DiagramRAG: A Lightweight Framework to Retrieve Scientific Diagram for Figure Generation
Pith reviewed 2026-06-29 12:43 UTC · model grok-4.3
The pith
DiagramRAG retrieves reference diagrams that match both the content and topological structure of a user sketch to guide scientific diagram generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
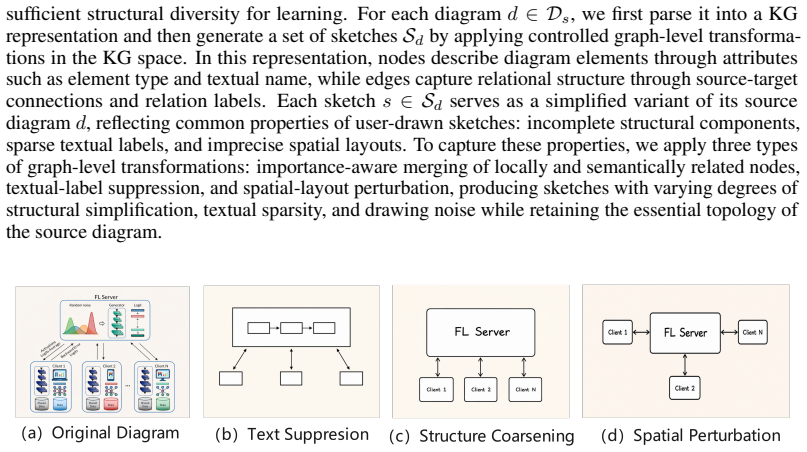
Given a user sketch, DiagramRAG retrieves reference diagrams that are both semantically relevant to the sketch content and topologically compatible with its structure, and uses them to guide downstream diagram generation. To enable efficient structure-aware retrieval, diagrams are represented as knowledge graphs, sketch variants at different simplification levels are synthesized, and an embedding model is trained to align sketches with compatible diagrams in a shared space. The retrieved references further provide content, topology, and visual priors for completing and rendering the final diagram.
What carries the argument
Knowledge graph encoding of diagrams plus an embedding model trained on synthesized multi-level sketch variants, which aligns incomplete sketches to topologically compatible full references for retrieval.
If this is right
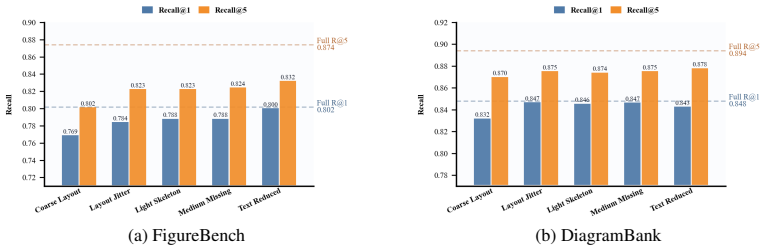
- The system reaches F1-scores of 0.848 on DiagramBank and 0.802 on FigureBench.
- Generation quality improves to a peak VLM-as-a-Judge score of 7.170.
- Inference runs at 35.48 seconds per sample.
Where Pith is reading between the lines
- The same graph-plus-embedding retrieval could be tested on non-scientific sketches such as flowcharts or network diagrams to check whether topological matching transfers.
- Feeding the retrieved reference graphs directly as additional conditioning tokens into the generator might raise the observed quality scores further.
- The multi-level sketch synthesis used for training suggests a reusable way to make retrieval robust when input drawings omit many edges or labels.
Load-bearing premise
That encoding diagrams as knowledge graphs and training embeddings on synthesized sketch variants will produce alignments that reliably locate references whose content and structure actually improve the quality of the generated diagram.
What would settle it
Generating diagrams from the same sketches once with the retrieved references and once without them, then measuring no gain or a drop in VLM-as-a-Judge score or F1 on DiagramBank and FigureBench, would show the retrieval step adds no value.
