Category-Level 3D Correspondence in Camera Space via Morphable Object Priors
Pith reviewed 2026-06-29 13:53 UTC · model grok-4.3
The pith
Category-level 3D correspondences emerge implicitly when learning a shared morphable object prior from images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By disentangling canonical shape, deformation, and object pose in a morphable category-level shape prior learned from image reconstruction, semantically meaningful 3D correspondences in camera space emerge implicitly without explicit correspondence supervision.
What carries the argument
The morphable object prior that shares a canonical grounding across instances by disentangling shape, deformation, and pose.
If this is right
- Semantically meaningful 3D correspondences appear in camera space across instances.
- The approach sets a new state of the art on the HouseCorr3D benchmark.
- Semantic 3D object understanding arises without direct correspondence supervision.
- Consistent correspondences hold even for occluded regions due to amodal labels.
Where Pith is reading between the lines
- This could allow similar implicit emergence in other vision tasks like part segmentation without supervision.
- Extending the prior to dynamic scenes might help in video-based correspondence.
- The symmetry annotations could be used to test if the method respects object symmetries naturally.
Load-bearing premise
Disentangling canonical shape, deformation, and object pose from image reconstruction losses alone produces consistent semantic 3D correspondences across instances without any correspondence supervision or post-hoc alignment.
What would settle it
Training the model on HouseCorr3D and finding that predicted 3D keypoints fail to align with ground-truth annotations across different instances would falsify the emergence of correspondences.
Figures

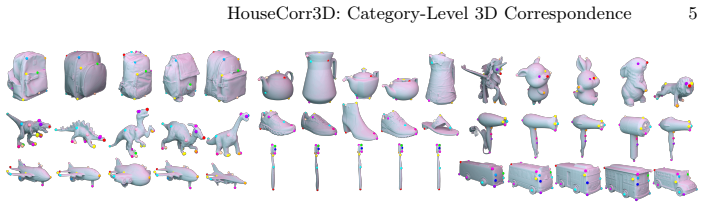
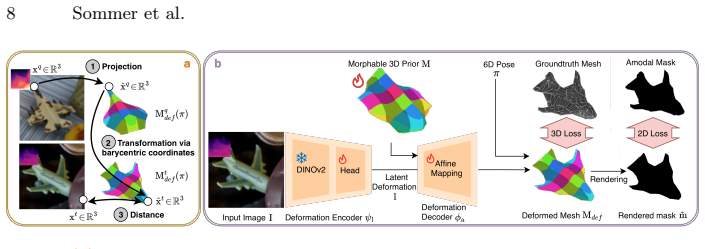

read the original abstract
Understanding 3D objects from images is fundamental to robotics and AR/VR applications. While recent work has made progress in category-level pose estimation, current representations fail to capture the fine-grained semantics needed for reasoning about object parts, functions, and interactions. In this work, we study category-level 3D correspondence in camera space -- predicting, from a single image, 3D locations that remain consistent across instances within a category -- and show that it can emerge without explicit correspondence supervision by learning a shared morphable object prior. To enable research in this direction, we introduce HouseCorr3D, the first large-scale benchmark for monocular category-level 3D correspondence with 178k images across 50 household object categories, 280 unique instances, and 3D keypoint annotations directly on CAD models. Crucially, HouseCorr3D provides amodal correspondence labels for occluded regions and explicit symmetry annotations, addressing key limitations of existing datasets. We further propose Morpheus, a method that learns morphable category-level shape priors by disentangling canonical shape, deformation, and object pose. Through this shared canonical grounding, semantically meaningful 3D correspondences in camera space emerge implicitly. These emerging 3D correspondences set a new state of the art on HouseCorr3D, demonstrating that semantic 3D object understanding can arise without direct correspondence supervision. Data and code are publicly available at https://github.com/GenIntel/HouseCorr3D.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that category-level 3D correspondences in camera space can emerge implicitly without explicit supervision by learning a shared morphable object prior (Morpheus) that disentangles canonical shape, deformation, and object pose from image reconstruction and pose objectives. To support evaluation, the authors introduce HouseCorr3D, a benchmark of 178k images across 50 household categories and 280 instances with 3D keypoint annotations on CAD models, including amodal labels for occlusions and explicit symmetry annotations. The method is reported to achieve state-of-the-art performance on this benchmark.
