SA4Depth: Consistent Pose-Depth Scale Alignment for Self-Supervised Monocular Depth Estimation
Pith reviewed 2026-06-29 12:43 UTC · model grok-4.3
The pith
Reprojecting depth-estimated features refines pose and aligns scene scales in self-supervised monocular depth estimation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
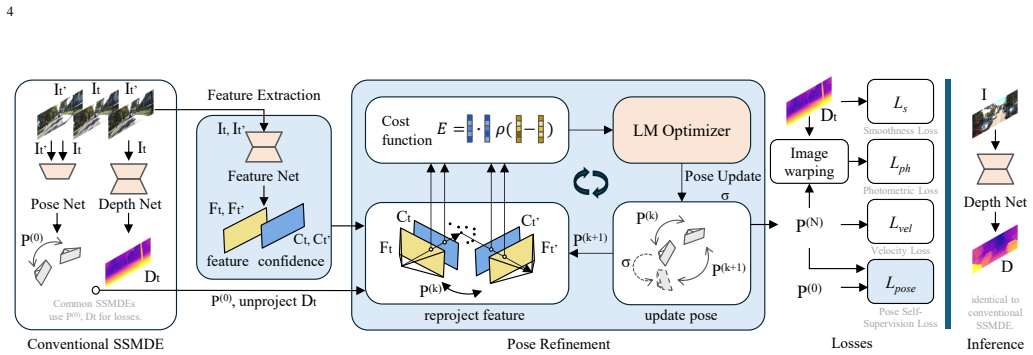
By using the depth estimated during training to reproject learnable visual features across consecutive frames and refining the pose estimates through reduction of feature alignment residuals, the scene scales produced by the separate depth and pose networks become aligned and the scale consistency of depth predictions improves across different sequences.
What carries the argument
A differentiable pose-refinement step that reprojects learnable visual features using the current depth estimate and minimizes the resulting frame-to-frame alignment residuals.
If this is right
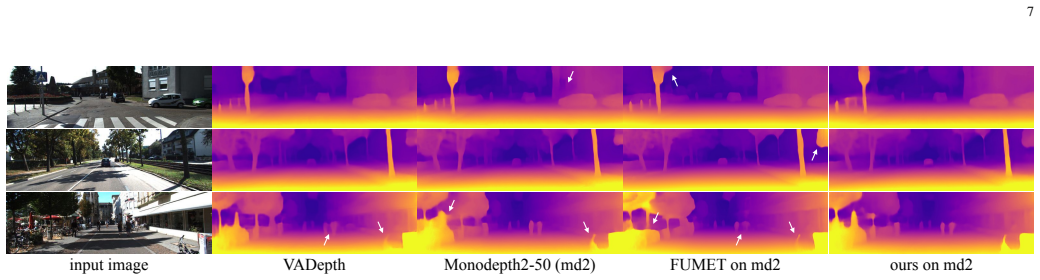
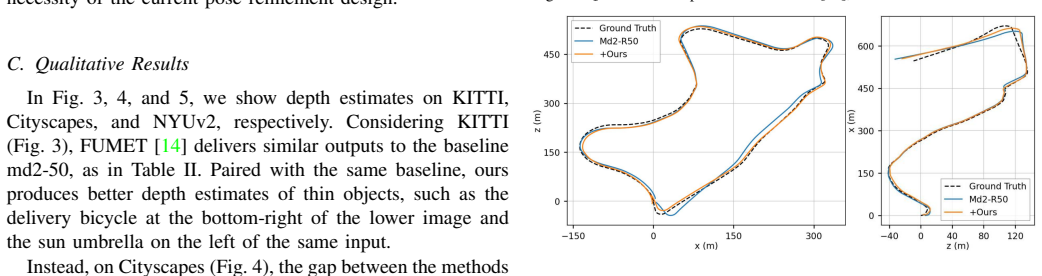
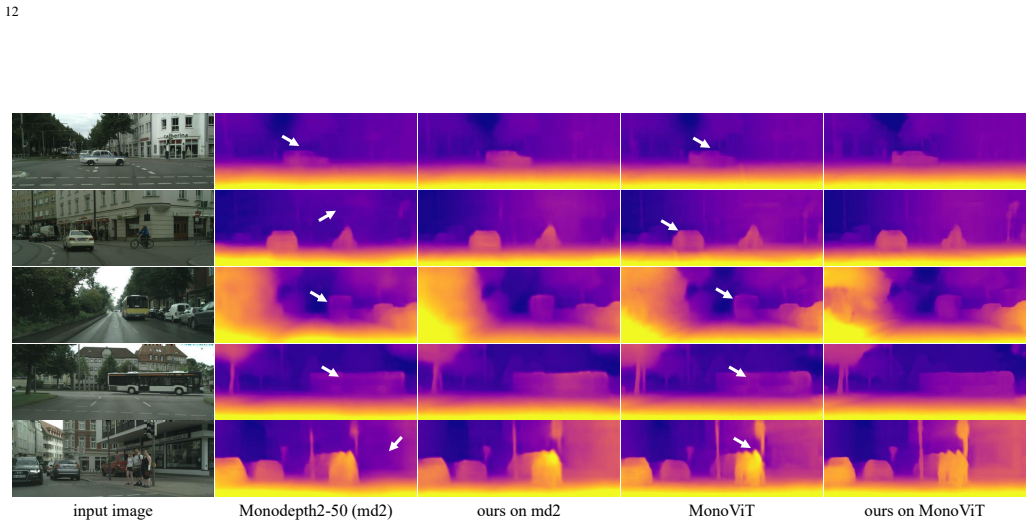
- Depth accuracy improves on both outdoor sequences (KITTI, Cityscapes) and indoor scenes (NYUv2).
- Pose estimates become more accurate, as verified on KITTI Odometry benchmarks.
- Scale consistency across sequences rises without any added computation at inference time.
- The refinement module can be inserted into existing self-supervised training pipelines without architectural changes.
- The method leaves inference speed and model size unchanged.
Where Pith is reading between the lines
- The same residual-minimization idea could be tested on joint depth-and-flow estimation to see whether scale drift decreases over longer videos.
