Adapting Automotive Aerodynamics Surrogates to New Vehicle Families via Transfer Learning
Pith reviewed 2026-06-29 09:53 UTC · model grok-4.3
The pith
Low-rank adaptation lets a pretrained aerodynamics Transformer transfer to new vehicle families with only 20 samples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
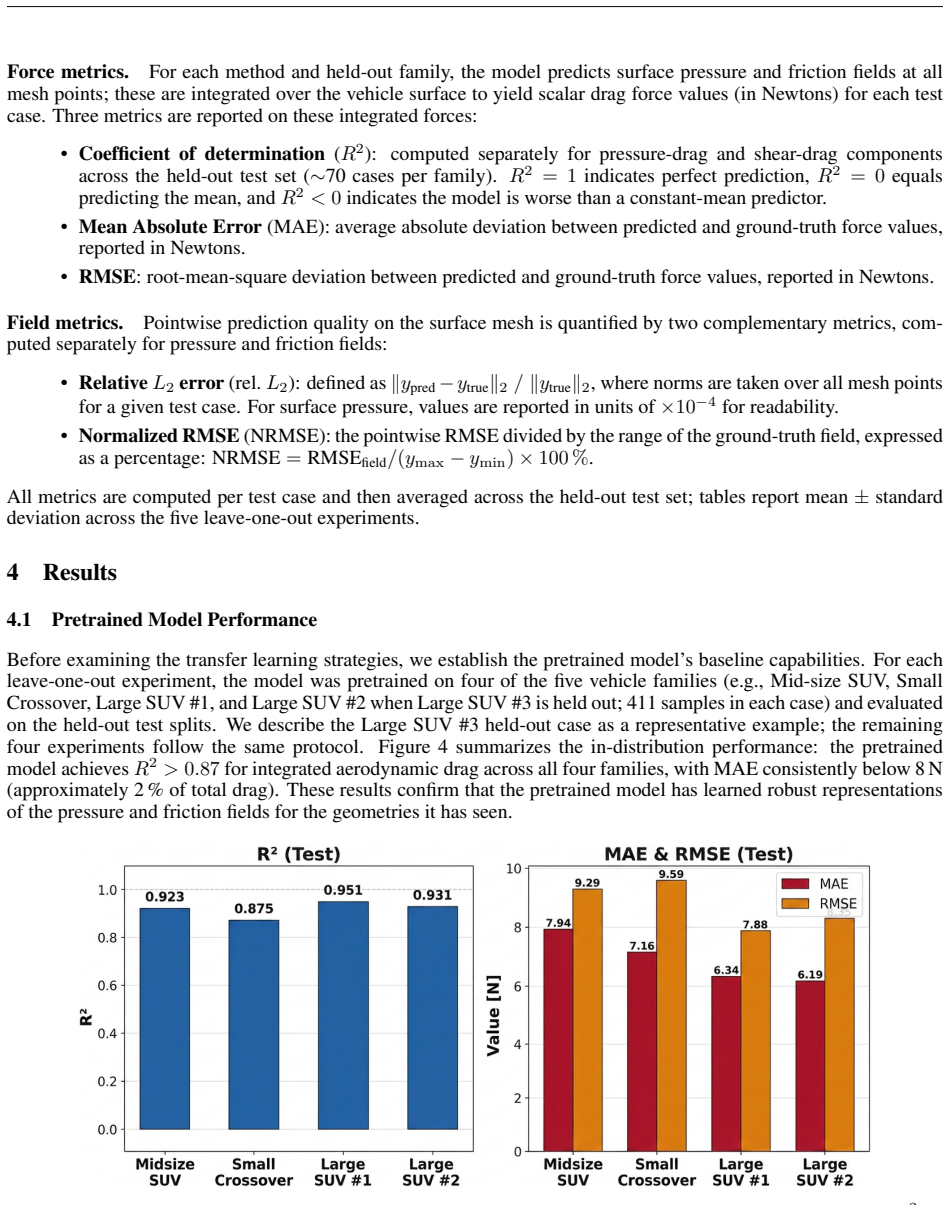
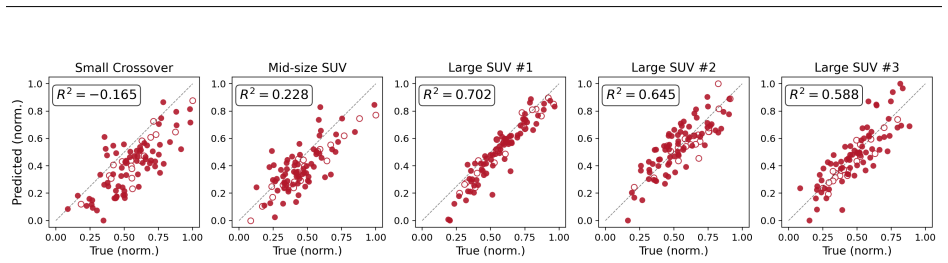
Pretrained geometry encoders learn transferable representations, but the adaptation mechanism determines whether they can be exploited. LoRA resolves both problems by injecting rank-constrained adapters into all layers, which regularizes the loss landscape while preserving pretrained features. This yields R^2=0.85+/-0.02 across all five families, 50% lower force RMSE than full fine-tuning, and 28% lower pointwise field errors, while also outperforming from-scratch training that uses 3x more target-family data.
