ProgVLA: Progress-Aware Robot Manipulation Skill Learning
Pith reviewed 2026-06-29 11:49 UTC · model grok-4.3
The pith
A 0.1B-parameter vision-language-action model reaches competitive or better success rates than much larger pretrained baselines on robot manipulation benchmarks, especially long-horizon tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ProgVLA integrates a two-stage Perceiver resampling scheme to compress variable-length visual, language, and proprioceptive streams into a fixed set of control-ready context tokens while preserving cross-modal grounding, together with an auxiliary set of progress heads trained with offline RL objectives to jointly learn critics over normalized remaining-horizon targets. This supplies the policy with an internal estimate of task progress and enables advantage- and success-weighted flow-matching imitation learning, so that a 0.1B-parameter model achieves success rates competitive with and on long-horizon and harder task tiers exceeding substantially larger pretrained baselines.
What carries the argument
Two-stage Perceiver resampling scheme that compresses multi-modal streams into fixed context tokens, paired with auxiliary progress heads that estimate remaining task horizon.
If this is right
- The 0.1B model reaches success rates competitive with larger baselines overall and exceeds them on long-horizon and harder task tiers.
- Ablations identify the learned context resampler and task-adaptive visual fine-tuning as the largest contributors, while progress-aware training adds a consistent gain concentrated on long-horizon and multi-object tasks.
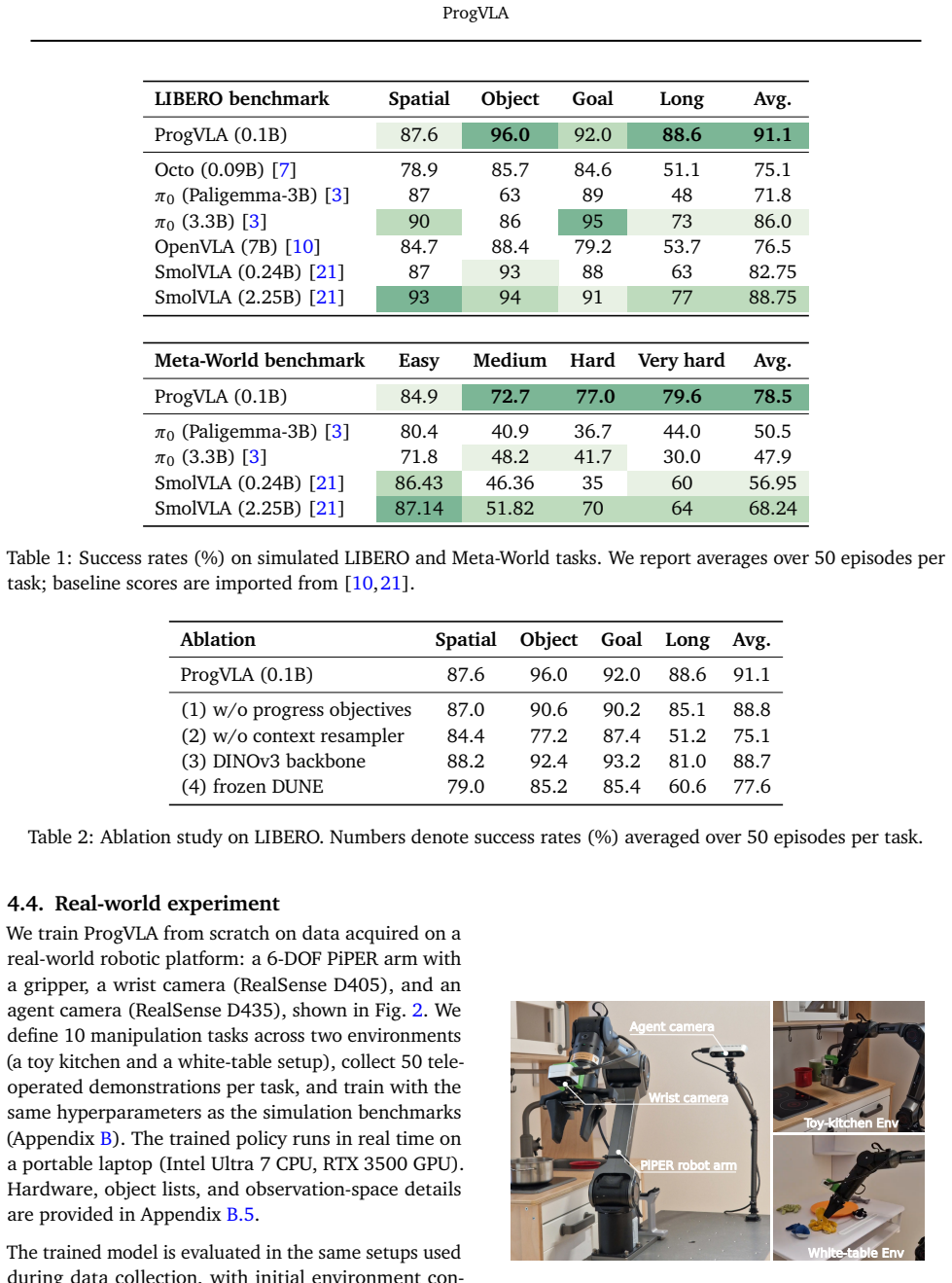
- The full approach validates in real-world toy-kitchen environments.
