Dasheng AudioGen: A Unified Model for Generating Coherent Audio Scenes from Text
Pith reviewed 2026-06-29 10:52 UTC · model grok-4.3
The pith
A unified model generates coherent mixed audio scenes from text using layered captions and a shared high-dimensional space.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
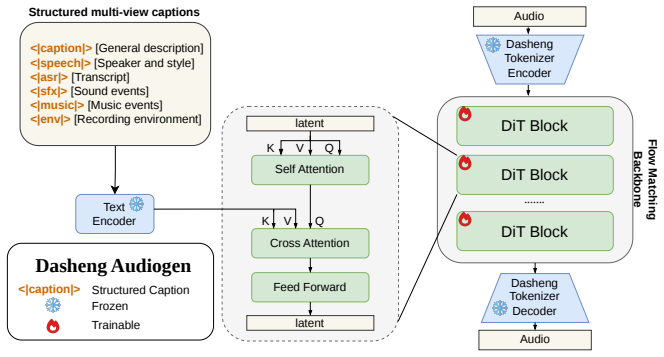
Dasheng AudioGen is a unified framework for generating general mixed-audio scenes from text. It introduces structured multi-view captions that explicitly decouple complex acoustic scenes into complementary description views for fine-grained control and employs a high-dimensional unified semantic-acoustic representation as the shared latent space that injects semantic priors for cross-modal convergence and supplies capacity to disentangle and fuse concurrent audio components. With these designs a simple flow-matching DiT achieves high-quality end-to-end audio scene generation, approaching real-world recordings in mixed-audio categories while remaining competitive with specialized models in si
What carries the argument
Structured multi-view captions that decouple scenes into complementary description views together with a high-dimensional unified semantic-acoustic representation as the shared latent space for a flow-matching DiT.
If this is right
- One model can replace multiple domain-specific audio generators for both mixed and single-type tasks.
- Multi-view captions enable explicit fine-grained control over separate audio layers within a single scene.
- Semantic priors in the latent space improve training convergence across text and audio modalities.
- A standardized evaluation pipeline becomes available for measuring progress on coherent audio scene generation.
Where Pith is reading between the lines
- The same layered-caption and unified-representation strategy could be tested on synchronized audio-visual scene generation.
- The disentanglement capacity might extend to handling overlapping sounds in real-time applications such as virtual environments.
- If the representation scales, separate datasets for speech, music, and effects may become less necessary.
Load-bearing premise
The high-dimensional unified semantic-acoustic representation supplies enough capacity to disentangle and fuse concurrent audio components in mixed scenes.
What would settle it
A head-to-head evaluation in the paper's proposed pipeline where Dasheng AudioGen mixed-audio outputs score substantially below real-world recordings on perceptual quality metrics.
Figures



read the original abstract
Audio generation has long been fragmented, with speech, music, and sound effects produced by domain-specific models that fail to jointly generate coherent audio scenes from a single description. The key obstacles are insufficient fine-grained supervision for real-world mixed audio and limited acoustic representations for modeling concurrent audio components. We present Dasheng AudioGen, a unified framework for generating general mixed-audio scenes from text. Dasheng AudioGen introduces structured multi-view captions, which explicitly decouple complex acoustic scenes into complementary description views, thereby enabling fine-grained control over audio layers. Furthermore, we employ a high-dimensional unified semantic-acoustic representation as the shared latent space. It injects semantic priors that facilitate cross-modal training convergence, while its high-dimensional feature space provides sufficient capacity to disentangle and fuse concurrent audio components effectively. With these designs, a simple flow-matching DiT achieves high-quality end-to-end audio scene generation. We also establish a comprehensive evaluation pipeline for audio scene generation. Experiments demonstrate that Dasheng AudioGen achieves performance approaching real-world recordings in mixed-audio categories, while remaining competitive with specialized models in single-type generation tasks. Demos are available at https://nieeim.github.io/Dasheng-AudioGen-Web/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents Dasheng AudioGen, a unified text-to-audio model for generating coherent mixed-audio scenes. It introduces structured multi-view captions that decouple complex scenes into complementary description views for fine-grained supervision, and employs a high-dimensional unified semantic-acoustic representation as the shared latent space to inject semantic priors and enable disentangling/fusion of concurrent components. These designs are paired with a simple flow-matching DiT for end-to-end generation. The authors also establish a comprehensive evaluation pipeline and claim that the model approaches real-world recording quality in mixed-audio categories while remaining competitive with specialized models on single-type tasks.
