Zipping the Thought: When and How Compressed Reasoning Data Works in LLM Post-Training
Pith reviewed 2026-06-29 12:11 UTC · model grok-4.3
The pith
Coarser chain-of-thought compression requires more supervised fine-tuning data than composed or implicit forms.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
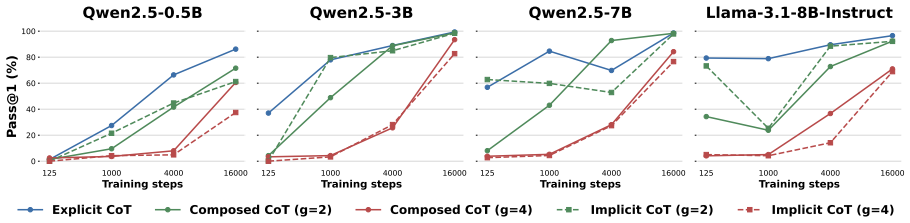
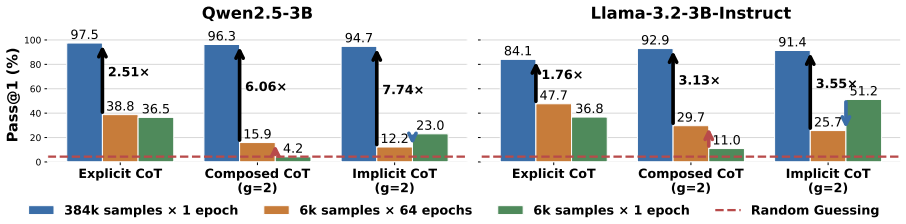
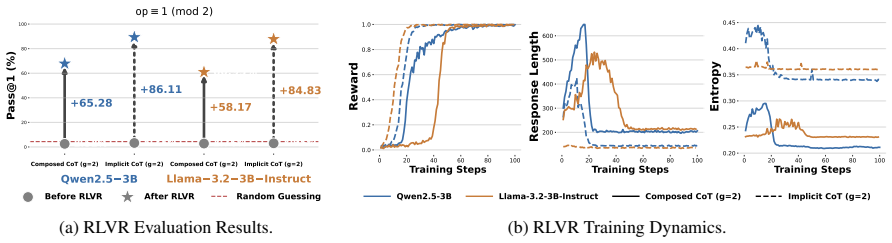
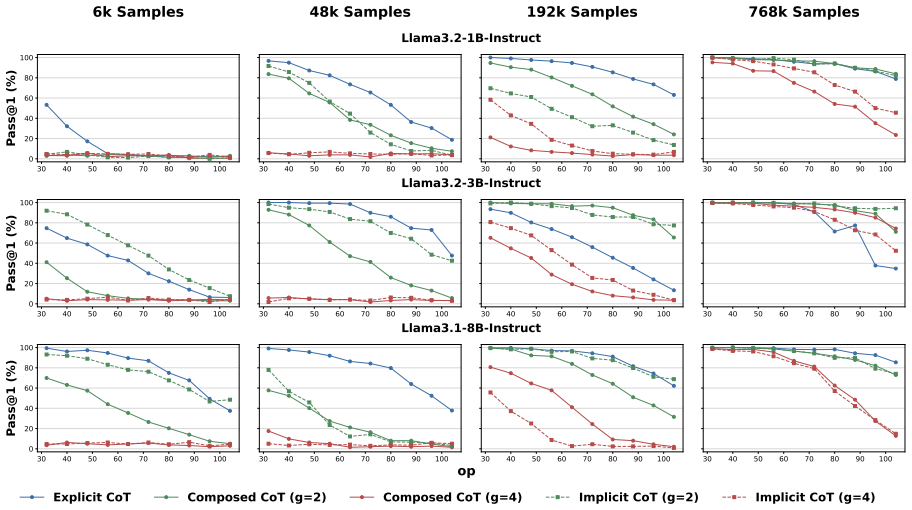
Using a synthetic compositional reasoning task that varies difficulty, compression granularity, and data size, experiments across model families show that explicit CoT requires the least SFT data while composed and implicit CoT benefit more from data scaling; composed CoT gains from repetition whereas implicit CoT tends toward memorization; RL with verifiable rewards decomposes the compressed steps acquired in SFT; and unidirectional CoT ordering produces stronger generalization on longer sequential tasks.
What carries the argument
The taxonomy of CoT into Explicit CoT (all operations shown), Composed CoT (multiple operations aggregated), and Implicit CoT (intermediate operations omitted), which controls compression granularity in the synthetic task.
