HELEA: Hard-Negative Benchmark and LLM-based Reranking for Robust Entity Alignment
Pith reviewed 2026-06-29 13:03 UTC · model grok-4.3
The pith
Entity alignment models can be made robust to name collisions by training retrieval on hard negatives from knowledge graph name overlaps and reranking candidates with an LLM.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
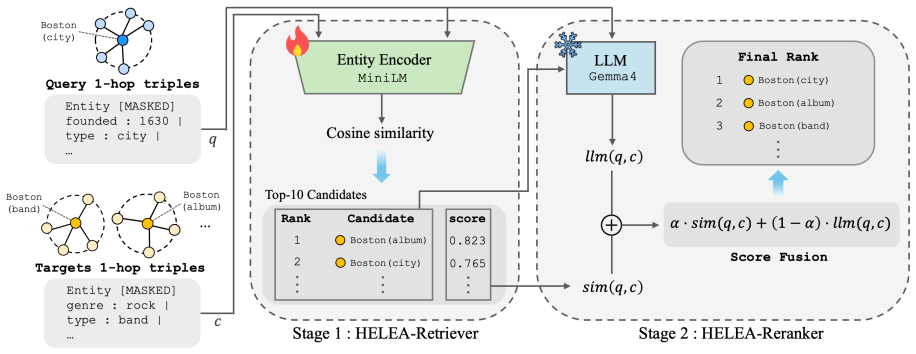
The paper establishes that a same-name hard-negative augmentation strategy, which extracts distinct entity pairs from knowledge graph name-collision groups, produces reliable hard-negative benchmarks and training sets. When combined with a two-stage process of context-aware retrieval followed by LLM reranking, this yields a system that achieves an F1 score of 0.967 on the DW-HN29K benchmark while preserving a Hit@1 of 0.993 on the standard DW-15K dataset, demonstrating robustness beyond name overlap.
What carries the argument
The same-name hard-negative augmentation strategy that mines distinct entity pairs from KG name-collision groups to create benchmarks and training data, combined with the two-stage HELEA framework of entity encoder retrieval using 1-hop context and LLM-based reranking without additional training.
If this is right
- Name-dependent baselines collapse to near-random performance on the hard-negative benchmarks.
- HELEA maintains high Hit@1 on standard benchmarks like DW-15K while scoring F1 0.967 on DW-HN29K.
- Augmented training corpora with 1-hop context improve robustness when name overlap is removed as a cue.
- LLM reranking can be added without further training to refine top candidates from the encoder.
- Entity alignment evaluation must control for name collisions to test reliance on relational structure.
Where Pith is reading between the lines
- The hard-negative mining approach could extend to other graph tasks such as link prediction where surface features mislead models.
- Evaluating the method on additional knowledge graphs beyond the DW and DY families would test its broader applicability.
- Using more than one hop of context in the encoder might further reduce dependence on any remaining superficial signals.
- This work points to a general need for benchmark designs that isolate relational reasoning in knowledge graph applications.
Load-bearing premise
The automatically mined same-name but distinct entity pairs from knowledge graph name-collision groups constitute quality-controlled hard negatives that genuinely require relational structure rather than name overlap to resolve correctly.
What would settle it
If a simple name-matching baseline achieves high F1 on DW-HN29K or DY-HN27K, or if HELEA's Hit@1 falls substantially below 0.993 on the standard DW-15K dataset.
Figures


read the original abstract
Entity Alignment (EA) is essential for knowledge graph (KG) fusion, but existing benchmarks often allow models to exploit name overlap rather than relational structure. This makes it difficult to evaluate whether models can reject same-name entities that refer to different real-world objects. Our primary contribution is a same-name hard-negative augmentation strategy that simultaneously yields quality-controlled evaluation benchmarks (DW-HN29K, DY-HN27K) and augmented training corpora (DW-Train, DY-Train), by mining same-name but distinct entity pairs from KG name-collision groups. We further introduce HELEA, a two-stage framework integrating (i) entity encoder retrieval trained on hard-negative-augmented training corpora with 1-hop KG context, and (ii) LLM-based reranking without additional training. Experiments show that name-dependent baselines collapse to near-random performance on our hard-negative benchmarks, while HELEA achieves F1 0.967 on DW-HN29K while maintaining Hit@1 0.993 on standard DW-15K.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a same-name hard-negative augmentation strategy for entity alignment that mines same-name but distinct entity pairs from KG name-collision groups, producing hard-negative benchmarks (DW-HN29K, DY-HN27K) and augmented training corpora. It proposes HELEA, a two-stage framework with (i) an entity encoder retrieval model trained on the augmented data using 1-hop KG context and (ii) LLM-based reranking without further training. Experiments claim that name-dependent baselines collapse to near-random performance on the new benchmarks while HELEA reaches F1 0.967 on DW-HN29K and Hit@1 0.993 on standard DW-15K.