Significance. If the empirical results hold with rigorous metrics and ablations, the work would be significant for unifying fragmented audio generation domains (speech, music, effects) into coherent scene synthesis. The multi-view captioning and unified latent space directly target stated obstacles in supervision and concurrent modeling; a simple DiT succeeding would highlight the value of these priors. Establishing an evaluation pipeline is a constructive field contribution. The absence of quantitative details in the abstract, however, prevents assessing whether the central claim is supported.
major comments (2)
- [Abstract] Abstract: The central empirical claim—that Dasheng AudioGen 'achieves performance approaching real-world recordings in mixed-audio categories' and 'remains competitive with specialized models in single-type generation tasks'—is stated without any metrics (e.g., FID, CLAP, FAD), baselines, dataset sizes, or error analysis. This is load-bearing for the paper's main contribution and cannot be evaluated from the provided text.
- [Abstract] Abstract (representation paragraph): The assertion that the 'high-dimensional unified semantic-acoustic representation injects semantic priors that facilitate cross-modal training convergence' and 'provides sufficient capacity to disentangle and fuse concurrent audio components' is presented as enabling the DiT result, yet no ablation, dimensionality analysis, or visualization is referenced to substantiate the disentangling capacity. This assumption is load-bearing for the architectural novelty.
minor comments (1)
- [Abstract] The link to demos is provided but no quantitative comparison table or pipeline details are summarized even at a high level.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. The points raised are valid, and we will revise the abstract in the next version to include quantitative metrics and references to supporting analyses from the main text. This will make the central claims more self-contained while preserving the abstract's brevity.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central empirical claim—that Dasheng AudioGen 'achieves performance approaching real-world recordings in mixed-audio categories' and 'remains competitive with specialized models in single-type generation tasks'—is stated without any metrics (e.g., FID, CLAP, FAD), baselines, dataset sizes, or error analysis. This is load-bearing for the paper's main contribution and cannot be evaluated from the provided text.
Authors: We agree that the abstract would be strengthened by including concrete metrics. The full manuscript reports results using FAD, CLAP, and other metrics on mixed-audio and single-type tasks, with comparisons to specialized baselines and real recordings. We will revise the abstract to incorporate key quantitative highlights (e.g., FAD values approaching real-world recordings in mixed categories) along with brief mention of the evaluation setup, while respecting length constraints. revision: yes
-
Referee: [Abstract] Abstract (representation paragraph): The assertion that the 'high-dimensional unified semantic-acoustic representation injects semantic priors that facilitate cross-modal training convergence' and 'provides sufficient capacity to disentangle and fuse concurrent audio components' is presented as enabling the DiT result, yet no ablation, dimensionality analysis, or visualization is referenced to substantiate the disentangling capacity. This assumption is load-bearing for the architectural novelty.
Authors: The experiments section of the manuscript contains ablations on representation dimensionality, comparisons to alternative latent spaces, and visualizations supporting the disentangling and fusion claims. We acknowledge that the abstract does not reference these. We will revise the abstract to include a brief clause pointing to the supporting ablation studies and analyses that validate the representation's role. revision: yes
Circularity Check
No significant circularity
full rationale
The paper introduces architectural designs (structured multi-view captions and high-dimensional unified semantic-acoustic latent space) and validates them empirically with a flow-matching DiT on audio scene generation tasks. No load-bearing step reduces by construction to a self-definition, fitted parameter renamed as prediction, or self-citation chain. The central claims rest on proposed components plus external experimental benchmarks rather than internal equivalence. This is self-contained against the stated evaluation pipeline.
