Rethinking Video-Language Model from the Language Input Perspective
Pith reviewed 2026-06-29 13:22 UTC · model grok-4.3
The pith
Varying text templates and reasoning over them improves video-language model performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
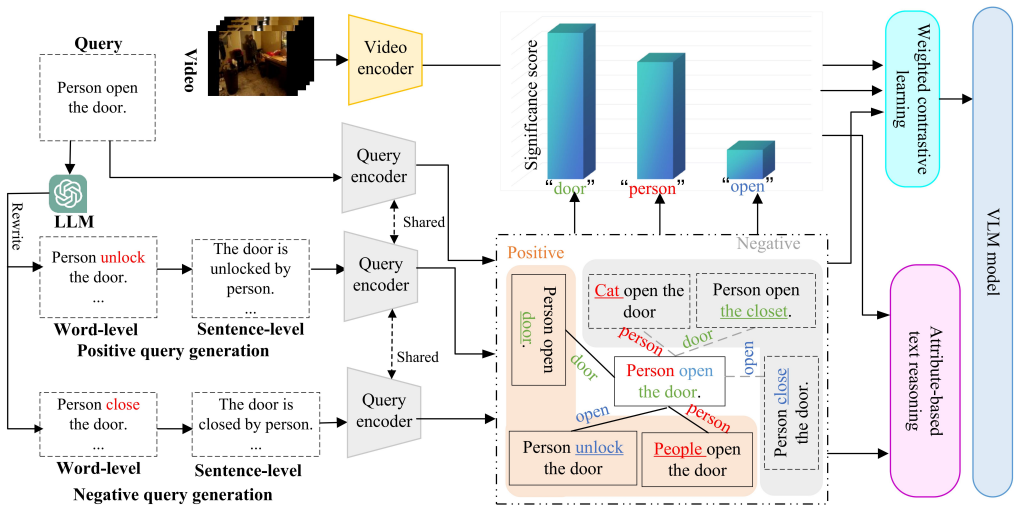
By generating positive and negative texts from original inputs and employing attribute-based text reasoning guided by videos through a self-weighted loss, the method bridges videos and texts more effectively than relying on predefined templates.
What carries the argument
The plug-and-play framework consisting of positive/negative text generation, attribute-based text reasoning, and self-weighted cross-modal loss.
If this is right
- Existing VLMs can be improved by adding this module without retraining from scratch.
- VLMs become less dependent on specific text templates, allowing more flexible inputs.
- Performance gains come from targeting specific text components through generated variants.
- The approach applies to various VLM-based methods as a general enhancer.
Where Pith is reading between the lines
- Similar strategies could apply to other multimodal models like image-text or audio-text systems.
- If the method reduces sensitivity to prompt phrasing, it might lower the need for prompt engineering in video tasks.
- Testing on diverse real-world user texts would validate broader applicability beyond the paper's experiments.
Load-bearing premise
That texts with similar semantics but different templates lead to various performances and that the generation of positive and negative texts with attribute reasoning reliably improves bridging without new biases.
What would settle it
An experiment showing that the performance improvements disappear when the generated texts are replaced with random variations or when the attribute reasoning is removed.
Figures



read the original abstract
Driven by the wave of large language models, Video-Language Models (VLMs) have become a significant yet challenging technology to bridge the gap between videos and texts. Although previous VLM works have made significant progress, almost all of them implicitly assume that all the texts are predefined by the specific template. In real-world applications, such a strict assumption is impossible to satisfy since 1) predefining all the texts is extremely time-consuming and labor-intensive. 2) these predefined text inputs are too restrictive and user-unfriendly, limiting their applications. It is observed that given a video input, texts with similar semantics but different templates lead to various performances. To this end, in this paper, we propose a novel plug-and-play framework for various VLM-based methods to fully bridge videos and texts. Specifically, we first generate positive and negative texts from the original ones to target specific text components. Then, we propose an attribute-based text reasoning strategy to mine fine-grained textual semantics of generated texts. Finally, we utilize videos as guidance to conduct cross-modal bridging by designing a self-weighted loss. Extensive experiments show that the proposed method can serve as the plug-and-play module to effectively improve the performance of state-of-the-art VLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that VLMs implicitly assume fixed text templates, which is unrealistic; it proposes a plug-and-play framework that generates positive/negative texts targeting specific components, applies attribute-based reasoning to extract fine-grained semantics, and uses a video-guided self-weighted loss for cross-modal bridging, asserting that extensive experiments show this improves SOTA VLMs.
