AsyncTool: Evaluating the Asynchronous Function Calling Capability under Multi-Task Scenarios
Pith reviewed 2026-06-29 12:22 UTC · model grok-4.3
The pith
Delayed tool feedback causes clear performance drops in LLM agents handling multiple tasks concurrently.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
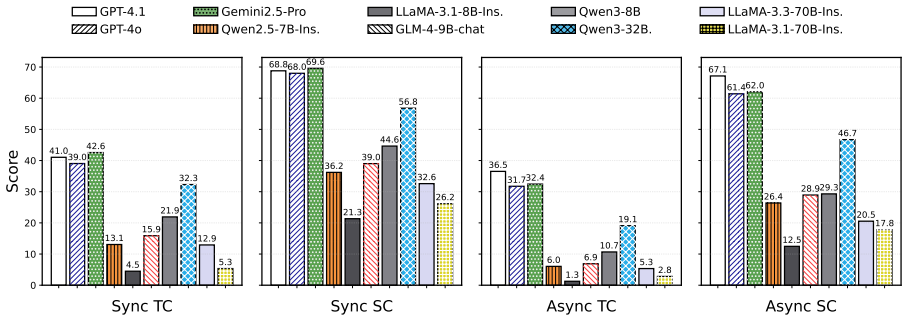
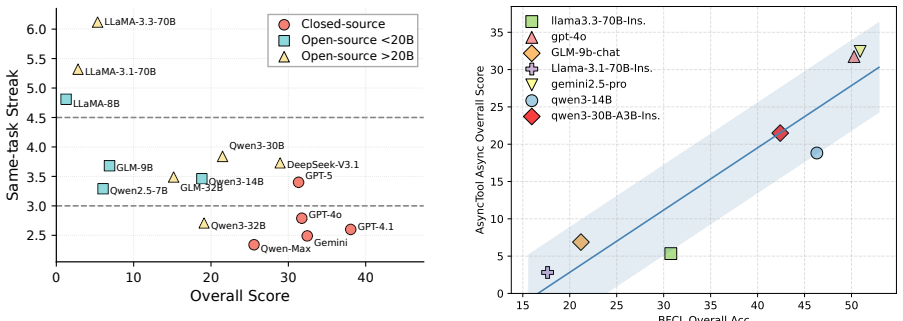
Delayed tool feedback poses substantial challenges to current agents and leads to clear performance degradation; models that better coordinate task switching, dependency tracking, and state maintenance achieve stronger performance on AsyncTool.
What carries the argument
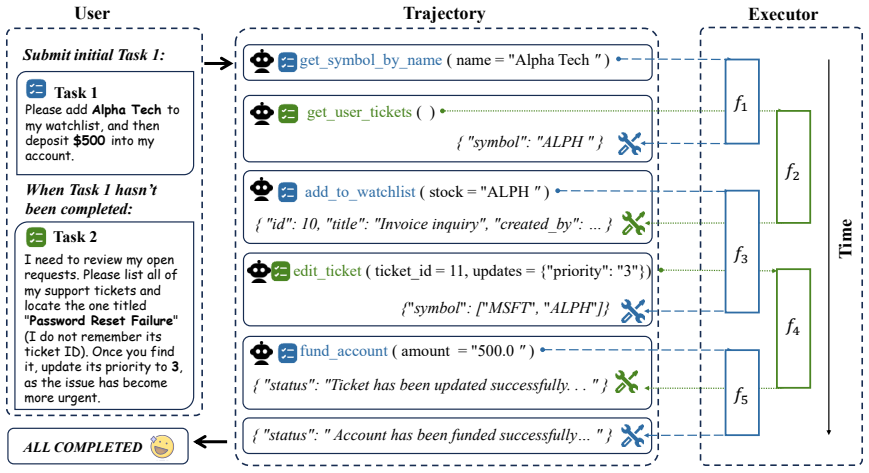
The AsyncTool benchmark, which simultaneously presents multiple tasks and simulates realistic tool response latencies to measure asynchronous calling ability.
If this is right
- Agents must incorporate explicit mechanisms for interleaving tasks during idle periods to maintain overall throughput.
- Dependency tracking and state maintenance become load-bearing skills when responses arrive out of order.
- Efficiency metrics at multiple granularities expose coordination failures that single-task benchmarks miss.
- Design of future agents should prioritize temporal reasoning to turn waiting time into productive computation.
Where Pith is reading between the lines
- Real deployments may benefit from agents that proactively issue additional tool calls while others are pending.
- The same latency sensitivity could appear in embodied systems where physical actions have variable completion times.
- Replacing simulated delays with measured network or API traces would test whether the identified failure modes persist.
Load-bearing premise
The hybrid data evolution method and chosen latency values produce task patterns and delays that match those encountered in actual multi-task tool environments.
What would settle it
Run the same models on live tools whose response times vary naturally and check whether the observed drop in completion rate and efficiency matches the benchmark degradation.