If this is right
- Coarser CoT requires more SFT data to reach performance levels comparable to finer forms.
- Composed CoT and Implicit CoT benefit more from increases in SFT data volume than Explicit CoT.
- Composed CoT improves with data repetition while Implicit CoT tends to produce memorization.
- RL with verifiable rewards after SFT decomposes the compressed steps learned during SFT.
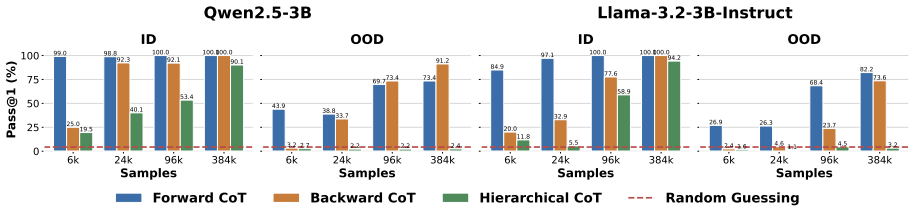
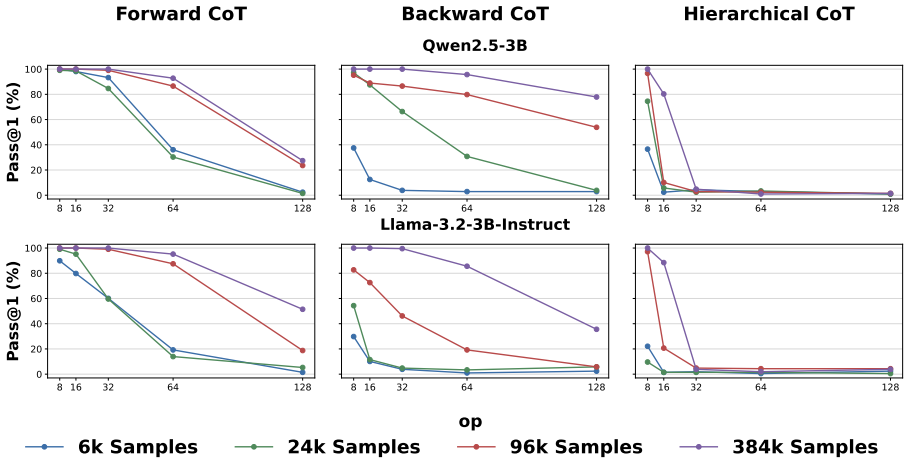
- Unidirectional CoT ordering improves generalization on longer sequential tasks.
Where Pith is reading between the lines
- Training pipelines could deliberately choose CoT granularity according to the amount of available data and tolerance for repetition.
- RL may function as a corrective step that recovers detail from shortcuts introduced by SFT on compressed traces.
- The observed ordering effect suggests testing whether forward-only traces also help on non-sequential reasoning problems.
- Datasets could be constructed with mixed CoT types to balance scaling benefits against memorization risks.
Load-bearing premise
The synthetic compositional reasoning task produces compression and generalization behaviors that transfer to the natural-language reasoning distributions used in real LLM post-training.
What would settle it
An experiment on a natural-language reasoning benchmark in which implicit CoT shows no greater memorization than explicit CoT, or in which RL fails to decompose SFT-learned compressions, would falsify the reported distinctions.
Figures










read the original abstract
Large language models (LLMs) can now solve complex problems through long chain-of-thought (CoT) reasoning, but the trade-off between performance and token cost remains a central challenge. To address this issue, supervised fine-tuning (SFT) often uses compressed reasoning data, where CoT traces are shortened into compact forms. However, the effect of such compressed reasoning data on post-training remains poorly understood. In this paper, we propose a taxonomy of CoT consisting of Explicit CoT, which outputs all operations without aggregation, Composed CoT, which combines multiple operations into a single step, and Implicit CoT, which omits intermediate operations. We construct a synthetic compositional reasoning task that allows controlled variation of difficulty, compression granularity, and data size, and conducted a comprehensive set of experiments across different model families and sizes. Notably, we find that (i) coarser CoT requires more SFT data, (ii) compared with Explicit CoT, Composed CoT and Implicit CoT benefit more from data scaling, while Composed CoT benefits from data repetition and Implicit CoT tends to lead to memorization, (iii) unlike SFT, subsequent reinforcement learning (RL) with verifiable rewards (RLVR) decomposes compressed steps learned during SFT, and (iv) unidirectional CoT ordering shows stronger generalization on longer sequential tasks. Our findings provide implications for CoT design under data resource constraints and offer important insights into the mechanisms of SFT and RL in LLM post-training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a taxonomy of chain-of-thought (CoT) reasoning into Explicit, Composed, and Implicit forms, then uses a synthetic compositional reasoning task with controlled variation in difficulty, compression granularity, and data volume to run SFT and RLVR experiments across multiple LLM families and sizes. It reports four main empirical patterns: coarser CoT requires more SFT data; Composed and Implicit CoT scale better with data volume than Explicit CoT; Composed CoT benefits from repetition while Implicit CoT risks memorization; RLVR tends to decompose compressed steps learned in SFT; and unidirectional ordering improves length generalization.