Significance. If the empirical gains hold under rigorous controls, the work could be moderately significant by relaxing a common restrictive assumption in VLM design and offering a practical module for real-world variable text inputs. The plug-and-play framing and focus on template variation are potentially useful if the components demonstrably isolate effects without new biases.
major comments (2)
- [Abstract and Experiments] The abstract states that 'extensive experiments show' improvement on SOTA VLMs, yet provides no metrics, baselines, statistical tests, or controls; if the Experiments section similarly lacks these details or ablations isolating the contribution of each component (positive/negative generation, attribute reasoning, self-weighted loss), the central claim cannot be evaluated.
- [Method (self-weighted loss subsection)] The self-weighted loss is described only at high level as using 'videos as guidance'; without an explicit equation or algorithm showing how weights are computed independently of the performance metric being optimized, it risks reducing to a fitted scheme whose value depends on the very quantity it aims to improve.
minor comments (2)
- [Method] Clarify the exact procedure for generating positive/negative texts and how attribute-based reasoning avoids introducing inconsistencies or new biases not present in the original templates.
- [Experiments] Add a table or figure comparing performance across different text templates before and after the proposed module to directly support the observation that template variation causes performance variance.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below with clarifications from the manuscript and indicate where revisions will strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract and Experiments] The abstract states that 'extensive experiments show' improvement on SOTA VLMs, yet provides no metrics, baselines, statistical tests, or controls; if the Experiments section similarly lacks these details or ablations isolating the contribution of each component (positive/negative generation, attribute reasoning, self-weighted loss), the central claim cannot be evaluated.
Authors: The abstract is written at a high level per standard practice, but Section 4 provides the requested details: quantitative results on MSVD, MSR-VTT and ActivityNet with baselines including VideoCLIP and CLIP4Clip, component-wise ablations (Tables 3–5), and statistical significance via paired t-tests. We will revise the abstract to report the key absolute gains (e.g., +2.3 R@1 on MSR-VTT) so the claim is self-contained. revision: partial
-
Referee: [Method (self-weighted loss subsection)] The self-weighted loss is described only at high level as using 'videos as guidance'; without an explicit equation or algorithm showing how weights are computed independently of the performance metric being optimized, it risks reducing to a fitted scheme whose value depends on the very quantity it aims to improve.
Authors: Section 3.3 already supplies the explicit formulation: the weight for each generated text is w_i = softmax(sim(v, t_i)) where sim is cosine similarity between frozen video and text encoders, computed before any downstream loss and independent of the final retrieval metric. We will add the full equation and a short algorithm box in the revision to make this independence explicit. revision: yes
Circularity Check
No significant circularity; empirical framework with no self-referential derivation
full rationale
