SiDP: Memory-Efficient Data Parallelism for Offline LLM Inference
Pith reviewed 2026-06-29 10:04 UTC · model grok-4.3
The pith
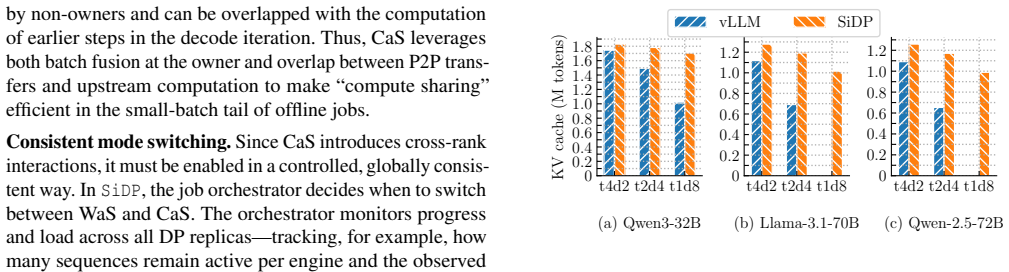
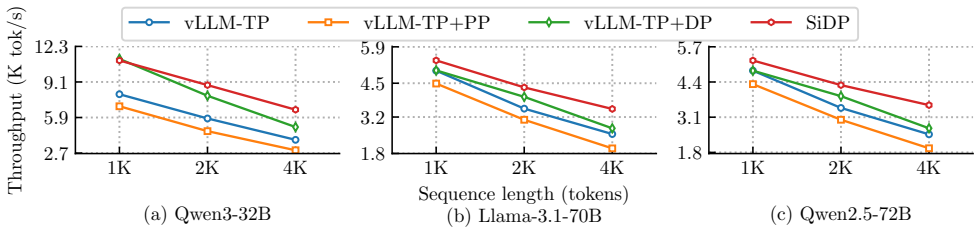
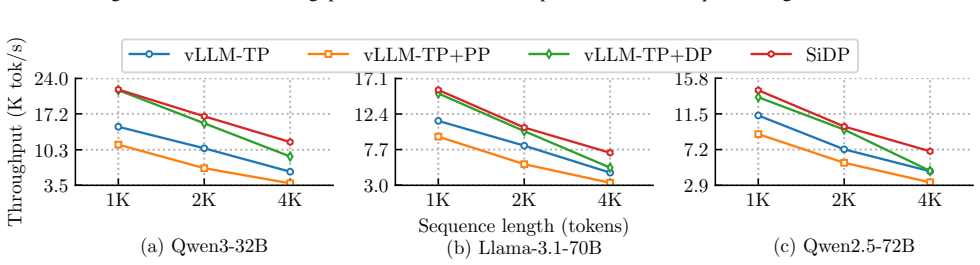
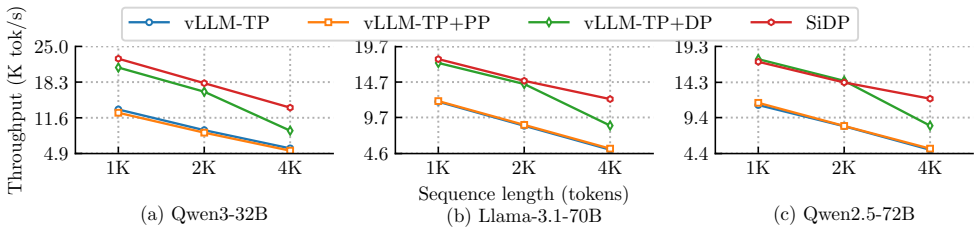
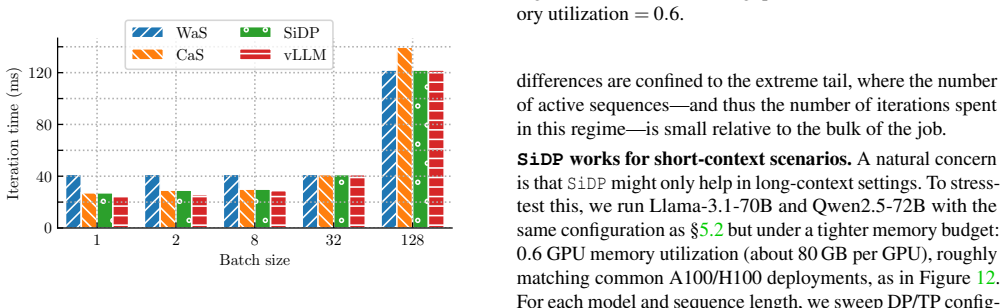
SiDP raises offline LLM throughput up to 1.5x by expanding usable KV cache 1.8x.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
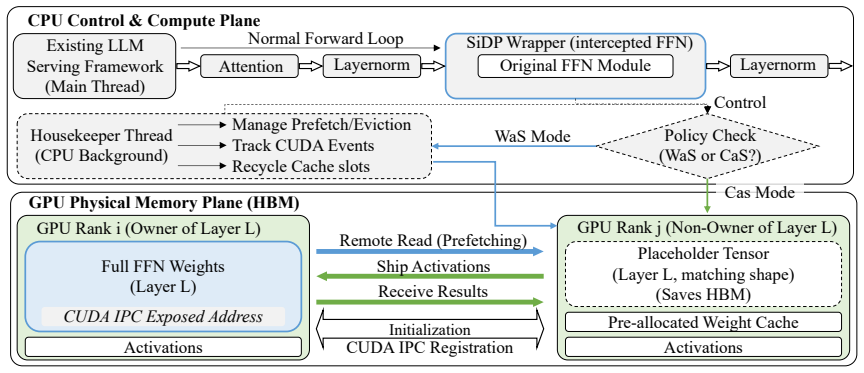
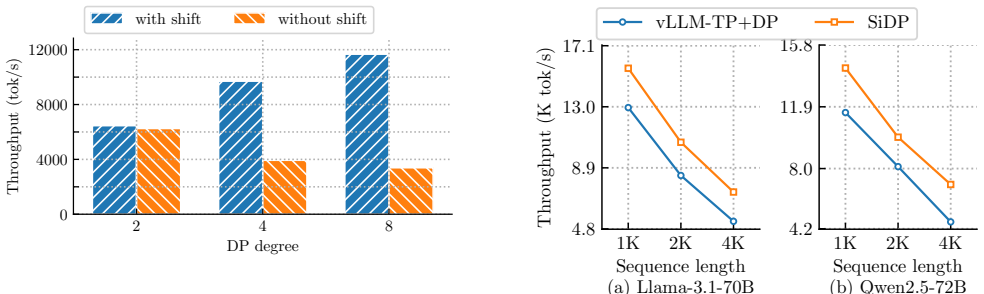
SiDP treats weights as a bandwidth-backed shared resource inside a DP group. Instead of storing the full model on every GPU, each layer is owned by a single GPU, and other replicas access its weights on demand via two complementary execution modes: a Weight-as-a-Service (WaS) mode