SuiChat-CN: Benchmarking Contextual Suicide Risk Assessment in Chinese Group Chats
Pith reviewed 2026-06-29 12:57 UTC · model grok-4.3
The pith
Contextual information from group chats is essential for reliable suicide risk assessment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
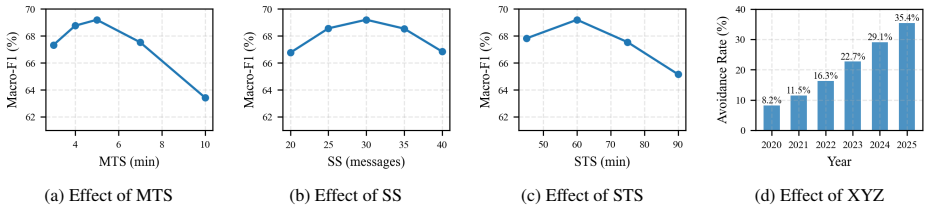
The SuiChat-CN benchmark contains 13,312 contextual segments from 1,406 users covering 258,228 raw messages. Experiments with PLMs and more than 40 LLMs establish that contextual information is essential for reliable risk assessment, while fine-tuning and partial-context evaluation further reveal the challenges of early detection in multi-party conversations.
What carries the argument
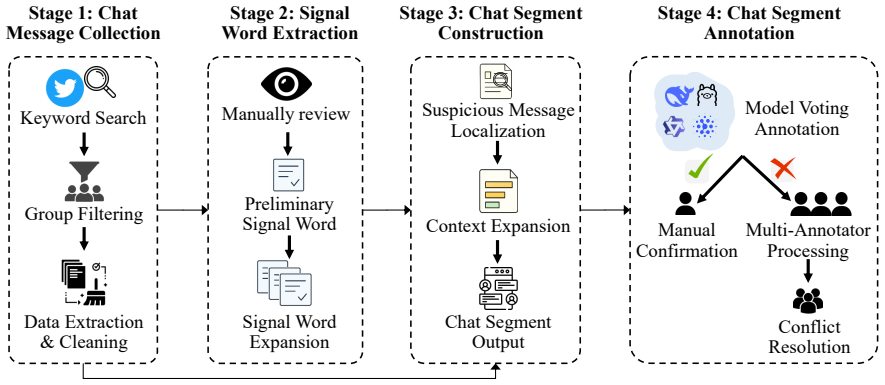
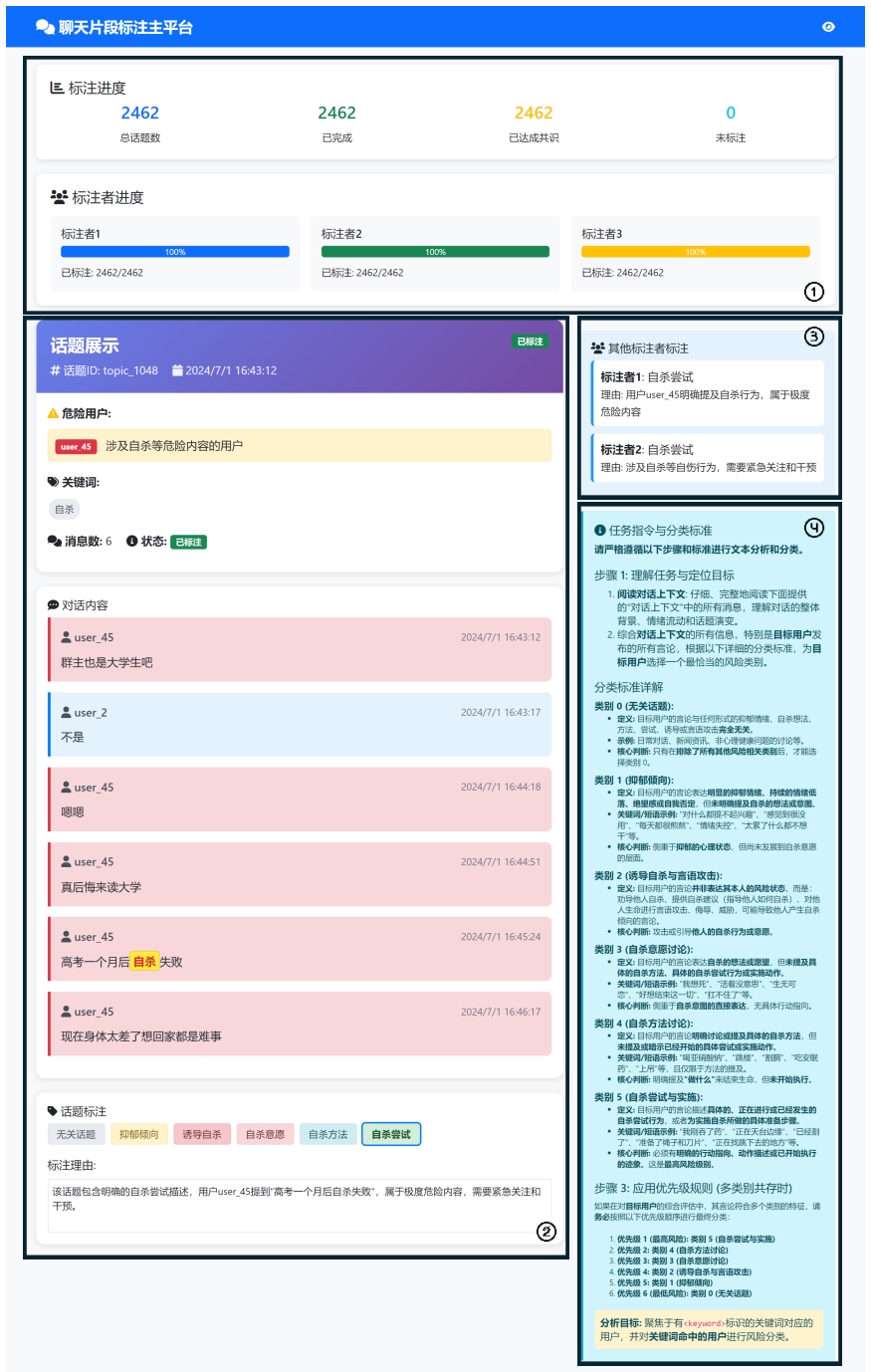
The SuiChat-CN benchmark of contextual conversational segments, built through signal-word extraction and bidirectional context expansion followed by expert-validated LLM-assisted annotation of user risk levels.
If this is right
- Contextual models outperform isolated-post approaches on risk assessment tasks.
- Fine-tuning on the benchmark data yields measurable gains in model performance.
- Partial context leaves early detection unreliable in multi-party group settings.
- Instant-messaging platforms need context-aware methods distinct from post-based social media analysis.
Where Pith is reading between the lines
- The segment-construction and annotation method could transfer to suicide-risk tasks in other languages or messaging apps.
- Privacy-preserving versions of the pipeline might support real-time monitoring tools if ethical safeguards are added.
- Future training corpora for detection models should emphasize full conversational threads over standalone messages.
Load-bearing premise
The expert-validated, LLM-assisted annotation accurately identifies true user suicide risk levels from the constructed segments.
What would settle it
A head-to-head test in which non-contextual models match or exceed the accuracy of contextual models on the same SuiChat-CN segments would falsify the necessity of context.