- If feature quality is the dominant factor, replacing the learnable features with fixed pretrained descriptors would provide a direct test of how much the improvement relies on joint learning.
- The approach may reduce the need for explicit scale-normalization post-processing when the depth maps are fed into downstream visual odometry systems.
Load-bearing premise
That the reduction of feature alignment residuals will correct scale mismatches between the depth and pose networks rather than allowing unrelated errors to trade off against each other.
What would settle it
Apply the refinement on NYUv2 sequences, compute the variance of recovered scale factors across consecutive frames before and after, and observe that the variance does not decrease while depth accuracy stays the same or worsens.
Figures




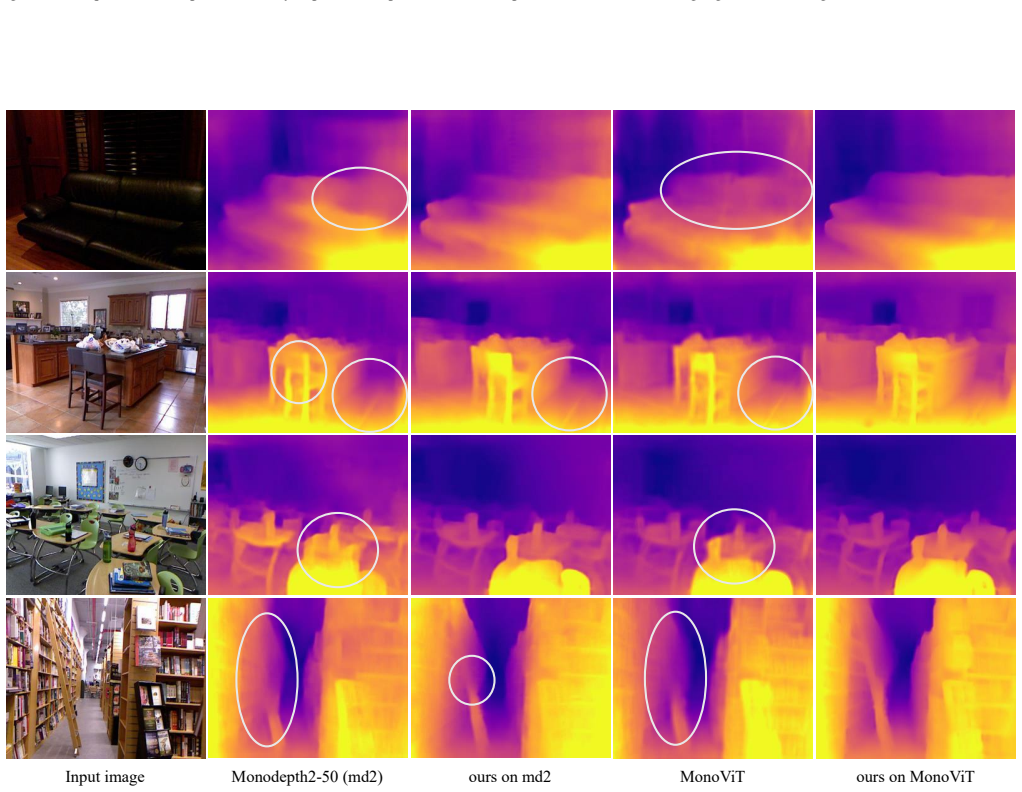
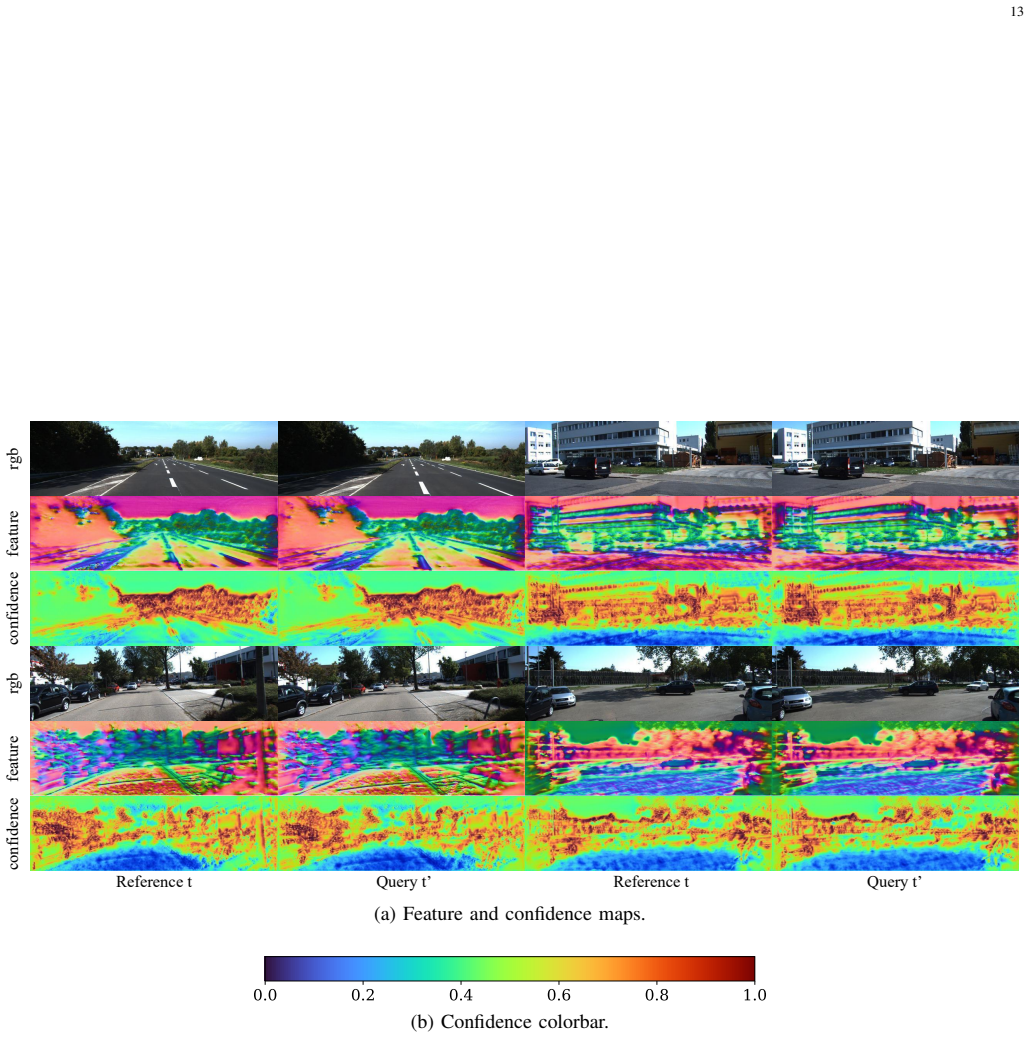
read the original abstract
Self-supervised depth estimation from monocular sequences relies on the joint learning of a depth and a pose network. Despite abundant research done to improve the depth network, efforts on the pose remain limited. In this context, even when depth is estimated up to scale, we highlight the importance of the alignment between the scene scales estimated by the pose and depth nets. Then, we introduce SA4Depth, an approach to improve this alignment and boost the depth predictions while keeping the inference time unchanged. Our proposed method uses the depth estimated during training to reproject learnable visual features across consecutive frames and refine the pose estimates by reducing feature alignment residuals. With our method, the estimated scene