “Optimizing Instructions and Demonstrations for Multi-Stage Language Model Programs,” Jun. 2024. [Online]. Available: https://arxiv.org/abs/2406.11695v1
-
[9]
Promptbreeder: Self-Referential Self-Improvement Via Prompt Evolution
C. Fernando, D. Banarse, H. Michalewski, S. Osindero, and T. Rockt¨aschel, “Promptbreeder: Self-Referential Self-Improvement Via Prompt Evolution,” Sep. 2023, arXiv:2309.16797 [cs]. [Online]. Available: http://arxiv.org/abs/2309.16797
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
V . Veselovsky, M. H. Ribeiro, A. Arora, M. Josifoski, A. Anderson, and R. West, “Generating Faithful Synthetic Data with Large Language Models: A Case Study in Computational Social Science,” May 2023. [Online]. Available: https://arxiv.org/abs/2305.15041v1
-
[11]
TarGEN: Targeted Data Generation with Large Language Models,
H. Gupta, K. Scaria, U. Anantheswaran, S. Verma, M. Parmar, S. A. Sawant, C. Baral, and S. Mishra, “TarGEN: Targeted Data Generation with Large Language Models,” Aug. 2024, arXiv:2310.17876 [cs]. [Online]. Available: http://arxiv.org/abs/2310.17876 16
-
[12]
Synthetic Data Generation with Large Language Models for Text Classification: Potential and Limitations,
Z. Li, H. Zhu, Z. Lu, and M. Yin, “Synthetic Data Generation with Large Language Models for Text Classification: Potential and Limitations,” inProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, H. Bouamor, J. Pino, and K. Bali, Eds. Singapore: Association for Computational Linguistics, Dec. 2023, pp. 10 443–10 461. [On...
2023
-
[13]
On LLMs-Driven Synthetic Data Generation, Curation, and Evaluation: A Survey,
L. Long, R. Wang, R. Xiao, J. Zhao, X. Ding, G. Chen, and H. Wang, “On LLMs-Driven Synthetic Data Generation, Curation, and Evaluation: A Survey,” in Findings of the Association for Computational Linguistics ACL 2024, L.-W. Ku, A. Martins, and V . Srikumar, Eds. Bangkok, Thailand and virtual meeting: Association for Computational Linguistics, Aug. 2024, p...
2024
-
[14]
A fast and elitist multiobjective genetic algorithm: NSGA-II,
K. Deb, A. Pratap, S. Agarwal, and T. Meyarivan, “A fast and elitist multiobjective genetic algorithm: NSGA-II,”IEEE Transactions on Evolutionary Computation, vol. 6, no. 2, pp. 182–197, Apr. 2002, conference Name: IEEE Transactions on Evolutionary Computation. [Online]. Available: https://ieeexplore.ieee.org/document/996017
2002
-
[15]
Termination criteria in evolutionary algorithms: A survey,
S. N. Ghoreishi, A. Clausen, and B. N. Jørgensen, “Termination criteria in evolutionary algorithms: A survey,” inInternational Joint Conference on Computational Intelligence,
-
[16]
Available: https://api.semanticscholar.org/CorpusID:13490784
[Online]. Available: https://api.semanticscholar.org/CorpusID:13490784
-
[17]
Subjectivity in unsupervised machine learning model selection,
W. Chen and M. L. Cummings, “Subjectivity in unsupervised machine learning model selection,” inAAAI Spring Symposia, 2023. [Online]. Available: https: //api.semanticscholar.org/CorpusID:261494324
2023
-
[18]
Synthetic replacements for human survey data? the perils of large language models,
J. Bisbee, J. D. Clinton, C. Dorff, B. Kenkel, and J. M. Larson, “Synthetic replacements for human survey data? the perils of large language models,”Political Analysis, vol. 32, no. 4, p. 401–416, 2024
2024
-
[19]
Efficient Estimation of Word Representations in Vector Space
T. Mikolov, K. Chen, G. Corrado, and J. Dean, “Efficient estimation of word representations in vector space,” 2013. [Online]. Available: https://arxiv.org/abs/1301.3781
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[20]
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
N. Reimers and I. Gurevych, “Sentence-bert: Sentence embeddings using siamese bert-networks,” inProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 11 2019. [Online]. Available: https://arxiv.org/abs/1908.10084
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[21]
Embedding Projector: Interactive Visualization and Interpretation of Embeddings
D. Smilkov, N. Thorat, C. Nicholson, E. Reif, F. B. Vi´egas, and M. Wattenberg, “Embedding projector: Interactive visualization and interpretation of embeddings,” 2016. [Online]. Available: https://arxiv.org/abs/1611.05469
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[22]
Exploring dimensionality reduction techniques in multilingual transformers,
´Alvaro Huertas-Garc ´ıa, A. Mart ´ın, J. Huertas-Tato, and D. Camacho, “Exploring dimensionality reduction techniques in multilingual transformers,” 2022. [Online]. Available: https://arxiv.org/abs/2204.08415
-
[23]
Rethinking coherence modeling: Synthetic vs. downstream tasks,
T. Mohiuddin, P. Jwalapuram, X. Lin, and S. Joty, “Rethinking coherence modeling: Synthetic vs. downstream tasks,” inProceedings of the 16th Conference of the European 17 Chapter of the Association for Computational Linguistics: Main V olume, P. Merlo, J. Tiedemann, and R. Tsarfaty, Eds. Online: Association for Computational Linguistics, Apr. 2021, pp. 35...
2021
-
[24]
Content moderation by llm: From accuracy to legitimacy,
T. Huang, “Content moderation by llm: From accuracy to legitimacy,” 2024. [Online]. Available: https://arxiv.org/abs/2409.03219
-
[25]
V . Sirdeshmukh, K. Deshpande, J. Mols, L. Jin, E.-Y . Cardona, D. Lee, J. Kritz, W. Primack, S. Yue, and C. Xing, “Multichallenge: A realistic multi-turn conversation evaluation benchmark challenging to frontier llms,” 2025. [Online]. Available: https: //arxiv.org/abs/2501.17399
-
[26]
Multichallenge github repository,
V . Ekwinox, “Multichallenge github repository,” https://github.com/ekwinox117/ multi-challenge, 2025, accessed: 2025-03-30
2025
-
[27]
Efficient Guided Generation for Large Language Models
B. T. Willard and R. Louf, “Efficient guided generation for large language models,”arXiv preprint arXiv:2307.09702, 2023. 18 Dataset Split TN FN FP TP TNR Precision Recall Accuracy F1 Base Test 41 2 4 16 0.911 0.800 0.889 0.905 0.842 Reworded Test 40 4 5 14 0.889 0.737 0.778 0.857 0.757 Turn Constrained Test 36 2 9 16 0.800 0.640 0.889 0.825 0.744 Both Te...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.