Figures















read the original abstract
Suicide is a critical global public health challenge, causing approximately 720,000 deaths each year and calling for timely, effective prevention strategies. Existing computational studies primarily focus on post-based social media platforms such as Twitter and Weibo, leaving instant messaging environments such as Telegram underexplored. Yet group chats pose distinct challenges: messages are short, fragmented, multi-party, and often rely on implicit or culturally specific expressions, making isolated post-level analysis insufficient. We introduce SuiChat-CN, a Chinese group-chat benchmark for contextual suicide risk assessment. We collect public Telegram group-chat data, construct coherent conversational segments through signal-word extraction and bidirectional context expansion, and annotate user risk levels with an expert-validated, LLM-assisted paradigm. SuiChat-CN contains 13,312 contextual segments from 1,406 users, covering 258,228 raw chat messages. Extensive experiments with PLMs and more than 40 LLMs demonstrate that contextual information is essential for reliable risk assessment, while fine-tuning and partial-context evaluation further reveal the challenges of early detection in multi-party conversations. Due to ethical and sensitivity concerns, the dataset is not publicly released but will be shared with accredited mental health and suicide-prevention research institutions upon reasonable request.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SuiChat-CN, a benchmark of 13,312 contextual segments drawn from 1,406 users and 258,228 raw Chinese Telegram group-chat messages. Segments are built by signal-word extraction followed by bidirectional context expansion; user risk levels are assigned via an expert-validated, LLM-assisted annotation pipeline. Experiments with PLMs and more than 40 LLMs are used to argue that full conversational context is essential for reliable suicide-risk assessment and that early detection in multi-party settings remains difficult.