What carries the argument
Low-Rank Adaptation (LoRA) with rank-constrained adapters injected into all layers of the 61.47M-parameter Transformer, which enables transfer by regularizing adaptation to minimal data while retaining pretrained geometric representations.
If this is right
- New vehicle families can be accommodated with 20 samples instead of large datasets.
- Full fine-tuning destabilizes and overfits on small target sets.
- Frozen encoder methods fail because they cannot represent unseen shapes.
- LoRA outperforms from-scratch training even with three times more data for the target family.
- Adapters can be trained in hours from minimal data, removing the need for large per-family datasets.
Where Pith is reading between the lines
- Similar adapter-based transfer could reduce data needs in other physics simulation domains beyond automotive aerodynamics.
- The success with topologically distinct families suggests the pretrained encoder captures general shape features useful across related but different geometries.
- Industrial workflows could maintain one shared backbone model updated only with lightweight family-specific adapters.
- Testing on families with greater topological differences would clarify the limits of this transfer.
Load-bearing premise
The five vehicle families are sufficiently distinct that adaptation success with 20 samples indicates real transfer of learned geometric representations rather than hidden similarities between the families.
What would settle it
Running the same leave-one-family-out test but replacing one family with a set of shapes that share no common topological features with the training families and observing whether the R^2 falls below 0.4.
Figures









read the original abstract
Deploying Scientific Machine Learning surrogates in industrial CFD workflows requires adapting pretrained models to new vehicle families without large datasets; yet whether geometric representations learned by a geometry encoder transfer to topologically distinct shapes remains unvalidated. We address this through leave-one-family-out experiments on a 61.47M-parameter Transformer surrogate (AB-UPT) pretrained on four vehicle families (411 external aerodynamics cases) and adapted to the held-out fifth with only 20 samples. Three strategies are compared: Full Fine-Tuning (FFT), Lightweight Fine-Tuning (LFT), and Low-Rank Adaptation (LoRA). The central finding is that pretrained geometry encoders learn transferable representations, but the adaptation mechanism determines whether they can be exploited. FFT destabilizes as 61.47M unconstrained parameters overfit to 20 samples (R^2=0.40); LFT fails because the frozen encoder cannot represent unseen shapes (R^2<0). LoRA resolves both: rank-constrained adapters injected into all layers regularize the loss landscape while preserving pretrained features, achieving R^2=0.85+/-0.02 across all five families with 50% lower force RMSE than FFT and 28% lower pointwise field errors. LoRA also outperforms from-scratch training using 3x more target-family data, eliminating the need for large per-family datasets. These results recast LoRA from a memory-saving convenience into a convergence enabler for geometry transfer: a shared backbone paired with lightweight per-family adapters trainable in hours from minimal data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that a 61.47M-parameter Transformer surrogate (AB-UPT) pretrained on four vehicle families (411 cases) can be adapted to a held-out fifth family using only 20 samples. Through leave-one-family-out experiments, it compares Full Fine-Tuning (FFT, R²=0.40), Lightweight Fine-Tuning (LFT, R²<0), and Low-Rank Adaptation (LoRA), finding that LoRA achieves R²=0.85±0.02 with 50% lower force RMSE than FFT and 28% lower pointwise field errors, while also outperforming from-scratch training on 3x more target data. The central claim is that pretrained geometry encoders learn transferable representations but that the adaptation mechanism (specifically LoRA's rank-constrained adapters) is required to exploit them without overfitting or underfitting.