Significance. If the central claim holds, the work would be significant for demonstrating that semantic 3D object understanding can arise from standard reconstruction losses via a canonical representation, with implications for scalable learning in robotics and AR/VR. The benchmark's emphasis on amodal and symmetric cases addresses practical limitations of prior datasets. Public release of data and code is a clear strength that supports reproducibility.
major comments (3)
- [Abstract] Abstract: The claim that 'semantically meaningful 3D correspondences in camera space emerge implicitly' through disentangling canonical shape, deformation, and pose rests on the morphable prior discovering consistent semantics. However, pure image reconstruction losses are invariant to which semantic parts are assigned to which canonical coordinates, so nothing in the stated objectives prevents geometrically valid but semantically inconsistent alignments across instances (e.g., leg of one chair mapped to seat of another).
- [Method (Morpheus)] Method description: The disentanglement into canonical shape, deformation, and object pose is presented as producing the shared grounding for correspondences. No auxiliary semantic losses, part-aware features, or cross-instance regularizers are indicated in the abstract, making the emergence of semantics an empirical outcome of training rather than a property enforced by the formulation; ablations isolating the morphable prior's role are needed to substantiate the claim.
- [HouseCorr3D benchmark and evaluation] Benchmark and results: HouseCorr3D supplies 3D keypoint annotations directly on CAD models with amodal and symmetry handling. To support the 'without explicit correspondence supervision' advantage, the evaluation should include comparisons against supervised correspondence baselines and report cross-instance consistency metrics in addition to standard accuracy, as the predefined CAD keypoints may interact with the benchmark construction choices.
minor comments (2)
- [Abstract] Abstract: The SOTA claim would benefit from specifying the primary metric (e.g., PCK@threshold or mean distance error) on which Morpheus outperforms prior work.
- The distribution of the 178k images across the 280 instances and 50 categories should be detailed to allow assessment of category balance and instance diversity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will incorporate revisions to clarify the emergence claim, add ablations, and strengthen the evaluation.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that 'semantically meaningful 3D correspondences in camera space emerge implicitly' through disentangling canonical shape, deformation, and pose rests on the morphable prior discovering consistent semantics. However, pure image reconstruction losses are invariant to which semantic parts are assigned to which canonical coordinates, so nothing in the stated objectives prevents geometrically valid but semantically inconsistent alignments across instances (e.g., leg of one chair mapped to seat of another).
Authors: We agree that pure reconstruction losses are invariant to semantic labelings and do not explicitly prevent inconsistent part mappings. The emergence of consistent semantics is an empirical outcome driven by the requirement that a single shared canonical shape must explain all instances in the category. We will revise the abstract to state more precisely that correspondences emerge from the morphable prior under reconstruction and pose objectives, and add a short discussion paragraph explaining how the shared canonical representation promotes semantic consistency in practice despite the invariance. revision: yes
-
Referee: [Method (Morpheus)] Method description: The disentanglement into canonical shape, deformation, and object pose is presented as producing the shared grounding for correspondences. No auxiliary semantic losses, part-aware features, or cross-instance regularizers are indicated in the abstract, making the emergence of semantics an empirical outcome of training rather than a property enforced by the formulation; ablations isolating the morphable prior's role are needed to substantiate the claim.
Authors: The abstract is a high-level summary; the method section describes the architecture without auxiliary semantic losses. We agree that isolating ablations are required. In revision we will add experiments ablating the shared canonical shape (e.g., per-instance shape codes) and the disentanglement components, measuring impact on correspondence accuracy to substantiate the prior's role. revision: yes
-
Referee: [HouseCorr3D benchmark and evaluation] Benchmark and results: HouseCorr3D supplies 3D keypoint annotations directly on CAD models with amodal and symmetry handling. To support the 'without explicit correspondence supervision' advantage, the evaluation should include comparisons against supervised correspondence baselines and report cross-instance consistency metrics in addition to standard accuracy, as the predefined CAD keypoints may interact with the benchmark construction choices.