Figures








read the original abstract
Large language model (LLM)-based agents have shown strong capabilities in using external tools to solve complex tasks. However, existing evaluations often overlook the temporal dimension of tool use, especially the impact of tool response latency, and are usually limited to single-task settings. In real-world applications, multiple tasks often need to be executed concurrently, and overall efficiency depends on whether an agent can use idle time while waiting for tool responses. We refer to this capability as asynchronous tool calling. To evaluate it, we propose AsyncTool, a benchmark for assessing LLM-based agents in interactive multi-task tool-use environments with delayed tool feedback. AsyncTool presents multiple heterogeneous tasks simultaneously and simulates realistic tool response latency during execution. Using a hybrid data evolution strategy, we construct a diverse asynchronous multitasking dataset that covers multiple scenarios and tool-use patterns. We evaluate models at the step, sub-task, and task levels, and introduce efficiency-oriented metrics to measure task coordination and completion efficiency. Extensive experiments show that delayed tool feedback poses substantial challenges to current agents and leads to clear performance degradation. Models that better coordinate task switching, dependency tracking, and state maintenance achieve stronger performance on AsyncTool. Our analysis identifies key failure modes of current tool-using agents and provides practical insights for designing future systems with stronger temporal reasoning and coordination capabilities.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AsyncTool, a new benchmark for evaluating LLM-based agents on asynchronous multi-task tool use. It constructs a dataset via hybrid data evolution, simulates realistic tool response latencies, presents multiple heterogeneous tasks concurrently, and measures performance at step/sub-task/task levels using efficiency-oriented metrics focused on coordination, dependency tracking, and state maintenance. Experiments show clear performance degradation from delayed feedback, with stronger models on task switching and state maintenance performing better; the work also catalogs key failure modes.
Significance. If the simulated latencies and task interleaving patterns prove representative of real tool-use distributions, the benchmark fills a genuine gap in existing single-task or synchronous evaluations and supplies concrete evidence that temporal coordination is a distinct capability. The efficiency metrics and failure-mode analysis could directly inform agent architectures that exploit idle time during tool waits.
major comments (2)
- [Dataset construction] Dataset construction section: the claim that the hybrid data evolution strategy plus simulated latencies produce 'realistic' asynchronous multi-task patterns is load-bearing for the headline result on performance degradation, yet the manuscript provides no quantitative comparison (e.g., Kolmogorov-Smirnov tests or moment matching) of the resulting latency distributions or concurrency patterns against empirical traces from production tool APIs.
- [Evaluation metrics] Evaluation metrics section: the efficiency-oriented metrics are introduced to capture coordination, but it is unclear whether they are normalized for task difficulty or total tool-call volume; without such controls, the reported degradation could partly reflect differences in task complexity rather than asynchronous handling per se.
minor comments (2)
- [Abstract] Abstract and introduction use the phrase 'realistic tool response latency' without a forward reference to the validation (or lack thereof) that appears later.
- [Experiments] Table or figure captions for the main results should explicitly state the number of runs and any statistical significance tests performed.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Dataset construction] Dataset construction section: the claim that the hybrid data evolution strategy plus simulated latencies produce 'realistic' asynchronous multi-task patterns is load-bearing for the headline result on performance degradation, yet the manuscript provides no quantitative comparison (e.g., Kolmogorov-Smirnov tests or moment matching) of the resulting latency distributions or concurrency patterns against empirical traces from production tool APIs.
Authors: We agree that direct quantitative validation against production traces would strengthen the realism claim. Publicly available empirical traces of multi-task asynchronous tool calls from production APIs do not exist to our knowledge, precluding Kolmogorov-Smirnov tests. Our latency and concurrency patterns were derived from values reported in prior agent and tool-use literature. In revision we will add moment matching (means, variances) of our distributions against cited literature values and expand the limitations section to note the absence of direct empirical traces. revision: partial
-
Referee: [Evaluation metrics] Evaluation metrics section: the efficiency-oriented metrics are introduced to capture coordination, but it is unclear whether they are normalized for task difficulty or total tool-call volume; without such controls, the reported degradation could partly reflect differences in task complexity rather than asynchronous handling per se.
