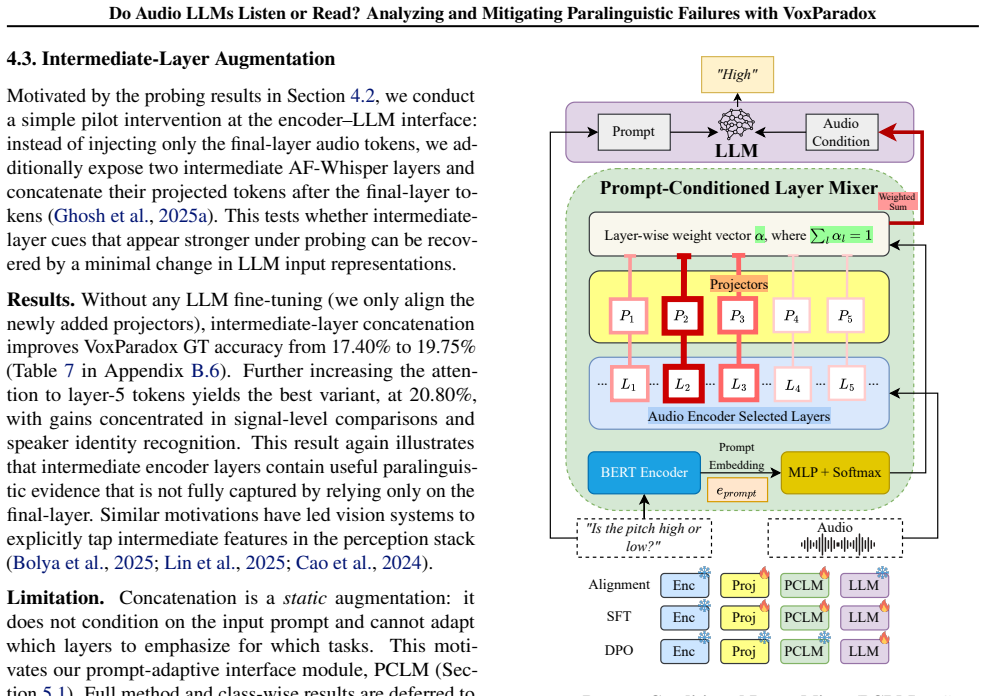
Do Audio LLMs Listen or Read? Analyzing and Mitigating Paralinguistic Failures with VoxParadox
Pith reviewed 2026-06-29 15:15 UTC · model grok-4.3
The pith
Audio LLMs ignore paralinguistic cues in speech and default to transcript meaning instead.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Audio LLMs exhibit low accuracy on acoustic ground truth and a strong tendency to follow language-implied incorrect answers on paralinguistic tasks; paralinguistic cues degrade in deeper encoder layers and at the encoder-LLM interface, and even when present the language model frequently ignores them, but Prompt-Conditioned Layer Mixer combined with Direct Preference Optimization substantially raises performance by adaptively mixing layers and preferring acoustically supported outputs.
What carries the argument
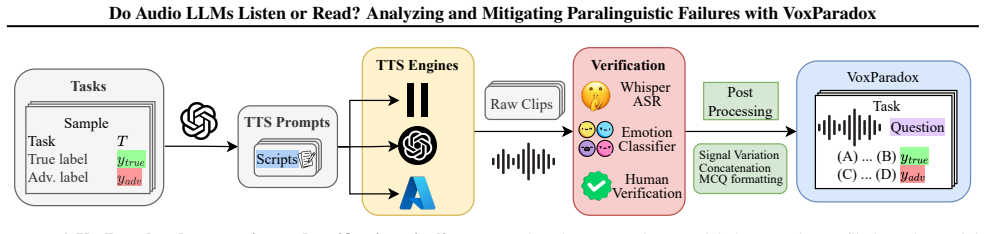
VoxParadox adversarial benchmark that creates intentional mismatches between transcript claims and speaking style via controlled speech synthesis, together with Prompt-Conditioned Layer Mixer that adaptively combines information from multiple audio encoder layers conditioned on the input prompt.