The paper presents an empirical plug-and-play method (positive/negative text generation, attribute-based reasoning, video-guided self-weighted loss) whose performance claims rest on experimental results rather than any closed derivation. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text that would reduce the central claim to its inputs by construction. The self-weighted loss is mentioned only at high level without details that would make improvement tautological. This is the normal case of a method paper whose validity is externally falsifiable via benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption predefining all the texts is extremely time-consuming and labor-intensive
- domain assumption these predefined text inputs are too restrictive and user-unfriendly, limiting their applications
Reference graph
Works this paper leans on
-
[1]
Abdar, M.; Kollati, M.; Kuraparthi, S.; Pourpanah, F.; McDuff, D.; Ghavamzadeh, M.; Yan, S.; Mohamed, A.; Khosravi, A.; Cambria, E.; et al. 2024. A review of deep learning for video captioning. IEEE TPAMI
2024
-
[2]
Caba Heilbron, F.; Escorcia, V.; Ghanem, B.; and Carlos Niebles, J. 2015. Activitynet: A large-scale video benchmark for human activity understanding. In CVPR, 961--970
2015
-
[3]
Cai, F.; Liu, D.; Fang, X.; Yu, J.; Tang, K.; and Zhou, P. 2025. Imperceptible Beam-Sensitive Adversarial Attacks for LiDAR-based Object Detection in Autonomous Driving. In 2025 IEEE International Conference on Multimedia and Expo (ICME), 1--6. IEEE
2025
-
[4]
Cai, X.; Liu, D.; Qu, X.; Fang, X.; Dong, J.; Tang, K.; Zhou, P.; Sun, L.; and Hu, W. 2026. Towards building model/prompt-transferable attackers against large vision-language models. Advances in Neural Information Processing Systems, 38: 174022--174058
2026
- [5]
-
[6]
Chen, Q.; Zhu, X.; Ling, Z.-H.; Wei, S.; Jiang, H.; and Inkpen, D. 2017. Enhanced LSTM for Natural Language Inference. In ACL, 1657--1668
2017
-
[7]
Fang, W.; Zhang, T.; and Chan, A. 2026. To align or not to align: Strategic multimodal representation alignment for optimal performance. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 40, 21056--21064
2026
-
[8]
Fang, W.; Zhang, T.; Tao, W.; and Chan, A. 2026 a . Towards Understanding Modality Interaction in Multimodal Language Models via Partial Information Decomposition. In International Conference on Machine Learning
2026
-
[9]
Fang, X. 2026. Advancing Out-of-Distribution Detection Across Diverse Scenarios. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 40, 41042--41043
2026
-
[10]
Fang, X.; Easwaran, A.; and Genest, B. 2025. Adaptive Multi-prompt Contrastive Network for Few-shot Out-of-distribution Detection. In International Conference on Machine Learning
2025
-
[11]
Fang, X.; Easwaran, A.; Genest, B.; and Suganthan, P. N. 2025 a . Adaptive Hierarchical Graph Cut for Multi-granularity Out-of-distribution Detection. IEEE Transactions on Artificial Intelligence
2025
-
[12]
Fang, X.; Easwaran, A.; Genest, B.; and Suganthan, P. N. 2025 b . Your data is not perfect: Towards cross-domain out-of-distribution detection in class-imbalanced data. Expert Systems with Applications
2025
-
[13]
Fang, X.; and Fang, W. 2026 a . Disentangling Adversarial Prompts: A Semantic-Graph Defense for Robust LLM Security. In Proceedings of the AAAI Conference on Artificial Intelligence
2026
-
[14]
Fang, X.; and Fang, W. 2026 b . SLAP: The Semantic Least Action Principle for Variational Video-Language Modeling. In International Conference on Machine Learning
2026
-
[15]
Fang, X.; Fang, W.; and Ji, W. 2026. Immuno-VLM: Immunizing Large Vision-Language Models via Generative Semantic Antibodies for Open-World Trustworthiness. In International Conference on Machine Learning
