Plan Before Search: Search Agents Need Plan
Pith reviewed 2026-06-29 12:29 UTC · model grok-4.3
The pith
A small-scale seed model generates filtered trajectories that activate Plan behavior in target models for multi-hop retrieval without external distillation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
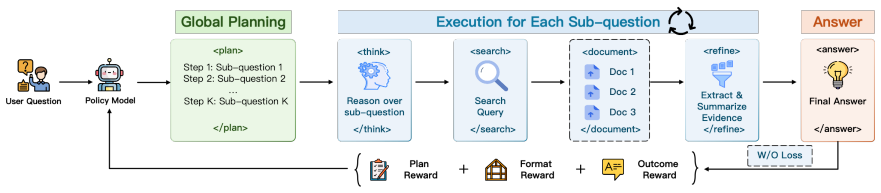
The paper claims that Plan, defined as decomposing a question into ordered sub-questions before any retrieval occurs, can be activated in target models through a self-bootstrapping paradigm that uses filtered trajectories generated by a small-scale seed model, and that this approach works across model families without distillation from an external stronger model while delivering consistent gains over competitive baselines on multi-hop QA benchmarks.
What carries the argument
Plan, the structured agentic behavior that decomposes a question into ordered sub-questions before retrieval to anchor search steps and prevent drift from partially relevant documents.
If this is right
- The pipeline activates Plan across every tested model from 3B to 14B parameters.
- It consistently outperforms competitive baselines on multi-hop QA benchmarks.
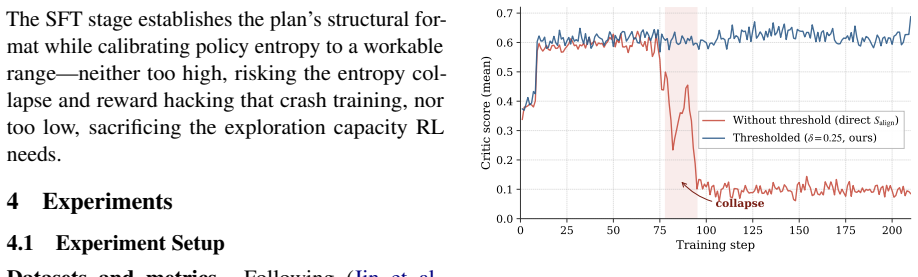
- Successful training depends on model-specific feasibility conditions including sufficient initial entropy, training stability, and prerequisite sub-skills.
- An identical reward signal induces qualitatively different RL failure modes across model families.
- The self-bootstrapping method eliminates the need for distillation from an external stronger model.
Where Pith is reading between the lines
- The approach implies that internal trajectory filtering can substitute for external teacher models in acquiring structured agent behaviors.
- Similar bootstrapping may apply to other agentic skills such as verification or tool use beyond planning.
- Model-specific initial conditions could become a standard diagnostic step before RL training of search agents.
- The method might reduce overall compute by avoiding repeated calls to larger teacher models during capability acquisition.
Load-bearing premise
That filtered trajectories generated by a small-scale seed model are sufficient to activate the Plan behavior in any target model without requiring distillation from an external stronger model.
What would settle it
A direct test applying the seed-model trajectories to a target model outside the 3B-14B range or lacking prerequisite sub-skills and measuring whether Plan activation and benchmark gains still occur.
Figures






read the original abstract
Training large language models as retrieval-augmented reasoning agents typically combines reinforcement learning with an SFT cold start distilled from a stronger model. However, this paradigm overlooks two fundamental factors: the dependency structure among sub-skills, and the possibility that distillation is not the only route to capability acquisition. We study this through Plan, a structured agentic behavior for multi-hop retrieval that decomposes a question into ordered sub-questions before any retrieval is performed, so that each search step can be anchored to a pre-designed sub-question instead of drifting under the influence of partially relevant documents retrieved earlier. However, across three model families spanning 3B to 14B parameters, we find that an identical reward signal induces qualitatively different RL failure modes. This phenomenon indicates that successful training hinges not only on reward design but also on model-specific feasibility conditions: sufficient initial entropy, training stability, and prerequisite sub-skills. Motivated by this, we propose a self-bootstrapping paradigm in which a small-scale seed model generates filtered trajectories that activate Plan in any target model, eliminating the need for distillation from an external stronger model. Our pipeline activates Plan across every tested model and consistently outperforms competitive baselines on multi-hop QA benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that standard RL training of retrieval-augmented agents requires an SFT cold-start distilled from a stronger model, but overlooks sub-skill dependencies and alternative acquisition routes. It defines 'Plan' as a structured behavior that decomposes a multi-hop question into an ordered list of sub-questions before any retrieval occurs. Across three model families (3B–14B), identical reward signals produce qualitatively different RL failure modes, which the authors attribute to model-specific conditions including initial entropy, stability, and prerequisite sub-skills. They therefore introduce a self-bootstrapping pipeline in which a small-scale seed model generates filtered trajectories that are used to activate Plan behavior in any target model, eliminating the need for stronger-model distillation. The pipeline is stated to activate Plan in every tested model and to outperform competitive baselines on multi-hop QA benchmarks.