If this is right
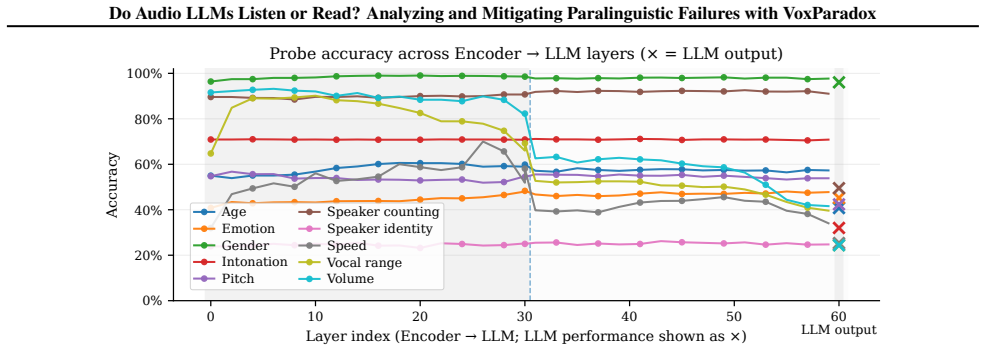
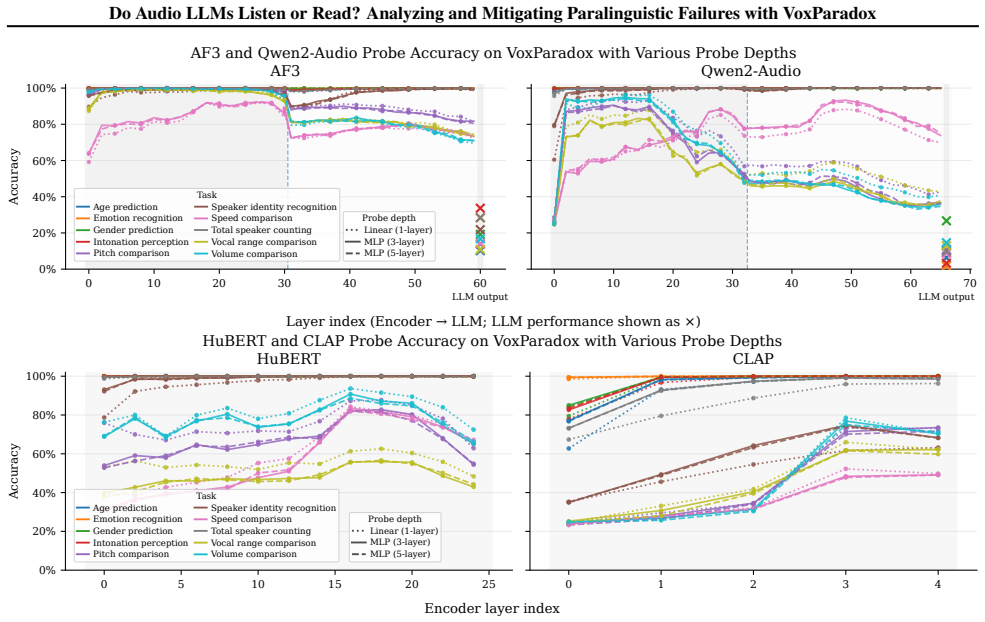
- Layer-wise probing identifies degradation of paralinguistic cues in deeper audio encoder layers and at the encoder-LLM interface.
- Even when paralinguistic cues remain available in audio tokens, the language model component frequently ignores them in favor of language-implied answers.
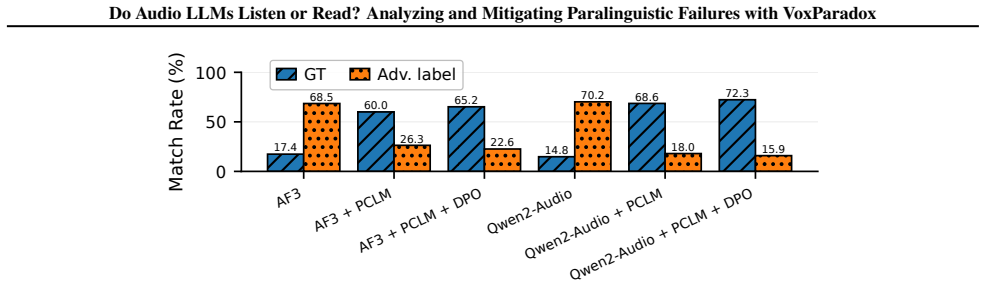
- Prompt-Conditioned Layer Mixer combined with Direct Preference Optimization raises accuracy on VoxParadox from 17.40 percent to 65.20 percent for Audio Flamingo 3.