that streams remote weights over NVLink into a small cache in the large-batch regime, and a Compute-as-a-Service (CaS) mode that ships activations to owners in the small-batch tail.
What carries the argument
The Weight-as-a-Service (WaS) and Compute-as-a-Service (CaS) modes that let replicas access distributed layer weights on demand without full replication.
If this is right
- SiDP increases usable KV capacity by up to 1.8x under the same configurations.
- This capacity increase converts into up to 1.5x higher end-to-end throughput over vLLM for offline workloads.
- SiDP preserves data parallelism's independence and scheduling flexibility while reducing per-device weight storage.
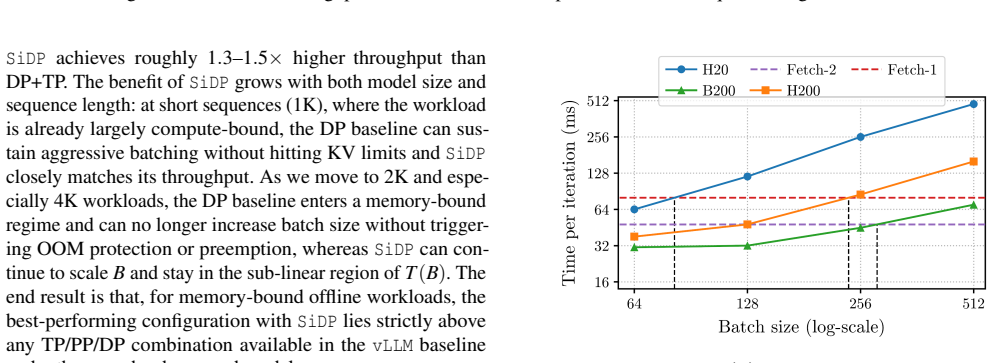
- The gains hold across Qwen3-32B, Qwen2.5-72B, and Llama-3.1-70B on H20, H200, and B200 GPUs.