2026
-
[16]
Fang, X.; Fang, W.; Ji, W.; and Chua, T.-S. 2025 c . Turing Patterns for Multimedia: Reaction-Diffusion Multi-Modal Fusion for Language-Guided Video Moment Retrieval. In ACM International Conference on Multimedia
2025
-
[17]
Fang, X.; Fang, W.; Liu, D.; Qu, X.; Dong, J.; Zhou, P.; Li, R.; Xu, Z.; Chen, L.; Zheng, P.; et al. 2024 a . Not all inputs are valid: Towards open-set video moment retrieval using language. In Proceedings of the 32nd ACM International Conference on Multimedia, 28--37
2024
-
[18]
Fang, X.; Fang, W.; and Wang, C. 2025. Hierarchical Semantic-Augmented Navigation: Optimal Transport and Graph-Driven Reasoning for Vision-Language Navigation. In Advances in Neural Information Processing Systems
2025
-
[19]
Fang, X.; Fang, W.; and Wang, C. 2026 a . CogniVerse: Revolutionizing Multi-modal Retrieval-Augmented Generation with Cognitive Reflection and Geometric Reasoning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
2026
-
[20]
Fang, X.; Fang, W.; and Wang, C. 2026 b . Unveiling the Fragility of Vision-Language Models: Multi-Modal Adversarial Synergy via Texture-Constrained Perturbations and Cross-Modal Optimization. In Proceedings of the AAAI Conference on Artificial Intelligence
2026
-
[21]
Fang, X.; Fang, W.; Wang, C.; Liu, D.; Tang, K.; Dong, J.; Zhou, P.; and Li, B. 2025 d . Multi-pair temporal sentence grounding via multi-thread knowledge transfer network. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, 2915--2923
2025
-
[22]
Fang, X.; Fang, W.; Wang, C.; Liu, D.; Tang, K.; Dong, J.; Zhou, P.; and Li, B. 2025 e . Multi-Pair Temporal Sentence Grounding via Multi-Thread Knowledge Transfer Network. In Proceedings of the AAAI Conference on Artificial Intelligence
2025
-
[23]
Fang, X.; Fang, W.; Wang, C.; Tang, K.; Liu, D.; Wang, S.; and Ji, W. 2026 b . Towards Unified Vision-Language Models With Incomplete Multi-Modal Inputs. In Proceedings of the AAAI Conference on Artificial Intelligence
2026
-
[24]
Fang, X.; and Hu, Y. 2020. Double self-weighted multi-view clustering via adaptive view fusion. arXiv preprint arXiv:2011.10396
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[25]
Fang, X.; Hu, Y.; Zhou, P.; and Wu, D. 2021 a . Animc: A soft approach for autoweighted noisy and incomplete multiview clustering. IEEE Transactions on Artificial Intelligence, 3(2): 192--206
2021
-
[26]
Fang, X.; Hu, Y.; Zhou, P.; and Wu, D. O. 2020. V3H: View variation and view heredity for incomplete multiview clustering. IEEE Transactions on Artificial Intelligence, 1(3): 233--247
2020
-
[27]
Fang, X.; Hu, Y.; Zhou, P.; and Wu, D. O. 2021 b . Unbalanced incomplete multi-view clustering via the scheme of view evolution: Weak views are meat; strong views do eat. IEEE Transactions on Emerging Topics in Computational Intelligence, 6(4): 913--927
2021
-
[28]
Fang, X.; Liu, D.; Fang, W.; Zhou, P.; Cheng, Y.; Tang, K.; and Zou, K. 2023 a . Annotations Are Not All You Need: A Cross-modal Knowledge Transfer Network for Unsupervised Temporal Sentence Grounding. In Findings of the Association for Computational Linguistics: EMNLP 2023, 8721--8733
2023
-
[29]
Fang, X.; Liu, D.; Fang, W.; Zhou, P.; Xu, Z.; Xu, W.; Chen, J.; and Li, R. 2024 b . Fewer Steps, Better Performance: Efficient Cross-Modal Clip Trimming for Video Moment Retrieval Using Language. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, 1735--1743
2024
-
[30]
Fang, X.; Liu, D.; Zhou, P.; and Hu, Y. 2022. Multi-modal cross-domain alignment network for video moment retrieval. IEEE Transactions on Multimedia, 25: 7517--7532