Figures



read the original abstract
Scientific diagrams are essential for communicating complex methodologies in academic papers. A natural way for researchers to specify such diagrams is through rough sketches, where text labels, connectors, and spatial arrangements express early semantic and topological intentions. However, sketches are usually incomplete, making them insufficient for directly producing publication-quality diagrams. Existing sketch-based generation methods mainly reconstruct the sketch itself, while recent text-driven diagram generation frameworks rely on textual semantics and do not fully exploit the topological structure contained in sketches. In this paper, we introduce DiagramRAG, a lightweight retrieval-augmented framework for sketch-based scientific diagram completion. Given a user sketch, DiagramRAG retrieves reference diagrams that are both semantically relevant to the sketch content and topologically compatible with its structure, and uses them to guide downstream diagram generation. To enable efficient structure-aware retrieval, we represent diagrams as knowledge graphs, synthesize sketch variants at different simplification levels, and train an embedding model to align sketches with compatible diagrams in a shared space. The retrieved references further provide content, topology, and visual priors for completing and rendering the final diagram. Experiments show that DiagramRAG achieves F1-scores of 0.848 and 0.802 on DiagramBank and FigureBench, respectively, and improves generation quality with the best VLM-as-a-Judge score of 7.170, while reducing inference latency to 35.48 seconds per sample. Our code and data are available at https://anonymous.4open.science/r/DiagramRAG-A262 and https://huggingface.co/datasets/anonymous-review-a262/DiagramSketch.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DiagramRAG, a lightweight RAG framework for sketch-based scientific diagram completion. Diagrams are represented as knowledge graphs; sketch variants at varying simplification levels are synthesized to train a contrastive embedding model that aligns user sketches with semantically relevant and topologically compatible reference diagrams in a shared space. Retrieved references supply content, topology, and visual priors to guide downstream generation. Experiments report F1 scores of 0.848 on DiagramBank and 0.802 on FigureBench, a peak VLM-as-a-Judge score of 7.170, and inference latency of 35.48 s per sample, with code and data released.
Significance. If the retrieval alignments generalize, the framework offers a practical, structure-aware alternative to purely text-driven or sketch-reconstruction methods for scientific figure generation, with measurable gains in quality and efficiency. The public release of code and datasets supports reproducibility and follow-on work.
major comments (1)
- [§3.2] §3.2: The contrastive embedding model is trained exclusively on synthesized sketch variants at different simplification levels. No held-out evaluation on authentic user-collected sketches (with real stroke noise, label variance, or partial connectivity) is reported, which directly undermines the central claim that the shared embedding space reliably surfaces topologically compatible references for downstream RAG benefit.
minor comments (2)
- The F1 metric is reported without an explicit definition of what constitutes a true positive (e.g., node/edge overlap thresholds or semantic matching criteria) in the retrieval or generation evaluation.
- Anonymous repository and dataset links are appropriate for review but should be replaced with permanent identifiers in the camera-ready version.
Simulated Author's Rebuttal
We thank the referee for the careful reading and the specific comment on evaluation. Below we respond directly to the major point raised.
read point-by-point responses
-
Referee: [§3.2] §3.2: The contrastive embedding model is trained exclusively on synthesized sketch variants at different simplification levels. No held-out evaluation on authentic user-collected sketches (with real stroke noise, label variance, or partial connectivity) is reported, which directly undermines the central claim that the shared embedding space reliably surfaces topologically compatible references for downstream RAG benefit.
Authors: We agree that evaluation on authentic user sketches would strengthen the central claim. Our synthesis procedure was explicitly constructed to introduce controlled variations in stroke density, label placement, and connectivity that approximate the characteristics of hand-drawn scientific sketches; the contrastive objective is trained across multiple simplification levels precisely to encourage robustness to such noise. The held-out portions of DiagramBank and FigureBench follow the same synthesis distribution, and the downstream RAG gains (F1 0.848/0.802 and VLM score 7.170) provide indirect evidence that the learned space transfers to the generation task. Nevertheless, we recognize that this remains a proxy evaluation. We will revise §3.2 and add a dedicated limitations paragraph to state the reliance on synthesized data, describe the design choices intended to mimic real sketch variance, and note the absence of a real-user held-out set as an open direction for future work. revision: partial
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's core pipeline—representing diagrams as knowledge graphs, synthesizing sketch variants for contrastive embedding training, retrieving from external collections (DiagramBank/FigureBench), and using references to guide generation—does not contain any self-definitional steps, fitted inputs renamed as predictions, or load-bearing self-citations. The reported F1-scores (0.848/0.802) and VLM score are external benchmark metrics on held-out data, not quantities forced by construction from the synthesis or training inputs. The embedding alignment is presented as an empirical method whose reliability is tested separately rather than assumed by definition.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Diagrams can be faithfully represented as knowledge graphs that capture both semantic labels and topological structure.