Axiom & Free-Parameter Ledger
invented entities (2)
-
structured multi-view captions
no independent evidence
-
high-dimensional unified semantic-acoustic representation
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Hangrui Hu, Xinfa Zhu, Ting He, Dake Guo, Bin Zhang, Xiong Wang, Zhifang Guo, Ziyue Jiang, Hongkun Hao, Zishan Guo, Xinyu Zhang, Pei Zhang, Baosong Yang, Jin Xu, Jingren Zhou, and Junyang Lin. Qwen3-tts technical report. 2026. arXiv preprint arXiv:2601.15621
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
Fastspeech: Fast, robust and controllable text to speech
Yi Ren, Yangjun Ruan, Xu Tan, Tao Qin, Sheng Zhao, Zhou Zhao, and Tie-Yan Liu. Fastspeech: Fast, robust and controllable text to speech. InAdvances in Neural Information Processing Systems (NeurIPS), 2019
2019
-
[3]
Simple and controllable music generation
Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi, and Alexandre Défossez. Simple and controllable music generation. In Advances in Neural Informa- tion Processing Systems (NeurIPS), 2023
2023
-
[4]
Denk, Zalán Borsos, Jesse Engel, Mauro Verzetti, Antoine Caillon, Qingqing Huang, Aren Jansen, Adam Roberts, Marco Tagliasacchi, Matt Sharifi, Neil Zeghidour, and Christian Frank
Andrea Agostinelli, Timo I. Denk, Zalán Borsos, Jesse Engel, Mauro Verzetti, Antoine Caillon, Qingqing Huang, Aren Jansen, Adam Roberts, Marco Tagliasacchi, Matt Sharifi, Neil Zeghidour, and Christian Frank. MusicLM: Generating music from text. In International Conference on Machine Learning (ICML Workshop), 2023
2023
-
[5]
Plumbley
Haohe Liu, Zehua Chen, Yi Yuan, Xinhao Mei, Xubo Liu, Danilo Mandic, Wenwu Wang, and Mark D. Plumbley. Audioldm: Text-to-audio generation with latent diffusion models. In Inter- national Conference on Machine Learning (ICML), 2023
2023
-
[6]
Plumbley
Haohe Liu, Yi Yuan, Xubo Liu, Xinhao Mei, Qiuqiang Kong, Qiao Tian, Yuping Wang, Wenwu Wang, Yuxuan Wang, and Mark D. Plumbley. Audioldm 2: Learning holistic audio generation with self-supervised pretraining. IEEE/ACM Transactions on Audio, Speech and Language Pro- cessing, 2023
2023
-
[7]
Chia-Yu Hung, Navonil Majumder, Zhifeng Kong, Ambuj Mehrish, Amir Ali Bagherzadeh, Chuan Li, Rafael Valle, Bryan Catanzaro, and Soujanya Poria. Tangoflux: Super fast and faith- ful text to audio generation with flow matching and clap-ranked preference optimization. 2024. arXiv preprint arXiv:2412.21037
-
[8]
Uniflow-audio: Unified flow matching for audio generation from omni-modalities
Xuenan Xu, Jiahao Mei, Zihao Zheng, Ye Tao, Zeyu Xie, Yaoyun Zhang, Haohe Liu, Yuning Wu, Ming Yan, Wen Wu, Chao Zhang, and Mengyue Wu. Uniflow-audio: Unified flow matching for audio generation from omni-modalities. 2025. arXiv preprint arXiv:2509.24391
-
[9]
Weiss, Viet Dang, Ye Jia, Yonghui Wu, Yu Zhang, and Zhifeng Chen
Heiga Zen, Rob Clark, Ron J. Weiss, Viet Dang, Ye Jia, Yonghui Wu, Yu Zhang, and Zhifeng Chen. Libritts: A corpus derived from librispeech for text-to-speech. In Interspeech, 2019
2019
-
[10]
Audiocaps: Gener- ating captions for audios in the wild
Chris Dongjoo Kim, Byeongchang Kim, Hyunmin Lee, and Gunhee Kim. Audiocaps: Gener- ating captions for audios in the wild. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics (NAACL), 2019
2019
-
[11]
MECAT: A Multi-Experts Constructed Benchmark for Fine-Grained Audio Understanding Tasks
Yadong Niu, Tianzi Wang, Heinrich Dinkel, Xingwei Sun, Jiahao Zhou, Gang Li, Jizhong Liu, Xunying Liu, Junbo Zhang, and Jian Luan. Mecat: A multi-experts constructed benchmark for fine-grained audio understanding tasks. 2025. arXiv preprint arXiv:2507.23511
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Dashengtokenizer: One layer is enough for unified audio understanding and generation
Heinrich Dinkel, Xingwei Sun, Gang Li, Jiahao Mei, Yadong Niu, Jizhong Liu, Xiyang Li, Yifan Liao, Jiahao Zhou, Junbo Zhang, and Jian Luan. Dashengtokenizer: One layer is enough for unified audio understanding and generation. 2026. arXiv preprint arXiv:2602.23765
-
[13]
Weiss, Mike Schuster, Navdeep Jaitly, Zongheng Yang, Zhifeng Chen, Yu Zhang, Yuxuan Wang, Rj Skerrv-Ryan, Rif A
Jonathan Shen, Ruoming Pang, Ron J. Weiss, Mike Schuster, Navdeep Jaitly, Zongheng Yang, Zhifeng Chen, Yu Zhang, Yuxuan Wang, Rj Skerrv-Ryan, Rif A. Saurous, Yannis Agiomvrgian- nakis, and Yonghui Wu. Natural tts synthesis by conditioning wavenet on mel spectrogram pre- dictions. In IEEE International Conference on Acoustics, Speech and Signal Processing ...