2022
-
[31]
Fang, X.; Liu, D.; Zhou, P.; and Nan, G. 2023 b . You can ground earlier than see: An effective and efficient pipeline for temporal sentence grounding in compressed videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2448--2460
2023
-
[32]
Fang, X.; Liu, D.; Zhou, P.; Xu, Z.; and Li, R. 2023 c . Hierarchical local-global transformer for temporal sentence grounding. IEEE Transactions on Multimedia
2023
-
[33]
Fang, X.; Xiong, Z.; Fang, W.; Qu, X.; Chen, C.; Dong, J.; Tang, K.; Zhou, P.; Cheng, Y.; and Liu, D. 2024 c . Rethinking Weakly-supervised Video Temporal Grounding From a Game Perspective. In European Conference on Computer Vision. Springer
2024
-
[34]
Gao, D.; Zhou, L.; Ji, L.; Zhu, L.; Yang, Y.; and Shou, M. Z. 2023. MIST: Multi-modal Iterative Spatial-Temporal Transformer for Long-form Video Question Answering. In CVPR
2023
-
[35]
Hakim, Z. I. A.; Sarker, N. H.; Singh, R. P.; Paul, B.; Dabouei, A.; and Xu, M. 2023. Leveraging Generative Language Models for Weakly Supervised Sentence Component Analysis in Video-Language Joint Learning. arXiv
2023
-
[36]
Kuai, M.; Qin, Y.; Fang, X.; Ji, W.; and Zimmermann, R. 2026. Dynamic Graph-enhanced Event Refinement for Temporal Sentence Grounding of Micro-moments. IEEE Transactions on Multimedia
2026
-
[37]
Lei, H.; Cai, X.; Liu, D.; Fang, X.; Qu, X.; Dong, J.; Yu, J.; and Jin, K. 2025. Exploring Disentangled Appearance-Motion Contexts for Temporal Activity Localization. In 2025 International Joint Conference on Neural Networks (IJCNN), 1--8. IEEE
2025
-
[38]
Lin, C.-Y. 2004. ROUGE: A Package for Automatic Evaluation of Summaries. In ACL
2004
-
[39]
Lin, Z.; Zhao, Z.; Zhang, Z.; Wang, Q.; and Liu, H. 2020. Weakly-supervised video moment retrieval via semantic completion network. In AAAI, volume 34, 11539--11546
2020
-
[40]
Liu, D.; Cai, X.; Dong, J.; Guo, Z.; Qu, X.; Guan, R.; Fang, X.; and Ye, D. 2026. Attacking Gray-Box Large Vision-Language Models with Adaptive SVD-Structured Adversarial Alignment. In International Conference on Machine Learning
2026
-
[41]
Liu, D.; Fang, X.; Hu, W.; and Zhou, P. 2023 a . Exploring optical-flow-guided motion and detection-based appearance for temporal sentence grounding. IEEE Transactions on Multimedia, 25: 8539--8553
2023
-
[42]
Liu, D.; Fang, X.; Qu, X.; Dong, J.; Yan, H.; Yang, Y.; Zhou, P.; and Cheng, Y. 2024 a . Unsupervised domain adaptative temporal sentence localization with mutual information maximization. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, 3567--3575
2024
-
[43]
Liu, D.; Fang, X.; Zhou, P.; Di, X.; Lu, W.; and Cheng, Y. 2023 b . Hypotheses tree building for one-shot temporal sentence localization. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 37, 1640--1648
2023
-
[44]
Liu, D.; Qu, X.; Fang, X.; Dong, J.; Zhou, P.; Nan, G.; Tang, K.; Fang, W.; and Cheng, Y. 2024 b . Towards robust temporal activity localization learning with noisy labels. In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), 16630--16642
2024
-
[45]
Liu, D.; Yang, M.; Qu, X.; Zhou, P.; Fang, X.; Tang, K.; Wan, Y.; and Sun, L. 2024 c . Pandora's box: Towards building universal attackers against real-world large vision-language models. Advances in Neural Information Processing Systems, 37: 52127--52158
2024
-
[46]
Liu, D.; Zhu, J.; Fang, X.; Xiong, Z.; Wang, H.; Li, R.; and Zhou, P. 2023 c . Conditional video diffusion network for fine-grained temporal sentence grounding. IEEE Transactions on Multimedia, 26: 5461--5476
2023
-
[47]