Authors: We will add supervised correspondence baselines trained on the HouseCorr3D keypoint annotations for direct comparison, while clearly noting that our method uses none of this supervision. We will also report cross-instance consistency (e.g., variance of predicted 3D locations for the same semantic keypoint across instances). We will clarify in the benchmark section that CAD models and keypoints were drawn from existing public sources independently of our method. revision: yes
Circularity Check
No significant circularity; central claim is empirical emergence from training
full rationale
The paper claims that category-level 3D correspondences emerge implicitly from disentangling canonical shape, deformation, and pose via image reconstruction losses in the Morpheus model, without explicit supervision. This is presented as a trained outcome on the new HouseCorr3D benchmark rather than a closed-form derivation. No equations, self-definitions, or fitted-input-as-prediction reductions are visible in the provided text. The result does not reduce by construction to its inputs; it is an observed property of the optimized network. No load-bearing self-citations or uniqueness theorems from prior author work are invoked in the abstract. This is the normal non-circular case for an empirical method paper.
Axiom & Free-Parameter Ledger
free parameters (1)
- latent dimensions for canonical shape and deformation
axioms (1)
- domain assumption A neural network trained on image reconstruction and pose objectives can learn a disentangled representation of canonical shape, deformation, and pose.
invented entities (1)
-
Morphable object prior
no independent evidence
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the 26th Annual Conference on Computer Graphics and Inter- active Techniques
Blanz, V., Vetter, T.: A morphable model for the synthesis of 3d faces. In: Proceedings of the 26th Annual Conference on Computer Graphics and Inter- active Techniques. p. 187–194. SIGGRAPH ’99, ACM Press/Addison-Wesley Publishing Co., USA (1999).https://doi.org/10.1145/311535.311556, https: //doi.org/10.1145/311535.3115564
-
[2]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
Brazil, G., Kumar, A., Straub, J., Ravi, N., Johnson, J., Gkioxari, G.: Omni3D: A large benchmark and model for 3D object detection in the wild. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, Vancouver, Canada (June 2023) 4
2023
-
[3]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) (2021) 3
Caron, M., Touvron, H., Misra, I., Jégou, H., Mairal, J., Bojanowski, P., Joulin, A.: Emerging properties in self-supervised vision transformers. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) (2021) 3
2021
-
[4]
Chang, A.X., Funkhouser, T., Guibas, L., Hanrahan, P., Huang, Q., Li, Z., Savarese, S., Savva, M., Song, S., Su, H., Xiao, J., Yi, L., Yu, F.: ShapeNet: An Information- Rich 3D Model Repository. Tech. Rep. arXiv:1512.03012 [cs.GR], Stanford Univer- sity — Princeton University — Toyota Technological Institute at Chicago (2015) 4
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[5]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
Chen, X., Mottaghi, R., Liu, X., Fidler, S., Urtasun, R., Yuille, A.: Detect what you can: Detecting and representing objects using holistic models and body parts. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). pp. 1971–1978 (2014) 6
1971
-
[6]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) (2025) 4
Dünkel, O., Wimmer, T., Theobalt, C., Rupprecht, C., Kortylewski, A.: Do it yourself: Learning semantic correspondence from pseudo-labels. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) (2025) 4
2025
-
[7]
In: Conference on Neural Informa- tion Processing Systems (NeurIPS) (2022) 2
Fu, Y., Wang, X.: Category-level 6d object pose estimation in the wild: A semi- supervised learning approach and a new dataset. In: Conference on Neural Informa- tion Processing Systems (NeurIPS) (2022) 2
2022
-
[8]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Gkioxari, G., Johnson, J., Malik, J.: Mesh r-cnn. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 9784–9794 (2019).https: //doi.org/10.1109/ICCV.2019.009884
-
[9]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