2018
-
[14]
Conditional variational autoencoder with adversarial learning for end-to-end text-to-speech
Jaehyeon Kim, Jungil Kong, and Juhee Son. Conditional variational autoencoder with adversarial learning for end-to-end text-to-speech. In International Conference on Machine Learning (ICML), 2021
2021
-
[15]
Jen-1: Text-guided universal music generation with omnidirectional diffusion models
Peike Li, Boyu Chen, Yuying Li, and Yaolong Li. Jen-1: Text-guided universal music generation with omnidirectional diffusion models. arXiv preprint arXiv:2308.04729, 2023. 11
-
[16]
Make-an-audio: Text-to-audio generation with prompt- enhanced diffusion models
Rongjie Huang, Jiawei Huang, Dongchao Yang, Yi Ren, Luping Liu, Mingze Li, Zhenhui Ye, Jinglin Liu, Xiang Yin, and Zhou Zhao. Make-an-audio: Text-to-audio generation with prompt- enhanced diffusion models. In International Conference on Machine Learning (ICML), 2023
2023
-
[17]
AudioX: A Unified Framework for Anything-to-Audio Generation
Zeyue Tian, Yizhu Jin, Zhaoyang Liu, Ruibin Yuan, Xu Tan, Qifeng Chen, Wei Xue, and Yike Guo. Audiox: Diffusion transformer for anything-to-audio generation. arXiv preprint arXiv:2503.10522, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Uniaudio: An audio foundation model toward universal audio generation
Dongchao Yang, Jinchuan Tian, Xu Tan, Rongjie Huang, Songxiang Liu, Xuankai Chang, Ji- atong Shi, Sheng Zhao, Jiang Bian, Zhou Zhao, Xixin Wu, and Helen Meng. Uniaudio: An audio foundation model toward universal audio generation. In IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2024
2024
-
[19]
Bagpiper: Solving Open-Ended Audio Tasks via Rich Captions
Jinchuan Tian, Haoran Wang, Bo-Hao Su, Chien-yu Huang, Qingzheng Wang, Jiatong Shi, William Chen, Xun Gong, Siddhant Arora, Chin-Jou Li, et al. Bagpiper: Solving open-ended audio tasks via rich captions. arXiv preprint arXiv:2602.05220, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[20]
Scaling instruction-finetuned language models
Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Yunxuan Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, et al. Scaling instruction-finetuned language models. Journal of Machine Learning Research, 25(70):1–53, 2024
2024
-
[21]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Matthew Nickel, and Matthew Le. Flow matching for generative modeling. In International Conference on Learning Representations (ICLR), 2024
2024
-
[22]
Acavcaps: Enabling large-scale training for fine-grained and diverse audio understanding
Yadong Niu, Tianzi Wang, Heinrich Dinkel, Xingwei Sun, Jiahao Zhou, Gang Li, Jizhong Liu, Junbo Zhang, and Jian Luan. Acavcaps: Enabling large-scale training for fine-grained and diverse audio understanding. In ICASSP 2026-2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 15347–15351. IEEE, 2026
2026
-
[23]
Acav100m: Automatic curation of large-scale datasets for audio-visual video represen- tation learning
Sangho Lee, Jiwan Chung, Youngjae Yu, Gunhee Kim, Thomas Breuel, Gal Chechik, and Yale Song. Acav100m: Automatic curation of large-scale datasets for audio-visual video represen- tation learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision , pages 10274–10284, 2021
2021
-
[24]
CLAP: Learn- ing audio concepts from natural language supervision
Benjamin Elizalde, Soham Deshmukh, Mahmoud Al Ismail, and Huaming Wang. CLAP: Learn- ing audio concepts from natural language supervision. InIEEE International Conference on Acous- tics, Speech and Signal Processing (ICASSP), 2023
2023
-
[25]
Glap: General contrastive audio-text pre- training across domains and languages
Heinrich Dinkel, Zhiyong Yan, Tianzi Wang, Yongqing Wang, Xingwei Sun, Yadong Niu, Jizhong Liu, Gang Li, Junbo Zhang, and Jian Luan. Glap: General contrastive audio-text pre- training across domains and languages. arXiv preprint arXiv:2506.11350, 2025
-
[26]
The t05 system for the VoiceMOS Challenge 2024: Transfer learning from deep image classifier to naturalness MOS prediction of high-quality synthetic speech