Significance. If the mined pairs constitute valid hard negatives that genuinely require relational structure, the benchmarks would address a recognized limitation in EA evaluation where models exploit name overlap. The training-free LLM reranking component is a practical contribution. The reported collapse of baselines would be a useful empirical result if the benchmark construction is sound.
major comments (1)
- [Abstract / mining strategy] The same-name hard-negative augmentation strategy is described as producing 'quality-controlled' benchmarks, yet the abstract (and by extension the central empirical claims) provides no quantitative details on collision resolution, false-positive rate among mined pairs, or external validation that the pairs are verifiably distinct real-world entities without residual name-overlap signals. This is load-bearing because the collapse of name-dependent baselines to near-random performance and HELEA's F1 0.967 both presuppose that the pairs require relational reasoning rather than name cues or labeling errors.
minor comments (1)
- The abstract reports precise performance numbers (F1 0.967, Hit@1 0.993) but does not outline the experimental protocol, quality-control steps, or validation of the mined pairs; these details should be added to the main text for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the benchmark construction. We address the concern about quantitative details in the abstract below and will make corresponding revisions.
read point-by-point responses
-
Referee: [Abstract / mining strategy] The same-name hard-negative augmentation strategy is described as producing 'quality-controlled' benchmarks, yet the abstract (and by extension the central empirical claims) provides no quantitative details on collision resolution, false-positive rate among mined pairs, or external validation that the pairs are verifiably distinct real-world entities without residual name-overlap signals. This is load-bearing because the collapse of name-dependent baselines to near-random performance and HELEA's F1 0.967 both presuppose that the pairs require relational reasoning rather than name cues or labeling errors.
Authors: We agree that the abstract would be strengthened by including quantitative details on the mining process. The full manuscript describes the same-name hard-negative augmentation as mining distinct pairs from name-collision groups with quality control via structural filters (detailed in the methods). We will revise the abstract to report key statistics on collision group sizes, the resolution approach, and filtering criteria used to produce the benchmarks. The observed collapse of name-dependent baselines to near-random performance on DW-HN29K and DY-HN27K provides supporting evidence that the pairs necessitate relational reasoning beyond name overlap. We do not have a separately measured false-positive rate from external validation, but the construction process and empirical results address the core concern. revision: yes
Circularity Check
No circularity: empirical benchmark construction and evaluation
full rationale
The paper's core contribution is the construction of new hard-negative benchmarks (DW-HN29K, DY-HN27K) via mining same-name distinct pairs from KG name-collision groups, followed by empirical evaluation of baselines and the HELEA framework. Reported metrics such as F1 0.967 and Hit@1 0.993 are direct experimental measurements on these benchmarks and standard datasets, not quantities obtained by fitting parameters to a subset and then predicting a closely related value, nor by any self-referential definition or equation that reduces to its inputs. No load-bearing self-citations, uniqueness theorems, or ansatzes are invoked in the abstract or described claims. The derivation chain consists of data construction followed by measurement; it is self-contained against external benchmarks and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Knowledge graphs contain name-collision groups from which same-name but distinct entities can be mined to create quality-controlled hard negatives.
Reference graph
Works this paper leans on
-
[1]
InAdvances in Neural Information Processing Systems, volume 26
Translating embeddings for modeling multi- relational data. InAdvances in Neural Information Processing Systems, volume 26. Curran Associates, Inc. Muhao Chen, Yingtao Tian, Mohan Yang, and Carlo Zaniolo. 2017. Multilingual knowledge graph embed- dings for cross-lingual knowledge alignment. InPro- ceedings of the Twenty-Sixth International Joint Con- fere...
2017
-
[2]
9 Lingbing Guo, Zequn Sun, and Wei Hu
https://ai.google.dev/gemma/docs/core/ model_card_4. 9 Lingbing Guo, Zequn Sun, and Wei Hu. 2019. Learning to exploit long-term relational dependencies in knowl- edge graphs. InProceedings of the 36th International Conference on Machine Learning, volume 97 ofPro- ceedings of Machine Learning Research, pages 2505–
2019
-
[3]
PMLR. Aidan Hogan, Eva Blomqvist, Michael Cochez, Clau- dia D’amato, Gerard De Melo, Claudio Gutierrez, Sabrina Kirrane, José Emilio Labra Gayo, Roberto Navigli, Sebastian Neumaier, Axel-Cyrille Ngonga Ngomo, Axel Polleres, Sabbir M. Rashid, Anisa Rula, Lukas Schmelzeisen, Juan Sequeda, Steffen Staab, and Antoine Zimmermann. 2021. Knowledge graphs. ACM Co...
-
[4]
Jeff Johnson, Matthijs Douze, and Herve Jegou
Hlmea: Unsupervised entity alignment based on hybrid language models.Proceedings of the AAAI Conference on Artificial Intelligence, 39(11):11888– 11896. Jeff Johnson, Matthijs Douze, and Herve Jegou. 2021. Billion-Scale Similarity Search with GPUs .IEEE Transactions on Big Data, 7(03):535–547. Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zh...
2021
-
[5]
gpt-oss-120b & gpt-oss-20b Model Card
Selfkg: Self-supervised entity alignment in knowledge graphs. InProceedings of the ACM Web Conference 2022, page 860–870. ACM. Zhiyuan Liu, Yixin Cao, Liangming Pan, Juanzi Li, Zhiyuan Liu, and Tat-Seng Chua. 2020. Exploring and evaluating attributes, values, and structures for entity alignment. InProceedings of the 2020 Con- ference on Empirical Methods ...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[6]
Cross-lingual Entity Alignment via Joint Attribute-Preserving Embedding
Yago: A multilingual knowledge base from wikipedia, wordnet, and geonames. pages 177–185. Nils Reimers and Iryna Gurevych. 2019. Sentence- BERT: Sentence embeddings using Siamese BERT- networks. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natu- ral Language Processi...
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[7]
Bootstrapping entity alignment with knowl- edge graph embedding. InProceedings of the Twenty- Seventh International Joint Conference on Artificial Intelligence, IJCAI-18, pages 4396–4402. Interna- tional Joint Conferences on Artificial Intelligence Organization. Zequn Sun, Jiacheng Huang, Xiaozhou Xu, Qijin Chen, Weijun Ren, and Wei Hu. 2023. What makes e...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.