Significance. If the results hold under verified conditions, the work is significant for industrial deployment of scientific ML surrogates in CFD, as it shows that minimal-data adaptation to new vehicle families is feasible and that LoRA functions as a convergence regularizer for high-parameter geometry models rather than merely a parameter-efficiency tool. This could reduce the need for large per-family datasets in automotive aerodynamics workflows.
major comments (2)
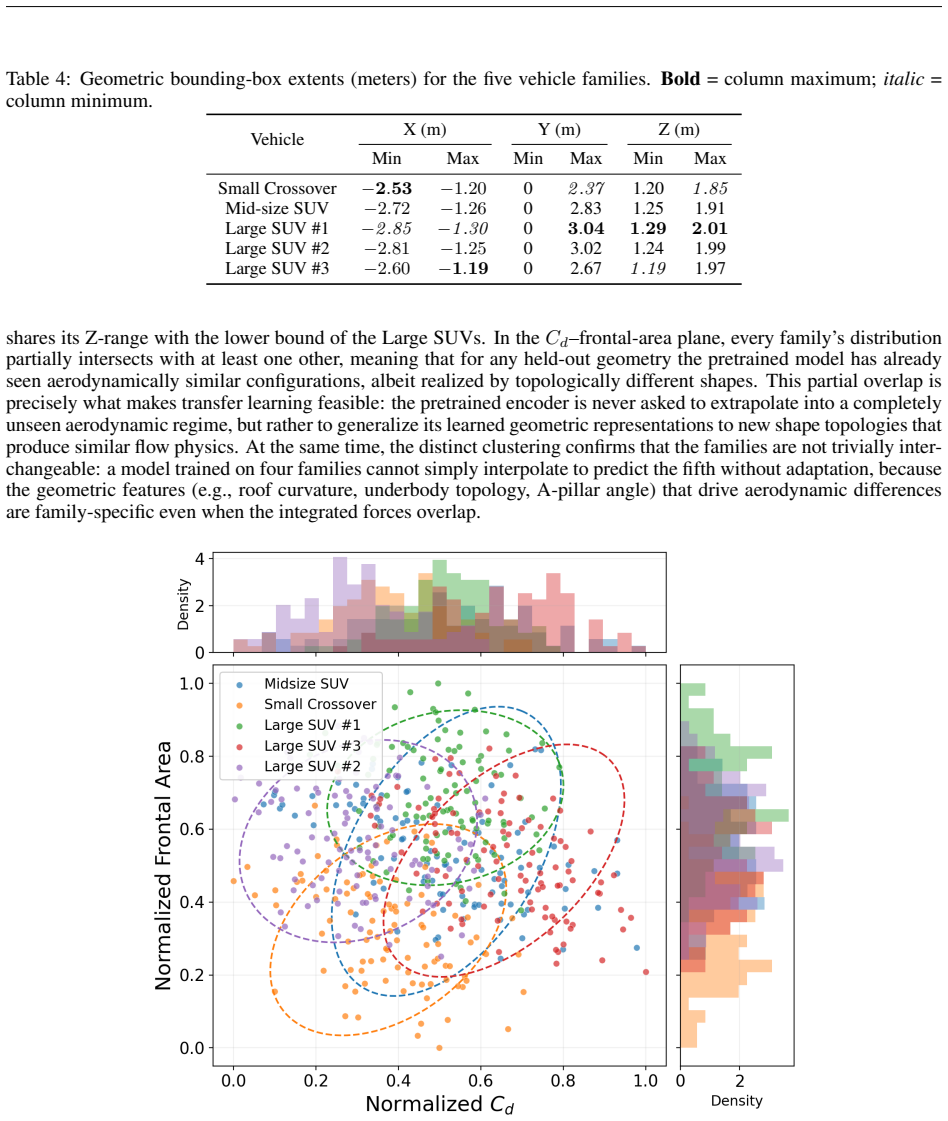
- [Abstract] Abstract: The leave-one-family-out design and the claim of transferable representations rest on the premise that the five vehicle families are topologically distinct. No quantitative evidence of distinctness (e.g., Hausdorff distances between shape distributions, mesh topology statistics, or inter-family feature-space distances) is supplied, leaving open the possibility that reported gains reflect incidental similarity rather than the claimed mechanism.