Significance. If the reported patterns are robust, the work supplies concrete, controlled evidence on how compression granularity interacts with data scaling, repetition, and the SFT-to-RL transition. The experimental design (explicit variation of difficulty/granularity/size, multi-model replication) is a strength and supports falsifiable claims about post-training mechanisms under resource constraints.
major comments (2)
- [Abstract and Conclusion] The manuscript's stated implications for CoT design in real LLM post-training rest on the assumption that compression and scaling behaviors observed on the synthetic compositional task transfer to natural-language reasoning distributions. No transfer experiments on standard reasoning benchmarks are reported, which is load-bearing for the broader claims in the abstract and conclusion.
- [Experimental Setup] §4 (Experimental Setup) and the task definition: the precise generation rules for Composed CoT (aggregation of operations) and Implicit CoT (omission of intermediates) are not stated with sufficient formality to allow independent replication or to evaluate how closely they match the distributional properties of natural-language CoT traces.
minor comments (2)
- [Figures] Figure captions and axis labels should explicitly state the number of runs and error bars used for each plotted point.
- [Methods] The distinction between 'data scaling' and 'data repetition' experiments should be clarified in the methods to avoid reader confusion about whether repetition means multiple epochs on the same examples.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract and Conclusion] The manuscript's stated implications for CoT design in real LLM post-training rest on the assumption that compression and scaling behaviors observed on the synthetic compositional task transfer to natural-language reasoning distributions. No transfer experiments on standard reasoning benchmarks are reported, which is load-bearing for the broader claims in the abstract and conclusion.
Authors: We agree that the broader implications would be strengthened by evidence of transfer to natural language tasks. However, the synthetic task was specifically designed to allow controlled experimentation on the effects of compression granularity, which is difficult to achieve with natural language data. We will revise the abstract and conclusion to emphasize that the findings are from the synthetic setting and discuss the potential implications for real-world post-training as hypotheses for future work. revision: partial
-
Referee: [Experimental Setup] §4 (Experimental Setup) and the task definition: the precise generation rules for Composed CoT (aggregation of operations) and Implicit CoT (omission of intermediates) are not stated with sufficient formality to allow independent replication or to evaluate how closely they match the distributional properties of natural-language CoT traces.
Authors: We appreciate this point and will provide more formal definitions in the revised manuscript. Specifically, we will include a detailed description of the generation process for each CoT type, including the rules for operation aggregation in Composed CoT and omission in Implicit CoT, using mathematical notation and examples to ensure replicability. revision: yes
Circularity Check
No circularity; purely experimental results on synthetic task
full rationale
The paper defines a taxonomy of CoT compression types and reports measured outcomes from controlled experiments on a synthetic compositional reasoning task. All four headline findings are obtained directly from performance metrics on held-out task variants under varying data sizes, repetition, and training stages (SFT then RLVR). No equations, parameter fits, or derivations are presented that reduce to their own inputs by construction, and no self-citations are invoked as load-bearing premises for uniqueness or ansatzes. The work is self-contained against its own experimental benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Training verifiers to solve math word prob- lems.arXiv preprint arXiv:2110.14168. Ganqu Cui, Yuchen Zhang, Jiacheng Chen, Lifan Yuan, Zhi Wang, Yuxin Zuo, Haozhan Li, Yuchen Fan, Huayu Chen, Weize Chen, Zhiyuan Liu, Hao Peng, Lei Bai, Wanli Ouyang, Yu Cheng, Bowen Zhou, and Ning Ding. 2025. The entropy mechanism of rein- forcement learning for reasoning l...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Implicit chain of thought reasoning via knowledge distillation
Implicit chain of thought reasoning via knowl- edge distillation.arXiv preprint arXiv:2311.01460. Yanrui Du, Sendong Zhao, Yibo Gao, Danyang Zhao, Qika Lin, Ming Ma, Jiayun Li, Yi Jiang, Kai He, Qianyi Xu, Bing Qin, and Mengling Feng. 2026. S3-CoT: Self-sampled succinct reasoning enables efficient Chain-of-Thought LLMs.arXiv preprint arXiv:2602.01982. Nou...