Goel, S., Gkioxari, G., Malik, J.: Differentiable stereopsis: Meshes from multiple views using differentiable rendering. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). pp. 8635–8644 (2022) 9
2022
-
[10]
In: Proceedings of the International Conference on Machine Learning (ICML) (2020) 10, 29 16 Sommer et al
Gropp, A., Yariv, L., Haim, N., Atzmon, M., Lipman, Y.: Implicit geometric regularization for learning shapes. In: Proceedings of the International Conference on Machine Learning (ICML) (2020) 10, 29 16 Sommer et al
2020
-
[11]
In: European Conference on Computer Vision (ECCV) (2018) 4
Groueix, T., Fisher, M., Kim, V.G., Russell, B., Aubry, M.: 3d-coded : 3d corre- spondences by deep deformation. In: European Conference on Computer Vision (ECCV) (2018) 4
2018
-
[12]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
Güler, R.A., Neverova, N., Kokkinos, I.: Densepose: Dense human pose estimation in the wild. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). pp. 7297–7306 (2018) 4
2018
-
[13]
In: IEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI) (2016) 3, 5, 6
Ham, B., Cho, M., Schmid, C., Ponce, J.: Proposal flow: Semantic correspondences from object proposals. In: IEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI) (2016) 3, 5, 6
2016
-
[14]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). pp. 770–778 (2016).https://doi.org/10.1109/CVPR.2016.9011, 23
-
[15]
Jakab, T., Tucker, R., Makadia, A., Wu, J., Snavely, N., Kanazawa, A.: Keypoint- deformer: Unsupervised 3d keypoint discovery for shape control. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). pp. 12778–12787 (2021).https://doi.org/10.1109/CVPR46437.2021.012594
-
[16]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) (2021) 2, 4
Jiang, W., Trulls, E., Hosang, J., Tagliasacchi, A., Yi, K.M.: COTR: Correspon- dence Transformer for Matching Across Images. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) (2021) 2, 4
2021
-
[17]
In: International Conference on 3D Vision (3DV) (2025) 4, 30
Kim, H., Lang, I., Aigerman, N., Groueix, T., Kim, V.G., Hanocka, R.: Meshup: Multi-target mesh deformation via blended score distillation. In: International Conference on 3D Vision (3DV) (2025) 4, 30
2025
-
[18]
Kingma, D.P., Ba, J.: Adam: A method for stochastic optimization. In: International Conference on Learning Representations (ICLR) (2015),https://arxiv.org/abs/ 1412.698011
-
[19]
In: European Conference on Computer Vision (ECCV) (2024) 2, 5
Krishnan, A., Kundu, A., Maninis, K.K., Hays, J., Brown, M.: Omninocs: A unified nocs dataset and model for 3d lifting of 2d objects. In: European Conference on Computer Vision (ECCV) (2024) 2, 5
2024
-
[20]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Kulkarni, N., Tulsiani, S., Gupta, A.: Canonical surface mapping via geometric cycle consistency. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 2202–2211 (2019).https://doi.org/10.1109/ICCV. 2019.002294
-
[21]
arXiv preprint arXiv:2305.02385 (2023) 3
Li, X., Han, K., Wan, X., Prisacariu, V.A.: Simsc: A simple framework for semantic correspondence with temperature learning. arXiv preprint arXiv:2305.02385 (2023) 3
-
[22]
IEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI)33(5), 978–994 (2011) 3
Liu, C., Yuen, J., Torralba, A.: Sift flow: Dense correspondence across scenes and its applications. IEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI)33(5), 978–994 (2011) 3
2011
-
[23]
ACM Trans
Loper, M., Mahmood, N., Romero, J., Pons-Moll, G., Black, M.J.: SMPL: A skinned multi-person linear model. ACM Trans. Graphics (Proc. SIGGRAPH Asia)34(6), 248:1–248:16 (Oct 2015) 4
2015
-
[24]
In: European Conference on Computer Vision (ECCV)
Lou, Y., You, Y., Li, C., Cheng, Z., Li, L., Ma, L., Wang, W., Lu, C.: Human correspondence consensus for 3d object semantic understanding. In: European Conference on Computer Vision (ECCV). p. 496–512. Springer-Verlag, Berlin, Heidelberg (2020). https://doi.org/10.1007/978-3-030-58542-6_30 , https: //doi.org/10.1007/978-3-030-58542-6_304, 6
-
[25]
International Journal of Computer Vision (IJCV)60(2), 91–110 (2004) 3
Lowe, D.G.: Distinctive image features from scale-invariant keypoints. International Journal of Computer Vision (IJCV)60(2), 91–110 (2004) 3
2004
-
[26]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