Where Pith is reading between the lines
- If NVLink bandwidth becomes saturated at larger scales, the WaS mode may need fallback to selective replication of hot layers.
- The approach could extend to heterogeneous GPU clusters where slower interconnects make the CaS mode more attractive for certain batch sizes.
- Adapting the ownership and streaming logic to models with heavy mixture-of-experts routing would require tracking which experts are accessed most often.
Load-bearing premise
The communication overhead from streaming weights over NVLink or shipping activations remains low enough not to negate the throughput gains from larger batches.
What would settle it
A direct measurement of end-to-end throughput on the same GPUs and models where weight-streaming or activation-shipping time exceeds the time saved by processing the extra batch size enabled by the larger KV cache.
Figures




read the original abstract
The rapid adoption of large language models (LLMs) has shifted a substantial portion of inference workloads into throughput-oriented offline regimes, where fully utilizing GPU compute requires large batch sizes. However, existing deployments face a structural tension. Data parallelism (DP) scales throughput well but replicates model weights, leaving limited GPU memory for key-value (KV) cache and constraining batch size. Model parallelism reduces per-device weights, but requires fine-grained synchronization that erodes DP's independence and scheduling flexibility. We present SiDP, a memory-efficient data-parallel paradigm for offline LLM inference that treats weights as a bandwidth-backed shared resource inside a DP group. Instead of storing the full model on every GPU, SiDP organizes weights as a distributed pool: each layer is owned by a single GPU, and other replicas access its weights on demand via two complementary execution modes: a Weight-as-a-Service (WaS) mode that streams remote weights over NVLink into a small cache in the large-batch regime, and a Compute-as-a-Service (CaS) mode that ships activations to owners in the small-batch tail. Evaluated on NVIDIA H20, H200, and B200 GPUs with Qwen3-32B, Qwen2.5-72B, and Llama-3.1-70B, SiDP increases usable KV capacity by up to 1.8x under the same configurations, and converts this into up to 1.5x higher end-to-end throughput over baselines (vLLM) for offline workloads.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SiDP, a memory-efficient data-parallel paradigm for offline LLM inference. Instead of replicating full model weights on every GPU in a DP group, it organizes weights as a distributed pool where each layer is owned by one GPU; other replicas access them on demand via Weight-as-a-Service (WaS) mode (streaming weights over NVLink into a small cache for large batches) or Compute-as-a-Service (CaS) mode (shipping activations to weight owners for small-batch tails). Evaluated on H20/H200/B200 GPUs with Qwen3-32B, Qwen2.5-72B, and Llama-3.1-70B, it claims up to 1.8x usable KV capacity and 1.5x end-to-end throughput over vLLM baselines.
Significance. If the results hold under rigorous controls, SiDP would provide a practical middle ground between pure data parallelism and model parallelism for throughput-oriented offline inference, relaxing the KV-cache bottleneck while preserving DP scheduling flexibility. The empirical evaluation across three GPU generations and multiple model sizes is a positive feature; the approach also demonstrates concrete use of NVLink bandwidth to support weight sharing without full model parallelism.
major comments (1)
- [Evaluation] Evaluation section: the reported 1.8x KV-capacity and 1.5x throughput gains are presented without workload details (sequence lengths, batch-size distributions), exact vLLM baseline configurations, error bars or run counts, or direct measurements of NVLink/activation-shipping overhead in WaS and CaS modes. These omissions are load-bearing because the central claim rests on the premise that communication overhead remains low enough not to offset the batch-size gains; without the missing controls it is impossible to verify the numbers.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the evaluation. We agree that the current presentation of results lacks several key controls needed to fully substantiate the reported gains, and we will revise the manuscript to address these omissions directly.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: the reported 1.8x KV-capacity and 1.5x throughput gains are presented without workload details (sequence lengths, batch-size distributions), exact vLLM baseline configurations, error bars or run counts, or direct measurements of NVLink/activation-shipping overhead in WaS and CaS modes. These omissions are load-bearing because the central claim rests on the premise that communication overhead remains low enough not to offset the batch-size gains; without the missing controls it is impossible to verify the numbers.
