CIRF: Tokenizing Chain-of-Thoughts into Reusable Functional Units for Efficient Latent Reasoning in Large Language Models
Pith reviewed 2026-06-29 13:14 UTC · model grok-4.3
The pith
Tokenizing explicit chain-of-thought traces into reusable functional units lets models perform aligned implicit reasoning with lower latency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CIRF extracts semantically coherent reasoning units from explicit CoT traces, assigns each a functional token, and fine-tunes the model to autoregressively generate the token sequence and any associated results before the final answer, thereby aligning latent reasoning with explicit rationales and supporting adaptive sequence lengths.
What carries the argument
The functional token, a discrete label assigned to each semantically coherent reasoning unit extracted from explicit CoT traces and generated autoregressively by the fine-tuned model.
If this is right
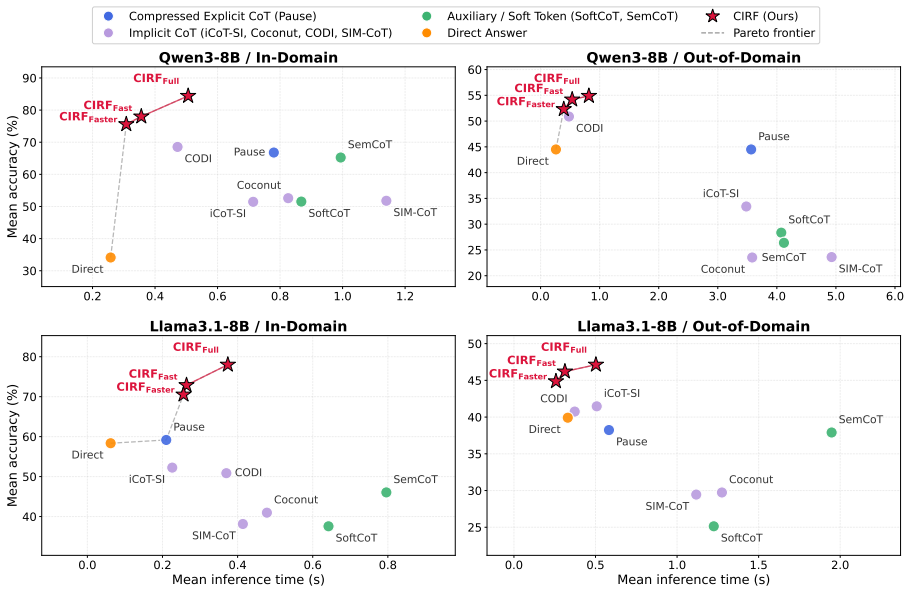
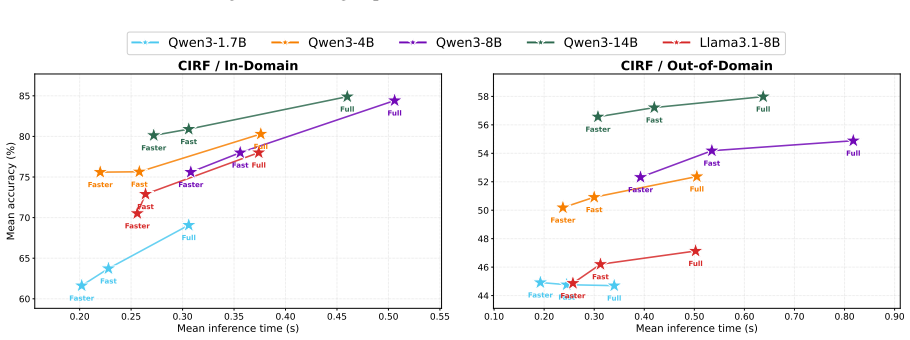
- The method yields a favorable accuracy-latency trade-off on mathematical, symbolic, and commonsense reasoning benchmarks relative to existing implicit CoT approaches.
