Deconstructing Spatial Complexity: Hierarchical Decomposition for LLM Spatial Reasoning
Pith reviewed 2026-06-29 12:56 UTC · model grok-4.3
The pith
Hierarchical decomposition guided by a modified search algorithm lets LLMs select better intermediate states for spatial tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
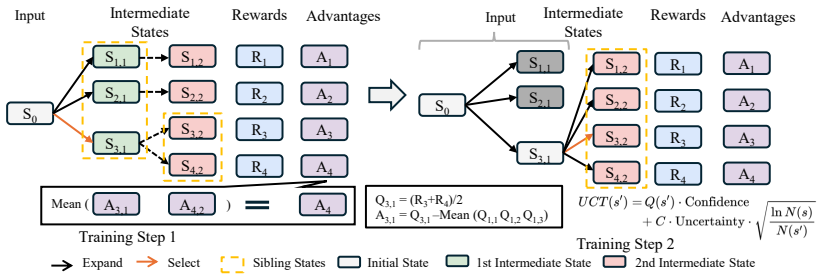
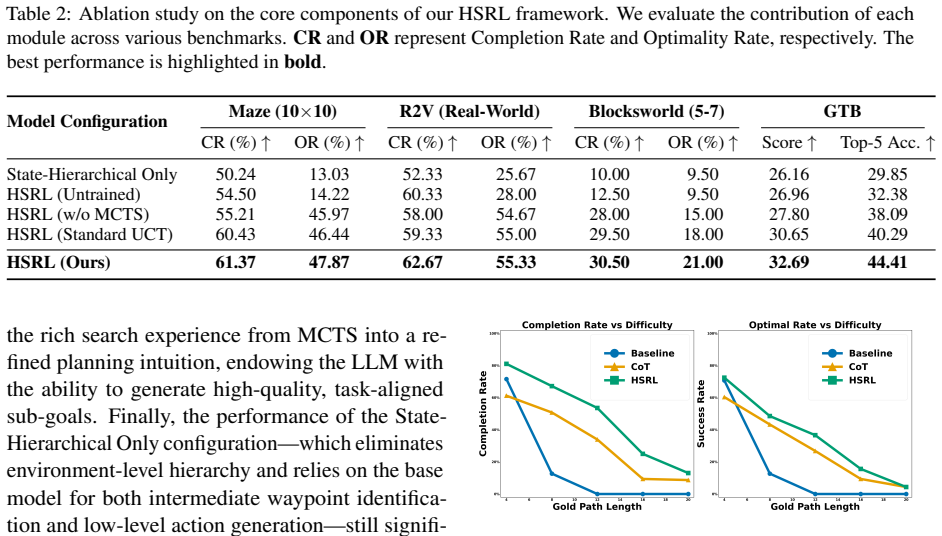
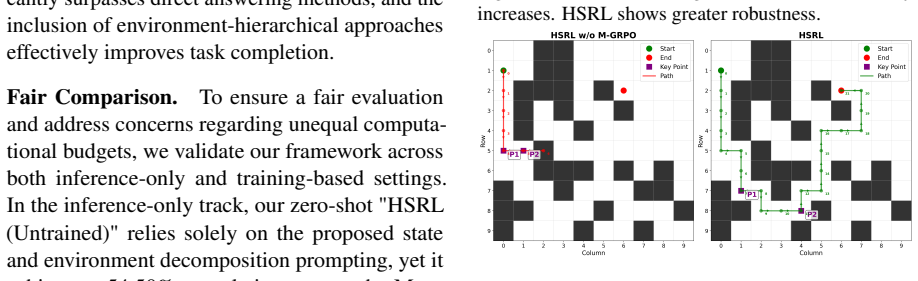
The paper claims that LLMs fail to find optimal intermediate states for task decomposition due to weak spatial priors, and that reformulating the UCT formula inside MCTS-Guided Group Relative Policy Optimization to include the model's prior predictive probabilities together with its epistemic uncertainty, plus a finer-grained advantage function, enables the model to learn better path planning and yields state-of-the-art performance on spatial reasoning tasks.