Authors: We agree that these details are essential for verifying the claims. In the revised manuscript we will expand the evaluation section with: (1) explicit workload specifications including sequence length distributions and batch-size histograms for all reported experiments; (2) precise vLLM baseline configurations (version, tensor-parallel degree, scheduling parameters, and memory settings); (3) error bars and the number of runs (minimum 5) for all throughput and capacity measurements; and (4) direct instrumentation results for NVLink bandwidth utilization and activation-shipping latency in both WaS and CaS modes, shown as a function of batch size to demonstrate that communication overhead does not negate the KV-cache capacity benefits. These additions will be placed in a new subsection and accompanying figures/tables. revision: yes
Circularity Check
No significant circularity; empirical system evaluation
full rationale
The paper introduces SiDP as a systems technique (WaS/CaS modes for weight sharing in DP) and supports its claims exclusively via direct hardware measurements of KV capacity and end-to-end throughput on H20/H200/B200 GPUs with listed models. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. All performance numbers are reported as observed outcomes under the implemented modes, making the argument self-contained against external benchmarks rather than internally forced.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption NVLink provides sufficient bandwidth for on-demand weight streaming in the large-batch regime without becoming the dominant bottleneck
- domain assumption Workloads exhibit a batch-size distribution with a large-batch body and small-batch tail that the two modes can exploit complementarily
invented entities (2)
-
Weight-as-a-Service (WaS) mode
no independent evidence
-
Compute-as-a-Service (CaS) mode
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Taming throughput- latency tradeoff in llm inference with sarathi-serve
Amey Agrawal, Nitin Kedia, Ashish Panwar, Jayashree Mohan, Nipun Kwatra, Bhargav Gulavani, Alexey Tu- manov, and Ramachandran Ramjee. Taming throughput- latency tradeoff in llm inference with sarathi-serve. In 18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24), pages 117–134, Santa Clara, CA, July 2024. USENIX Association
2024
-
[2]
Evaluating large language models trained on code, 2021
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, et al. Evaluating large language models trained on code, 2021
2021
-
[3]
Kunserve: Elastic and efficient large language model serving with parameter- centric memory management.arXiv e-prints, pages arXiv–2412, 2024
Rongxin Cheng, Yifan Peng, Yuxin Lai, Xingda Wei, Rong Chen, and Haibo Chen. Kunserve: Elastic and efficient large language model serving with parameter- centric memory management.arXiv e-prints, pages arXiv–2412, 2024
2024
-
[4]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. The Llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Jingzhi Fang, Yanyan Shen, Yue Wang, and Lei Chen. Improving the end-to-end efficiency of offline inference for multi-llm applications based on sampling and simu- lation.arXiv preprint arXiv:2503.16893, 2025
-
[6]
Model tells you what to discard: Adaptive KV cache compression for LLMs
Suyu Ge, Yunan Zhang, Liyuan Liu, Minjia Zhang, Ji- awei Han, and Jianfeng Gao. Model tells you what to discard: Adaptive KV cache compression for LLMs. In International Conference on Learning Representations (ICLR), 2024. 12
2024
-
[7]
Glinthawk: A two-tiered architecture for offline llm inference.arXiv preprint arXiv:2501.11779, 2025
Pouya Hamadanian and Sadjad Fouladi. Glinthawk: A two-tiered architecture for offline llm inference.arXiv preprint arXiv:2501.11779, 2025
-
[8]
Deferred continuous batching in resource-efficient large language model serving
Yongjun He, Yao Lu, and Gustavo Alonso. Deferred continuous batching in resource-efficient large language model serving. InProceedings of the 4th Workshop on Machine Learning and Systems, pages 98–106, 2024
2024
-
[9]
Measuring Massive Multitask Language Understanding
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Ja- cob Steinhardt. Measuring massive multitask language understanding.arXiv preprint arXiv:2009.03300, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[10]
OpenRLHF: An Easy-to-use, Scalable and High-performance RLHF Framework
Jian Hu, Xibin Wu, Zilin Zhu, Xianyu, Weixun Wang, Dehao Zhang, and Yu Cao. Openrlhf: An easy-to-use, scalable and high-performance rlhf framework.arXiv preprint arXiv:2405.11143, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Dense passage retrieval for open-domain question answering
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. Dense passage retrieval for open-domain question answering. InProceedings of the 2020 Con- ference on Empirical Methods in Natural Language Processing (EMNLP), pages 6769–6781. Association for Computational Linguistics, 2020
2020
-
[12]
MT-eval: A multi-turn capabilities evaluation benchmark for large language models
Wai-Chung Kwan, Xingshan Zeng, Yuxin Jiang, Yufei Wang, Liangyou Li, Lifeng Shang, Xin Jiang, Qun Liu, and Kam-Fai Wong. MT-eval: A multi-turn capabilities evaluation benchmark for large language models. InPro- ceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 20153–20177, Miami, Florida, USA, 2024. Association for...