- Functional tokens remain distinct and interpretable after training and produce consistent gains across tasks.
- Reasoning length adapts automatically to example complexity because the model generates only the needed sequence of functional tokens.
- Parallel training is enabled by the fixed token vocabulary and the separation of token generation from final-answer prediction.
Where Pith is reading between the lines
- The same functional-token vocabulary could in principle be reused across different models or tasks once the initial extraction step is complete.
- If the tokens prove composable, new reasoning chains might be assembled without retraining by substituting or reordering learned units.
- Interpretability of the tokens opens a route to inspecting which reasoning steps the model treats as atomic.
Load-bearing premise
Semantically coherent reasoning units can be identified in explicit CoT traces and turned into tokens that the model can generate autoregressively while staying aligned with the original rationales.
What would settle it
A controlled comparison on the same benchmarks in which CIRF yields no improvement in accuracy at equal or lower latency than the strongest prior implicit CoT baseline would falsify the central performance claim.
Figures


read the original abstract
Implicit Chain-of-Thought (CoT) reduces the inference cost of large language models by internalizing the explicit rationales. However, existing approaches typically lack alignment with explicit rationales and adaptivity to example complexity. In this work, we propose CIRF (\textit{\underline{C}hain-of-thoughts \underline{I}nto \underline{R}eusable \underline{F}unctional units}), an implicit CoT framework that performs reasoning as a dynamic sequence of discrete functional tokens. CIRF assigns a functional token to each semantically coherent reasoning unit in explicit CoT traces. The model is then fine-tuned to autoregressively generate functional tokens and their optional results, followed by the final answer. This design aligns latent reasoning with a sequence of functional units, facilitating parallel training, explicit rationale alignment, and adaptive reasoning. Extensive experiments on mathematical, symbolic, and commonsense reasoning benchmarks show that CIRF provides a favorable accuracy-latency trade-off compared with state-of-the-art implicit CoT methods. Further analyses demonstrate that CIRF constructs distinct, interpretable functional tokens, leading to consistent performance improvements.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CIRF, an implicit Chain-of-Thought framework that partitions explicit CoT traces into semantically coherent reasoning units, assigns each a distinct functional token, fine-tunes the LLM to autoregressively generate sequences of these tokens (plus optional results) before the final answer, and claims this yields a superior accuracy-latency trade-off versus prior implicit CoT methods on mathematical, symbolic, and commonsense benchmarks while producing distinct, interpretable tokens.
Significance. If the core mechanism can be made reproducible, the approach would strengthen alignment between latent and explicit reasoning and improve adaptivity to problem complexity, addressing two documented weaknesses of existing implicit CoT methods.
major comments (2)
- [Abstract / framework description] Abstract and framework description paragraph: the procedure for identifying semantically coherent reasoning units from explicit CoT traces (manual annotation, rule-based segmentation, clustering, or model-assisted) is never stated. This identification step is load-bearing for every subsequent claim—alignment, reusability, autoregressive generation, and performance gains—yet remains completely unspecified.
- [Abstract] Abstract: the claim of 'extensive experiments' showing a 'favorable accuracy-latency trade-off' is unsupported by any numbers, baselines, datasets, or error bars in the provided text. Without these data the central empirical claim cannot be evaluated.
minor comments (1)
- [Abstract] The abstract would benefit from a one-sentence summary of the key quantitative results (e.g., accuracy deltas and latency reductions on the primary benchmarks).
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below and outline the revisions we will make.
read point-by-point responses
-
Referee: [Abstract / framework description] Abstract and framework description paragraph: the procedure for identifying semantically coherent reasoning units from explicit CoT traces (manual annotation, rule-based segmentation, clustering, or model-assisted) is never stated. This identification step is load-bearing for every subsequent claim—alignment, reusability, autoregressive generation, and performance gains—yet remains completely unspecified.