-
[3]
InSecond Conference on Language Modeling
Training large language models to reason in a continuous latent space. InSecond Conference on Language Modeling. Yinghui He, Abhishek Panigrahi, Yong Lin, and Sanjeev Arora. 2025. Skill-Targeted adaptive training.arXiv preprint arXiv:2510.10023. Xanh Ho, Anh-Khoa Duong Nguyen, Saku Sugawara, and Akiko Aizawa. 2020. Constructing a multi- hop QA dataset for...
-
[4]
The invisible leash: Why rlvr may or may not escape its origin, 2026
Reinforcement learning with verifiable re- wards implicitly incentivizes correct reasoning in base LLMs. InThe Fourteenth International Confer- ence on Learning Representations. Fang Wu, Weihao Xuan, Ximing Lu, Zaid Harchaoui, and Yejin Choi. 2025a. The invisible leash: Why rlvr may not escape its origin.arXiv preprint arXiv:2507.14843. Yifan Wu, Jingze S...
-
[5]
Back attention: Understanding and enhanc- ing multi-hop reasoning in large language models. InProceedings of the 2025 Conference on Empiri- cal Methods in Natural Language Processing, pages 11257–11272, Suzhou, China. Association for Com- putational Linguistics. Lifan Yuan, Weize Chen, Yuchen Zhang, Ganqu Cui, Hanbin Wang, Ziming You, Ning Ding, Zhiyuan L...
-
[6]
InProceedings of the 62nd Annual Meeting of the Association for Compu- tational Linguistics (Volume 3: System Demonstra- tions), Bangkok, Thailand
Llamafactory: Unified efficient fine-tuning of 100+ language models. InProceedings of the 62nd Annual Meeting of the Association for Compu- tational Linguistics (Volume 3: System Demonstra- tions), Bangkok, Thailand. Association for Computa- tional Linguistics. Yang Zhou, Hongyi Liu, Zhuoming Chen, Yuandong Tian, and Beidi Chen. 2025. GSM-$\infty$: How do...
2025
-
[7]
Define [parameter] as [variable]; so [variable] [op- eration] = [value]
and targeting skills (He et al., 2025), and self-distillation (Sprague et al., 2026). Yao et al. (2026) analyzed compositional generalization under distribution shift and Lippl et al. (2025) identified compositional geometry of algorithmic primitives. Recently, Yuan et al. (2026) and Cheng et al. (2026) investigated the effect of RL on compositional abili...
2025
-
[8]
The number of onions equals the number of boots times 3
The number of maples equals 1. The number of onions equals the number of boots times 3. The number of opals equals 3. The number of needles equals 4. The number of cats equals the number of celery times 4. What is the number of scarves? Explicit CoT. Example of Explicit CoT Define whelks as JK; so JK = 1. Define celery as FP; so FP = JK * 3 = 1 * 3 = 3. D...
-
[9]
Example of Composed CoT (g= 4) Define whelks as JK; so JK = 1
Answer: 18. Example of Composed CoT (g= 4) Define whelks as JK; so JK = 1. Define chairs as DP; so DP = JK * 3 * 4 * 2 - 1 = 1 * 3 * 4 * 2 - 1 = 0. Define scarves as TH; so TH = DP * 2 * 3 - 1 - 4 = 0 * 2 * 3 - 1 - 4 = 18. Answer : 18. Example of Composed CoT (g=8) Define whelks as JK; so JK = 1. Define scarves as TH; so TH = (JK * 3 * 4 * 2 - 1) * 2 * 3 ...
-
[10]
Define scarves as TH; so TH = 22 - 4 = 18
Define onions as MP; so MP = 0 * 3 = 0. Define scarves as TH; so TH = 22 - 4 = 18. Answer: 18. Example of Implicit CoT (g= 4) Define whelks as JK; so JK = 1. Define chairs as DP; so DP = 1 - 1 = 0. Define scarves as TH; so TH = 22 - 4 = 18. Answer: 18. Example of Implicit CoT (g=8) Define whelks as JK; so JK = 1. Define scarves as TH; so TH = 22 - 4 = 18....
