Are Diffusion Language Models Good Database Analysts?
Pith reviewed 2026-06-29 09:50 UTC · model grok-4.3
The pith
Diffusion language models reduce sequential errors in natural language to SQL generation through iterative refinement.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
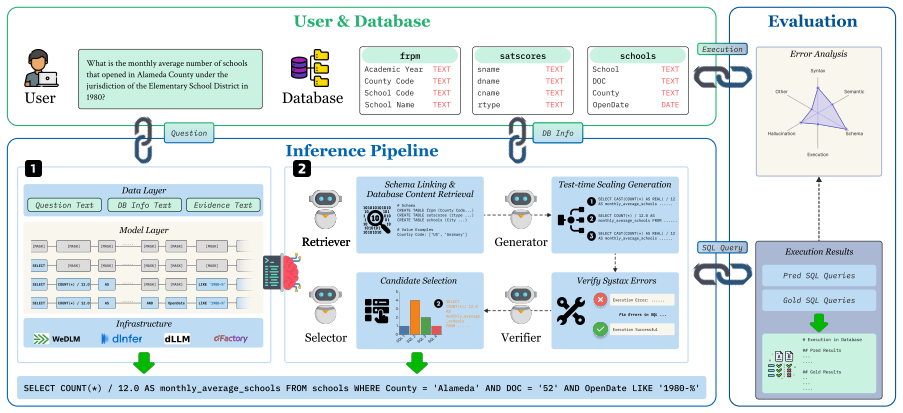
Through a unified evaluation framework that standardizes generation and execution across DLM architectures, and the SQL-D1 agent that combines database-aware context engineering, test-time scaling, and interactive optimization, the work shows that diffusion language models deliver structural robustness advantages and support adjustable efficiency-accuracy balances in NL2SQL compared with autoregressive baselines.
What carries the argument
SQL-D1 agentic framework, which supplies database context, enables test-time scaling, and performs interactive optimization to adapt diffusion models to structured SQL output.
If this is right
- DLMs can avoid left-to-right error chains in SQL by refining the full sequence at once.
- Database agents can tune the number of denoising steps to trade speed for higher accuracy on complex queries.
- Post-training stability experiments indicate DLMs maintain performance more consistently than AR models when fine-tuned on SQL tasks.
- Failure mode analysis reveals diffusion models handle schema and join errors differently, suggesting targeted fixes for remaining weaknesses.
Where Pith is reading between the lines
- The same iterative refinement approach could extend to other rigid output formats such as code generation or formal proofs where global consistency matters.
- A shared evaluation harness for diffusion models in structured tasks might help compare them fairly against autoregressive systems in additional domains beyond databases.
- If efficiency-accuracy knobs prove reliable, smaller diffusion models might reach usable NL2SQL performance without matching the parameter count of leading autoregressive systems.
Load-bearing premise
The evaluation framework and SQL-D1 agent truly isolate the diffusion decoding method rather than being shaped by differences in model size, data, or engineering details.
What would settle it
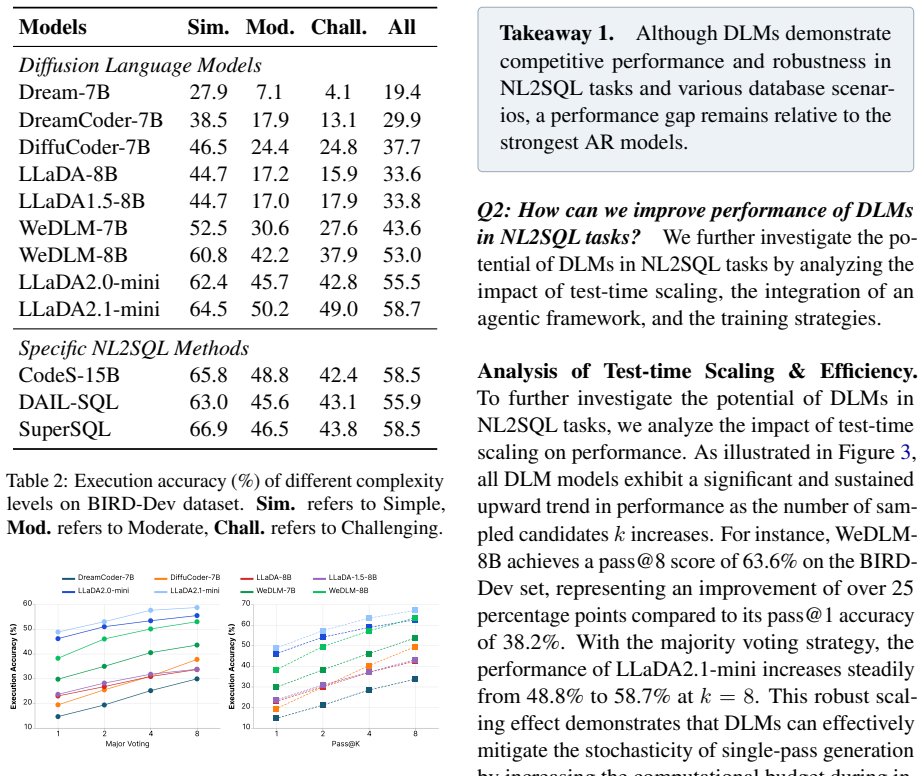
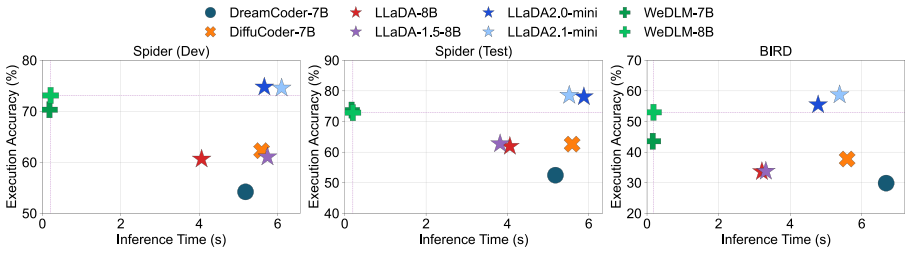
Compare diffusion and autoregressive models on identical NL2SQL benchmarks using the same model scale, training data volume, and the proposed unified framework; check whether diffusion models retain measurable gains in structural robustness metrics.