Kaito Baba, Wataru Nakata, Yuki Saito, and Hiroshi Saruwatari. The t05 system for the VoiceMOS Challenge 2024: Transfer learning from deep image classifier to naturalness MOS prediction of high-quality synthetic speech. In IEEE Spoken Language Technology Workshop (SLT), pages 818–824, 2024
2024
-
[27]
Wavcaps: A chatgpt-assisted weakly-labelled audio captioning dataset for audio-language multimodal research
Xinhao Mei, Chutong Meng, Haohe Liu, Qiuqiang Kong, Tom Ko, Chengqi Zhao, Mark D Plumbley, Yuexian Zou, and Wenwu Wang. Wavcaps: A chatgpt-assisted weakly-labelled audio captioning dataset for audio-language multimodal research. IEEE/ACM Transactions on Audio, Speech, and Language Processing , 32:3339–3354, 2024
2024
-
[28]
Lp-musiccaps: Llm-based pseudo music captioning
SeungHeon Doh, Keunwoo Choi, Jongpil Lee, and Juhan Nam. Lp-musiccaps: Llm-based pseudo music captioning. arXiv preprint arXiv:2307.16372, 2023
-
[29]
Diffusion Transformers with Representation Autoencoders
Boyang Zheng, Nanye Ma, Shengbang Tong, and Saining Xie. Diffusion transformers with rep- resentation autoencoders. arXiv preprint arXiv:2510.11690, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Robust speech recognition via large-scale weak supervision
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. Robust speech recognition via large-scale weak supervision. International Confer- ence on Machine Learning , 2023. 12
2023
-
[31]
Shawn Hershey, Sourish Chaudhuri, Daniel P. W. Ellis, Jort F. Gemmeke, Aren Jansen, Chan- ning Moore, Manoj Plakal, Devin Platt, Rif A. Saurous, Bryan Seybold, Malcolm Slaney, Ron Weiss, and Kevin Wilson. Cnn architectures for large-scale audio classification. In International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2017
2017
-
[32]
original → used
Qiuqiang Kong, Yin Cao, Turab Iqbal, Yuxuan Wang, Wenwu Wang, and Mark D Plumbley. Panns: Large-scale pretrained audio neural networks for audio pattern recognition. IEEE/ACM Transactions on Audio, Speech, and Language Processing , 28:2880–2894, 2020. 13 A MECAT Single-Type Results Table A1: Results on MECAT single-type categories. Best values are in bold...
2020
-
[33]
The audio contains severe noise, clipping, or strong AI-generated artifacts and feels completely unrealistic
Very poor. The audio contains severe noise, clipping, or strong AI-generated artifacts and feels completely unrealistic. If multiple sounds are mixed, the result is extremely chaotic, heavily conflicting, and unbearable to hear
-
[34]
Individual sounds have obvious artifacts, distortion, or unnaturalness and clearly sound generated
Poor. Individual sounds have obvious artifacts, distortion, or unnaturalness and clearly sound generated. If multiple sounds are mixed, they feel crudely stitched together, interfere with each other, or are severely imbalanced in volume, making the result uncomfortable to hear
-
[35]
Individual sounds are basically clear, with occasional minor noise or AI artifacts, and only moderate realism
Average. Individual sounds are basically clear, with occasional minor noise or AI artifacts, and only moderate realism. If multiple sounds are mixed, the parts are distinguishable and do not severely clash, but the layering is weak and the result feels ordinary
-
[36]
Individual sounds are clear and natural, and the listening experience is close to a real acoustic envi- ronment
Good. Individual sounds are clear and natural, and the listening experience is close to a real acoustic envi- ronment. If multiple sounds are mixed, they are blended fairly well, with a clear sense of foreground and background, resulting in a comfortable and harmonious sound
-
[37]
The audio quality is outstanding, with almost no AI artifacts and a highly realistic sound
Excellent. The audio quality is outstanding, with almost no AI artifacts and a highly realistic sound. If multiple sounds are mixed, all elements are integrated beautifully with rich layering, comparable to real-world field recordings or professional film and TV sound production, and highly immersive. Rating Criteria for REL Please evaluate how well the g...
