Test-Time Collective Action: Proxy-Based Perturbations for Correcting Algorithmic Harms
Pith reviewed 2026-06-29 18:36 UTC · model grok-4.3
The pith
Groups of users can pool black-box queries to build a proxy, optimize shared perturbations, and correct subgroup performance gaps at test time without platform cooperation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
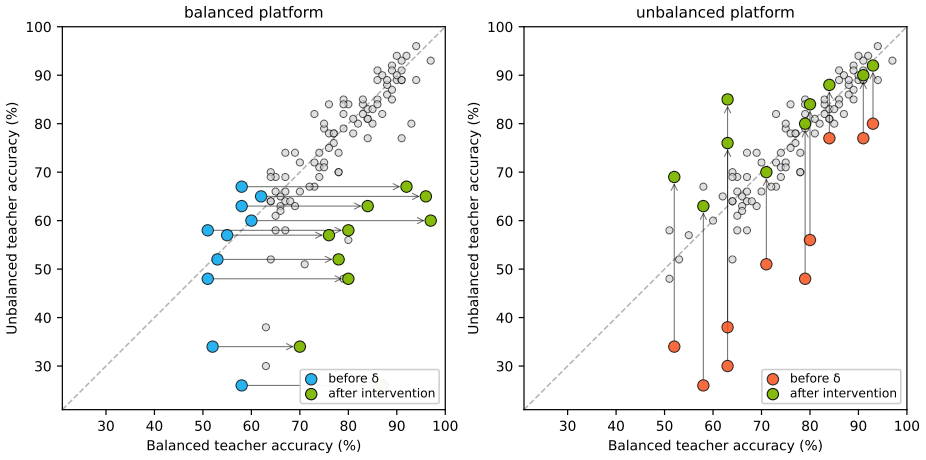
Test-Time Collective Action lets coordinated users correct algorithmic harms by pooling queries to extract a proxy of a black-box platform model, optimizing a per-class universal perturbation against the proxy, and applying that perturbation to their inputs at submission time, thereby improving subgroup accuracy, worst-group performance, equal-opportunity gap, and disparate impact without any participation in the platform's training loop.
What carries the argument
Proxy-based per-class universal perturbation optimized on a model extracted from pooled black-box queries.
If this is right
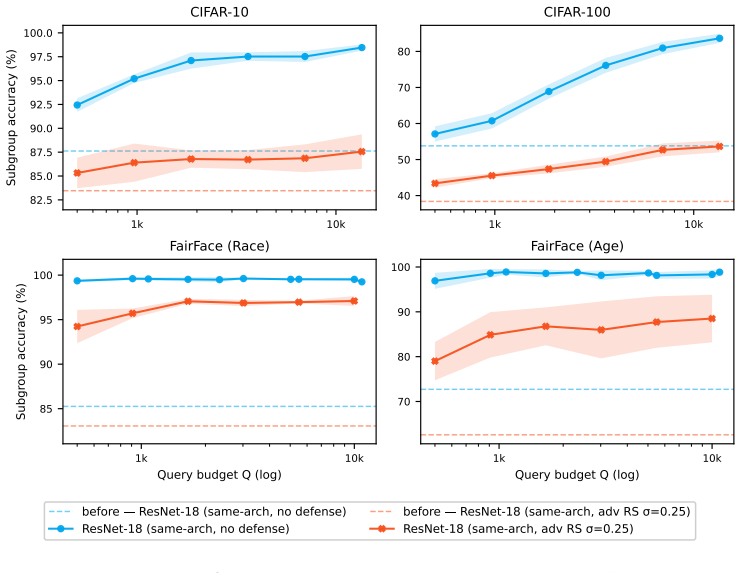
- Modestly sized collectives close most of the subgroup accuracy gap on CIFAR-10, CIFAR-100, and FairFace.
- The perturbations transfer across architectures so a small proxy can affect a larger platform model.