- The same methods improve performance on the existing MMSU paralinguistic subset from 37.74 percent to 54.78 percent.
Where Pith is reading between the lines
- Applications that rely on detecting sarcasm, emotion, or intent from spoken audio may currently suffer systematic errors when models default to transcript semantics.
- Training objectives that explicitly reward attention to acoustic features over linguistic ones could be tested as a general remedy beyond the proposed PCLM and DPO steps.
- Extending the benchmark construction method to additional languages or acoustic conditions would test whether the identified failure mode generalizes.
Load-bearing premise
The controlled speech synthesis used to create VoxParadox produces audio whose paralinguistic attributes are perceived by the models exactly as intended by the synthesis parameters, without introducing confounding acoustic artifacts that alter model behavior in unmeasured ways.
What would settle it
Evaluating the same models and methods on a collection of real human speech recordings that contain verified mismatches between spoken words and paralinguistic attributes would show whether the observed failures and improvements hold without synthesis artifacts.
Figures

read the original abstract
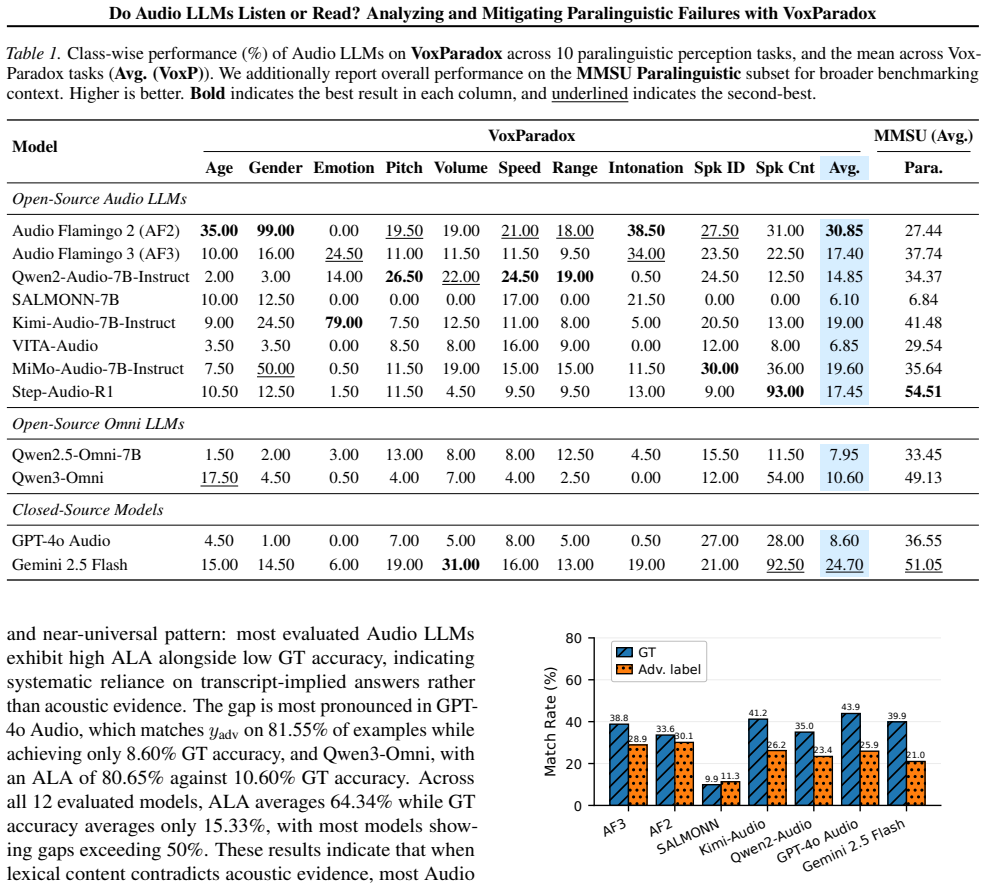
Audio large language models (Audio LLMs) demonstrate strong performance on speech understanding tasks, yet their ability to understand paralinguistic information remains limited. To systematically quantify this issue, we introduce VoxParadox, an adversarial benchmark with 2,000 verified examples, spanning 10 paralinguistic tasks, created with controlled speech synthesis to intentionally mismatch transcript claims and speaking style, enabling direct measurement of speech paralinguistic understanding. Evaluation of a diverse set of Audio LLMs reveals consistently low accuracy on acoustic ground truth and a strong tendency to follow language-implied (incorrect) answers. To understand the cause of this gap, we perform layer-wise probing and find that (i) paralinguistic cues can degrade in deeper encoder layers and at the encoder--LLM interface, and (ii) even when such cues are available in audio tokens, the language model frequently ignores them. To address these problems, we propose Prompt-Conditioned Layer Mixer (PCLM), which adaptively combines information from multiple audio layers based on the input prompt, and pair it with Direct Preference Optimization (DPO) to explicitly prefer acoustically supported options over language-implied alternatives. These methods substantially improve Audio LLM paralinguistic understanding, improving Audio Flamingo 3 from 17.40% to 65.20% on VoxParadox, and from 37.74% to 54.78% on MMSU paralinguistic subset. Our project page is available at https://voxparadox.github.io/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces VoxParadox, a new adversarial benchmark of 2,000 verified examples across 10 paralinguistic tasks, built via controlled speech synthesis to create intentional mismatches between linguistic transcripts