Which Pretraining Paradigm Better Serves Spatial Intelligence? An Empirical Comparison of Vision-Language and Video Generation Models
Pith reviewed 2026-06-29 13:47 UTC · model grok-4.3
The pith
Vision-language models capture semantics better while video generation models capture geometry better, with their simple combination outperforming either alone on both.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
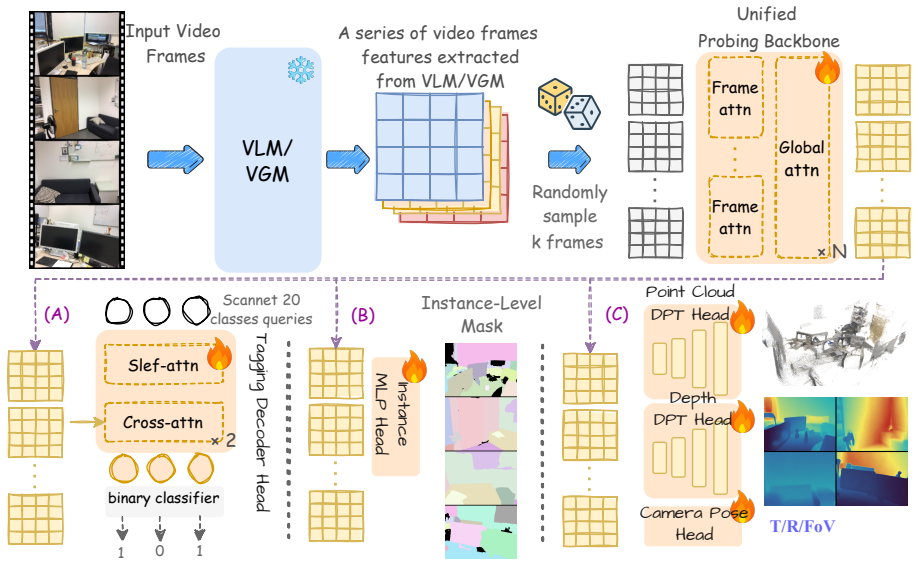
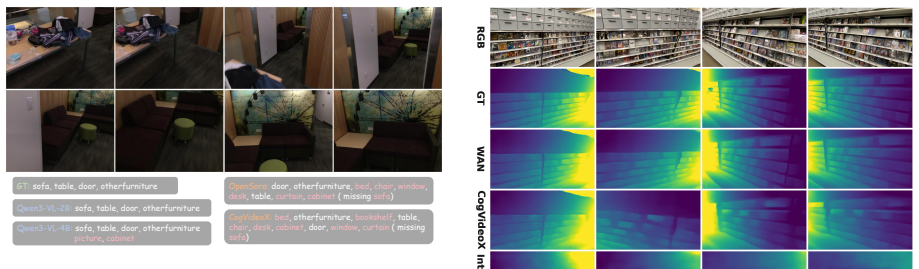
The paper claims that vision-language models are stronger at semantic tagging and instance grouping, while video generation models provide more accessible signals for dense geometry and camera motion. Moreover, a naive fusion of the two already yields a representation that excels at both geometry and semantics. This is shown through controlled frozen-feature probing that directly compares what each pretraining family encodes without further adaptation.
What carries the argument
The lightweight frozen-feature probe applied uniformly to representations from both model families on the three axes of semantic tagging, instance grouping, and 3D geometry prediction.
If this is right
- Vision-language and video generation pretraining encode complementary information for spatial tasks.
- A combined representation from both families already performs well on both semantic and geometric axes.
- Spatial intelligence backbones can be strengthened by integrating features from language supervision and temporal video modeling.
- The probe method allows direct measurement of what each pretraining scheme already encodes before any task-specific training.
Where Pith is reading between the lines
- The observed complementarity could guide construction of hybrid models that feed both types of features into downstream spatial reasoning systems such as navigation or manipulation.
- More advanced fusion techniques might extract even stronger joint representations than the naive combination tested here.