- [Abstract] Abstract: The reported performance numbers (R²=0.85±0.02, 50% RMSE reduction, 28% field-error reduction) are presented without dataset statistics, cross-validation details, or error-bar methodology, making it impossible to verify whether they support the comparative claims among FFT, LFT, and LoRA.
Simulated Author's Rebuttal
We thank the referee for highlighting these important points regarding the validation of our experimental design and the clarity of our reported results. We address each comment below and will make corresponding revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The leave-one-family-out design and the claim of transferable representations rest on the premise that the five vehicle families are topologically distinct. No quantitative evidence of distinctness (e.g., Hausdorff distances between shape distributions, mesh topology statistics, or inter-family feature-space distances) is supplied, leaving open the possibility that reported gains reflect incidental similarity rather than the claimed mechanism.
Authors: We agree that quantitative evidence of topological distinctness would better support our claims. In the revised manuscript, we will add an analysis section computing Hausdorff distances between the point clouds of different vehicle families, statistics on mesh topologies (e.g., number of elements, connectivity patterns), and distances in the latent space of the pretrained geometry encoder. This will demonstrate that the families are indeed distinct and that the performance gains arise from transferable representations rather than similarity. revision: yes
-
Referee: [Abstract] Abstract: The reported performance numbers (R²=0.85±0.02, 50% RMSE reduction, 28% field-error reduction) are presented without dataset statistics, cross-validation details, or error-bar methodology, making it impossible to verify whether they support the comparative claims among FFT, LFT, and LoRA.
Authors: The full manuscript provides dataset statistics in Section 3.1 (411 pretraining cases across four families, 20 adaptation samples for the fifth) and details the leave-one-family-out procedure in Section 4, with error bars computed as standard deviation over the five folds. To improve accessibility, we will revise the abstract to briefly note the cross-validation setup and refer to the methods for full details. We believe this addresses the verifiability concern without altering the core claims. revision: partial
Circularity Check
No circularity: all claims rest on empirical evaluation of adaptation strategies on held-out families
full rationale
The paper presents an empirical study comparing Full Fine-Tuning, Lightweight Fine-Tuning, and LoRA on a pretrained Transformer surrogate using leave-one-family-out splits across five vehicle families. Reported metrics (R^2=0.85, force RMSE reductions, pointwise field errors) are computed directly from model predictions versus ground-truth CFD data on the held-out family. No equations, derivations, or parameter fittings are described that reduce by construction to the inputs or to quantities defined in terms of the outputs. No self-citations are invoked as load-bearing premises. The experimental design assumes topological distinctness of families but does not create a self-referential loop; results remain falsifiable against external CFD benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Simulations from different vehicle families share underlying geometric features that a shared encoder can capture and that remain useful after adaptation.
