MERIT: Matching Expertise via Rubric-Informed Training for Reviewer Assignment
Pith reviewed 2026-06-29 13:32 UTC · model grok-4.3
The pith
Rubric-guided RL trains a 4B assessor that beats larger LLMs and distills into a top retriever for reviewer matching.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
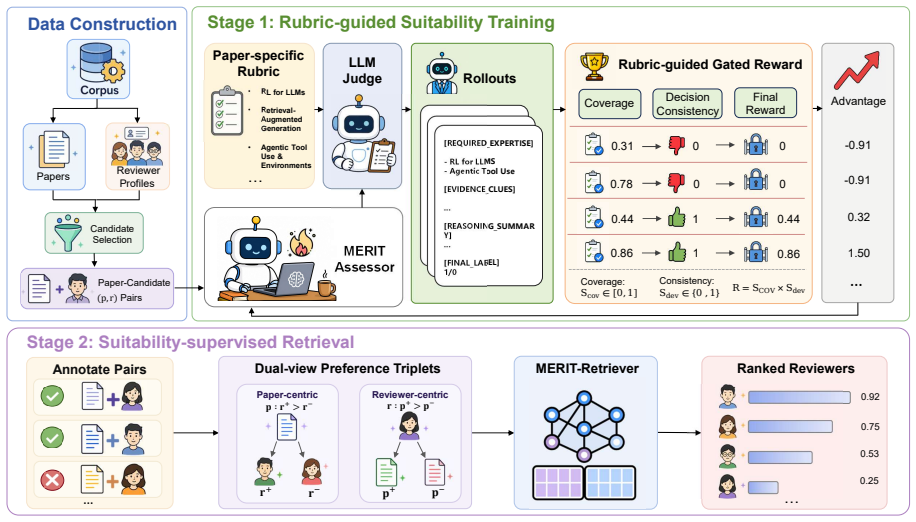
MERIT converts criterion-level expertise matching into scalable suitability supervision by training a reviewer assessor via reinforcement learning to identify the expertise dimensions a paper requires, match them against the reviewer's prior work, and produce a suitability decision, with rewards provided by an LLM judge guided by paper-specific expertise rubrics; the assessor's predictions are then distilled into an embedding-based retriever for efficient large-scale assignment.
What carries the argument
Reinforcement learning trained reviewer assessor that identifies required expertise dimensions and matches them to reviewer prior work using rewards from an LLM judge guided by paper-specific expertise rubrics, followed by distillation into an embedding-based retriever.
If this is right
- The 4B reviewer assessor outperforms larger general-purpose LLMs on suitability classification.
- The resulting retriever achieves state-of-the-art performance across LR-Bench and the CMU Gold dataset.
- The framework produces precise suitability signals without requiring expensive human annotations.
- It improves on methods that rely only on coarse proxy signals such as general relatedness.
Where Pith is reading between the lines
- The rubric-based reward method could extend to other expertise-matching tasks such as grant proposal review.
- If the LLM judge remains consistent, the approach could lower the cost of building reviewer systems for new venues.
- Applying the retriever in a live conference and tracking subsequent review quality metrics would test downstream effects.
Load-bearing premise
The LLM judge, when guided by paper-specific expertise rubrics, produces reliable and unbiased reward signals that correctly reflect true reviewer suitability.
What would settle it
Human experts rate reviewer suitability for a held-out set of paper-reviewer pairs and the correlation between those ratings and the assessor's decisions or the retriever rankings is measured.
Figures






read the original abstract
Matching submissions with suitable reviewers at scale is a growing challenge for major venues, yet existing approaches either rely on coarse proxy signals that conflate general relatedness with true suitability, or require expensive human annotations that are difficult to scale for training. We propose MERIT, a two-stage framework that bridges this gap by converting criterion-level expertise matching into scalable suitability supervision. In the first stage, we train a reviewer assessor via reinforcement learning to identify the expertise dimensions a paper requires, match them against the reviewer's prior work, and produce a suitability decision, with rewards provided by an LLM judge guided by paper-specific expertise rubrics. In the second stage, we distill the assessor's predictions into an embedding-based retriever for efficient large-scale assignment. Experiments show that our 4B reviewer assessor outperforms larger general-purpose LLMs on suitability classification, and the resulting retriever achieves state-of-the-art performance across LR-Bench and the CMU Gold dataset. Our code is available at https://github.com/Luli3220/MERIT.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents MERIT, a two-stage framework for reviewer assignment. Stage 1 trains a 4B reviewer assessor via reinforcement learning, using rewards from an LLM judge guided by paper-specific expertise rubrics to identify required expertise dimensions, match against reviewer history, and output suitability decisions. Stage 2 distills the assessor's outputs into an embedding-based retriever for scalable assignment. The paper claims the 4B assessor outperforms larger general-purpose LLMs on suitability classification and that the retriever achieves state-of-the-art results on LR-Bench and the CMU Gold dataset. Code is released at the provided GitHub link.