scales by the separate depth and pose networks are aligned, and the prediction scale consistency is improved across different sequences. Our differentiable refinement integrates seamlessly into existing self-supervised pipelines and substantially improves their depth estimates. We demonstrate this with extensive experiments both outdoors and indoors on KITTI, Cityscapes, and NYUv2. Additionally, results on KITTI Odometry confirm the effectiveness of our pose refinement. Our code is available at https://github.com/Runningchauncey/SA4Depth .
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SA4Depth for self-supervised monocular depth estimation. It identifies scale inconsistency between jointly trained depth and pose networks as a key limitation and proposes to address it by using the depth estimate to reproject learnable visual features across frames, then refining the pose network by minimizing the resulting feature alignment residuals. The method is presented as a differentiable module that integrates into existing pipelines, improves depth accuracy, and yields more consistent scale predictions across sequences, with supporting experiments on KITTI, Cityscapes, NYUv2, and KITTI Odometry.
Significance. If the proposed feature-residual refinement demonstrably enforces global scale alignment rather than permitting local compensation, the approach would be a practical and low-overhead contribution to self-supervised depth pipelines. The unchanged inference cost, public code release, and multi-dataset evaluation (including odometry) are strengths. The core idea targets a recognized but under-addressed inconsistency between the two networks.
major comments (2)
- [Abstract / §3] Abstract and §3 (method description): the central claim that minimizing depth-reprojected feature residuals aligns the scene scales estimated by the depth and pose networks lacks an explicit derivation or stationary-point analysis showing that the equilibrium of the combined loss corresponds to matched scales rather than to compensating local adjustments in either network. The construction permits pose adjustments that absorb depth errors without enforcing global scale consistency.
- [§4] §4 (experiments): the reported depth improvements and cross-sequence scale consistency gains are not accompanied by an ablation that isolates the scale-alignment effect from other changes in the training objective or from hyper-parameter tuning; without such controls it is difficult to attribute gains specifically to the claimed mechanism.
minor comments (2)
- [§3] Notation for the feature reprojection and residual loss should be introduced with explicit equations rather than descriptive prose only.
- [§3] The manuscript should clarify whether the learnable visual features are frozen or jointly optimized with the depth/pose networks.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract / §3] Abstract and §3 (method description): the central claim that minimizing depth-reprojected feature residuals aligns the scene scales estimated by the depth and pose networks lacks an explicit derivation or stationary-point analysis showing that the equilibrium of the combined loss corresponds to matched scales rather than to compensating local adjustments in either network. The construction permits pose adjustments that absorb depth errors without enforcing global scale consistency.