Reference graph
Works this paper leans on
-
[1]
Gomez, Łukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in Neural Information Processing Systems (NeurIPS), volume 30, pages 5998–6008, 2017
2017
-
[2]
Florent Bonnet, Jocelyn Ahmed Mazari, Paola Cinnella, and Patrick Gallinari. AirfRANS: High fidelity com- putational fluid dynamics dataset for approximating Reynolds-Averaged Navier-Stokes solutions.Advances in Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track, 2022
2022
-
[3]
Neil Ashton, Charles Mockett, Marian Fuchs, Louis Fliessbach, Hendrik Hetmann, Thilo Knacke, Norbert Schonwald, Vangelis Skaperdas, Grigoris Fotiadis, Astrid Walle, Burkhard Hupertz, and Danielle Maddix. Dri- vaerml: High-fidelity computational fluid dynamics dataset for road-car external aerodynamics, 2025. URL https://arxiv.org/abs/2408.11969
-
[4]
Mohamed Elrefaie, Florin Morar, Angela Dai, and Faez Ahmed. Drivaernet++: A large-scale multimodal car dataset with computational fluid dynamics simulations and deep learning benchmarks, 2025. URLhttps: //arxiv.org/abs/2406.09624
-
[5]
Drivaerstar: An industrial-grade cfd dataset for vehicle aerodynamic optimization, 2025
Jiyan Qiu, Lyulin Kuang, Guan Wang, Yichen Xu, Leiyao Cui, Shaotong Fu, Yixin Zhu, and Ruihua Zhang. Drivaerstar: An industrial-grade cfd dataset for vehicle aerodynamic optimization, 2025. URLhttps://arxiv. org/abs/2510.16857
-
[6]
Seunghwan Keum, Vishal Raul, Ronald Grover, Scott Parrish, Rishikesh Ranade, Abouzar Ghasemi, Alexey Kamenev, and Srinivas Tadepalli. Automotive aerodynamics surrogate modeling using nvidia physicsnemo on mid-sized suv gm dataset.SAE International, 2026. doi: 10.4271/2026-01-0600
-
[7]
Schoenholz, Patrick F
Justin Gilmer, Samuel S. Schoenholz, Patrick F. Riley, Oriol Vinyals, and George E. Dahl. Neural message passing for quantum chemistry. InProceedings of the 34th ICML, pages 1263–1272. PMLR, 2017
2017
-
[8]
Battaglia
Tobias Pfaff, Meire Fortunato, Alvaro Sanchez-Gonzalez, and Peter W. Battaglia. Learning mesh-based simula- tion with graph networks. InInternational Conference on Learning Representations (ICLR), 2021
2021
-
[9]
Neil Ashton, Johannes Brandstetter, and Siddhartha Mishra. Fluid intelligence: A forward look on AI foundation models in computational fluid dynamics.arXiv preprint arXiv:2511.20455, 2025. doi: 10.48550/arXiv.2511. 20455
-
[10]
Shashank Subramanian, Karthik Kashinath, Mustafa Mustafa, Aniruddha George, Thomas Scharth, N. J. Sai Phani, et al. Towards foundation models for scientific machine learning: Characterizing scaling and transfer behavior.arXiv preprint arXiv:2306.00007, 2023. doi: 10.48550/arXiv.2306.00007
-
[11]
Fourier neural operator for parametric partial differential equations.International Conference on Learning Representations (ICLR), 2021
Zongyi Li, Nikola Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Kaushik Bhatt, Andrew Stuart, and Anima Anandkumar. Fourier neural operator for parametric partial differential equations.International Conference on Learning Representations (ICLR), 2021
2021
-
[12]
Neural operator with geometry- informed pre-training (GINO).Advances in Neural Information Processing Systems (NeurIPS), 2023
Zongyi Li, Daniel Zhengyu Huang, Burigede Liu, and Anima Anandkumar. Neural operator with geometry- informed pre-training (GINO).Advances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[13]
Rishikesh Ranade, Mohammad Amin Nabian, Kaustubh Tangsali, Alexey Kamenev, Oliver Hennigh, Raj Cherukuri, and Shahroz Choudhry. DoMINO: A decomposable multi-scale iterative neural operator for modeling large scale engineering simulations.arXiv preprint arXiv:2501.13350, 2025. doi: 10.48550/arXiv.2501.13350. 20
-
[14]