Significance. If the empirical claims hold, the work would be significant for showing that a self-bootstrapping route using only a small seed model can replace distillation from a stronger model when training agentic retrieval behaviors. The observation that identical rewards induce different failure modes across model families supplies a concrete diagnostic for why RL succeeds or fails on agent tasks and underscores the role of prerequisite sub-skills. The approach is falsifiable via the reported multi-hop QA results and the cross-family activation experiments.
major comments (2)
- [Abstract] Abstract: the claim of 'consistent outperformance across model families' and 'outperforms competitive baselines' is presented without any quantitative results, error bars, baseline specifications, or controls, so the central empirical claim cannot be evaluated from the supplied text.
- [Method] Method / self-bootstrapping section: the central claim that filtered trajectories from the small-scale seed model suffice to activate Plan 'in any target model' without stronger-model distillation rests on the unverified assumption that the seed already possesses (or filtering reliably extracts) the prerequisite sub-skills. The paper itself notes that identical rewards produce different failure modes precisely because of missing sub-skills; no experiment is described that tests whether the 3B-scale seed trajectories are high-entropy and on-distribution enough to avoid reproducing the documented RL instabilities.
minor comments (2)
- Clarify the precise parameter counts of the seed model and each target model, and state whether the seed is from the same family as the targets.
- Specify the exact filtering criteria applied to the seed trajectories and report the fraction of trajectories retained.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point-by-point below. We agree the abstract requires quantitative support and will revise it. For the self-bootstrapping method, we provide clarification on the role of filtering while acknowledging the need for additional discussion of trajectory properties.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of 'consistent outperformance across model families' and 'outperforms competitive baselines' is presented without any quantitative results, error bars, baseline specifications, or controls, so the central empirical claim cannot be evaluated from the supplied text.
Authors: We agree that the abstract would be strengthened by including quantitative details. In the revised manuscript we will update the abstract to report specific performance metrics on the multi-hop QA benchmarks, note the consistency of gains across the three model families, and identify the competitive baselines used. This change will make the central empirical claims directly evaluable from the abstract. revision: yes
-
Referee: [Method] Method / self-bootstrapping section: the central claim that filtered trajectories from the small-scale seed model suffice to activate Plan 'in any target model' without stronger-model distillation rests on the unverified assumption that the seed already possesses (or filtering reliably extracts) the prerequisite sub-skills. The paper itself notes that identical rewards produce different failure modes precisely because of missing sub-skills; no experiment is described that tests whether the 3B-scale seed trajectories are high-entropy and on-distribution enough to avoid reproducing the documented RL instabilities.
Authors: We recognize the logical connection to our own observations on model-specific RL failure modes. The pipeline's filtering step selects trajectories that already exhibit ordered sub-question decomposition, which our cross-family experiments show is sufficient to activate Plan in target models without triggering the documented instabilities. While a dedicated entropy or distribution analysis of the raw seed trajectories is not reported, the consistent activation success across 3B–14B models serves as empirical evidence that the filtered data avoids the problematic conditions. We will revise the method section to expand the description of the filtering criteria and their relation to preserving prerequisite sub-skills and training stability. revision: partial
Circularity Check
No circularity; empirical self-bootstrapping claim stands on experimental results
full rationale
The paper presents an empirical pipeline in which a small seed model produces filtered trajectories to activate Plan behavior in target models, with success demonstrated across three model families on multi-hop QA benchmarks. No derivation reduces by construction to fitted inputs, self-citations, or definitional loops; the central claim is framed as an observed outcome of the proposed self-bootstrapping method rather than a mathematical identity or renamed known result. The text supplies no load-bearing self-citations, uniqueness theorems, or ansatzes smuggled via prior work, rendering the chain self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Successful RL training of Plan requires sufficient initial entropy, training stability, and prerequisite sub-skills that vary by model.
invented entities (1)
-
Plan
no independent evidence
Reference graph
Works this paper leans on
-
[1]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Group-in-group policy optimization for llm agent training.Advances in Neural Information Pro- cessing Systems, 38:46375–46408. Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, and 1 others. 2025. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv pr...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
s3: You don’t need that much data to train a search agent via rl. InProceedings of the 2025 Con- ference on Empirical Methods in Natural Language Processing, pages 21610–21628. Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan Arik, Dong Wang, Hamed Zamani, and Jiawei Han. 2025. Search-r1: Training llms to reason and leverage search engines with re...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
R1-Searcher: Incentivizing the Search Capability in LLMs via Reinforcement Learning
Search and refine during think: Autonomous retrieval-augmented reasoning of llms.arXiv e- prints, pages arXiv–2505. Huatong Song, Jinhao Jiang, Yingqian Min, Jie Chen, Zhipeng Chen, Wayne Xin Zhao, Lei Fang, and Ji- Rong Wen. 2025. R1-searcher: Incentivizing the search capability in llms via reinforcement learning. arXiv preprint arXiv:2503.05592. Hao Sun...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
All I Can Think About Is Getting You Home
Internvl-u: Democratizing unified multimodal models for understanding, reasoning, generation and editing.arXiv preprint arXiv:2603.09877. Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. 2022. Musique: Multi- hop questions via single-hop question composition. Transactions of the Association for Computational Linguistics, 10:539–...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.