Significance. If the central results hold, the work offers a scalable alternative to coarse proxies or expensive human annotations for generating suitability supervision, potentially improving automated reviewer matching at large venues. The release of code is a clear strength that supports reproducibility.
major comments (2)
- [Abstract / first-stage description] The central claim that the 4B assessor produces accurate suitability classifications (and thereby supports the SOTA retriever) depends on the LLM judge providing faithful, unbiased rewards via paper-specific rubrics. No human-expert agreement, correlation with manual annotations, or judge-quality ablation is reported, leaving open the possibility that training encodes LLM-specific artifacts rather than true expertise matching (abstract, first-stage description).
- [Abstract] Abstract states performance claims (outperformance over larger LLMs; SOTA on LR-Bench and CMU Gold) but supplies no experimental details, baselines, metrics, statistical tests, or ablation results, making it impossible to assess whether the data support the claims.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We address each major comment point by point below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract / first-stage description] The central claim that the 4B assessor produces accurate suitability classifications (and thereby supports the SOTA retriever) depends on the LLM judge providing faithful, unbiased rewards via paper-specific rubrics. No human-expert agreement, correlation with manual annotations, or judge-quality ablation is reported, leaving open the possibility that training encodes LLM-specific artifacts rather than true expertise matching (abstract, first-stage description).
Authors: We agree that explicit validation of the LLM judge against human experts would provide stronger support for the reward signals. The outperformance of the 4B assessor over larger general-purpose LLMs offers indirect evidence that the rubric-guided training captures expertise signals rather than artifacts alone, and the downstream SOTA results on LR-Bench and CMU Gold further corroborate this. Nevertheless, we will add a dedicated limitations discussion on potential LLM judge biases and include a small-scale judge-quality ablation correlating LLM rewards with human annotations in the revised manuscript. revision: partial
-
Referee: [Abstract] Abstract states performance claims (outperformance over larger LLMs; SOTA on LR-Bench and CMU Gold) but supplies no experimental details, baselines, metrics, statistical tests, or ablation results, making it impossible to assess whether the data support the claims.
Authors: We will revise the abstract to concisely incorporate key experimental details, including the primary metrics (suitability classification accuracy and retrieval metrics such as NDCG), main baselines, and note that improvements are statistically significant. revision: yes
Circularity Check
No significant circularity; external LLM judge and public benchmarks keep claims independent
full rationale
The paper presents an empirical two-stage ML pipeline (RL training of 4B assessor with external LLM-judge rewards, followed by distillation to embedding retriever) evaluated on public benchmarks LR-Bench and CMU Gold. No equations, fitted parameters renamed as predictions, or self-citations appear in the provided text. The LLM judge is treated as an external oracle rather than derived from the model itself, and no derivation chain reduces outputs to inputs by construction. This is the normal non-circular case for a methods paper relying on external supervision and held-out test sets.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption An LLM judge guided by paper-specific expertise rubrics can provide reliable rewards for training a reviewer suitability assessor
Reference graph
Works this paper leans on
-
[1]
InProceedings of the Third ACM Conference on Recommender Systems, RecSys ’09, page 357–360, New York, NY , USA
Recommender systems for the conference paper assignment problem. InProceedings of the Third ACM Conference on Recommender Systems, RecSys ’09, page 357–360, New York, NY , USA. Association for Computing Machinery. DeepSeek-AI. 2025. Deepseek-v3.2: Pushing the fron- tier of open large language models. Susan T. Dumais and Jakob Nielsen. 1992. Automating the...
2025
-
[2]
InNeurIPS 2025 Work- shop on Efficient Reasoning
Rubrics as rewards: Reinforcement learning beyond verifiable domains. InNeurIPS 2025 Work- shop on Efficient Reasoning. Sunanda Gupta and Aruddha Sarkar. 2025. Peer review of scientific studies: Problems and potential solutions. Cureus, 17. Yun He, Wenzhe Li, Hejia Zhang, Songlin Li, Karishma Mandyam, Sopan Khosla, Yuanhao Xiong, Nanshu Wang, Selina Peng,...
-
[3]
InCham- pioning Open-source DEvelopment in ML Workshop @ ICML25
Vulnerability of text-matching in ML/AI con- ference reviewer assignments to collusions. InCham- pioning Open-source DEvelopment in ML Workshop @ ICML25. Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2022. LoRA: Low-rank adaptation of large language models. InInternational Conference on Learn...