Authors: The metrics are computed at step, sub-task, and task levels with efficiency ratios that normalize completion against the number of actions taken. We will revise the evaluation metrics section to make the normalization for task difficulty and tool-call volume explicit and add controls or ablations confirming that the observed degradation is not explained by complexity differences alone. revision: yes
Circularity Check
No circularity: benchmark construction and evaluation are independent of fitted parameters or self-referential definitions
full rationale
The paper proposes AsyncTool as an external benchmark with a hybrid data evolution strategy and simulated latencies for multi-task tool use. No equations, predictions, or first-principles derivations are present that reduce to the paper's own inputs by construction. Evaluation metrics and failure mode analysis are applied to model outputs on the constructed tasks without any self-definitional loops, fitted-input renamings, or load-bearing self-citations that collapse the central claims. The dataset construction is presented as an independent methodological choice, not derived from the results it produces. This is the standard case of a self-contained empirical benchmark paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Simulated tool response latencies and concurrent multi-task setups accurately reflect real-world application conditions.
invented entities (1)
-
AsyncTool benchmark and associated dataset
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437. Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, and 1 others. 2023. Agent- bench: Evaluating llms as agents.arXiv preprint arXiv:2308.03688. OpenAI. 2025a. Gpt-5. https://openai.com/ zh-Hans-CN/index/introducing-gpt-5/ . Ac- cess...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Kimi K2: Open Agentic Intelligence
Kimi k2: Open agentic intelligence.arXiv preprint arXiv:2507.20534. Qwen Team. 2024a. Qwen2 technical report.arXiv preprint arXiv:2407.10671. Qwen Team. 2024b. Qwen2.5: A party of foundation models. Qwen Team. 2024c. Qwen2.5 technical report.arXiv preprint arXiv:2412.15115. Qiuchen Wang, Ruixue Ding, Yu Zeng, Zehui Chen, Lin Chen, Shihang Wang, Pengjun Xi...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik Narasimhan. 2024. τ-bench: A benchmark for tool-agent-user interaction in real-world domains. Preprint, arXiv:2406.12045. Junjie Ye, Guanyu Li, Songyang Gao, Caishuang Huang, Yilong Wu, Sixian Li, Xiaoran Fan, Shihan Dou, Qi Zhang, Tao Gui, and 1 oth...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Read the task description carefully and iden- tify the user’s intended goal
-
[5]
Inspect the ordered tool-call trajectory and check whether each function call is valid
-
[6]
Verify that the function name and arguments are supported by the corresponding tool
-
[7]
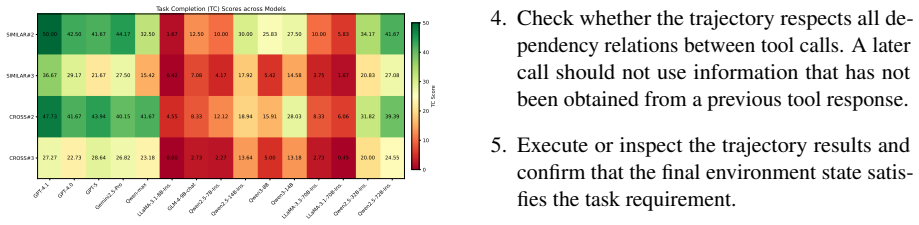
A later call should not use information that has not been obtained from a previous tool response
Check whether the trajectory respects all de- pendency relations between tool calls. A later call should not use information that has not been obtained from a previous tool response
-
[8]
Execute or inspect the trajectory results and confirm that the final environment state satis- fies the task requirement
-
[9]
If an error is found, mark the error type and provide a corrected version when the correc- tion is unambiguous
-
[10]
If the task description is ambiguous or incon- sistent with the trajectory, rewrite the descrip- tion to make key information such as entities, time, location, or required arguments explicit
-
[11]
id ": " id of task
Remove instances that cannot be reliably cor- rected or whose task description cannot be aligned with the execution trajectory. Common Error Types.Annotators were asked to pay special attention to the following errors: • incorrect interpretation of the initial task con- dition; • missing prerequisite tool calls; • invalid function names or unsupported arg...
2024
-
[12]
Clarify any ambiguities in the original problem by deriving explicit specifications from the initial configuration
Ensure problems are solvable within the given initial configuration, avoiding ambiguous or unsolvable cases. Clarify any ambiguities in the original problem by deriving explicit specifications from the initial configuration. Including but not limited to: file names, folder paths, numerical counts, and similar parameters
-
[13]
Expand the problem if necessary to meet this length requirement
Define solution paths as strict API call sequences (not less than 2 steps) with strong dependencies—later steps must require outputs from earlier ones. Expand the problem if necessary to meet this length requirement
-
[14]
Extend problems only by deriving new details from the initial config
Preserve existing explicit information (e.g., filenames, data). Extend problems only by deriving new details from the initial config
-
[15]
Consecutive duplicate function calls are prohibited in the execution sequence
Always provide the most efficient path—no unnecessary API calls. Consecutive duplicate function calls are prohibited in the execution sequence
-
[16]
Carefully review the function description
Never explicitly name APIs in the problem description. Carefully review the function description. You must ensure all function calls in the provided ground truth strictly comply with the specifications. For example, certain filesystem operations are restricted to the current working directory and cannot process multi-level paths. Only functions explicitly...
-
[17]
id ": " number_0
You have permission to edit the question and ground_truth fields, and your response must explicitly return modified versions. The output format should follow the usage examples in JSON formatinstead of the origin data. You can use the following APIs: [ API Document ] Here is one usage examples that you must follow: [ { " id ": " number_0 " , " question ":...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.