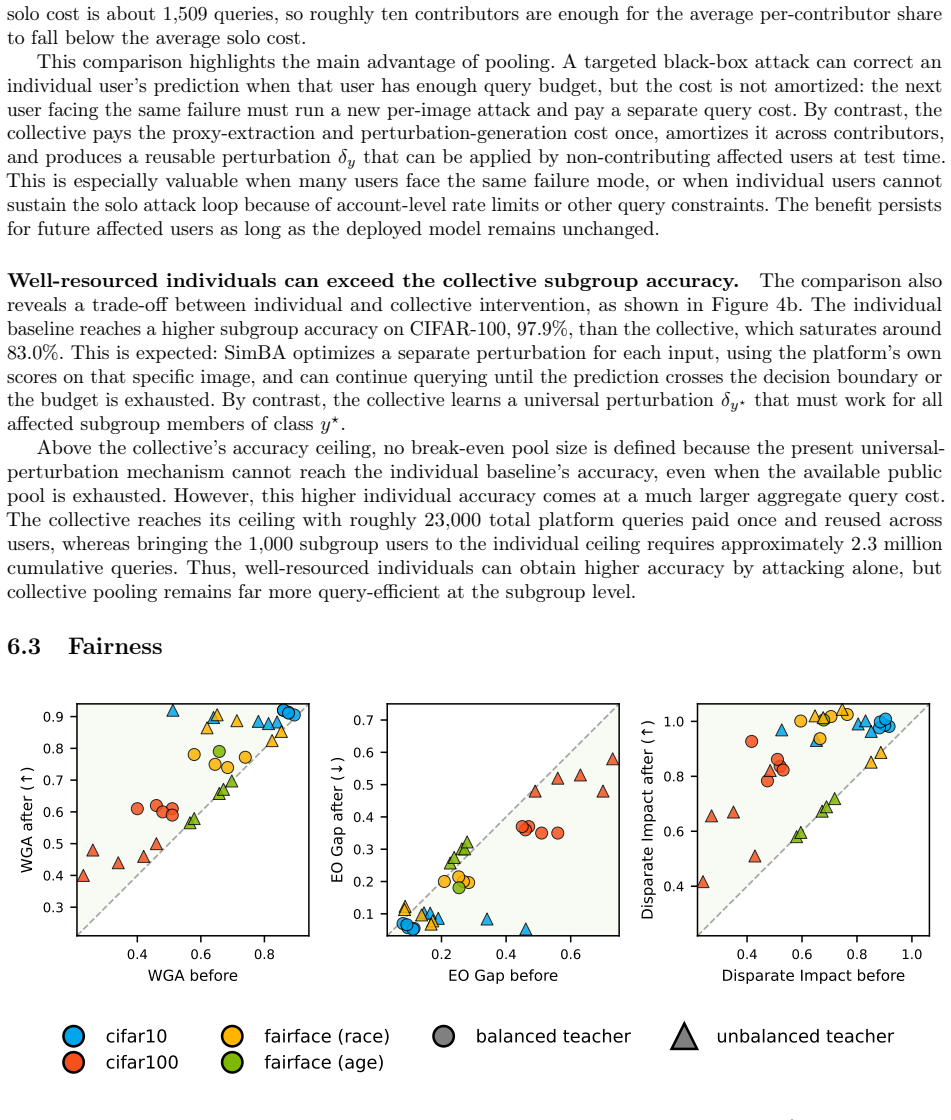
- The method improves worst-group accuracy, equal-opportunity gap, and disparate impact.
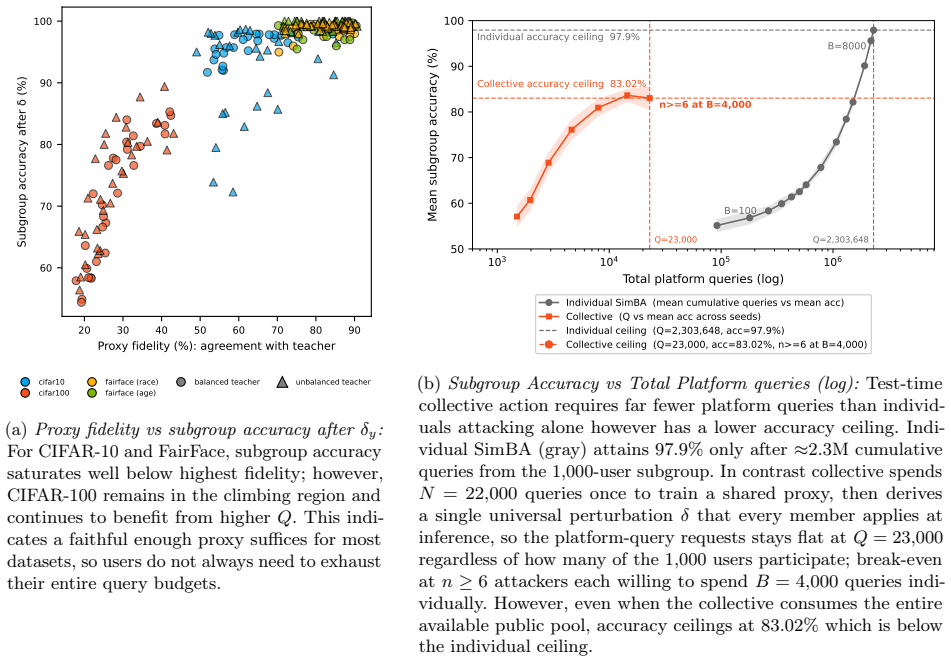
- Pooling queries reduces the total query budget compared with each user attacking independently.