- Purely one-sided pretraining may leave gaps in world understanding that only appear when models must handle both object identity and precise layout simultaneously.
Load-bearing premise
The lightweight frozen-feature probe accurately reveals the information relevant to spatial intelligence without requiring task-specific fine-tuning or additional adaptation of the backbone models.
What would settle it
An experiment that fine-tunes both model families on the same spatial tasks and finds the relative ordering of their strengths reverses would show the frozen probe missed key capabilities.
Figures




read the original abstract
Spatial intelligence requires visual representations that capture both semantic objects and geometric structure in the physical world. To support this, two major pre-training schemes are now widely used as foundation backbones: Vision-Language Models (VLMs), which use language supervision to align visual observations with semantic concepts, and Video Generation Models (VGMs), which learn from temporally evolving visual worlds. However, it still remains unclear which pre-training scheme provides a better representation substrate for spatial intelligence. In this paper, we present the first systematic frozen-feature probing study of VLMs and VGMs across three representative axes of spatial intelligence: semantic tagging, instance grouping, and 3D geometry prediction. Using the lightweight probe, our framework enables a controlled comparison of what information is already encoded in frozen representations from two model families. Experimental results reveal a clear complementarity: VLMs are stronger at semantic tagging and instance grouping, while VGMs provide more accessible signals for dense geometry and camera motion. Moreover, a naive fusion of the two already yields a representation that excels at both geometry and semantics, suggesting a promising direction for building stronger spatial-intelligence backbones by effectively integrating features from both model families. Our code is available at \href{https://github.com/om-ai-lab/Probing-VLM-VGM}{https://github.com/om-ai-lab/Probing-VLM-VGM}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts a systematic frozen-feature probing study comparing Vision-Language Models (VLMs) and Video Generation Models (VGMs) on three axes of spatial intelligence—semantic tagging, instance grouping, and 3D geometry prediction—concluding that VLMs are stronger on semantic tasks, VGMs on dense geometry and camera motion, and that a naive fusion of their features yields representations excelling at both.
Significance. If the probe-based results hold under scrutiny, the work provides a useful empirical map of complementary strengths between language-supervised and video-generation pretraining for spatial tasks, with the public code release enabling direct reproduction and extension. This could inform design of hybrid backbones, though the significance is tempered by dependence on the specific probing setup.
major comments (2)
- [Abstract (probing framework) and experimental sections] The central claims of complementarity and fusion benefits rest entirely on results from a single lightweight frozen-feature probe (as stated in the abstract). The manuscript does not include controls or ablations showing that this probe suffices to surface all encoded information; if relevant geometric or semantic signals require non-linear adaptation, deeper mixing, or task-specific fine-tuning to become accessible, the observed gaps and fusion gains could be artifacts of probe choice rather than intrinsic properties of the representations. This assumption is load-bearing for the framing that the study reveals 'what information is already encoded in frozen representations.'
- [Methodology and results sections] The abstract and framing tie conclusions directly to the lightweight probe without reporting comparisons to alternative probes (e.g., linear vs. MLP heads, or partial fine-tuning baselines) that would test robustness of the VLM-vs-VGM ranking. Without such checks, it is unclear whether the complementarity finding generalizes beyond the chosen probe architecture.
minor comments (2)
- [Abstract] The abstract supplies no details on the specific models, datasets, probe architectures, or statistical tests used; while the full manuscript presumably contains these, the high-level summary would benefit from a sentence listing the model families and task datasets for immediate context.
- [Abstract] The term 'naive fusion' is used without a precise definition or diagram in the provided abstract; a short methods paragraph clarifying the fusion operation (e.g., concatenation, averaging) would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback on our probing study. We address the two major comments below regarding the choice and sufficiency of the lightweight frozen-feature probe.
read point-by-point responses
-
Referee: [Abstract (probing framework) and experimental sections] The central claims of complementarity and fusion benefits rest entirely on results from a single lightweight frozen-feature probe (as stated in the abstract). The manuscript does not include controls or ablations showing that this probe suffices to surface all encoded information; if relevant geometric or semantic signals require non-linear adaptation, deeper mixing, or task-specific fine-tuning to become accessible, the observed gaps and fusion gains could be artifacts of probe choice rather than intrinsic properties of the representations. This assumption is load-bearing for the framing that the study reveals 'what information is already encoded in frozen representations.'