Mariotti, O., Mac Aodha, O., Bilen, H.: Improving semantic correspondence with viewpoint-guided spherical maps. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). pp. 19521–19530 (2024) 2, 4 HouseCorr3D: Category-Level 3D Correspondence 17
2024
- [27]
-
[28]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2019) 4
Mo, K., Zhu, S., Chang, A.X., Yi, L., Tripathi, S., Guibas, L., Su, H.: Partnet: A large-scale benchmark for fine-grained and hierarchical part-level 3d object understanding. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2019) 4
2019
-
[29]
In: International Conference on Learning Representations (ICLR)
Nam, J., Lee, G., Kim, S., Kim, H., Cho, H., Kim, S., Kim, S.: Diffusion model for dense matching. In: International Conference on Learning Representations (ICLR). OpenReview.net (2024),https://openreview.net/forum?id=Zsfiqpft6K2, 4
2024
-
[30]
Conference on Neural Information Processing Systems (NeurIPS) (2020) 4, 30
Neverova, N., Novotny, D., Khalidov, V., Szafraniec, M., Labatut, P., Vedaldi, A.: Continuous surface embeddings for deformable shape correspondence. Conference on Neural Information Processing Systems (NeurIPS) (2020) 4, 30
2020
-
[31]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) (2019) 4
Novotny, D., Ravi, N., Graham, B., Neverova, N., Vedaldi, A.: C3dpo: Canonical 3d pose networks for non-rigid structure from motion. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) (2019) 4
2019
-
[32]
Oquab, M., Darcet, T., Moutakanni, T., Vo, H.V., Szafraniec, M., Khalidov, V., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., Howes, R., Huang, P.Y., Xu, H., Sharma, V., Li, S.W., Galuba, W., Rabbat, M., Assran, M., Ballas, N., Synnaeve, G., Misra, I., Jegou, H., Mairal, J., Labatut, P., Joulin, A., Bojanowski, P.: Dinov2: Learning robust visual feat...
2023
-
[33]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) (2021) 4
Reizenstein, J., Shapovalov, R., Henzler, P., Sbordone, L., Labatut, P., Novotny, D.: Common objects in 3d: Large-scale learning and evaluation of real-life 3d category reconstruction. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) (2021) 4
2021
-
[34]
Conference on Neural Information Processing Systems (NeurIPS)34, 6087–6101 (2021) 9
Shen, T., Gao, J., Yin, K., Liu, M.Y., Fidler, S.: Deep marching tetrahedra: a hybrid representation for high-resolution 3d shape synthesis. Conference on Neural Information Processing Systems (NeurIPS)34, 6087–6101 (2021) 9
2021
-
[35]
In: European Conference on Computer Vision (ECCV) (2024) 4, 30, 31
Shtedritski, A., Rupprecht, C., Vedaldi, A.: Shic: Shape-image correspondences with no keypoint supervision. In: European Conference on Computer Vision (ECCV) (2024) 4, 30, 31
2024
-
[36]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
Sommer, L., Dünkel, O., Theobalt, C., Kortylewski, A.: Common3d: Self-supervised learning of 3d morphable models for common objects in neural feature space. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). pp. 6468–6479 (June 2025) 4, 22
2025
-
[37]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2021) 2, 4
Sun, J., Shen, Z., Wang, Y., Bao, H., Zhou, X.: LoFTR: Detector-free local feature matching with transformers. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2021) 2, 4
2021
-
[38]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2018) 4
Sun, X., Wu, J., Zhang, X., Zhang, Z., Zhang, C., Xue, T., Tenenbaum, J.B., Freeman, W.T.: Pix3d: Dataset and methods for single-image 3d shape modeling. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2018) 4
2018
-
[39]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
Sun, Y., Huang, Y., Guo, H., Zhao, Y., Wu, R., Yu, Y., Ge, W., Zhang, W.: Misc210k: A large-scale dataset for multi-instance semantic correspondence. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). pp. 7121–7130 (2023) 5, 6
2023
-
[40]
In: Bengio, S., Wallach, H.M., Larochelle, H.,Grauman,K.,Cesa-Bianchi,N.,Garnett,R.(eds.)ConferenceonNeuralInforma- tion Processing Systems (NeurIPS)
Suwajanakorn, S., Snavely, N., Tompson, J., Norouzi, M.: Discovery of latent 3d key- points via end-to-end geometric reasoning. In: Bengio, S., Wallach, H.M., Larochelle, H.,Grauman,K.,Cesa-Bianchi,N.,Garnett,R.(eds.)ConferenceonNeuralInforma- tion Processing Systems (NeurIPS). pp. 2063–2074 (2018),https://proceedings. neurips.cc/paper/2018/hash/24146db4e...