Where Pith is reading between the lines
- The approach could be adapted to other input modalities if black-box query access remains available.
- Platforms may need new detection mechanisms to distinguish collective perturbations from normal user inputs.
- Repeated application of such perturbations might create an arms race between collectives and platform defenses.
- The technique opens a route for users to exert corrective pressure on deployed systems when providers are slow or unwilling to act.
Load-bearing premise
A proxy model extracted from pooled black-box queries is close enough to the real platform model that the optimized perturbation will transfer and improve performance on the actual system.
What would settle it
Build the proxy from pooled queries on one architecture or data distribution, optimize the perturbation, then measure whether subgroup accuracy improves when the same perturbation is applied to the real platform model trained on a substantially different architecture or distribution.
Figures



read the original abstract
When machine learning systems under-perform for particular subgroups, affected users typically have no way to correct these disparities without relying on platform-level fixes. Existing approaches to algorithmic fairness rely on provider-centric approaches to correct these failures, leaving users with no external lever when faced with harm. Recent work in Algorithmic Collective Action shows that coordinated users can steer an algorithmic system toward a collective goal, but the existing mechanisms require the provider to retrain on the collective's modified data which users may not have control over. We propose Test-Time Collective Action (TTCA), a framework through which a group of users who share query access to the platform, can correct disparities affecting under-served subgroup without participating in the platform's training loop. We implement this through a proxy-based mechanism where the collective pools query access to a black-box API to extract a proxy of the platform, then optimizes a per-class universal perturbation against the proxy. Each member applies this perturbation to their own inputs at submission time, requiring no cooperation from the platform. We empirically evaluate the mechanism on CIFAR-10, CIFAR-100, and FairFace, showing that modestly-sized collectives close most of the subgroup accuracy gap, transfer across architectures (a small proxy can attack a larger platform), and improve worst-group accuracy, equal-opportunity gap, and disparate impact. A query-budget analysis comparing a per-user black-box attack baseline shows that pooling is cheaper than each subgroup member attacking alone. Test-time collective action thus offers corrective intervention to users when platform-side remediation is unavailable or delayed.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Test-Time Collective Action (TTCA), a framework in which a collective of users pools black-box API queries to train a proxy model of a platform, optimizes per-class universal perturbations against this proxy, and applies the perturbations to their inputs at inference time. This is intended to correct subgroup performance disparities (e.g., accuracy gaps, worst-group accuracy, equal-opportunity gap, disparate impact) on CIFAR-10, CIFAR-100, and FairFace without requiring platform retraining or cooperation. The authors report that modestly sized collectives achieve most of the gap closure, that the perturbations transfer across architectures (small proxy to larger target), and that query pooling is more efficient than per-user attacks.