Figures



read the original abstract
Recent advancements in large language models (LLMs) have significantly improved Natural Language to SQL (NL2SQL) tasks, yet most NL2SQL systems continue to rely on the autoregressive (AR) paradigm. The highly structured nature of SQL makes AR models susceptible to sequential error propagation due to their rigid left-to-right decoding process. Diffusion Language Models~(DLMs) have recently emerged as a promising alternative, replacing unidirectional decoding with iterative denoising to enable global sequence refinement. Nevertheless, the adoption of DLMs in NL2SQL is constrained by a fragmented ecosystem and the absence of a standardized evaluation framework, which obscures their true capabilities and impedes fair comparison with AR baselines. In this paper, we propose a unified evaluation framework that standardizes both generation and execution environments across various DLM architectures. To further improve the performance of DLMs-based NL2SQL systems, we propose \texttt{SQL-D1}, a novel agentic framework that integrates database-aware context engineering, test-time scaling and interactive optimization. Through extensive empirical studies on scaling properties, post-training stability, and primary failure modes, we demonstrate that DLMs offer distinct advantages in structural robustness and facilitate flexible trade-offs between efficiency and accuracy. By distilling these insights into structured takeaways, our work provides a systematic understanding of DLMs-based NL2SQL and lays the foundation for future database analysis agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a unified evaluation framework to standardize generation and execution for diffusion language models (DLMs) in NL2SQL tasks, introduces the SQL-D1 agentic framework incorporating database-aware context engineering, test-time scaling, and interactive optimization, and reports empirical studies on scaling properties, post-training stability, and failure modes to claim that DLMs provide structural robustness advantages over autoregressive models along with flexible efficiency-accuracy trade-offs.
Significance. If the empirical results hold after adequate controls, the work would be significant for database analysis agents by challenging the default autoregressive paradigm for structured outputs like SQL and supplying a standardized framework that could enable reproducible comparisons; the distillation of takeaways on failure modes and scaling is a constructive contribution.
major comments (2)
- [Empirical studies (scaling, stability, failure modes)] The central claim of distinct DLM advantages in structural robustness rests on the empirical studies, yet the manuscript provides no explicit description of matched controls for model scale, training data volume/quality, or non-paradigm factors (e.g., context length, test-time compute) when comparing DLMs to AR baselines; without such isolation the observed differences cannot be attributed to the diffusion paradigm (see the skeptic concern on confounders).
- [Unified evaluation framework and SQL-D1 sections] The unified evaluation framework and SQL-D1 agent are presented as enabling fair comparison, but the text does not detail how generation/execution environments are standardized across architectures or whether the agent components are applied identically to AR baselines, which is load-bearing for the claim that advantages are paradigm-specific.
minor comments (2)
- Notation for DLM architectures and SQL-D1 components could be clarified with a table of acronyms and parameters.
- The abstract states 'extensive empirical studies' but the manuscript would benefit from an explicit methods subsection listing datasets, exact baselines, and metrics before results.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our empirical controls and the clarity of our standardization procedures. We address each major comment below and commit to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Empirical studies (scaling, stability, failure modes)] The central claim of distinct DLM advantages in structural robustness rests on the empirical studies, yet the manuscript provides no explicit description of matched controls for model scale, training data volume/quality, or non-paradigm factors (e.g., context length, test-time compute) when comparing DLMs to AR baselines; without such isolation the observed differences cannot be attributed to the diffusion paradigm (see the skeptic concern on confounders).