2063
-
[41]
In: European Conference on Computer Vision (ECCV)
Tian, M., Ang, M.H., Lee, G.H.: Shape prior deformation for categorical 6d object pose and size estimation. In: European Conference on Computer Vision (ECCV). p. 530–546. Springer-Verlag, Berlin, Heidelberg (2020).https://doi.org/10.1007/ 978-3-030-58589-1_32,https://doi.org/10.1007/978-3-030-58589-1_324
-
[42]
Tola, E., Lepetit, V., Fua, P.: Daisy: An efficient dense descriptor applied to wide baseline stereo. IEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI)32, 815–30 (05 2010).https://doi.org/10.1109/TPAMI.2009.773
-
[43]
Wah, C., Branson, S., Welinder, P., Perona, P., Belongie, S.: Cub-200-2011 (Apr 2022).https://doi.org/10.22002/D1.200984, 5, 6
-
[44]
Showui: One vision-language- action model for GUI visual agent
Wandel, K., Wang, H.: Semalign3d: Semantic correspondence between rgb-images through aligning 3d object-class representations. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). pp. 1138–1147 (2025).https://doi.org/10.1109/CVPR52734.2025.001144
-
[45]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
Wang, H., Sridhar, S., Huang, J., Valentin, J., Song, S., Guibas, L.J.: Normalized object coordinate space for category-level 6d object pose and size estimation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). pp. 2642–2651 (2019) 2, 5, 11, 12, 21, 23, 30
2019
-
[46]
In: European Conference on Computer Vision (ECCV) (2018) 4
Wang, N., Zhang, Y., Li, Z., Fu, Y., Liu, W., Jiang, Y.G.: Pixel2mesh: Generating 3d mesh models from single rgb images. In: European Conference on Computer Vision (ECCV) (2018) 4
2018
-
[47]
In: Proceedings of the IEEE/CVF Interna- tional Conference on Computer Vision (ICCV)
Weinzaepfel, P., Revaud, J., Harchaoui, Z., Schmid, C.: Deepflow: Large displace- ment optical flow with deep matching. In: Proceedings of the IEEE/CVF Interna- tional Conference on Computer Vision (ICCV). pp. 1385–1392 (2013) 3
2013
-
[48]
International Journal of Computer Vision (IJCV) (2023) 4, 5, 6
Wu, S., Jakab, T., Rupprecht, C., Vedaldi, A.: DOVE: Learning deformable 3d objects by watching videos. International Journal of Computer Vision (IJCV) (2023) 4, 5, 6
2023
-
[49]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2023) 4, 9, 10, 11, 12, 22, 23
Wu, S., Li, R., Jakab, T., Rupprecht, C., Vedaldi, A.: MagicPony: Learning articu- lated 3d animals in the wild. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2023) 4, 9, 10, 11, 12, 22, 23
2023
-
[50]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2015) 4
Wu, Z., Song, S., Khosla, A., Yu, F., Zhang, L., Tang, X., Xiao, J.: 3d shapenets: A deep representation for volumetric shapes. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2015) 4
2015
-
[51]
In: Proceedings of the Winter Conference on Applications of Computer Vision (WACV)
Xiang, Y., Mottaghi, R., Savarese, S.: Beyond pascal: A benchmark for 3d object detection in the wild. In: Proceedings of the Winter Conference on Applications of Computer Vision (WACV). pp. 75–82. IEEE (2014) 4
2014
-
[52]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) (2023) 4
Xu, J., Zhang, Y., Peng, J., Ma, W., Jesslen, A., Ji, P., Hu, Q., Zhang, J., Liu, Q., Wang, J., Ji, W., Wang, C., Yuan, X., Kaushik, P., Zhang, G., Liu, J., Xie, Y., Cui, Y., Yuille, A., Kortylewski, A.: Animal3d: A comprehensive dataset of 3d animal pose and shape. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) (2023) 4
2023
-
[53]
In: Conference on Robot Learning (CoRL) (2020) 3
Xu, Z., He, Z., Wu, J., Song, S.: Learning 3d dynamic scene representations for robot manipulation. In: Conference on Robot Learning (CoRL) (2020) 3