Significance. If the segment-level risk labels prove reliable, the work supplies the first large-scale benchmark focused on implicit, multi-party, culturally specific expressions in instant-messaging environments rather than isolated social-media posts. The scale of the LLM evaluation and the emphasis on partial-context and fine-tuning ablations could usefully inform model development for early-intervention systems, while the decision to release the data only to accredited institutions is ethically appropriate.
major comments (2)
- [Abstract / Annotation] Abstract (and the Data Construction / Annotation sections): the central claim that 'contextual information is essential' rests entirely on the correctness of the 13,312 risk labels. The manuscript supplies no inter-annotator agreement statistic, no size or sampling method for the expert-reviewed subset, and no comparison against an independent gold-standard annotation. Without these quantities it is impossible to determine whether LLM-assisted labeling systematically misclassifies culturally implicit expressions, rendering all full-context vs. partial-context accuracy differences uninterpretable.
- [Experiments] Experiments section: performance differences between full-context and partial-context models are reported without error bars, statistical significance tests, or an ablation that isolates the effect of potential label noise. Because label quality is unquantified, these differences cannot be confidently attributed to the value of context rather than annotation artifacts.
minor comments (2)
- [Abstract] The abstract states the dataset 'will be shared with accredited mental health and suicide-prevention research institutions upon reasonable request' but provides no concrete access protocol or review criteria; this should be clarified for reproducibility.
- [Experiments] Table or figure captions that report model counts ('more than 40 LLMs') should list the exact models and versions evaluated.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [Abstract / Annotation] Abstract (and the Data Construction / Annotation sections): the central claim that 'contextual information is essential' rests entirely on the correctness of the 13,312 risk labels. The manuscript supplies no inter-annotator agreement statistic, no size or sampling method for the expert-reviewed subset, and no comparison against an independent gold-standard annotation. Without these quantities it is impossible to determine whether LLM-assisted labeling systematically misclassifies culturally implicit expressions, rendering all full-context vs. partial-context accuracy differences uninterpretable.
Authors: We agree that the absence of reported inter-annotator agreement (IAA), expert-review subset size, sampling details, and gold-standard comparison limits the interpretability of the results. Although the manuscript describes an expert-validated, LLM-assisted pipeline, these quantitative validation metrics were not included. In the revised manuscript we will add: (1) the IAA statistic computed on the expert-reviewed portion, (2) the exact size and sampling procedure of that subset, and (3) any available comparison against an independent gold-standard annotation. These additions will allow readers to assess label reliability directly. revision: yes
-
Referee: [Experiments] Experiments section: performance differences between full-context and partial-context models are reported without error bars, statistical significance tests, or an ablation that isolates the effect of potential label noise. Because label quality is unquantified, these differences cannot be confidently attributed to the value of context rather than annotation artifacts.