Authors: We agree that the manuscript does not specify the procedure used to partition explicit CoT traces into semantically coherent reasoning units. This detail is necessary for reproducibility. In the revised manuscript we will add an explicit description of the segmentation method (including the criteria and any automation involved) in the Methods section. revision: yes
-
Referee: [Abstract] Abstract: the claim of 'extensive experiments' showing a 'favorable accuracy-latency trade-off' is unsupported by any numbers, baselines, datasets, or error bars in the provided text. Without these data the central empirical claim cannot be evaluated.
Authors: The abstract is a concise summary; the full manuscript contains the complete experimental details, including all datasets, baselines, accuracy and latency numbers, and error bars, in the Experiments section. We can incorporate one or two key quantitative highlights into the abstract if the editor prefers, but we believe the current level of detail is standard for abstracts. revision: partial
Circularity Check
No circularity in derivation; empirical framework with no self-referential reductions
full rationale
The paper proposes an implicit CoT method by partitioning explicit traces into functional units and fine-tuning for autoregressive token generation. No equations, fitted parameters, or predictions are described that reduce by construction to their own inputs. Claims rest on benchmark experiments rather than a mathematical chain that collapses to self-definition, self-citation, or renamed ansatzes. The unit-identification step is a methodological choice whose validity is tested externally via performance metrics, not presupposed by the framework itself.