and acoustic style. Evaluation of multiple Audio LLMs shows consistently low accuracy on acoustic ground truth and a strong preference for language-implied (incorrect) answers. Layer-wise probing identifies cue degradation in deeper encoder layers and at the encoder-LLM interface, plus LLM ignoring of available cues. The authors propose Prompt-Conditioned Layer Mixer (PCLM) paired with DPO, reporting gains for Audio Flamingo 3 from 17.40% to 65.20% on VoxParadox and 37.74% to 54.78% on the MMSU paralinguistic subset.
Significance. If the benchmark holds, the work is significant for diagnosing a systematic limitation in Audio LLMs' paralinguistic processing and for demonstrating a mitigation approach with substantial empirical gains. The layer-wise analysis offers concrete insights into failure modes. Strengths include the controlled benchmark construction, the explicit preference optimization against language bias, and the reported transfer to an external dataset (MMSU).
major comments (2)
- [§3 (benchmark construction)] §3 (benchmark construction): The headline claims of low acoustic accuracy, language bias, and the 17.40%→65.20% lift all rest on the assumption that synthesized audio's paralinguistic attributes are perceived by models exactly as parameterized by the synthesis controls. No human listening tests, acoustic feature verification, or artifact analysis is described to rule out confounding cues (unnatural prosody, spectral distortions, or synthesis-specific patterns) that models could exploit instead of the intended ground truth. This is load-bearing for interpreting the results as general model failures rather than benchmark-specific artifacts.
- [Results (quantitative tables/figures reporting accuracy)] Results (quantitative tables/figures reporting accuracy): The reported improvements lack error bars, statistical significance tests, or details on variance across runs/seeds. Without these, it is unclear whether the gains exceed noise or post-hoc selection effects, undermining confidence in the central empirical claim.
minor comments (1)
- The abstract states '2,000 verified examples' but the verification procedure (human or otherwise) receives limited elaboration; expanding this in the main text would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments below and will revise the manuscript accordingly to strengthen the work.
read point-by-point responses
-
Referee: [§3 (benchmark construction)] §3 (benchmark construction): The headline claims of low acoustic accuracy, language bias, and the 17.40%→65.20% lift all rest on the assumption that synthesized audio's paralinguistic attributes are perceived by models exactly as parameterized by the synthesis controls. No human listening tests, acoustic feature verification, or artifact analysis is described to rule out confounding cues (unnatural prosody, spectral distortions, or synthesis-specific patterns) that models could exploit instead of the intended ground truth. This is load-bearing for interpreting the results as general model failures rather than benchmark-specific artifacts.