Significance. If the empirical transfer results hold under the reported conditions, TTCA would constitute a practical user-side intervention for algorithmic harms in deployed black-box systems, extending collective-action ideas from training-time data modification to test-time perturbations. The query-efficiency comparison and cross-architecture transfer are potentially useful engineering contributions, though the work remains an empirical method without parameter-free derivations or formal guarantees.
major comments (2)
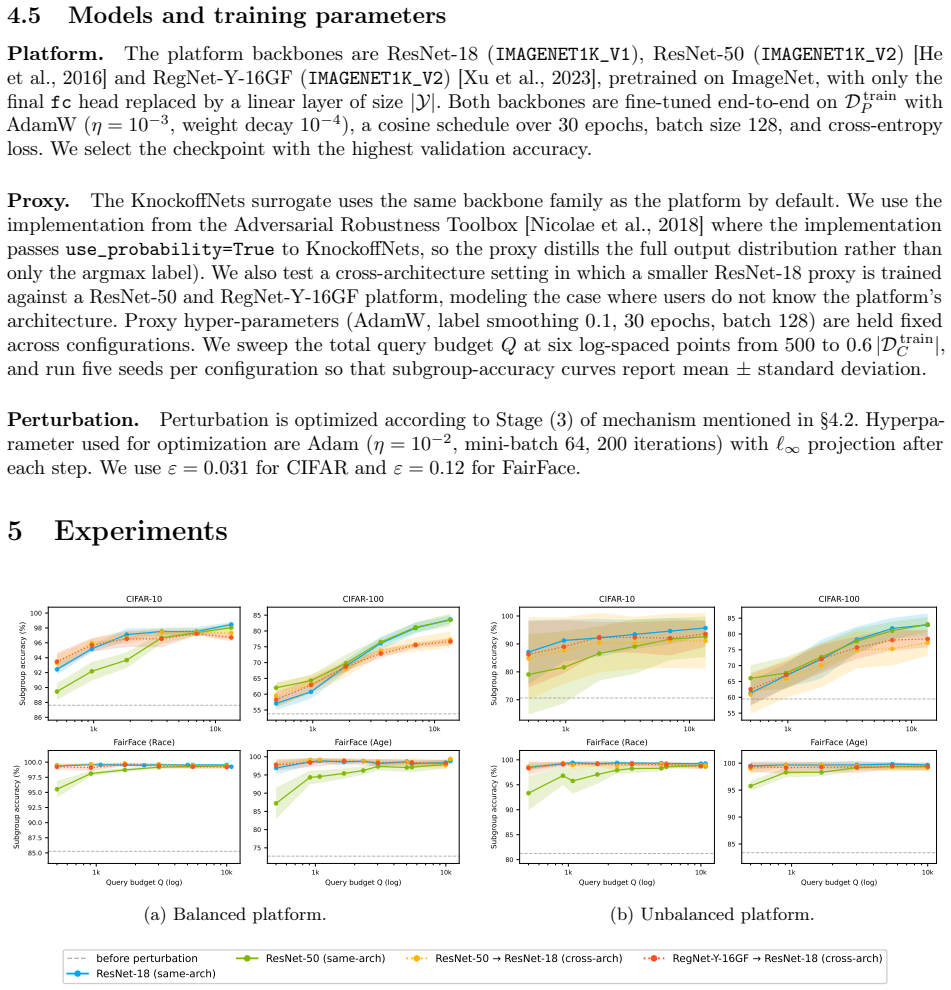
- [Empirical Evaluation (and proxy construction description)] The central transfer claim (proxy-optimized per-class universal perturbation improves subgroup metrics on the true platform model) rests on the unexamined assumption that the surrogate, trained on pooled queries, faithfully captures the subgroup decision boundaries of the target. No section provides the query-selection strategy, number of queries per class, surrogate architecture/loss, or ablation on proxy size vs. target size; without these, it is impossible to assess whether the reported gap closures are robust or could increase error on the real model when the proxy is smaller or architecturally mismatched.
- [Abstract and results sections] The abstract states that TTCA 'close[s] most of the subgroup accuracy gap' and improves worst-group accuracy, EO gap, and DI, yet supplies no numerical values, error bars, statistical tests, or ablation tables. This prevents verification of effect sizes or whether the improvements are driven by the collective mechanism versus generic perturbation effects.
minor comments (2)
- [Method] Notation for the per-class universal perturbation and the proxy training objective should be defined explicitly with equations rather than prose descriptions.