Reference graph
Works this paper leans on
-
[1]
A diagram is worth a dozen images
Aniruddha Kembhavi, Mike Salvato, Eric Kolve, Minjoon Seo, Hannaneh Hajishirzi, and Ali Farhadi. A diagram is worth a dozen images. In Computer Vision – ECCV 2016, volume 9908 of Lecture Notes in Computer Science, pages 235–251. Springer, 2016. doi: 10.1007/ 978-3-319-46493-0_15. URLhttps://doi.org/10.1007/978-3-319-46493-0_15
-
[2]
Dy- namic graph generation network: Generating relational knowledge from diagrams
Daesik Kim, Youngjoon Yoo, Jeesoo Kim, Sangkuk Lee, and Nojun Kwak. Dy- namic graph generation network: Generating relational knowledge from diagrams. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3298– 3307, 2018. URL https://openaccess.thecvf.com/content_cvpr_2018/html/Kim_ Dynamic_Graph_Generation_CVPR_2018_paper.html
2018
-
[3]
Tingwen Zhang, Ling Yue, Zhen Xu, and Shaowu Pan. Diagrambank: A large-scale dataset of diagram design exemplars with paper metadata for retrieval-augmented generation. arXiv preprint arXiv:2604.20857, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
Graphesis: Visual Knowledge Production and Representation
Johanna Drucker. Graphesis: Visual Knowledge Production and Representation. Harvard University Press, 2014
2014
-
[5]
Visualizing thought
Barbara Tversky. Visualizing thought. Topics in Cognitive Science, 3(3):499–535, 2011
2011
-
[6]
Po-Shen Lee, Jevin D. West, and Bill Howe. Viziometrics: Analyzing visual information in the scientific literature. IEEE Transactions on Big Data, 4(1):117–129, 2018. doi: 10.1109/ TBDATA.2017.2689038
- [8]
-
[9]
Autofigure: Generating and refining publication-ready scientific illustrations
Minjun Zhu, Zhen Lin, Yixuan Weng, Panzhong Lu, Qiujie Xie, Yifan Wei, Sifan Liu, Qiyao Sun, and Yue Zhang. Autofigure: Generating and refining publication-ready scientific illustrations. In International Conference on Learning Representations, 2026. URL https://arxiv.org/ abs/2602.03828. to appear
-
[10]
SciFig: Towards Automating Editable Figure Generation for Scientific Papers
Siyuan Huang, Yutong Gao, Juyang Bai, Yifan Zhou, Zi Yin, Xinxin Liu, Rama Chellappa, Chun Pong Lau, Sayan Nag, Cheng Peng, and Shraman Pramanick. SciFig: Towards Automating Scientific Figure Generation. arXiv preprint arXiv:2601.04390, 2026. URL https://arxiv. org/abs/2601.04390
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[11]
Sketch2diagram: Generating vector diagrams from hand-drawn sketches
Itsumi Saito, Haruto Yoshida, and Keisuke Sakaguchi. Sketch2diagram: Generating vector diagrams from hand-drawn sketches. In International Conference on Learning Representations (ICLR), 2025
2025
-
[12]
Kevin Ellis, Daniel Ritchie, Armando Solar-Lezama, and Joshua B. Tenenbaum. Learning to in- fer graphics programs from hand-drawn images. In Advances in Neural Information Processing Systems, volume 31, pages 6062–6071, 2018. URL https://proceedings.neurips.cc/ paper/2018/hash/6788076842014c83cedadbe6b0ba0314-Abstract.html
- [13]
-
[14]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 3836–3847, 2023. URL https: //openaccess.thecvf.com/content/ICCV2023/html/Zhang_Adding_Conditional_ Control_to_Text-to-Image_Diffusion_Models_ICCV_2023_paper.html
2023
-
[15]
Diagrammergpt: Generating open- domain, open-platform diagrams via llm planning
Abhay Zala, Han Lin, Jaemin Cho, and Mohit Bansal. Diagrammergpt: Generating open- domain, open-platform diagrams via llm planning. arXiv preprint arXiv:2310.12128, 2023. URLhttps://arxiv.org/abs/2310.12128. 10
-
[16]
Retrieval-augmented generation for knowledge-intensive nlp tasks
Patrick Lewis, Ethan Perez, Aleksandras Piktus, and et al. Retrieval-augmented generation for knowledge-intensive nlp tasks. NeurIPS, 2020
2020
-
[17]
Shamma, Michael S
Justin Johnson, Ranjay Krishna, Michael Stark, Li-Jia Li, David A. Shamma, Michael S. Bernstein, and Li Fei-Fei. Image retrieval using scene graphs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2015
2015
-
[18]
Shamma, Michael S