Authors: We agree that the absence of explicit verification leaves open the possibility of confounding cues and that this is a substantive concern for the benchmark's validity. In the revised manuscript we will add (i) human listening tests on a random subset of 200 examples (with inter-rater agreement reported) confirming that listeners perceive the intended paralinguistic attributes, and (ii) acoustic feature comparisons (pitch, energy, spectral tilt, formant statistics) between the synthesized utterances and a matched natural-speech corpus to quantify any systematic distortions. These additions will appear in an expanded §3 and a new appendix. revision: yes
-
Referee: [Results (quantitative tables/figures reporting accuracy)] Results (quantitative tables/figures reporting accuracy): The reported improvements lack error bars, statistical significance tests, or details on variance across runs/seeds. Without these, it is unclear whether the gains exceed noise or post-hoc selection effects, undermining confidence in the central empirical claim.
Authors: We accept that the current reporting lacks the statistical detail needed to assess reliability. In the revision we will recompute all main results (VoxParadox and MMSU) over five independent runs with different random seeds, report mean ± standard deviation, and include paired t-test p-values comparing each baseline to its PCLM+DPO counterpart. These statistics will be added to Tables 2–4 and the corresponding figures. revision: yes
Circularity Check
No circularity: empirical benchmark evaluation and method improvements are measured, not derived by construction
full rationale
The paper introduces VoxParadox as a new benchmark via controlled synthesis, reports direct accuracy measurements on it and on the external MMSU subset, performs layer probing, and evaluates PCLM+DPO via accuracy lifts. No equations, fitted parameters, or self-citations are used to define or force the reported results. The central claims are falsifiable empirical observations on held-out data, making the derivation chain self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
URL http: //dx.doi.org/10.1145/3664647.3681674
doi: 10.1145/3664647.3681674. URL http: //dx.doi.org/10.1145/3664647.3681674. Kang, W., Jia, J., Wu, C., Zhou, W., Lakomkin, E., Gaur, Y ., Sari, L., Kim, S., Li, K., Mahadeokar, J., and Kalinli, O. Frozen large language models can perceive paralinguistic aspects of speech. InInterspeech 2025, interspeech 2025, pp. 4323–4327. ISCA, August 2025. doi: 10.21...
-
[2]
ISSN 0885-2308. doi: 10.1016/j.csl.2012.02
-
[3]
URL https://doi.org/10.1016/j.csl. 2012.02.005. Schuller, B., Steidl, S., Batliner, A., Hirschberg, J., Burgoon, J. K., Baird, A., Elkins, A. C., Zhang, Y ., Coutinho, E., and Evanini, K. The INTERSPEECH 2016 computational paralinguistics challenge: Deception, sincerity & native language. InInterspeech, 2016. URL https://api. semanticscholar.org/CorpusID:...
-
[4]
URL https://aclanthology.org/2025. emnlp-main.974/. Shekhar, R., Pezzelle, S., Klimovich, Y ., Herbelot, A., Nabi, M., Sangineto, E., and Bernardi, R. FOIL it! find one mismatch between image and language cap- tion. InProceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computatio...
-
[5]
URL https://openreview.net/forum? id=14rn7HpKVk. Team, C., Zhang, D., Wang, G., Xue, J., Fang, K., Zhao, L., Ma, R., Ren, S., Liu, S., Guo, T., Zhuang, W., Zhang, X., Song, X., Yan, Y ., He, Y ., Cici, Shen, B., Zhu, C., Ma, C., Chen, C., Chen, H., Li, J., Li, L., Zhu, M., Li, P., Wang, Q., Deng, S., Xiong, W., Huang, W., Yang, W., Jiang, Y ., Yang, Y ., ...
-
[6]
URL https://aclanthology.org/2025. findings-emnlp.760/. Wang, Q., Sailor, H. B., Wong, J. H. M., Liu, T., Sun, S., Zhang, W., Huzaifah, M., Chen, N. F., and Aw, A. Incor- porating contextual paralinguistic understanding in large speech-language models. In2025 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), pp. 1–8, 2025b. wen Yang, S....
-
[7]
Association for Computational Linguistics. ISBN 979-8-89176-251-0. doi: 10.18653/v1/2025.acl-long
-
[8]
URL https://aclanthology.org/2025. acl-long.598/. 14 Do Audio LLMs Listen or Read? Analyzing and Mitigating Paralinguistic Failures with VoxParadox Appendix Contents A.V oxParadox Dataset Details . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15 ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.