Authors: We appreciate the referee's emphasis on this point. Our study is explicitly framed as a frozen-feature probing analysis using a lightweight probe precisely to isolate what information is directly accessible from the pretrained representations without adaptation or task-specific tuning; this is a deliberate methodological choice to enable controlled, apples-to-apples comparison across model families. While we acknowledge that more expressive probes could surface additional signals, the consistent trends we observe under this standard lightweight setup already demonstrate clear differences in accessibility between VLMs and VGMs. We will revise the abstract, introduction, and discussion to more explicitly delimit the scope to 'information accessible via lightweight probing' and note this as a limitation. revision: yes
-
Referee: [Methodology and results sections] The abstract and framing tie conclusions directly to the lightweight probe without reporting comparisons to alternative probes (e.g., linear vs. MLP heads, or partial fine-tuning baselines) that would test robustness of the VLM-vs-VGM ranking. Without such checks, it is unclear whether the complementarity finding generalizes beyond the chosen probe architecture.
Authors: The referee correctly notes the absence of such robustness checks. Our design prioritizes a single, fixed lightweight probe architecture to maintain strict control and fairness when comparing representations across dozens of models; varying the probe would introduce confounding factors that complicate attribution to the pretraining paradigm. Nevertheless, to address the concern we will add a limited set of experiments using an MLP probe head in the revised manuscript and report whether the main VLM-vs-VGM ranking and fusion benefits remain consistent. revision: partial
Circularity Check
No circularity: direct empirical comparison with no derivations or fitted predictions
full rationale
The paper performs a controlled empirical study comparing frozen features from VLMs and VGMs via lightweight probes on semantic tagging, instance grouping, and 3D geometry tasks. No equations, parameter fitting, self-referential predictions, or derivation chains exist. Claims of complementarity rest on observed probe accuracies, not on any reduction to inputs by construction. Self-citations are absent from load-bearing positions. The study is self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The three axes (semantic tagging, instance grouping, 3D geometry prediction) are representative of spatial intelligence.
Reference graph
Works this paper leans on
-
[1]
Arkitscenes: A diverse real-world dataset for 3d indoor scene understanding using mobile rgb-d data.arXiv preprint arXiv:2111.08897. Zhongang Cai, Ruisi Wang, Chenyang Gu, Fanyi Pu, Junxiang Xu, Yubo Wang, Wanqi Yin, Zhitao Yang, Chen Wei, Qingping Sun, Tongxi Zhou, Jiaqi Li, Hui En Pang, Oscar Qian, Yukun Wei, Zhiqian Lin, Xuanke Shi, Kewang Deng, Xiaoya...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
Scannet: Richly-annotated 3d reconstructions of indoor scenes. InProceedings of the IEEE con- ference on computer vision and pattern recognition, pages 5828–5839. Abhishek Das, Samyak Datta, Georgia Gkioxari, Stefan Lee, Devi Parikh, and Dhruv Batra. 2018. Embodied question answering. InProceedings of the IEEE con- ference on computer vision and pattern r...
-
[3]
Zeju Li, Chao Zhang, Xiaoyan Wang, Ruilong Ren, Yifan Xu, Ruifei Ma, Xiangde Liu, and Rong Wei
Iggt: Instance-grounded geometry trans- former for semantic 3d reconstruction.arXiv preprint arXiv:2510.22706. Zeju Li, Chao Zhang, Xiaoyan Wang, Ruilong Ren, Yifan Xu, Ruifei Ma, Xiangde Liu, and Rong Wei. 2024a. 3dmit: 3d multi-modal instruction tuning for scene understanding. In2024 IEEE Interna- tional Conference on Multimedia and Expo Work- shops (IC...