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word prob- lems.CoRR, abs/2110.14168. Yuntian Deng, Yejin Choi, and Stuart Shieber. 2024. From explicit CoT to implicit CoT: Learning to inter- nalize CoT step by step.CoRR, abs/2405.14838. Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Are NLP models really able to solve simple math word problems? InProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 2080–2094, Online. Association for Computational Linguistics. Jacob Pfau, William Merrill, and Samuel R. Bow- man. 2024. Let’s think dot by do...
-
[3]
Sim-cot: Supervised implicit chain-of-thought.arXiv preprint arXiv:2509.20317, 2025
Guiding language model reasoning with plan- ning tokens. InFirst Conference on Language Mod- eling (COLM). OpenReview.net. Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V . Le, Ed H. Chi, Sharan Narang, Aakanksha Chowd- hery, and Denny Zhou. 2023. Self-consistency im- proves chain of thought reasoning in language mod- els. InThe Eleventh International Con...
-
[4]
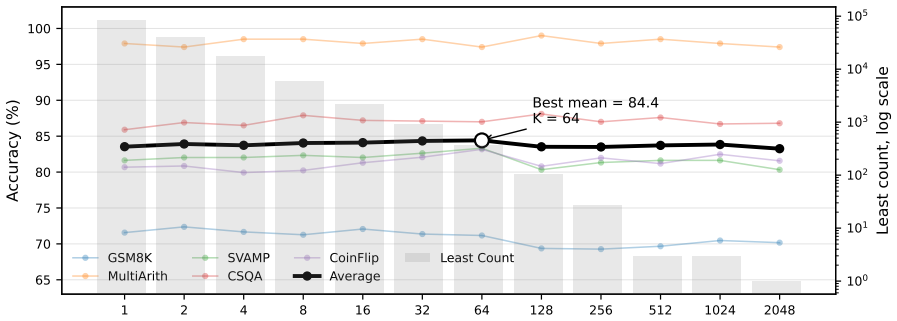
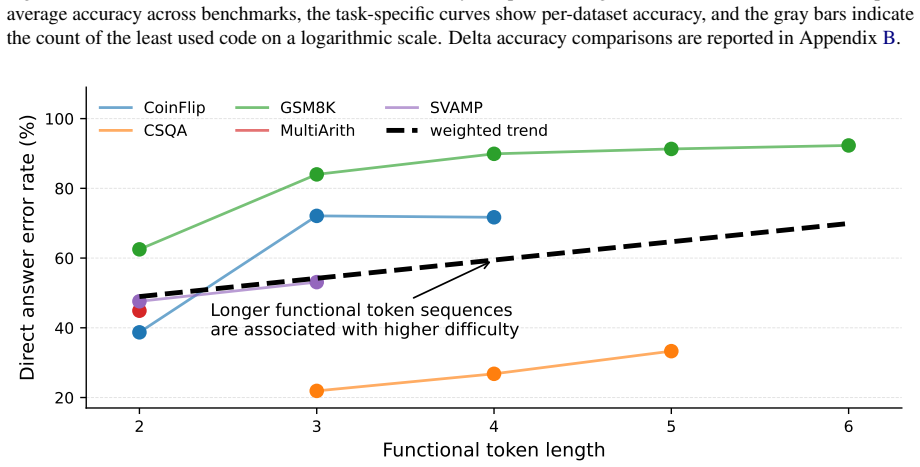
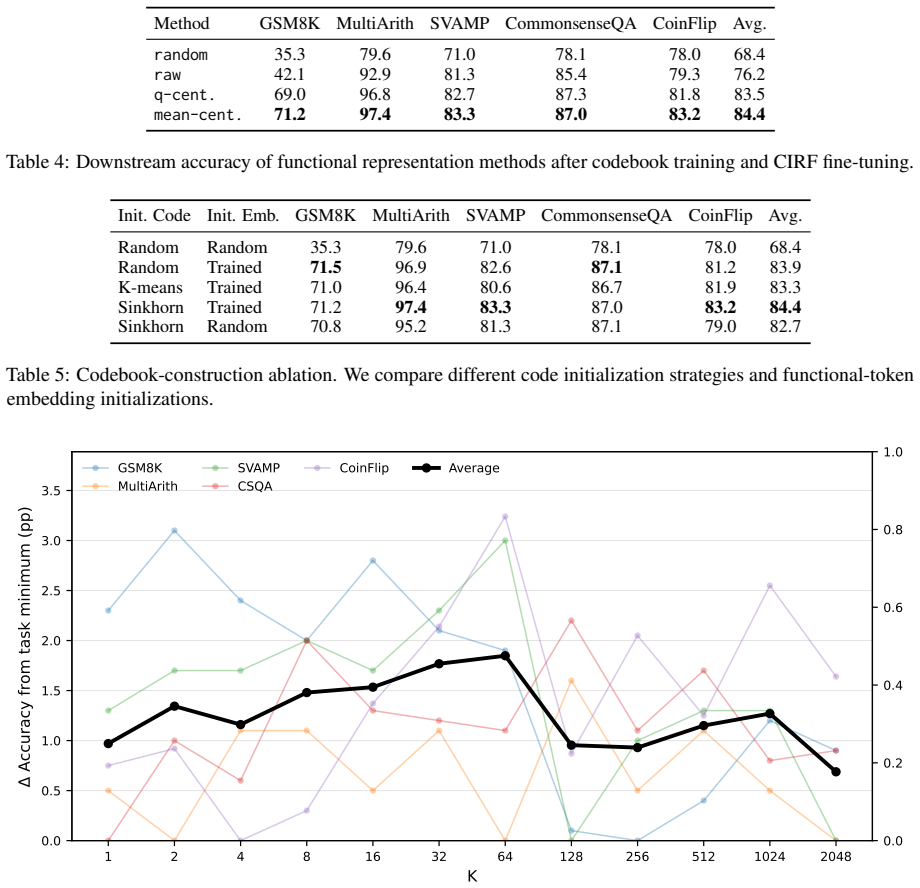
These results support that mean-centering sup- presses question-specific situational bias while pre- serving reusable reasoning functionality. 14 0.2 0.3 0.4 0.5 0.6 45 50 55 60 65 70Mean accuracy (%) Qwen3-1.7B / In-Domain Pause CODI CIRFFull CIRFFast CIRFFaster 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 40 50 60 70 80 Qwen3-4B / In-Domain Pause CODI CIRFFull CIRFF...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.