Ranjay Krishna, Yuke Zhu, Oliver Groth, Justin Johnson, Kenji Hata, Joshua Kravitz, Stephanie Chen, Yannis Kalantidis, Li-Jia Li, David A. Shamma, Michael S. Bernstein, and Li Fei-Fei. Visual genome: Connecting language and vision using crowdsourced dense image annotations. International Journal of Computer Vision (IJCV), 2017
2017
-
[19]
Visual relationship detection with language priors
Cewu Lu, Ranjay Krishna, Michael Bernstein, and Li Fei-Fei. Visual relationship detection with language priors. In European Conference on Computer Vision, pages 852–869. Springer,
-
[20]
Visual Relationship Detection with Language Priors
doi: 10.1007/978-3-319-46448-0_51. URLhttps://arxiv.org/abs/1608.00187
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1007/978-3-319-46448-0_51
-
[21]
Choy, and Li Fei-Fei
Danfei Xu, Yuke Zhu, Christopher B. Choy, and Li Fei-Fei. Scene graph generation by iterative message passing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 5410–5419, 2017. URL https://openaccess.thecvf.com/content_ cvpr_2017/html/Xu_Scene_Graph_Generation_CVPR_2017_paper.html
2017
-
[22]
Neural motifs: Scene graph parsing with global context
Rowan Zellers, Mark Yatskar, Sam Thomson, and Yejin Choi. Neural motifs: Scene graph parsing with global context. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 5831–5840, 2018. URL https://openaccess.thecvf.com/ content_cvpr_2018/html/Zellers_Neural_Motifs_Scene_CVPR_2018_paper.html
2018
-
[23]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agar- wal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. In Proceedings of the 38th International Conference on Machine Learning (ICML), pages 8748– 8763, ...
2021
-
[24]
Reproducible scaling laws for contrastive language-image learning
Mehdi Cherti, Romain Beaumont, Ross Wightman, Mitchell Wortsman, Gabriel Ilharco, Cade Gordon, Christoph Schuhmann, Ludwig Schmidt, and Jenia Jitsev. Reproducible scaling laws for contrastive language-image learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2818–2829, 2023
2023
-
[25]
Mingxin Li, Yanzhao Zhang, Dingkun Long, Keqin Chen, Sibo Song, Shuai Bai, Zhibo Yang, Pengjun Xie, An Yang, Dayiheng Liu, et al. Qwen3-vl-embedding and qwen3-vl-reranker: A unified framework for state-of-the-art multimodal retrieval and ranking. arXiv preprint arXiv:2601.04720, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[26]
Clip for all things zero-shot sketch-based image retrieval, fine-grained or not
Aneeshan Sain, Ayan Kumar Bhunia, Pinaki Nath Chowdhury, Subhadeep Koley, Tao Xiang, and Yi-Zhe Song. Clip for all things zero-shot sketch-based image retrieval, fine-grained or not. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2765–2775, 2023
2023
-
[27]
Xuefei Li, Yizhou Zhou, et al. Multimodal representation learning via contrastive predic- tion for image and text matching. Pattern Recognition, 123:108402, 2022. doi: 10.1016/j. patcog.2021.108402. URL https://www.sciencedirect.com/science/article/pii/ S0031320321003198
work page doi:10.1016/j 2022
-
[28]
SimGNN: A Neural Network Approach to Fast Graph Similarity Computation
Yunsheng Bai, Hao Ding, Song Bian, Ting Chen, Yizhou Sun, and Wei Wang. SimGNN: A Neural Network Approach to Fast Graph Similarity Computation. In Proceedings of the 12th ACM International Conference on Web Search and Data Mining (WSDM), pages 384–392,
-
[29]
doi: 10.1145/3289600.3290967
-
[30]
Parth Sarthi, Salman Abdullah, Aditi Tuli, Shubh Khanna, Anna Goldie, and Christopher D. Manning. Raptor: Recursive abstractive processing for tree-organized retrieval. 2024
2024
-
[31]
From local to global: A graph rag approach to query-focused summarization
Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, Dasha Metropolitansky, Robert Osazuwa Ness, and Jonathan Larson. From local to global: A graph rag approach to query-focused summarization. 2025. 11
2025
-
[32]
Colbert: Efficient and effective passage search via contextu- alized late interaction over bert
Omar Khattab and Matei Zaharia. Colbert: Efficient and effective passage search via contextu- alized late interaction over bert. 2020
2020
-
[33]
Diagrameval: Evaluating llm-generated diagrams via graphs
Chumeng Liang and Jiaxuan You. Diagrameval: Evaluating llm-generated diagrams via graphs. 2025
2025
-
[34]