-
[4]
hdbscan: Hierarchical density based clustering. J. Open Source Softw., 2(11):205. Zhenyu Pan and Han Liu. 2025. Metaspatial: Reinforc- ing 3d spatial reasoning in vlms for the metaverse. arXiv preprint arXiv:2503.18470. Yanyuan Qiao, Haodong Hong, Wenqi Lyu, Dong An, Siqi Zhang, Yutong Xie, Xinyu Wang, and Qi Wu
-
[5]
MotuBrain: An Advanced World Action Model for Robot Control
Navbench: Probing multimodal large language models for embodied navigation. InNeurIPS. Tal Ridnik, Emanuel Ben-Baruch, Nadav Zamir, Asaf Noy, Itamar Friedman, Matan Protter, and Lihi Zelnik-Manor. 2021. Asymmetric loss for multi- label classification. InProceedings of the IEEE/CVF international conference on computer vision, pages 82–91. Chonghao Sima, Ka...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[6]
Open-Sora 2.0: Training a Commercial-Level Video Generation Model in $200k
Open-sora 2.0: Training a commercial-level video generation model in $200 k.arXiv preprint arXiv:2503.09642. Xingcheng Zhou, Xuyuan Han, Feng Yang, Yunpu Ma, V olker Tresp, and Alois Knoll. 2025. Open- drivevla: Towards end-to-end autonomous driving with large vision language action model.Preprint, arXiv:2503.23463. Haoyi Zhu, , Honghui Yang, Yating Wang,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
VGM features are spatially pooled to a fixed grid when needed: WAN/OpenSora use 15×26 , and CogVideoX/Aether use 15×22 ; VLM features keep their native visual-token grids
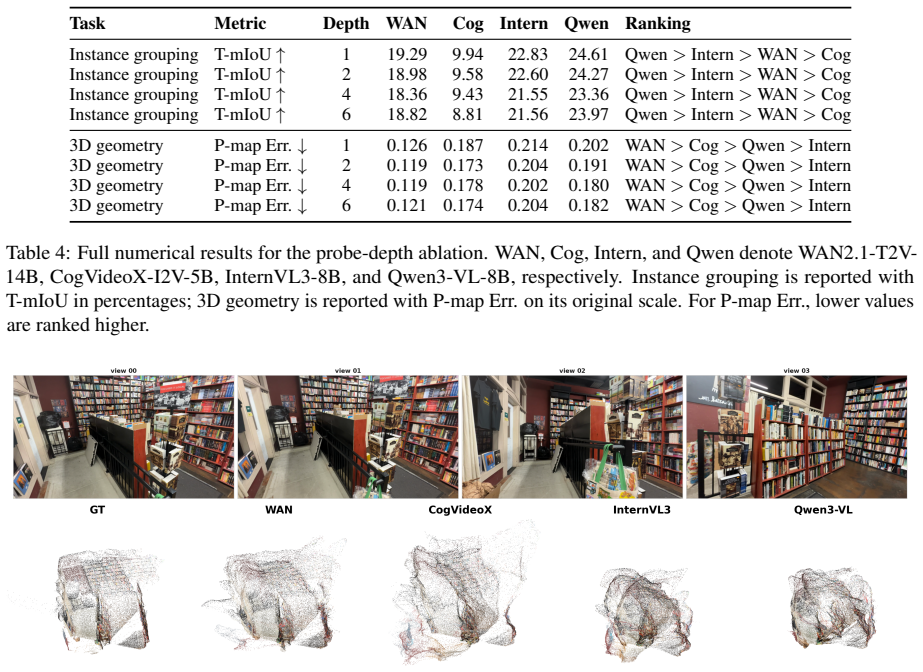
All tasks use the same 76-frame context con- struction; semantic and instance probes sample 8 frames, while geometry probes sample 4 frames. VGM features are spatially pooled to a fixed grid when needed: WAN/OpenSora use 15×26 , and CogVideoX/Aether use 15×22 ; VLM features keep their native visual-token grids. D Probe-Depth Ablation Details Table 4 provi...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.