Authors: We concur that error bars, statistical significance testing, and an explicit analysis of label-noise effects are necessary to attribute performance gains to context rather than annotation artifacts. The current version reports point estimates only. In the revision we will: (1) recompute all reported metrics with error bars (via bootstrapping or multiple random seeds), (2) add paired statistical significance tests between full-context and partial-context conditions, and (3) include a sensitivity ablation that perturbs a controlled fraction of labels to quantify robustness to noise. These changes will strengthen the experimental claims. revision: yes
Circularity Check
No circularity: benchmark rests on independent data collection and external model evaluations
full rationale
The paper constructs SuiChat-CN via Telegram data collection, signal-word segment extraction with bidirectional expansion, and an expert-validated LLM-assisted annotation process yielding 13,312 segments. It then runs independent experiments comparing PLMs and >40 LLMs under full vs. partial context to measure the value of context and early-detection difficulty. No equations, fitted parameters renamed as predictions, self-citation chains, or ansatzes appear; the central claims derive directly from the new dataset and off-the-shelf model runs rather than reducing to the inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Textual content in group chats can be used to assess suicide risk levels
Reference graph
Works this paper leans on
-
[1]
InProceedings of the 26th ACM Conference on Hypertext and Social Media, pages 75–84
Machine classification and analysis of suicide- related communication on twitter. InProceedings of the 26th ACM Conference on Hypertext and Social Media, pages 75–84. ACM. SP Devika, MR Pooja, MS Arpitha, and Ravi Vinayaku- mar. 2023. Bert-based approach for suicide and de- pression identification. InProceedings of 3rd Inter- national Conference on Advanc...
-
[2]
Kelly Posner, Gregory Brown, Barbara Stanley, Kseniya Yershova, Maria Oquendo, Glenn Currier, Glenn Melvin, Laurence Greenhill, Sa Shen, and J
Detecting suicidality on twitter.Internet Inter- ventions, 2(2):183–188. Kelly Posner, Gregory Brown, Barbara Stanley, Kseniya Yershova, Maria Oquendo, Glenn Currier, Glenn Melvin, Laurence Greenhill, Sa Shen, and J. Mann
-
[3]
The American journal of psychiatry, 168:1266–77
The columbia-suicide severity rating scale: Initial validity and internal consistency findings from three multisite studies with adolescents and adults. The American journal of psychiatry, 168:1266–77. Hongzhi Qi, Guanghui Fu, Jianqiang Li, Changwei Song, Wei Zhai, Dan Luo, Shuo Liu, Yijing Yu, Bingxiang Yang, and Qing Zhao. 2025. Supervised learning and ...
2025
-
[4]
Ramit Sawhney, Harshit Joshi, Saumya Gandhi, and Rajiv Ratn Shah
Depressionemo: A novel dataset for multil- abel classification of depression emotions.Journal of Affective Disorders, 366:445–458. Ramit Sawhney, Harshit Joshi, Saumya Gandhi, and Rajiv Ratn Shah. 2020. A time-aware transformer based model for suicide ideation detection on social media. InProceedings of the 25th Conference on Empirical Methods in Natural ...
2020
-
[5]
ൻԛğJSONൔჭቆb (Reasoning Steps:)
-
[6]
Analyze the conversation semantics: Determine whether it expresses suicidal or depressive emotions, focusing on both explicit and implicit expressions
-
[7]
Identify signal words: Extract explicit or implicit signal words related to suicide or depression and analyze their meanings
-
[8]
Determine the true intention: Identify the actual object or concept referenced by the explicit or implicit expressions
-
[9]
Infer the underlying motive: Describe the semantic connection between the true intention and the original suicide or depression- related signal words using a clear and concise explanation
-
[10]
the more I chat the more I want todie
Output: Return a single triplet in JSON format. ഒဢЧൕ২ğ •છđൻԛğ<ൔ > •तđൻԛğ<đሱ೪ၩ > •མႵದյඵীđൻԛğ<ൔđյඵđሱ೪ၩ > •Ϥс siđൻԛğ<đsiіղሱ೪ > •ದđൻԛğ<іղሱ೪ > (Few-shot Examples:) • Input: Who has potent potassium cyanide for sale, Output: <Suicide method, cyanide, Suicide means> • Input: What does jump into magma feel like, Output: <Suicide method, jump into magma, Suici...
1977
-
[11]
Read the Chat Context: Carefully and thoroughly read all messages in the chat context provided below to understand the background, emotional changes, and topic development
-
[12]
UserID: Message Content
Locate the Target User: In the conversation, find the target message that contains the <Signal Word> tag and identify the user who posted this message as the target user. ҄ᇧ 1໊ 1.ഈ༯໓ğᅚb 2.ğႵ <Signal Word>b Step 2: Risk Category Assessment Compare the target user’s statements with the following risk categories and select the most appropriate risk category ...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.