What carries the argument
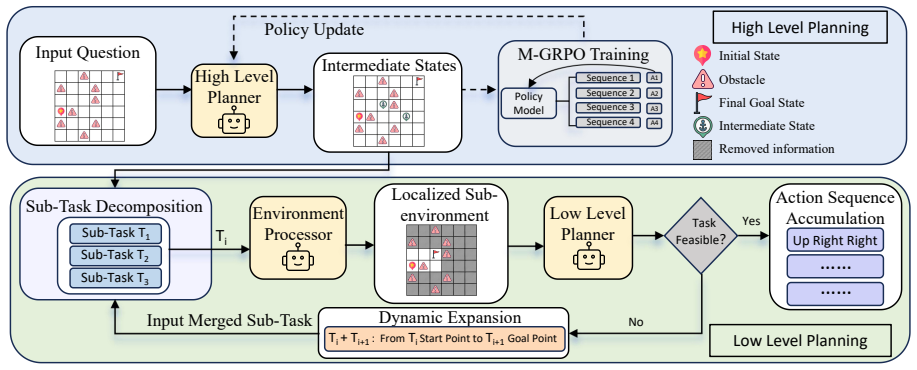
MCTS-Guided Group Relative Policy Optimization (M-GRPO), which modifies the UCT selection formula to blend LLM prior probabilities with epistemic uncertainty and applies a fine-grained advantage function to train optimal hierarchical decompositions.
If this is right
- LLMs achieve stronger results on navigation tasks through more effective choice of intermediate states.
- Planning in complex spatial environments improves because the model learns better sequences of sub-tasks.
- Performance on strategic games reaches state-of-the-art levels from the refined optimization loop.
- The method supports progress toward real-world embodied intelligence applications that require spatial reasoning.
Where Pith is reading between the lines
- The same prior-and-uncertainty adjustment might transfer to non-spatial reasoning tasks that rely on sequential decomposition.
- Testing the method on models of different sizes would show whether the uncertainty term remains useful at larger scales.
- Deployment on physical robots would reveal whether simulated gains hold when sensor noise and continuous space replace discrete environments.
Load-bearing premise
That LLMs choose poor intermediate states mainly from insufficient spatial prior knowledge, and that inserting their predictive probabilities and uncertainty into the UCT formula will produce optimal path planning.
What would settle it
An experiment showing that M-GRPO produces no measurable gain over standard hierarchical decomposition on the same navigation, planning, and game benchmarks would falsify the central claim.
Figures

read the original abstract
LLMs have shown remarkable proficiency in general language understanding and reasoning. However, they consistently underperform in spatial reasoning that severely limits their application, particularly in embodied intelligence. Inspired by the success of hierarchical reinforcement learning, this paper introduces a novel method for hierarchical task decomposition in LLM spatial reasoning. Our approach guides LLMs to decompose complex tasks into manageable sub-tasks by identifying key intermediate states and generating simplified sub-environments. However, we identify that LLMs often fail to derive optimal intermediate states due to their insufficient spatial prior, leading to sub-optimal task decomposition. To address this limitation and enhance its planning capability, we propose the MCTS-Guided Group Relative Policy Optimization (M-GRPO), where we reformulate the UCT formula by incorporating the LLM's prior predictive probabilities alongside its epistemic uncertainty. Furthermore, we implement a more fine-grained advantage function, enabling the model to learn optimal path planning. Experimental results demonstrate that our method substantially improves LLM performance on spatial tasks, including navigation, planning, and strategic games, achieving state-of-the-art results. This work paves the way for LLMs in real-world applications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a hierarchical task decomposition method for LLM spatial reasoning, inspired by hierarchical RL. It identifies that LLMs struggle with optimal intermediate states due to insufficient spatial priors and proposes M-GRPO, which reformulates the UCT formula to incorporate the LLM's prior predictive probabilities and epistemic uncertainty, plus a fine-grained advantage function for path planning. The central claim is that this yields substantial improvements and state-of-the-art results on navigation, planning, and strategic games.