Authors: We agree that explicit documentation of controls is necessary to support paradigm-specific claims. The original experiments matched model scales (comparing models of comparable parameter counts) and used the same NL2SQL fine-tuning corpora where available; context lengths and execution environments were also aligned via the unified framework. However, we did not provide a dedicated discussion of all potential confounders such as training data quality differences or exact test-time compute parity. We will add an 'Experimental Controls and Confounders' subsection that details the matching procedures performed, reports any unavoidable differences due to paradigm-specific training requirements, and discusses their implications for attribution. This addresses the concern directly. revision: yes
-
Referee: [Unified evaluation framework and SQL-D1 sections] The unified evaluation framework and SQL-D1 agent are presented as enabling fair comparison, but the text does not detail how generation/execution environments are standardized across architectures or whether the agent components are applied identically to AR baselines, which is load-bearing for the claim that advantages are paradigm-specific.
Authors: The unified framework standardizes generation (via shared SQL syntax constraints and denoising schedules) and execution (via identical database instances, query validators, and result comparators) for all models. SQL-D1 components were applied equivalently to AR baselines in the reported comparisons to enable direct paradigm contrasts. We will revise the 'Unified Evaluation Framework' and 'SQL-D1' sections to include explicit descriptions of these standardizations, confirmation of identical agent component usage across architectures, and additional implementation details (e.g., pseudocode for the shared pipeline). This will make the fairness of the comparisons transparent. revision: yes
Circularity Check
No derivation chain present; empirical claims only
full rationale
The paper contains no equations, first-principles derivations, fitted parameters presented as predictions, or self-citation chains that reduce any result to its inputs by construction. All central claims rest on proposed frameworks (unified evaluation, SQL-D1 agent) and subsequent empirical studies whose outcomes are not forced by the framework definitions themselves. No load-bearing self-citations or ansatzes are invoked to justify uniqueness or results. This is a standard empirical comparison paper whose independence from its own inputs is not in question under the circularity criteria.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
C3: Zero-shot text-to-SQL with ChatGPT,
C3: Zero-shot text-to-sql with chatgpt.arXiv preprint arXiv:2307.07306. Yujian Gan, Xinyun Chen, Qiuping Huang, Matthew Purver, John R. Woodward, Jinxia Xie, and Peng- sheng Huang. 2021a. Towards robustness of text-to- SQL models against synonym substitution. pages 2505–2515, Online. Association for Computational Linguistics. Yujian Gan, Xinyun Chen, and ...
-
[2]
Jinjie Ni, Qian Liu, Chao Du, Longxu Dou, Hang Yan, Zili Wang, Tianyu Pang, and Michael Qizhe Shieh
Diver: A robust text-to-sql system with dy- namic interactive value linking and evidence reason- ing.Proceedings of the ACM on Management of Data, 4(1):1–24. Jinjie Ni, Qian Liu, Chao Du, Longxu Dou, Hang Yan, Zili Wang, Tianyu Pang, and Michael Qizhe Shieh
-
[3]
Shen Nie, Fengqi Zhu, Chao Du, Tianyu Pang, Qian Liu, Guangtao Zeng, Min Lin, and Chongxuan Li
Training optimal large diffusion language mod- els.Preprint, arXiv:2510.03280. Shen Nie, Fengqi Zhu, Chao Du, Tianyu Pang, Qian Liu, Guangtao Zeng, Min Lin, and Chongxuan Li. 2025a. Scaling up masked diffusion models on text. Preprint, arXiv:2410.18514. Shen Nie, Fengqi Zhu, Zebin You, Xiaolu Zhang, Jingyang Ou, Jun Hu, Jun Zhou, Yankai Lin, Ji-Rong Wen, ...
-
[4]
Generalized interpolating discrete diffusion. Preprint, arXiv:2503.04482. Bing Wang, Changyu Ren, Jian Yang, Xinnian Liang, Ji- aqi Bai, Linzheng Chai, Zhao Yan, Qian-Wen Zhang, Di Yin, Xing Sun, and Zhoujun Li. 2024. Mac-sql: A multi-agent collaborative framework for text-to-sql. Preprint, arXiv:2312.11242. Pengfei Wang, Baolin Sun, Xuemei Dong, Yaxun Da...
-
[5]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. Haolin Yang, Jipeng Zhang, Zhitao He, Alexander Zhou, and Yi R. Fung. 2026a. Mars-sql: A multi-agent reinforcement learning framework for text-to-sql. Preprint, arXiv:2511.01008. Jiaxi Yang, Binyuan Hui, Min Yang, Jian Yang, Junyang Lin, and Chang Zhou. 2024. Synthesizing text-to- sql data from weak ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Dream 7B: Diffusion Large Language Models
Dream 7b: Diffusion large language models. arXiv preprint arXiv:2508.15487. Runpeng Yu, Qi Li, and Xinchao Wang. 2025. Discrete diffusion in large language and multimodal models: A survey.arXiv preprint arXiv:2506.13759. Tao Yu, Rui Zhang, Kai Yang, Michihiro Yasunaga, Dongxu Wang, Zifan Li, James Ma, Irene Li, Qingn- ing Yao, Shanelle Roman, Zilin Zhang,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
to characterize the performance gap between current DLMs and the most advanced sequential generation paradigms in the NL2SQL domain. To ensure a fair comparison, all AR baselines are eval- uated using the same retrieval-augmented context and, where applicable, identical verification and selection budgets as their DLM counterparts, as specified in Table 1....
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.