2020
-
[54]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
Yang, G., Sun, D., Jampani, V., Vlasic, D., Cole, F., Chang, H., Ramanan, D., Freeman, W.T., Liu, C.: Lasr: Learning articulated shape reconstruction from a monocular video. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). pp. 15980–15989 (2021) 9
2021
-
[55]
In: ACM Trans
Yi, L., Kim, V.G., Ceylan, D., Shen, W., Yan, M., Su, H., Lu, C., Huang, Q., Sheffer, A., Guibas, L.: A scalable active framework for region annotation in 3d shape collections. In: ACM Trans. Graphics (Proc. SIGGRAPH Asia) (2016) 4 HouseCorr3D: Category-Level 3D Correspondence 19
2016
-
[56]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Yifan, W., Aigerman, N., Kim, V.G., Chaudhuri, S., Sorkine-Hornung, O.: Neural cages for detail-preserving 3d deformations. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). pp. 72–80 (2020).https: //doi.org/10.1109/CVPR42600.2020.000154
-
[57]
Nature Human Behaviour8(2), 320–335 (Feb 2024) 3
Yildirim, I., Siegel, M.H., Soltani, A.A., Ray Chaudhuri, S., Tenenbaum, J.B.: Perception of 3D shape integrates intuitive physics and analysis-by-synthesis. Nature Human Behaviour8(2), 320–335 (Feb 2024) 3
2024
-
[58]
You, Y., Li, C., Lou, Y., Cheng, Z., Li, L., Ma, L., Wang, W., Lu, C.: Understanding pixel-level 2d image semantics with 3d keypoint knowledge engine. IEEE Trans- actions on Pattern Analysis and Machine Intelligence (PAMI)44(9), 5780–5795 (2022).https://doi.org/10.1109/TPAMI.2021.30726594
-
[59]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
You, Y., Lou, Y., Li, C., Cheng, Z., Li, L., Ma, L., Lu, C., Wang, W.: Keypointnet: A large-scale 3d keypoint dataset aggregated from numerous human annotations. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). pp. 13644–13653 (2020).https://doi.org/10.1109/CVPR42600.2020. 013664, 6
-
[60]
In: European Conference on Computer Vision (ECCV)
Zhang, J., Huang, W., Peng, B., Wu, M., Hu, F., Chen, Z., Zhao, B., Dong, H.: Omni6dpose: Large-scale multi-object 6d pose estimation with realistic rendering. In: European Conference on Computer Vision (ECCV). pp. 3110–3120 (2024) 2, 4, 6, 7, 8, 11, 12, 22, 23
2024
-
[61]
In: Conference on Neural Information Processing Systems (NeurIPS) (2023) 3, 23
Zhang, J., Herrmann, C., Hur, J., Cabrera, L.P., Jampani, V., Sun, D., Yang, M.H.: A Tale of Two Features: Stable Diffusion Complements DINO for Zero- Shot Semantic Correspondence. In: Conference on Neural Information Processing Systems (NeurIPS) (2023) 3, 23
2023
-
[62]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
Zheng, Z., Yu, T., Dai, Q., Liu, Y.: Deep implicit templates for 3d shape represen- tation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). pp. 1429–1439 (2021) 9, 10, 30
2021
-
[63]
International Conference on Learning Representations (ICLR) (2022) 3
Zhou, J., Wei, C., Wang, H., Shen, W., Xie, C., Yuille, A., Kong, T.: ibot: Image bert pre-training with online tokenizer. International Conference on Learning Representations (ICLR) (2022) 3
2022
-
[64]
International Conference on Learning Representations (ICLR) (2025) 4, 5, 6, 30 20 Sommer et al
Zhu, J., Ju, Y., Zhang, J., Wang, M., Yuan, Z., Hu, K., Xu, H.: Densematcher: Learning 3d semantic correspondence for category-level manipulation from a single demo. International Conference on Learning Representations (ICLR) (2025) 4, 5, 6, 30 20 Sommer et al. Category-Level 3D Correspondence in Camera Space via Morphable Object Priors Supplementary Mate...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.