- The design focuses on efficient processing of long multi-modal sequences under tight compute budgets.
Where Pith is reading between the lines
- The resampling-plus-progress pattern could be tested on sequential decision tasks outside manipulation, such as navigation or assembly with more objects.
- Scaling the same progress heads to even longer horizons might expose whether the benefit grows or saturates.
- The fixed-token compression might allow similar efficiency gains when pairing other imitation objectives with multi-modal robot data.
Load-bearing premise
The auxiliary progress heads supply an internal estimate of task progress that meaningfully improves advantage- and success-weighted flow-matching imitation learning.
What would settle it
An ablation that removes the progress heads and shows no performance drop on long-horizon or multi-object tasks, or a head-to-head test where the 0.1B model falls behind larger baselines on the same benchmarks, would falsify the central claim.
Figures

read the original abstract
We present ProgVLA, a compact vision-language-action (VLA) model designed for reliable robot manipulation under tight compute and memory budgets. The model specifically focuses on efficiently processing long multi-modal sequences by maintaining an explicit representation of task progress over extended horizons. To this end, ProgVLA integrates two key components. First, a multi-modal encoder with a two-stage Perceiver resampling scheme compresses variable-length visual, language, and proprioceptive streams into a fixed set of control-ready context tokens, substantially reducing sequence length while preserving cross-modal grounding. Second, an auxiliary set of progress heads is trained with offline reinforcement learning (RL) objectives to jointly learn critics over normalized remaining-horizon targets. This provides the policy with an internal estimate of task progress and enables advantage- and success-weighted flow-matching imitation learning. On two well-established multi-task robot manipulation benchmarks, a 0.1B-parameter ProgVLA model reaches success rates that are competitive with, and on long-horizon and harder task tiers exceed, substantially larger pretrained baselines. Ablations indicate that the learned context resampler and task-adaptive visual fine-tuning are the largest single contributors, while progress-aware training provides a consistent additional gain that is concentrated on long-horizon and multi-object tasks. We further validate the approach in real-world toy-kitchen environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. ProgVLA is a 0.1B-parameter vision-language-action model for robot manipulation that employs a two-stage Perceiver resampling scheme to compress variable-length visual, language, and proprioceptive inputs into fixed context tokens and auxiliary progress heads trained via offline RL objectives to supply normalized remaining-horizon estimates. These components enable advantage- and success-weighted flow-matching imitation learning. The paper claims that ProgVLA achieves success rates competitive with or exceeding those of substantially larger pretrained baselines on two multi-task manipulation benchmarks (particularly on long-horizon and harder tiers), with ablations attributing the largest gains to the resampler and task-adaptive visual fine-tuning and a consistent additional benefit from progress-aware training; real-world validation in toy-kitchen settings is also reported.
Significance. If the performance claims hold under detailed scrutiny, the work would demonstrate that explicit progress modeling combined with efficient multi-modal compression can allow compact VLAs to match or surpass larger models on long-horizon tasks, which is relevant for resource-constrained robot deployment. The reported ablations and real-world experiments provide concrete evidence of practical utility.
major comments (1)
- [Abstract] Abstract: The central claim that a 0.1B ProgVLA reaches competitive or superior success rates on long-horizon tiers versus larger baselines is stated without any numerical success rates, baseline names/sizes, error bars, statistical tests, or table references. This absence prevents evaluation of whether the two-stage Perceiver resampler and progress heads deliver the asserted gains, making the empirical support for the primary contribution unevaluable.
minor comments (1)
- The description of the multi-modal encoder and progress heads would benefit from an accompanying diagram illustrating the two-stage resampling and how the auxiliary heads interface with the flow-matching objective.
Simulated Author's Rebuttal
We thank the referee for the detailed review and constructive comment on the abstract. We agree that the abstract would be strengthened by including specific quantitative results to support the central claims. We address the point below and will incorporate the suggested changes in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that a 0.1B ProgVLA reaches competitive or superior success rates on long-horizon tiers versus larger baselines is stated without any numerical success rates, baseline names/sizes, error bars, statistical tests, or table references. This absence prevents evaluation of whether the two-stage Perceiver resampler and progress heads deliver the asserted gains, making the empirical support for the primary contribution unevaluable.