2024
-
[13]
Efficient memory man- agement for large language model serving with page- dattention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory man- agement for large language model serving with page- dattention. InProceedings of the 29th Symposium on Operating Systems Principles, pages 611–626, 2023
2023
-
[14]
John, and Neeraja J
Ruihao Li, Shagnik Pal, Vineeth Narayan Pullu, Pra- soon Sinha, Jeeho Ryoo, Lizy K. John, and Neeraja J. Yadwadkar. Oneiros: Kv cache optimization through parameter remapping for multi-tenant LLM serving. In Proceedings of the ACM Symposium on Cloud Comput- ing (SoCC ’25), 2025
2025
-
[15]
Holistic Evaluation of Language Models
Percy Liang, Rishi Bommasani, Tony Lee, Dimitris Tsipras, Giannis Daras, Deep Ganguli, Dario Amodei Hernandez, et al. Holistic evaluation of language models. arXiv preprint arXiv:2211.09110, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[16]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3 techni- cal report.arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Deepspeed, 2024
Microsoft. Deepspeed, 2024. https://github.com /microsoft/DeepSpeed
2024
-
[18]
Training language models to follow instructions with human feedback.Advances in Neural Information Pro- cessing Systems, 35:27730–27744, 2022
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in Neural Information Pro- cessing Systems, 35:27730–27744, 2022
2022
-
[19]
The carbon footprint of machine learning training will plateau, then shrink.Computer, 55(7):18–28, 2022
David Patterson, Joseph Gonzalez, Urs Hölzle, Quoc Le, Chen Liang, Lluis-Miquel Munguia, Daniel Rothchild, David R So, Maud Texier, and Jeff Dean. The carbon footprint of machine learning training will plateau, then shrink.Computer, 55(7):18–28, 2022
2022
-
[20]
Zero: Memory optimizations toward train- ing trillion parameter models
Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He. Zero: Memory optimizations toward train- ing trillion parameter models. InSC20: International Conference for High Performance Computing, Network- ing, Storage and Analysis, pages 1–16. IEEE, 2020
2020
-
[21]
Zero-offload : Democ- ratizing billion-scale model training
Jie Ren, Samyam Rajbhandari, Reza Yazdani Am- inabadi, Olatunji Ruwase, Shuangyan Yang, Minjia Zhang, Dong Li, and Yuxiong He. Zero-offload : Democ- ratizing billion-scale model training. In2021 USENIX Annual Technical Conference (USENIX ATC 21), pages 551–564, 2021
2021
-
[22]
Recipes for building an open-domain chatbot
Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric Michael Smith, Y-Lan Boureau, and Jason Weston. Recipes for building an open-domain chatbot. Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguis- tics: Main Volume, pages 300–325, 2021
2021
-
[23]
Liu, and Christopher D
Abigail See, Peter J. Liu, and Christopher D. Manning. Get to the point: Summarization with pointer-generator networks. InProceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1073–1083, Vancouver, Canada,
-
[24]
Association for Computational Linguistics
-
[25]
Ying Sheng, Lianmin Li, Lianmin Zheng, et al. Flexgen: High-throughput generative inference of large language models with a single GPU.CoRR, abs/2303.06865, 2023
-
[26]
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. Megatron-lm: Training multi-billion parameter lan- guage models using model parallelism.arXiv preprint arXiv:1909.08053, 2019. 13
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[27]
Gemma: Open Models Based on Gemini Research and Technology
Gemma Team. Gemma: Open models based on gemini research and technology.CoRR, abs/2403.08295, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