- [Query-budget analysis] The query-budget analysis would benefit from a table comparing total queries for collective vs. individual attacks across the three datasets.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on the manuscript. We address each major comment below and indicate the revisions that will be incorporated.
read point-by-point responses
-
Referee: [Empirical Evaluation (and proxy construction description)] The central transfer claim (proxy-optimized per-class universal perturbation improves subgroup metrics on the true platform model) rests on the unexamined assumption that the surrogate, trained on pooled queries, faithfully captures the subgroup decision boundaries of the target. No section provides the query-selection strategy, number of queries per class, surrogate architecture/loss, or ablation on proxy size vs. target size; without these, it is impossible to assess whether the reported gap closures are robust or could increase error on the real model when the proxy is smaller or architecturally mismatched.
Authors: We agree that the current manuscript lacks sufficient detail on proxy construction to fully support evaluation of the transfer results. In the revised version we will add a dedicated subsection specifying the query-selection strategy, queries per class, surrogate architecture and loss, and ablations on proxy size relative to the target. This will allow assessment of robustness under architectural mismatch. revision: yes
-
Referee: [Abstract and results sections] The abstract states that TTCA 'close[s] most of the subgroup accuracy gap' and improves worst-group accuracy, EO gap, and DI, yet supplies no numerical values, error bars, statistical tests, or ablation tables. This prevents verification of effect sizes or whether the improvements are driven by the collective mechanism versus generic perturbation effects.
Authors: The abstract is a high-level summary and omits numbers for brevity. We will revise the results sections to report concrete numerical values for gap closures and other metrics, include error bars from repeated trials, statistical significance tests, and ablation tables that isolate the collective pooling benefit from generic perturbation effects. revision: yes
Circularity Check
No significant circularity; empirical method with external validation
full rationale
The paper proposes TTCA as an empirical engineering framework: users pool black-box queries to train a proxy, optimize a per-class universal perturbation on that proxy, and apply it at test time. No load-bearing step reduces by construction to a fitted parameter or self-citation chain; the central claims rest on experimental results across CIFAR-10/100 and FairFace that are independently falsifiable via replication on the same benchmarks. The approach contains no uniqueness theorems, ansatzes smuggled via citation, or renamings of known results as derivations. This is the expected non-finding for a methods paper whose validity is measured by transfer performance rather than internal algebraic closure.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Fairness for the people, by the people: Minority collective action.arXiv preprint arXiv:2508.15374,
Omri Ben-Dov, Samira Samadi, Amartya Sanyal, and Alexandru Ţifrea. Fairness for the people, by the people: Minority collective action.arXiv preprint arXiv:2508.15374,
-
[2]
14 Tom B Brown, Dandelion Mané, Aurko Roy, Martín Abadi, and Justin Gilmer. Adversarial patch.arXiv preprint arXiv:1712.09665,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
ISSN 0360-0300. doi: 10.1145/3616865. URLhttps://doi.org/10.1145/3616865. Khaoula Chehbouni, Megha Roshan, Emmanuel Ma, Futian Andrew Wei, Afaf Taïk, Jackie Chi Kit Cheung, and Golnoosh Farnadi. From representational harms to quality-of-service harms: A case study on llama 2 safety safeguards. InACL (Findings), Findings of ACL, pages 15694–15710. Associat...
-
[4]
Bogdan Kulynych, Rebekah Overdorf, Carmela Troncoso, and Seda F
URLhttps://www.cs.toronto.edu/~kriz/ learning-features-2009-TR.pdf. Bogdan Kulynych, Rebekah Overdorf, Carmela Troncoso, and Seda F. Gürses. Pots: protective optimization technologies. InF AT*, pages 177–188. ACM,
2009
-
[5]
Crowding Out The Noise: Algorithmic Collective Action Under Differential Privacy
Rushabh Solanki, Meghana Bhange, Ulrich Aïvodji, and Elliot Creager. Crowding out the noise: Algorithmic collective action under differential privacy.arXiv preprint arXiv:2505.05707,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
URLhttps://doi.org/10.1145/3630107
doi: 10.1145/3630107. URLhttps://doi.org/10.1145/3630107. 17 A Appendix A.1 Cross-label transfer 103 104 Collective pool size N (log) 0 20 40 60 80 100 Mean prediction rate M[ytrue, ytarget] (%) CIFAR-10 ytrue = ytarget CIFAR-10 ytrue ytarget CIFAR-100 ytrue = ytarget CIFAR-100 ytrue ytarget (a) CIFAR-10 and CIFAR-100. 103 104 Collective pool size N (log)...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.