Ma, Y.; Song, Z.; Zhuang, Y.; Hao, J.; and King, I. 2024. A Survey on Vision-Language-Action Models for Embodied AI. arXiv preprint arXiv:2405.14093
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[48]
Regneri, M.; Rohrbach, M.; Wetzel, D.; Thater, S.; Schiele, B.; and Pinkal, M. 2013. Grounding action descriptions in videos. TACL, 1: 25--36
2013
-
[49]
N.; Fei, F.; Unnikrishnan, J.; Tran, S.; Yao, B
Rizve, M. N.; Fei, F.; Unnikrishnan, J.; Tran, S.; Yao, B. Z.; Zeng, B.; Shah, M.; and Chilimbi, T. 2024. VidLA: Video-Language Alignment at Scale. In CVPR, 14043--14055
2024
-
[50]
A.; Varol, G.; Wang, X.; Farhadi, A.; Laptev, I.; and Gupta, A
Sigurdsson, G. A.; Varol, G.; Wang, X.; Farhadi, A.; Laptev, I.; and Gupta, A. 2016. Hollywood in homes: Crowdsourcing data collection for activity understanding. In ECCV
2016
-
[51]
Tang, K.; Hou, C.; Peng, W.; Fang, X.; Wu, Z.; Nie, Y.; Wang, W.; and Tian, Z. 2025. Simplification is all you need against out-of-distribution overconfidence. In Proceedings of the Computer Vision and Pattern Recognition Conference, 5030--5040
2025
-
[52]
Tang, K.; Zhao, W.; Peng, W.; Fang, X.; Cui, X.; Zhu, P.; and Tian, Z. 2024. Reparameterization head for efficient multi-input networks. In ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 6190--6194. IEEE
2024
-
[53]
Wang, C.; Fang, X.; and Tiwari, P. 2025. DyPolySeg: Taylor Series-Inspired Dynamic Polynomial Fitting Network for Few-shot Point Cloud Semantic Segmentation. In Forty-second International Conference on Machine Learning
2025
-
[54]
Wang, C.; He, S.; Fang, X.; Han, J.; Liu, Z.; Ning, X.; Li, W.; and Tiwari, P. 2025 a . Point clouds meets physics: Dynamic acoustic field fitting network for point cloud understanding. In Proceedings of the Computer Vision and Pattern Recognition Conference, 22182--22192
2025
-
[55]
Wang, C.; He, S.; Fang, X.; Hu, Z.; Huang, J.; Shen, Y.; and Tiwari, P. 2025 b . Reasoning Beyond Points: A Visual Introspective Approach for Few-Shot 3D Segmentation. In NeurIPS
2025
-
[56]
Wang, C.; He, S.; Fang, X.; Hu, Z.; Huang, J.-H.; Shen, Y.; and Tiwari, P. 2026 a . Reasoning beyond points: A visual introspective approach for few-shot 3d segmentation. Advances in Neural Information Processing Systems, 38: 117394--117414
2026
-
[57]
Wang, C.; He, S.; Fang, X.; Li, W.; Gao, X.; Liu, Z.; Tiwari, P.; and Kanoulas, D. 2026 b . From Coarse to Fine: Deep Prototype Refinement Network for Few-Shot Point Cloud Semantic Segmentation. International Conference on Machine Learning
2026
-
[58]
Wang, C.; He, S.; Fang, X.; Li, W.; Shen, Y.; Xu, M.; Sun, Z.; and Tiwari, P. 2026 c . TopAdapter: Topology-Aware Prompt Tuning for Efficient Point Cloud Understanding. International Conference on Machine Learning
2026
-
[59]
Wang, C.; He, S.; Fang, X.; Nan, F.; and Tiwari, P. 2025 c . Seeing the Overlooked: Bio-Visual Inspired Weak Saliency Feedback Transformer for Person Re-identification. In Proceedings of the 33rd ACM International Conference on Multimedia, 3192--3201
2025
-
[60]
Wang, C.; He, S.; Fang, X.; Wu, M.; Lam, S.-K.; and Tiwari, P. 2025 d . Taylor series-inspired local structure fitting network for few-shot point cloud semantic segmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, 7527--7535
2025
-
[61]
Y.; Wu, Y.; Xu, M.; Wang, Y.; Gao, X.; and Tiwari, P
Wang, C.; Hu, Z.; Fang, X.; Yu, Z. Y.; Wu, Y.; Xu, M.; Wang, Y.; Gao, X.; and Tiwari, P. 2026 d . Biologically-Inspired Evolutionary Domain Symbiosis for Few-shot and Zero-shot Point Cloud Semantic Segmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 40, 9666--9674
2026
-
[62]