Authors: We acknowledge that the manuscript provides no formal stationary-point analysis or derivation establishing that the equilibrium necessarily enforces global scale matching rather than local compensations. The design intends global alignment because the feature re-projection operates over the full image and multiple frames, but we agree this is not rigorously shown. In revision we will add a short explanatory paragraph in §3 clarifying the mechanism and why local pose adjustments alone cannot minimize the residuals without scale consistency; this constitutes a partial revision as the core method description remains unchanged. revision: partial
-
Referee: [§4] §4 (experiments): the reported depth improvements and cross-sequence scale consistency gains are not accompanied by an ablation that isolates the scale-alignment effect from other changes in the training objective or from hyper-parameter tuning; without such controls it is difficult to attribute gains specifically to the claimed mechanism.
Authors: We agree that the experiments would benefit from ablations that isolate the contribution of the scale-alignment refinement. The current results compare complete pipelines but do not hold all other factors fixed while toggling only the proposed module. In the revised manuscript we will include controlled ablations that enable or disable the SA4Depth refinement while keeping the training objective, hyperparameters, and network architectures identical, thereby directly attributing improvements to the scale-alignment component. revision: yes
Circularity Check
No circularity: scale alignment presented as optimization outcome, not tautological definition
full rationale
The paper introduces an auxiliary differentiable loss that reprojects features using the depth network output to refine the pose network via residual minimization. The claim that this produces consistent scene-scale alignment between the two networks is framed as an empirical consequence of the joint optimization rather than a quantity defined in terms of itself or recovered by fitting a parameter to the target metric. No self-citation chain, ansatz smuggling, or renaming of a known result is used to establish the central result; the derivation remains self-contained against external benchmarks such as KITTI and NYUv2 depth metrics.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Holistic 3d scene understanding from a single image with implicit representation,
C. Zhang, Z. Cui, Y . Zhang, B. Zeng, M. Pollefeys, and S. Liu, “Holistic 3d scene understanding from a single image with implicit representation,” inCVPR, 2021, pp. 8833–8842
2021
-
[2]
DepthSplat: Connecting gaussian splatting and depth,
H. Xu, S. Peng, F. Wang, H. Blum, D. Barath, A. Geiger, and M. Polle- feys, “DepthSplat: Connecting gaussian splatting and depth,” inCVPR, 2025, pp. 16 453–16 463
2025
-
[3]
Visual attention- based self-supervised absolute depth estimation using geometric priors in autonomous driving,
J. Xiang, Y . Wang, L. An, H. Liu, Z. Wang, and J. Liu, “Visual attention- based self-supervised absolute depth estimation using geometric priors in autonomous driving,”IEEE RAL, vol. 7, no. 4, pp. 11 998–12 005, 2022
2022
-
[4]
Orb-slam2: An open-source slam system for monocular, stereo, and rgb-d cameras,
R. Mur-Artal and J. D. Tard ´os, “Orb-slam2: An open-source slam system for monocular, stereo, and rgb-d cameras,”IEEE Trans. Robot., vol. 33, no. 5, pp. 1255–1262, 2017
2017
-
[5]
Adabins: Depth estimation using adaptive bins,
S. F. Bhat, I. Alhashim, and P. Wonka, “Adabins: Depth estimation using adaptive bins,” inCVPR, 2021, pp. 4009–4018
2021
-
[6]
Depth anything: Unleashing the power of large-scale unlabeled data,