Authors: We agree with this observation. The abstract was drafted to emphasize the high-level contribution and method, but it lacks the concrete numbers, baseline identifiers, and references needed for immediate evaluation. In the revised version we will expand the abstract to report specific success rates on the long-horizon and harder tiers, name the larger pretrained baselines and their parameter counts, reference the main result tables, and include any available error-bar or statistical information. These additions will directly address the concern while preserving the abstract's length constraints. revision: yes
Circularity Check
No circularity; empirical model presentation with no derivation chain or self-referential reductions
full rationale
The paper presents an empirical architecture (ProgVLA with Perceiver resampler and progress heads) and reports benchmark results plus ablations. No equations, first-principles derivations, or 'predictions' appear that could reduce to fitted inputs by construction. No self-citation load-bearing steps, uniqueness theorems, or ansatzes are invoked in the provided text. The central claims rest on external benchmark comparisons and ablations rather than any internal definitional loop, making the work self-contained against the listed circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Video-Language Critic: Transferable Reward Functions for Language-Conditioned Robotics.Transac- tions on Machine Learning Research, 2024
Minttu Alakuijala, Reginald McLean, Isaac Woungang, Nariman Farsad, Samuel Kaski, Pekka Marttinen, and Kai Yuan. Video-Language Critic: Transferable Reward Functions for Language-Conditioned Robotics.Transac- tions on Machine Learning Research, 2024. 1, 2
2024
-
[2]
Flamingo: a Visual Language Model for Few-Shot Learning, 2022
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, An- toine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, KatieMillican, MalcolmReynolds, RomanRing, Eliza Rutherford, Serkan Cabi, Tengda Han, Zhitao Gong, Sina Samangooei, Marianne Monteiro, Jacob Menick, Sebastian Borgeaud, Andrew Brock, Aida Ne- matzadeh, Sahand Sharifzadeh, Mikolaj Binkowski...
2022
-
[3]
$\pi_0$: AVision-Language-ActionFlowModelforGen- eral Robot Control, 2024
Kevin Black, Noah Brown, Danny Driess, Adnan Es- mail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsch, Lucy Xiaoyang Shi, James Tanner, Quan Vuong, Anna Walling, Haohuan Wang, and Ury Zhilinsky. $\pi_0$:...
2024
-
[4]
Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Manuel Y. Galliker, Dibya Ghosh, Lachy Groom, Karol Hausman, Brian Ichter, Szy- mon Jakubczak, Tim Jones, Liyiming Ke, Devin LeBlanc, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsch, Allen Z. Ren, Lucy ...
2025
-
[5]
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Xi Chen, Krzysztof Choromanski, Tianli Ding, Danny Driess, Avinava Dubey, Chelsea Finn, Pete Flo- rence,ChuyuanFu,MontseGonzalezArenas,Keerthana Gopalakrishnan, Kehang Han, Karol Hausman, Alexan- der Herzog, Jasmine Hsu, Brian Ichter, Alex Irpan, Nikhil Joshi, Ryan Julian, Dmitry Kalashnikov, ...
2023
-
[6]
Vision-Language Models as Success Detec- tors
Yuqing Du, Ksenia Konyushkova, Misha Denil, Akhil Raju, Jessica Landon, Felix Hill, Nando de Freitas, and Serkan Cabi. Vision-Language Models as Success Detec- tors. InConference on Lifelong Learning Agents, 2023. 1, 2
2023
-
[7]
Octo: An Open-Source Generalist Robot Policy, 2024
Dibya Ghosh, Homer Walke, Karl Pertsch, Kevin Black, Oier Mees, Sudeep Dasari, Joey Hejna, Tobias Kreiman, Charles Xu, Jianlan Luo, You Liang Tan, Lawrence Yun- liang Chen, Pannag Sanketi, Quan Vuong, Ted Xiao, Dorsa Sadigh, Chelsea Finn, and Sergey Levine. Octo: An Open-Source Generalist Robot Policy, 2024. 6
2024
-
[8]
Task Success Prediction for Open-Vocabulary Manipulation Based on Multi-Level Aligned Representations
Miyu Goko, Motonari Kambara, Daichi Saito, Seitaro Otsuki, and Komei Sugiura. Task Success Prediction for Open-Vocabulary Manipulation Based on Multi-Level Aligned Representations. InCoRL, 2024. 2
2024
-
[9]
Perceiver: General Perception with Iterative Attention, 2021
Andrew Jaegle, Felix Gimeno, Andrew Brock, Andrew Zisserman, Oriol Vinyals, and Joao Carreira. Perceiver: General Perception with Iterative Attention, 2021. 1, 2