2024
-
[11]
Table 1: SFT Configuration
implemented in the verl framework (Sheng et al., 2024), with hyperparameters listed in Ta- ble 2. Table 1: SFT Configuration. Component Setting Effective batch size 48 Optimizer AdamW Learning rate2.0×10 −5 Weight decay 0.1 Max gradient norm 1.0 Scheduler Cosine Warmup ratio 0.05 Minimum learning rate3.0×10 −6 Mixed precision bfloat16 Table 2: RLVR Config...
2024
-
[12]
Define aspens as YL; so YL = (YH - 1) * 3 = (21 - 1) * 3 = 14
Define markers as YH; so YH = YL * 4 * 3 = 19 * 4 * 3 = 21. Define aspens as YL; so YL = (YH - 1) * 3 = (21 - 1) * 3 = 14. Define wolves as YL; so YL = YL - 2 - 2 = 14 - 2 - 2 =
-
[13]
Answer: 12
Define YL + 2 = 10 + 2 = 12. Answer: 12. Qwen2.5-3B, Implicit CoT (g= 2) Define whelks as ZD; so ZD = 3. Define cats as ZF; so ZF = 4 + 4 = 8. Define chairs as ZU; so ZU = 9 * 2 = 18. Define onions as ZL; so ZL = 8 - 2 =
-
[14]
Define batons as ZY; so ZY = 15 + 2 = 17
Define scarves as ZC; so ZC = 18 * 2 = 13. Define batons as ZY; so ZY = 15 + 2 = 17. Define hats as ZN; so ZN = 5 + 1 = 6. Define maples as ZD; so ZD = 2 + 3 = 5. Define violets as ZF; so ZF = 15 * 2 = 7. Define flutes as ZD; so ZD = 21 * 2 = 19. Define markers as ZD; so ZD = 7 * 3 = 21. Define aspens as ZD; so ZD = 20 * 3 =
-
[15]
Define tokens as ZD; so ZD = 10 + 2 = 12
Define wolves as ZD; so ZD = 12 - 2 = 10. Define tokens as ZD; so ZD = 10 + 2 = 12. Answer: 12. Llama3.2-3B-Instruct, Composed CoT (g= 2) Define whelks as ZD; so ZD = 3. Define cats as ZT; so ZT = ZD + 1 + 4 = 3 + 1 + 4 = 8. Define chairs as ZQ; so ZQ = ZT * 4 * 2 = 8 * 4 * 2 = 18. Define onions as ZD; so ZD = ZQ * 3 - 2 = 18 * 3 - 2 = 6. Define scarves a...
-
[16]
Define aspens as ZD; so ZD = (ZT - 1) * 3 = (21 - 1) * 3 = 14
Define markers as ZT; so ZT = ZD * 4 * 3 = 19 * 4 * 3 = 21. Define aspens as ZD; so ZD = (ZT - 1) * 3 = (21 - 1) * 3 = 14. Define wolves as ZT; so ZT = ZD - 2 - 2 = 14 - 2 - 2 =
-
[17]
Answer: 12
Define tokens as ZD; so ZD = ZT * 1 + 2 = 10 * 1 + 2 = 12. Answer: 12. Llama3.2-3B-Instruct, Implicit CoT ( g= 2) Define whelks as ZD; so ZD = 3. Define cats as ZC; so ZC = 4 + 4 = 8. Define chairs as ZK; so ZK = 9 * 2 = 18. Define onions as ZU; so ZU = 8 - 2 =
-
[18]
Define batons as ZD; so ZD = 15 + 2 = 17
Define scarves as ZC; so ZC = 18 * 2 = 13. Define batons as ZD; so ZD = 15 + 2 = 17. Define hats as ZU; so ZU = 5 + 1 = 6. Define maples as ZC; so ZC = 2 + 3 = 5. Define violets as ZD; so ZD = 15 * 2 = 7. Define flutes as ZD; so ZD = 21 * 2 = 19. Define markers as ZD; so ZD = 7 * 3 = 21. Define aspens as ZD; so ZD = 20 * 3 =
-
[19]
Define tokens as ZD; so ZD = 10 + 2 = 12
Define wolves as ZD; so ZD = 12 - 2 = 10. Define tokens as ZD; so ZD = 10 + 2 = 12. Answer: 12. D.4 SFT Results on Different CoT Orders For Qwen2.5-3B and Llama-3.2-3B-Instruct, we consider Forward CoT, Backward CoT, and Hierar- chical CoT. We perform SFT on op= 8,16 tasks (≡0 (mod 8) ), varying the training dataset size among 6k, 24k, 96k, and 384k. Figu...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.