Significance. If the experimental claims hold with proper validation, the work could meaningfully advance LLM capabilities in embodied intelligence by bridging spatial reasoning gaps via MCTS-guided policy optimization. The hierarchical decomposition idea aligns with known RL successes, but the absence of any quantitative results, baselines, or derivations in the provided material makes it impossible to gauge actual impact or novelty.
major comments (2)
- Abstract: The claim that the method 'achieves state-of-the-art results' on spatial tasks is load-bearing for the contribution yet is stated without any data, baselines, ablation tables, error bars, or statistical tests, rendering the central experimental assertion unverifiable from the manuscript.
- Method description: The reformulation of the UCT formula using LLM prior predictive probabilities and epistemic uncertainty is presented at a conceptual level with no explicit equation, derivation, or pseudocode, which is required to evaluate whether the modification is well-defined, non-circular, or an improvement over standard UCT.
minor comments (1)
- The abstract and method overview use terms such as 'epistemic uncertainty' and 'fine-grained advantage function' without initial definitions or references to standard formulations, which could be clarified for readers unfamiliar with the intersection of MCTS and LLM fine-tuning.
Simulated Author's Rebuttal
We thank the referee for the careful review and constructive feedback. The comments highlight important gaps in verifiability and formal detail that we will address through revision.
read point-by-point responses
-
Referee: Abstract: The claim that the method 'achieves state-of-the-art results' on spatial tasks is load-bearing for the contribution yet is stated without any data, baselines, ablation tables, error bars, or statistical tests, rendering the central experimental assertion unverifiable from the manuscript.
Authors: We agree that the SOTA claim in the abstract cannot be evaluated without supporting evidence. The current manuscript version lacks the experimental results, baselines, ablations, error bars, and statistical tests, making the assertion unverifiable as noted. We will revise by adding a full experimental section with quantitative results on navigation, planning, and games (including tables, baselines, and statistical analysis) and will update the abstract to either include summary metrics or qualify the claim until the data is presented. revision: yes
-
Referee: Method description: The reformulation of the UCT formula using LLM prior predictive probabilities and epistemic uncertainty is presented at a conceptual level with no explicit equation, derivation, or pseudocode, which is required to evaluate whether the modification is well-defined, non-circular, or an improvement over standard UCT.
Authors: We agree that the reformulation must be presented formally rather than conceptually. The manuscript currently describes M-GRPO at a high level without the explicit modified UCT equation, its derivation, or pseudocode. In revision we will insert the precise mathematical reformulation of the UCT formula that incorporates the LLM's prior predictive probabilities and epistemic uncertainty, provide a step-by-step derivation showing it is well-defined and non-circular, and add algorithm pseudocode for M-GRPO and the fine-grained advantage function. revision: yes
Circularity Check
No significant circularity detected
full rationale
The abstract and available description present a high-level method (M-GRPO with UCT reformulation) but contain no equations, derivations, or self-referential steps. No load-bearing claim reduces by construction to fitted inputs, self-citations, or renamed results. The central claim is experimental improvement on spatial tasks; without visible derivation chain or parameter-fitting details that equate prediction to input, the paper is self-contained against external benchmarks. This matches the default expectation for most papers and the reader's note on absence of assessable equations.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Understanding R1-Zero-Like Training: A Critical Perspective
Understanding r1-zero-like training: A critical perspective.Preprint, arXiv:2503.20783. Xinyang Lu, Flint Xiaofeng Fan, and Tianying Wang
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
arXiv preprint arXiv:2405.06682 , year=
Action and trajectory planning for urban au- tonomous driving with hierarchical reinforcement learning. InICML Workshop on New Frontiers in Learning, Control, and Dynamical Systems. Runyu Ma, Jelle Luijkx, Zlatan Ajanovi ´c, and Jens Kober. 2025. Explorllm: Guiding exploration in reinforcement learning with large language models. In2025 IEEE International...
-
[3]
Recently, other works have evaluated LLMs as a cognitive capability in navigation and planning tasks(Momennejad et al., 2023)
or using them as a general pattern machine for sequence transformation(Mirchandani et al., 2023; Gong et al., 2024). Recently, other works have evaluated LLMs as a cognitive capability in navigation and planning tasks(Momennejad et al., 2023). However, these methods perform poorly in tasks requiring continuous action reasoning. Another mainstream approach...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.