Universal physics transformers: A framework for efficiently scaling neural operators.Advances in Neural Infor- mation Processing Systems (NeurIPS), 2024
Benedikt Alkin, Andreas F ¨urst, Simon Schmid, Lukas Gruber, David Holzm ¨uller, and Johannes Brandstetter. Universal physics transformers: A framework for efficiently scaling neural operators.Advances in Neural Infor- mation Processing Systems (NeurIPS), 2024
2024
-
[15]
Benedikt Alkin, Maurits Bleeker, Richard Kurle, Tobias Kronlachner, Reinhard Sonnleitner, Matthias Dorfer, and Johannes Brandstetter. AB-UPT: Scaling neural CFD surrogates for high-fidelity automotive aerodynamics simulations via anchored-branched universal physics transformers.Transactions on Machine Learning Research, 2025
2025
-
[16]
Transolver: A fast transformer solver for PDEs on general geometries.International Conference on Machine Learning (ICML), 2024
Haixu Wu, Huakun Luo, Haowen Wang, Jianmin Wang, and Mingsheng Long. Transolver: A fast transformer solver for PDEs on general geometries.International Conference on Machine Learning (ICML), 2024
2024
-
[17]
Transolver++: An accurate neural solver for PDEs on million-scale geome- tries
Huakun Luo, Haixu Wu, Hang Zhou, Lanxiang Xing, Yichen Di, Jianmin Wang, and Mingsheng Long. Tran- solver++: An accurate neural solver for PDEs on million-scale geometries.arXiv preprint arXiv:2502.02414, 2025
-
[18]
Hang Zhou, Haixu Wu, Haonan Shangguan, Yuezhou Ma, Huikun Weng, Jianmin Wang, and Mingsheng Long. Transolver-3: Scaling up transformer solvers to industrial-scale geometries.arXiv preprint arXiv:2602.04940, 2026
-
[19]
Corey Adams, Rishikesh Ranade, Ram Cherukuri, and Sanjay Choudhry. GeoTransolver: Learning physics on irregular domains using multi-scale geometry aware physics attention transformer.arXiv preprint arXiv:2512.20399, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Carbench: A comprehensive benchmark for neural surrogates on high-fidelity 3d car aerodynamics, 2025
Mohamed Elrefaie, Dule Shu, Matt Klenk, and Faez Ahmed. Carbench: A comprehensive benchmark for neural surrogates on high-fidelity 3d car aerodynamics, 2025. URLhttps://arxiv.org/abs/2512.07847
-
[21]
A comprehensive survey on transfer learning.Proceedings of the IEEE, 109(1):43–76, 2021
Fuzhen Zhuang, Zhiyuan Qi, Keyu Duan, Dongbo Xi, Yongchun Zhu, Hengshu Zhu, Hui Xiong, and Qing He. A comprehensive survey on transfer learning.Proceedings of the IEEE, 109(1):43–76, 2021. doi: 10.1109/JPROC. 2020.3004555
-
[22]
Lequn Pan, Guang Li, Tong Zhu, Dongming Liu, and Yan Lu. Physics-informed machine learning in design and manufacturing: Status and challenges.Journal of Computing and Information Science in Engineering, 25(12): 120804, 2025. doi: 10.1115/1.4067764
-
[23]
Phong C. H. Nguyen, Joseph B. Choi, H. S. Udaykumar, and Stephen Baxter. Challenges and opportunities for machine learning in multiscale computational modeling.Journal of Computing and Information Science in Engineering, 23(6):060808, 2023. doi: 10.1115/1.4062495
-
[24]
Qi, Hao Su, Kaichun Mo, and Leonidas J
Charles R. Qi, Hao Su, Kaichun Mo, and Leonidas J. Gupta. PointNet: Deep learning on point sets for 3D classi- fication and segmentation. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 652–660, 2017
2017
-
[25]
Graph attention networks
Petar Veli ˇckovi´c, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Li`o, and Yoshua Bengio. Graph attention networks. InInternational Conference on Learning Representations (ICLR), 2018
2018
-
[26]
Bayan Bruss, and Tom Goldstein
Kezhi Kong, Jiuhai Chen, John Kirchenbauer, Renkun Ni, C. Bayan Bruss, and Tom Goldstein. GOAT: A global transformer on large-scale graphs. InProceedings of the 40th International Conference on Machine Learning (ICML), volume 202 ofProceedings of Machine Learning Research, pages 17375–17390. PMLR, 2023
2023
-