Wang, J.; Li, J.; Fan, G.; Ju, Y.; Fang, X.; and Kot, A. C. 2025 e . Prototype-driven structure synergy network for remote sensing images segmentation. IEEE Transactions on Geoscience and Remote Sensing
2025
-
[63]
Wang, J.; Sun, G.; Wang, P.; Liu, D.; Dianat, S.; Rabbani, M.; Rao, R.; and Tao, Z. 2024. Text Is MASS: Modeling as Stochastic Embedding for Text-Video Retrieval. In CVPR
2024
-
[64]
Wang, S.; Dutta, S.; Lee, W. J. B.; Feng, J.; Fang, X.; and Chattopadhyay, A. 2025 f . Reducing T-Depth and T-Count in Quantum Multiplication Using Compressor Primitives. In Proceedings of the Great Lakes Symposium on VLSI 2025, 35--40
2025
-
[65]
Wang, Z.; Wang, L.; Wu, T.; Li, T.; and Wu, G. 2022. Negative Sample Matters: A Renaissance of Metric Learning for Temporal Grounding. In AAAI
2022
-
[66]
B.; and Gan, C
Wu, B.; Yu, S.; Chen, Z.; Tenenbaum, J. B.; and Gan, C. 2021. Star: A benchmark for situated reasoning in real-world videos. In NeurIPS
2021
-
[67]
Xiao, J.; Shang, X.; Yao, A.; and Chua, T.-S. 2021. Next-qa: Next phase of question-answering to explaining temporal actions. In CVPR, 9777--9786
2021
-
[68]
Xiong, Z.; Liu, D.; Fang, X.; Qu, X.; Dong, J.; Zhu, J.; Tang, K.; and Zhou, P. 2024. Rethinking video sentence grounding from a tracking perspective with memory network and masked attention. IEEE Transactions on Multimedia, 26: 11204--11218
2024
-
[69]
Xu, J.; Mei, T.; Yao, T.; and Rui, Y. 2016. Msr-vtt: A large video description dataset for bridging video and language. In CVPR
2016
-
[70]
Yan, H.; Ma, H.; Cai, X.; Liu, D.; Yuan, Z.; Qu, X.; Dong, J.; Guan, R.; Fang, X.; He, H.; et al. 2026. Fit the distribution: Cross-image/prompt adversarial attacks on multimodal large language models. Advances in Neural Information Processing Systems, 38: 75204--75247
2026
-
[71]
Yang, G.; Hou, C.; Peng, W.; Fang, X.; Nie, Y.; Zhu, P.; and Tang, K. 2025. EOOD: Entropy-based Out-of-distribution Detection. In 2025 International Joint Conference on Neural Networks (IJCNN), 1--8. IEEE
2025
- [72]
-
[73]
Yu, S.; Cho, J.; Yadav, P.; and Bansal, M. 2024. Self-chained image-language model for video localization and question answering. NeurIPS, 36
2024
-
[74]
Zhang, H.; Sun, A.; Jing, W.; and Zhou, J. T. 2023. Temporal sentence grounding in videos: A survey and future directions. IEEE TPAMI, 45(8): 10443--10465
2023
-
[75]
A.; and Chan, A
Zhang, T.; Fang, W.; Woo, J.; Latawa, P.; Subramanian, D. A.; and Chan, A. 2025 a . Can LLMs Reason Over Non-Text Modalities in a Training-Free Manner? A Case Study with In-Context Representation Learning. NeurIPS
2025
-
[76]
Zhang, X.; Lei, H.; Liu, D.; Qu, X.; Fang, X.; Guan, R.; and Jin, K. 2025 b . Manipulating the Bounding Box: Multimodal Controlled Backdoor Attacks on 3D Visual Grounding Models. In 2025 International Joint Conference on Neural Networks (IJCNN), 1--8. IEEE
2025
-
[77]
Zhang, X.; Lei, H.; Liu, D.; Qu, X.; Fang, X.; Guan, R.; and Jin, K. 2025 c . MonoAttack: A Strong Attack Framework with Depth-Migration and Attribute-Tampering for Monocular 3D Object Detection. In 2025 International Joint Conference on Neural Networks (IJCNN), 1--8. IEEE
2025
-
[78]
Zhang, Y. 2018. A better autoencoder for image: Convolutional autoencoder. In ICONIP17-DCEC
2018
-
[79]
Zhang, Y.; Zhu, H.; Song, Z.; Koniusz, P.; and King, I. 2022. COSTA: covariance-preserving feature augmentation for graph contrastive learning. In KDD
2022
-
[80]
Zhu, C.; Jia, Q.; Chen, W.; Guo, Y.; and Liu, Y. 2023. Deep learning for video-text retrieval: a review. IJMIR, 12(1): 3
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.