Sciflow-bench: Evaluat- ing structure-aware scientific diagram generation via inverse parsing
Tong Zhang, Honglin Lin, Zhou Liu, Chong Chen, and Wentao Zhang. Sciflow-bench: Evaluat- ing structure-aware scientific diagram generation via inverse parsing. 2026
2026
-
[35]
Optimal transport graph neural networks
Gary Bécigneul, Octavian-Eugen Ganea, Benson Chen, Regina Barzilay, and Tommi Jaakkola. Optimal transport graph neural networks. arXiv preprint arXiv:2006.04804, 2020. URL https://arxiv.org/abs/2006.04804
-
[36]
Bridging the gap between graph edit distance and kernel machines
Michel Neuhaus and Horst Bunke. Bridging the gap between graph edit distance and kernel machines. World Scientific Publishing Co., Inc., 15(10):2129–2144, 2005
2005
-
[37]
Ziheng Sun, Hongning Wang, Kangfei Zhao, and Qiong Luo. A comprehensive sur- vey and experimental study of subgraph matching: Trends, unbiasedness, and interaction. ACM Transactions on Database Systems, 49(1):1–42, 2024. doi: 10.1145/3639315. URL https://dl.acm.org/doi/10.1145/3639315
-
[38]
A comprehen- sive survey of subgraph matching: [experiments & analysis]
Myoungji Han, Hyunjoon Kim, Geonmo Gu, Kunsoo Park, and Wook-Shin Han. A comprehen- sive survey of subgraph matching: [experiments & analysis]. ACM Transactions on Database Systems, 2025. doi: 10.1145/3771791. URL https://dl.acm.org/doi/10.1145/3771791. Just Accepted
-
[39]
LightGBM: A highly efficient gradient boosting decision tree
Guolin Ke, Qi Meng, Thomas Finley, Taifeng Wang, Wei Chen, Weidong Ma, Qiwei Ye, and Tie-Yan Liu. LightGBM: A highly efficient gradient boosting decision tree. In Advances in Neural Information Processing Systems, volume 30, 2017. URL https://papers.nips.cc/ paper/6907-lightgbm-a-highly-efficient-gradient-boosting-decision-tree
2017
-
[40]
Prometheus- vision: Vision-language model as a judge for fine-grained evaluation
Seongyun Lee, Seungone Kim, Sue Hyun Park, Geewook Kim, and Minjoon Seo. Prometheus- vision: Vision-language model as a judge for fine-grained evaluation. arXiv preprint arXiv:2401.06591, 2024. URLhttps://arxiv.org/abs/2401.06591
-
[41]
Sigmoid loss for language image pre-training
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training. In Proceedings of the IEEE/CVF international conference on computer vision, pages 11975–11986, 2023
2023
-
[42]
Michael Tschannen, Alexey Gritsenko, Xiao Wang, Muhammad Ferjad Naeem, Ibrahim Alab- dulmohsin, Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Ye Xia, Basil Mustafa, et al. Siglip 2: Multilingual vision-language encoders with improved semantic understanding, localization, and dense features. arXiv preprint arXiv:2502.14786, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Brief: Bi-level coreset selection for efficient instruction tuning in llms
Chaoyuan Shen, Chi Zhang, Chengliang Chai, Jiacheng Wang, Jia Yuan, Yuping Wang, Ye Yuan, Guoren Wang, and Lei Cao. Brief: Bi-level coreset selection for efficient instruction tuning in llms. Proceedings of the VLDB Endowment, 19(6):1264–1277, 2026
2026
-
[44]
Handling label noise via instance-level difficulty modeling and dynamic optimization
Kuan Zhang, Chengliang Chai, Jingzhe Xu, Chi Zhang, Han Han, Ye Yuan, Guoren Wang, and Lei Cao. Handling label noise via instance-level difficulty modeling and dynamic optimization. Advances in Neural Information Processing Systems, 38:46667–46696, 2026
2026
-
[45]
Not all documents are what you need for extracting instruction tuning data
Chi Zhang, Huaping Zhong, Hongtao Li, Chengliang Chai, Jiawei Hong, Yuhao Deng, Jiacheng Wang, Tian Tan, Yizhou Yan, Jiantao Qiu, et al. Not all documents are what you need for extracting instruction tuning data. arXiv preprint arXiv:2505.12250, 2025
-
[46]
decision
Chi Zhang, Huaping Zhong, Kuan Zhang, Chengliang Chai, Rui Wang, Xinlin Zhuang, Tianyi Bai, Qiu Jiantao, Lei Cao, Ju Fan, et al. Harnessing diversity for important data selection in pretraining large language models. In International Conference on Learning Representations, volume 2025, pages 72980–73003, 2025. 12 A Additional Experimental Details Training...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.