L. Yang, B. Kang, Z. Huang, X. Xu, J. Feng, and H. Zhao, “Depth anything: Unleashing the power of large-scale unlabeled data,” inCVPR, 2024, pp. 10 371–10 381
2024
-
[7]
3D packing for self-supervised monocular depth estimation,
V . Guizilini, R. Ambrus, S. Pillai, A. Raventos, and A. Gaidon, “3D packing for self-supervised monocular depth estimation,” inCVPR, 2020, pp. 2485–2494
2020
-
[8]
Digging into self-supervised monocular depth estimation,
C. Godard, O. Mac Aodha, M. Firman, and G. J. Brostow, “Digging into self-supervised monocular depth estimation,” inCVPR, 2019, pp. 3828–3838
2019
-
[9]
Unsupervised learning of depth and ego-motion from video,
T. Zhou, M. Brown, N. Snavely, and D. G. Lowe, “Unsupervised learning of depth and ego-motion from video,” inCVPR, 2017, pp. 1851–1858
2017
-
[10]
Vision meets robotics: The KITTI dataset,
A. Geiger, P. Lenz, C. Stiller, and R. Urtasun, “Vision meets robotics: The KITTI dataset,”IJRR, 2013
2013
-
[11]
The cityscapes dataset for semantic urban scene understanding,
M. Cordts, M. Omran, S. Ramos, T. Rehfeld, M. Enzweiler, R. Benen- son, U. Franke, S. Roth, and B. Schiele, “The cityscapes dataset for semantic urban scene understanding,” inCVPR, 2016
2016
-
[12]
Indoor segmen- tation and support inference from rgbd images,
P. K. Nathan Silberman, Derek Hoiem and R. Fergus, “Indoor segmen- tation and support inference from rgbd images,” inECCV, 2012
2012
-
[13]
MonoViT: Self-supervised monocular depth estimation with a vision transformer,
C. Zhao, Y . Zhang, M. Poggi, F. Tosi, X. Guo, Z. Zhu, G. Huang, Y . Tang, and S. Mattoccia, “MonoViT: Self-supervised monocular depth estimation with a vision transformer,” in3DV. IEEE, 2022, pp. 668– 678
2022
-
[14]
Camera height doesn’t change: Unsu- pervised training for metric monocular road-scene depth estimation,
G. Kinoshita and K. Nishino, “Camera height doesn’t change: Unsu- pervised training for metric monocular road-scene depth estimation,” in ECCV. Springer, 2024, pp. 57–73
2024
-
[15]
R4dyn: Exploring radar for self-supervised monocular depth estimation of dynamic scenes,
S. Gasperini, P. Koch, V . Dallabetta, N. Navab, B. Busam, and F. Tombari, “R4dyn: Exploring radar for self-supervised monocular depth estimation of dynamic scenes,” in3DV. IEEE, 2021, pp. 751–760
2021
-
[16]
Robust monocular depth estimation under challenging conditions,
S. Gasperini, N. Morbitzer, H. Jung, N. Navab, and F. Tombari, “Robust monocular depth estimation under challenging conditions,” inCVPR, 2023, pp. 8177–8186
2023
-
[17]
Learning depth from monocular videos using direct methods,
C. Wang, J. M. Buenaposada, R. Zhu, and S. Lucey, “Learning depth from monocular videos using direct methods,” inCVPR, 2018, pp. 2022– 2030
2018
-
[18]
Towards better generalization: Joint depth-pose learning without posenet,
W. Zhao, S. Liu, Y . Shu, and Y .-J. Liu, “Towards better generalization: Joint depth-pose learning without posenet,” inCVPR, 2020, pp. 9151– 9161
2020
-
[19]
DualRefine: Self- supervised depth and pose estimation through iterative epipolar sampling and refinement toward equilibrium,
A. Bangunharcana, A. Magd, and K.-S. Kim, “DualRefine: Self- supervised depth and pose estimation through iterative epipolar sampling and refinement toward equilibrium,” inCVPR, 2023, pp. 726–738
2023
-
[20]
Are we ready for autonomous driving? the KITTI vision benchmark suite,
A. Geiger, P. Lenz, and R. Urtasun, “Are we ready for autonomous driving? the KITTI vision benchmark suite,” inCVPR, 2012
2012
-
[21]
Unsupervised learning of monocular depth estimation and visual odom- etry with deep feature reconstruction,
H. Zhan, R. Garg, C. S. Weerasekera, K. Li, H. Agarwal, and I. Reid, “Unsupervised learning of monocular depth estimation and visual odom- etry with deep feature reconstruction,” inCVPR, 2018, pp. 340–349