[27]
How transferable are features in deep neural networks? InAdvances in Neural Information Processing Systems (NeurIPS), volume 27, pages 3320–3328, 2014
Jason Yosinski, Jeff Clune, Yoshua Bengio, and Hod Lipson. How transferable are features in deep neural networks? InAdvances in Neural Information Processing Systems (NeurIPS), volume 27, pages 3320–3328, 2014
2014
-
[28]
Yanlu Wang, Jie Bai, Maede Sadeghpour Eshaghi, Cosmin Anitescu, and Timon Rabczuk. Transfer learning in physics-informed neural networks: Full fine-tuning, lightweight fine-tuning, and low-rank adaptation.Interna- tional Journal of Mechanical System Dynamics, 5(1):86–109, 2025. doi: 10.1002/msd2.70030
-
[29]
Jian-Xing Leng, Yu Feng, Wei Huang, Yiran Shen, and Zhen-Guo Wang. Variable-fidelity surrogate model based on transfer learning and its application in multidisciplinary design optimization of aircraft.Physics of Fluids, 36 (1):017131, 2024. doi: 10.1063/5.0188109
-
[30]
James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A. Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, et al. Overcoming catastrophic for- getting in neural networks.Proceedings of the National Academy of Sciences, 114(13):3521–3526, 2017. doi: 10.1073/pnas.1611835114
-
[31]
Parameter-efficient fine-tuning of large-scale pre-trained language models: A state-of-the-art survey.Engineering, 2023
Ning Ding, Yujia Qin, Guang Yang, Fuchao Wei, Zonghan Yang, Yusheng Su, Shengding Hu, Yulin Chen, Chi- Min Chan, Weize Chen, et al. Parameter-efficient fine-tuning of large-scale pre-trained language models: A state-of-the-art survey.Engineering, 2023. 21
2023
-
[32]
Vladislav Lialin, Vijeta Deshpande, and Anna Rumshisky. Scaling down to scale up: A guide to parameter- efficient fine-tuning.arXiv preprint arXiv:2303.15647, 2023
-
[33]
LLaMA-Adapter: Efficient Fine-tuning of Language Models with Zero-init Attention
Renrui Zhang, Jiaming Han, Aojun Zhou, Xiangfei Hu, Shilin Yan, Pan Pan, et al. LLaMA-Adapter: Efficient fine-tuning of language models with zero-init attention.arXiv preprint arXiv:2303.16199, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[34]
F-Adapter: Frequency-adaptive parameter-efficient fine-tuning in scientific machine learning
Haixin Zhang, Cong Kang, Yan Wang, Rongjie Huang, and Zhou Zhao. F-Adapter: Frequency-adaptive parameter-efficient fine-tuning in scientific machine learning. InAdvances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[35]
LoRA: Low-Rank Adaptation of Large Language Models
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models.arXiv preprint arXiv:2106.09685, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[36]
Adaptive budget allocation for parameter-efficient fine-tuning
Qingru Zhang, Minshuo Chen, Alexander Bukharin, Pengcheng He, Yu Cheng, Weizhu Chen, and Tuo Zhao. Adaptive budget allocation for parameter-efficient fine-tuning. InProceedings of ICLR, 2023
2023
-
[37]
QLoRA: Efficient finetuning of quan- tized LLMs
Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. QLoRA: Efficient finetuning of quan- tized LLMs. InNeurIPS, volume 36, pages 10088–10115, 2023
2023
-
[38]
DoRA: Weight-decomposed low-rank adaptation
Shih-Yang Liu, Chien-Yi Wang, Hongxu Yin, Pavlo Molchanov, Yu-Chiang Frank Wang, Kwang-Ting Cheng, and Min-Hung Chen. DoRA: Weight-decomposed low-rank adaptation. InProceedings of ICML, 2024
2024
-
[39]
Matthews, and Saad A
Jian Chen, James Pierce, Glen Williams, Jean-Baptiste Forien, Erin Fong, Manyalibo J. Matthews, and Saad A. Sahoo. Accelerating thermal simulations in additive manufacturing by training physics-informed neural networks with randomly synthesized data.Journal of Computing and Information Science in Engineering, 24(1):011004,
-
[40]
doi: 10.1115/1.4063338
-
[41]