-
[38]
The generated audio has nothing to do with the input text, and all required elements are wrong or missing
Completely irrelevant. The generated audio has nothing to do with the input text, and all required elements are wrong or missing
-
[39]
Most key descriptions are missing
Low relevance. Most key descriptions are missing. For example, the dialogue may be completely incorrect, or the specified sound effects or music style may be absent
-
[40]
The audio matches the main intent of the text and includes the major sound elements, but some specific audio elements are still missing
Basically relevant. The audio matches the main intent of the text and includes the major sound elements, but some specific audio elements are still missing
-
[41]
Most of the text description is reproduced accurately
Highly relevant. Most of the text description is reproduced accurately. The speech, sound effects, music, and recording environment are basically correct, with only minor deviations in detail
-
[42]
All detailed requirements of the text are reproduced accurately
Perfect match. All detailed requirements of the text are reproduced accurately. The elements are complete, the pronunciation is correct, and the audio fully matches the atmosphere and emotion described in the text. 20 E.3 Human Evaluation Interface Figure A2: Human evaluation interface screenshot. Annotators rated Overall Quality (OVL) and Text Relevance ...
-
[43]
Consider whether early reflections, distance cues, HRTF pat- terns, and high-frequency attenuation match the implied space
Spatial Consistency: Determine whether all sound sources are situated within a uni- fied acoustic soundfield. Consider whether early reflections, distance cues, HRTF pat- terns, and high-frequency attenuation match the implied space
-
[44]
Strong mismatch in dryness or RT60 across sources should be treated as evidence of splicing or artificial composition
Reverberation Coherence: Determine whether the primary subject and background sounds share a consistent reverb profile. Strong mismatch in dryness or RT60 across sources should be treated as evidence of splicing or artificial composition
-
[45]
Consider masking effects, depth ordering, and whether overlaps sound phys- ically plausible rather than phase-conflicting
Dynamic Layering & Masking : Determine whether simultaneous sources interact naturally. Consider masking effects, depth ordering, and whether overlaps sound phys- ically plausible rather than phase-conflicting
-
[46]
Environmental Immersion: Determine whether the audio contains a credible noise floor and a coherent sense of place, including room tone, low-frequency disturbances, reflections, and diffusion
-
[47]
score": <int>,
Physical & Kinematic Logic : Determine whether source motion obeys acoustic physics, including Doppler shift and inverse-square SPL changes. Scoring Rubric (0–5) • 0: Severe violation. Obvious phase cancellations, fractured spectra, mismatched re- verberation, or clearly broken splicing / AI artifacts. • 1: Barely acceptable. The scene is recognizable, bu...
-
[48]
The ASR field must also be entirely in English
Absolute English-Only Output: ALL fields in the output JSON MUST be generated in English, regardless of the language of the user’s input. The ASR field must also be entirely in English. Do NOT output any other languages
-
[49]
If generat- ing ASR, keep the dialogue concise and realistic for a 10-second window (usually 1-2 short sentences)
10-Second Constraint: The entire audio scene is exactly 10 seconds long. If generat- ing ASR, keep the dialogue concise and realistic for a 10-second window (usually 1-2 short sentences)
-
[50]
Never include names, character tags, or action descriptions within the ASR string
Strict ASR Formatting : The ASR field must ONLY contain the raw spoken text. Never include names, character tags, or action descriptions within the ASR string. (Correct: ”Watch out for that car!” | Incorrect: ”Man: Watch out for that car!”). If there are multiple speakers, just combine their dialogue naturally without labels
-
[51]
If the user says ”at a train station,” automatically add train horn (SFX) and crowd murmurs (ENV)
Scene Enrichment: Act as a sound designer and logically enrich the scene. If the user says ”at a train station,” automatically add train horn (SFX) and crowd murmurs (ENV). 25
-
[52]
Logical Nulls: Except for Caption (mandatory), if a field is not mentioned by the user AND makes no logical sense in the scene, set its value to null
-
[53]
Caption":
Strict Output : Output ONLY valid JSON. Do not include markdown blocks like ```json or any explanatory text. Examples User Input: ”A man complaining about the weather on a rainy street.” Output: { "Caption": "A man complaining about the rainy weather on a wet city street .", "Speech": "A frustrated middle-aged male voice speaking loudly.", "ASR": "Damn it...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.