2017
-
[29]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Guanzhi Wang, Yuqi Zhang, Hao Zhang, Haoyi Xu, Yu- tong Yang, Yuxiao Dong, Ziwei Liu, Yixin Wang, et al. V oyager: An open-ended embodied agent with large lan- guage models.arXiv preprint arXiv:2305.16291, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
Self-Instruct: Aligning Language Models with Self-Generated Instructions
Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Pe- gah Alipoormolabashi, Amirreza Mirzaei, Atharva Naik, Arjun Ashok, et al. Self-instruct: Aligning language models with self-generated instructions.arXiv preprint arXiv:2212.10560, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[31]
Pie: Pooling CPU memory for LLM inference
Yi Xu, Ziming Mao, Xiangxi Mo, Shu Liu, and Ion Sto- ica. Pie: Pooling CPU memory for LLM inference. abs/2411.09317, 2024
-
[32]
An Yang et al. Qwen2.5 technical report.CoRR, abs/2412.15115, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
An Yang, Baosong Yang, and et al. Zhi- wei Zhang. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Orca: A distributed serving system for transformer-based generative mod- els
Gyeong-In Yu, Joo Seong Jeong, Geon-Woo Kim, Soo- jeong Kim, and Byung-Gon Chun. Orca: A distributed serving system for transformer-based generative mod- els. In16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 22), pages 521–538, 2022
2022
-
[35]
Hongbin Zhang, Taosheng Wei, Zhenyi Zheng, Jiangsu Du, Zhiguang Chen, and Yutong Lu. TD-pipe: Temporally-disaggregated pipeline parallelism architec- ture for high-throughput llm inference.arXiv preprint arXiv:2506.10470, 2025
-
[36]
PyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel
Yanli Zhao, Andrew Gu, Rohan Varma, Liang Luo, Chien-Chin Huang, Min Xu, Less Wright, Hamid Sho- janazeri, Myle Ott, Sam Shleifer, et al. Pytorch FSDP: experiences on scaling fully sharded data parallel.arXiv preprint arXiv:2304.11277, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[37]
Yilong Zhao, Shuo Yang, Kan Zhu, Lianmin Zheng, Baris Kasikci, Yang Zhou, Jiarong Xing, and Ion Sto- ica. Blendserve: Optimizing offline inference for auto- regressive large models with resource-aware batching. arXiv preprint arXiv:2411.16102, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
SGLang: Efficient Execution of Structured Language Model Programs
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E Gonzalez, et al. Sglang: Efficient execution of structured language model pro- grams.arXiv preprint arXiv:2312.07104, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
Zhen Zheng, Xin Ji, Taosong Fang, Fanghao Zhou, Chuanjie Liu, and Gang Peng. Batchllm: Optimizing large batched llm inference with global prefix sharing and throughput-oriented token batching.arXiv preprint arXiv:2412.03594, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[40]
Yinmin Zhong, Zili Zhang, Xiaoniu Song, Hanpeng Hu, Chao Jin, Bingyang Wu, Nuo Chen, Yukun Chen, Yu Zhou, Changyi Wan, Hongyu Zhou, Yimin Jiang, Yibo Zhu, and Daxin Jiang. StreamRL: Scalable, hetero- geneous, and elastic RL for LLMs with disaggregated stream generation.arXiv preprint arXiv:2504.15930, 2025
-
[41]
RLHFuse: Effi- cient rlhf training for large language models with inter- and intra-stage fusion
Yinmin Zhong, Zili Zhang, Bingyang Wu, Shengyu Liu, Yukun Chen, Changyi Wan, Hanpeng Hu, Lei Xia, Ranchen Ming, Yibo Zhu, and Xin Jin. RLHFuse: Effi- cient rlhf training for large language models with inter- and intra-stage fusion. InUSENIX Symposium on Net- worked Systems Design and Implementation (NSDI),
- [42]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.