2022
-
[4]
Prometheus: Inducing fine-grained evaluation capability in language models. InInternational Con- ference on Learning Representations, volume 2024, pages 29927–29962. Yizhi Li, Zhenghao Liu, Chenyan Xiong, and Zhiyuan Liu. 2021. More robust dense retrieval with con- trastive dual learning. InProceedings of the 2021 ACM SIGIR International Conference on The...
-
[5]
Rate: Reviewer profiling and annotation-free training for expertise ranking in peer review systems. Preprint, arXiv:2601.19637. Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. 2023. G-eval: NLG evaluation using gpt-4 with better human align- ment. InProceedings of the 2023 Conference on Empirical Methods in Natural Language P...
-
[7]
(CORE)" and enabling technologies as
Candidate Author Profile (List of historical publications) Decision Logic: - Label 1 (Qualified): The candidate possesses **at least ONE of the CORE (Primary)** expertise requirements **AND** at least one additional relevant skill (Secondary or another Core). They have sufficient domain knowledge to evaluate the paper 's key contributions. - Label 0 (Unqu...
-
[8]
Adversarial Patch Attacks on Vision Transformers (CORE)
-
[9]
Quantization-Aware Training (Secondary)
-
[10]
DeepPatch: Attacking ViTs
Image Classification Benchmarks (Secondary)> [EVIDENCE_CLUES] <List specific paper titles and a brief tag indicating which requirement they support. Example: - "DeepPatch: Attacking ViTs": Supports CORE (Adversarial Patch Attacks). - "Q-ViT: Robust Quantization": Supports Secondary (Quantization). If no relevant papers are found, write'None'.> [REASONING_...
-
[11]
Whether the candidate covers the (CORE) expertise
-
[12]
Which (additional) expertise supports the CORE match
-
[13]
Core + 1 additional
Conclusion based on the "Core + 1 additional" rule.> [FINAL_LABEL] <0 or 1> ------------------------------------------------------------ ### User Prompt [[Target Paper]] Title: {{paper_title}} Content: {{paper_abstract}} {{paper_introduction}} [[Candidate Author Profile]] (Recent Publications) {{candidate_history_list}} Based on the strict standard (1=Exp...
-
[14]
Target Paper Context
-
[15]
Candidate's Verified Publications
-
[16]
Output Structure: Output **ONLY** the strict JSON object
The Report to be audited. Output Structure: Output **ONLY** the strict JSON object. JSON Schema:
-
[17]
rubric_breakdown
"rubric_breakdown": { "Rubric Title": boolean } - true: The Report **actively addresses and discusses** this requirement. * It goes beyond merely listing the string; it evaluates whether the candidate possesses or lacks this specific expertise (e.g., linking it to a specific paper or explicitly stating it is missing in the reasoning). - false: The require...
-
[18]
logical": Boolean. - true: The decision is **sound, fair, and strongly supported** by the
"logical": Boolean. - true: The decision is **sound, fair, and strongly supported** by the "1 Core + 1 additional requirement" threshold rule. * If Label 1: The Report accurately identifies at least ONE Core and ONE additional requirement, supported by valid cited papers. * If Label 0: The Report correctly proves the candidate lacks Core expertise or lack...
-
[19]
**Check for Keyword Stuffing:** Mark rubric items as false if they are just listed in the requirements section but never actually evaluated against the candidate's history in the reasoning/evidence
-
[20]
Penalize over-claiming ( unjustified 1s) AND overly strict rejections (unjustified 0s when the candidate meets the 1 Core + 1 additional requirement threshold)
**Check for Logical Consistency:** Ensure the final label accurately reflects the evidence. Penalize over-claiming ( unjustified 1s) AND overly strict rejections (unjustified 0s when the candidate meets the 1 Core + 1 additional requirement threshold). Generate the strict JSON output:
-
[21]
rubric_breakdown
"rubric_breakdown": { "Rubric Title": boolean }
-
[22]
Figure 7: Prompt template for the direct prompting baseline in reviewer suitability classification
"logical": boolean. Figure 7: Prompt template for the direct prompting baseline in reviewer suitability classification. ### System Prompt You are an expert Conference Area Chair. Determine whether a Candidate Reviewer is qualified to review a Target Paper. Input:
-
[23]
Target Paper (Title, Abstract, Introduction)
-
[24]
- Label 0: The candidate lacks the expertise needed to provide a competent review
Candidate Author Profile (historical publications) Decision Rule: - Label 1: The candidate has sufficient expertise to review the target paper. - Label 0: The candidate lacks the expertise needed to provide a competent review. Output Format: [FINAL_LABEL] <0 or 1> ------------------------------------------------------------ ### User Prompt [[Target Paper]...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.