2021
-
[10]
OpenVLA: An Open-Source Vision-Language-Action Model, 2024
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, Quan Vuong, ThomasKollar, BenjaminBurchfiel, RussTedrake, Dorsa Sadigh, Sergey Levine, Percy Liang, and Chelsea Finn. OpenVLA: An Open-Source Vision-Language-Action Model, 2024. 1, 2, 6
2024
-
[11]
Offline Reinforcement Learning with Implicit Q-Learning
Ilya Kostrikov, Ashvin Nair, and Sergey Levine. Offline Reinforcement Learning with Implicit Q-Learning. In ICLR, 2022. 4, 9
2022
-
[12]
Stabilizing Off-Policy Q-Learning via Bootstrap- ping Error Reduction
Aviral Kumar, Justin Fu, George Tucker, and Sergey Levine. Stabilizing Off-Policy Q-Learning via Bootstrap- ping Error Reduction. InNeurIPS, 2019. 9
2019
-
[13]
Vision-Language Foundation Models as Effective Robot Imitators
Xinghang Li, Minghuan Liu, Hanbo Zhang, Cunjun Yu, Jie Xu, Hongtao Wu, Chilam Cheang, Ya Jing, Weinan Zhang, Huaping Liu, Hang Li, and Tao Kong. Vision- Language Foundation Models as Effective Robot Imita- tors, 2024. arXiv:2311.01378 [cs]. 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
LIBERO: Benchmarking Knowledge Transfer for Lifelong Robot Learning
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. LIBERO: Benchmarking Knowledge Transfer for Lifelong Robot Learning. In NeurIPS, 2023. 4, 5
2023
-
[15]
Vision-Language Models for Robot Success Detection.Proceedings of the AAAI Conference on Artifi- cial Intelligence, 38(21):23750–23752, 2024
Fiona Luo. Vision-Language Models for Robot Success Detection.Proceedings of the AAAI Conference on Artifi- cial Intelligence, 38(21):23750–23752, 2024. 2
2024
-
[16]
Vision Language Models are In-Context Value Learners
Yecheng Jason Ma, Joey Hejna, Chuyuan Fu, Dhruv Shah, Jacky Liang, Zhuo Xu, Sean Kirmani, Peng Xu, Danny Driess, Ted Xiao, Osbert Bastani, Dinesh Jayara- man, Wenhao Yu, Tingnan Zhang, Dorsa Sadigh, and Fei Xia. Vision Language Models are In-Context Value Learners. InICLR, 2025. 1, 2, 14
2025
-
[17]
DINOv2: Learning Robust Visual Features without Supervision,
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fer- nandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mahmoud Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Hervé Jegou, Julien Mairal, Patrick L...
-
[18]
arXiv:2304.07193 [cs]. 1
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer.Jour- nal of Machine Learning Research, 2020. 3, 11
2020
-
[20]
DUNE: Distilling a Universal Encoder from Heteroge- neous 2D and 3D Teachers
Mert Bulent Sariyildiz, Philippe Weinzaepfel, Thomas Lucas,PaudeJorge,DianeLarlus,andYannisKalantidis. DUNE: Distilling a Universal Encoder from Heteroge- neous 2D and 3D Teachers. InCVPR, 2025. 1, 3, 11
2025
-
[21]
Masked World Models for Visual Control
Younggyo Seo, Danijar Hafner, Hao Liu, Fangchen Liu, Stephen James, Kimin Lee, and Pieter Abbeel. Masked World Models for Visual Control. InCoRL, 2022. 5
2022
-
[22]
SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics, 2025
Mustafa Shukor, Dana Aubakirova, Francesco Capuano, Pepijn Kooijmans, Steven Palma, Adil Zouitine, Michel Aractingi,CarolinePascal,MartinoRussi,AndresMarafi- oti, Simon Alibert, Matthieu Cord, Thomas Wolf, and Remi Cadene. SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics, 2025. 1, 2, 3, 5, 6, 11, 13
2025
-
[23]
Oriane Siméoni, Huy V. Vo, Maximilian Seitzer, Fed- erico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khali- dov, Marc Szafraniec, Seungeun Yi, Michaël Ramamon- jisoa, Francisco Massa, Daniel Haziza, Luca Wehrstedt, Jianyuan Wang, Timothée Darcet, Théo Moutakanni, Leonel Sentana, Claire Roberts, Andrea Vedaldi, Jamie Tolan, John Brandt, Camille Couprie, J...
2025
-
[24]
Meta- World: A Benchmark and Evaluation for Multi-Task and Meta Reinforcement Learning
Tianhe Yu, Deirdre Quillen, Zhanpeng He, Ryan Julian, KarolHausman, ChelseaFinn, andSergeyLevine. Meta- World: A Benchmark and Evaluation for Multi-Task and Meta Reinforcement Learning. InCoRL, 2019. 4 8 ProgVLA A. Notation summary For convenience we collect the notation used through- out the paper in Table 3. B. Additional experimental details B.1. Justi...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.