Kye M. Samuel and Faez Ahmed. Continual learning strategies for 3D engineering regression problems: A benchmarking study.Journal of Computing and Information Science in Engineering, 25(10):101003, 2025. doi: 10.1115/1.4066929
-
[42]
Dang and Phong C
Hoang V . Dang and Phong C. H. Nguyen. Deep operator learning for high-fidelity fluid flow field reconstruction from sparse sensor measurements.Journal of Computing and Information Science in Engineering, 26(1):011007,
-
[43]
doi: 10.1115/1.4067993
-
[44]
Yining Chen, Jonathan Cagan, and Levent Burak Kara. Self-supervised geometric representation learning for fine-scale feature preservation in AI-driven surrogate modeling. InASME International Design Engineering Technical Conferences (IDETC-CIE), 2025. doi: 10.1115/DETC2025-168907
-
[45]
GeoPT: Scaling Physics Simulation via Lifted Geometric Pre-Training
Haixu Wu, Minghao Guo, Zongyi Li, Zhiyang Dou, Mingsheng Long, Kaiming He, and Wojciech Matusik. GeoPT: Scaling physics simulation via lifted geometric pre-training.arXiv preprint arXiv:2602.20399, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[46]
HyperLoRA for PDEs.arXiv preprint arXiv:2308.09290, 2023
Ritam Majumdar, Vishal Jadhav, Anirudh Deodhar, Shirish Karande, Lovekesh Vig, and Venkataramana Runk- ana. HyperLoRA for PDEs.arXiv preprint arXiv:2308.09290, 2023
-
[47]
Perceiver: General perception with iterative attention
Andrew Jaegle, Felix Gimeno, Andrew Brock, Oriol Vinyals, Andrew Zisserman, and Jo ˜ao Carreira. Perceiver: General perception with iterative attention. InProceedings of the 38th International Conference on Machine Learning (ICML), pages 4651–4664, 2021
2021
-
[48]
Michael D. McKay, Richard J. Beckman, and William J. Conover. A comparison of three methods for selecting values of input variables in the analysis of output from a computer code.Technometrics, 21(2):239–245, 1979. doi: 10.1080/00401706.1979.10489755
-
[49]
Accessed: 2026
PowerFLOW.https://www.3ds.com/products/simulia/powerflow. Accessed: 2026
2026
-
[50]
Sylvestre-Alvise Rebuffi, Alexander Kolesnikov, Georg Sperl, and Christoph H. Lampert. iCaRL: Incremental classifier and representation learning. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 2001–2010, 2017
2001
-
[51]
PEFT: State-of-the-art parameter-efficient fine-tuning methods, 2022
Sourab Mangrulkar, Sylvain Gugger, Lysandre Debut, Younes Belkada, Sayak Paul, and Benjamin Bossan. PEFT: State-of-the-art parameter-efficient fine-tuning methods, 2022. URLhttps://github.com/ huggingface/peft
2022
-
[52]
SGDR: Stochastic gradient descent with warm restarts
Ilya Loshchilov and Frank Hutter. SGDR: Stochastic gradient descent with warm restarts. InInternational Conference on Learning Representations (ICLR), 2017
2017
-
[53]
Eric L. Buehler and Markus J. Buehler. X-lora: Mixture of low-rank adapter experts, a flexible framework for large language models with applications in protein mechanics and molecular design, 2024. URLhttps: //arxiv.org/abs/2402.07148
-
[54]
Dropout as a Bayesian approximation: Representing model uncertainty in deep learning
Yarin Gal and Zoubin Ghahramani. Dropout as a Bayesian approximation: Representing model uncertainty in deep learning. InProceedings of the 33rd International Conference on Machine Learning (ICML), pages 1050–1059, 2016. 22
2016
-
[55]
Angelopoulos and Stephen Bates
Anastasios N. Angelopoulos and Stephen Bates. Conformal prediction: A gentle introduction.Foundations and Trends in Machine Learning, 16(4):494–591, 2023. doi: 10.1561/2200000101
-
[56]
Synthesis Lectures on Artificial Intelligence and Machine Learning
Burr Settles.Active Learning. Synthesis Lectures on Artificial Intelligence and Machine Learning. Morgan & Claypool Publishers, 2012. 23
2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.