2018
-
[22]
Mono-vifi: A unified learning framework for self-supervised single and multi-frame monocular depth estimation,
J. Liu, L. Kong, B. Li, Z. Wang, H. Gu, and J. Chen, “Mono-vifi: A unified learning framework for self-supervised single and multi-frame monocular depth estimation,” inECCV. Springer, 2024, pp. 90–107
2024
-
[23]
Channel-wise attention-based net- work for self-supervised monocular depth estimation,
J. Yan, H. Zhao, P. Bu, and Y . Jin, “Channel-wise attention-based net- work for self-supervised monocular depth estimation,” in3DV. IEEE, 2021, pp. 464–473
2021
-
[24]
Monoindoor++: Towards better practice of self-supervised monocular depth estimation for indoor envi- ronments,
R. Li, P. Ji, Y . Xu, and B. Bhanu, “Monoindoor++: Towards better practice of self-supervised monocular depth estimation for indoor envi- ronments,”IEEE TCSVT, vol. 33, no. 2, pp. 830–846, 2022
2022
-
[25]
Superglue: Learning feature matching with graph neural networks,
P.-E. Sarlin, D. DeTone, T. Malisiewicz, and A. Rabinovich, “Superglue: Learning feature matching with graph neural networks,” inCVPR, 2020, pp. 4938–4947
2020
-
[26]
LM-Reloc: Levenberg-Marquardt based direct visual relocalization,
L. V on Stumberg, P. Wenzel, N. Yang, and D. Cremers, “LM-Reloc: Levenberg-Marquardt based direct visual relocalization,” in3DV. IEEE, 2020, pp. 968–977
2020
-
[27]
Back to the feature: Learning robust camera localization from pixels to pose,
P.-E. Sarlin, A. Unagar, M. Larsson, H. Germain, C. Toft, V . Larsson, M. Pollefeys, V . Lepetit, L. Hammarstrand, F. Kahlet al., “Back to the feature: Learning robust camera localization from pixels to pose,” in CVPR, 2021, pp. 3247–3257
2021
-
[28]
Relative pose estimation through affine corrections of monocular depth priors,
Y . Yu, S. Liu, R. Pautrat, M. Pollefeys, and V . Larsson, “Relative pose estimation through affine corrections of monocular depth priors,” in CVPR, 2025, pp. 16 706–16 716
2025
-
[29]
Y . Cabon, N. Murray, and M. Humenberger, “Virtual kitti 2,”arXiv preprint arXiv:2001.10773, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[30]
Cnn-slam: Real-time dense monocular slam with learned depth prediction,
K. Tateno, F. Tombari, I. Laina, and N. Navab, “Cnn-slam: Real-time dense monocular slam with learned depth prediction,” inCVPR, 2017, pp. 6243–6252
2017
-
[31]
Sparsity invariant cnns,
J. Uhrig, N. Schneider, L. Schneider, U. Franke, T. Brox, and A. Geiger, “Sparsity invariant cnns,” in3DV. IEEE, 2017, pp. 11–20
2017
-
[32]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inCVPR, 2016, pp. 770–778
2016
-
[33]
Hybrid-grained feature aggregation with coarse-to- fine language guidance for self-supervised monocular depth estimation,
W. Zhang, H. Liu, B. Li, J. He, Z. Qi, Y . Wang, S. Zhao, X. Yu, W. Zeng, and X. Jin, “Hybrid-grained feature aggregation with coarse-to- fine language guidance for self-supervised monocular depth estimation,” inICCV, 2025, pp. 6678–6692
2025
-
[34]
Adam: A Method for Stochastic Optimization
D. P. Kingma, “Adam: A method for stochastic optimization,”arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[35]
Predicting depth, surface normals and semantic labels with a common multi-scale convolutional architecture,
D. Eigen and R. Fergus, “Predicting depth, surface normals and semantic labels with a common multi-scale convolutional architecture,” inICCV, 2015, pp. 2650–2658
2015
-
[36]
The temporal opportunist: Self-supervised multi-frame monocular depth,
J. Watson, O. Mac Aodha, V . Prisacariu, G. Brostow, and M. Fir- man, “The temporal opportunist: Self-supervised multi-frame monocular depth,” inCVPR, 2021, pp. 1164–1174
2021
-
[37]
Auto- rectify network for unsupervised indoor depth estimation,
J.-W. Bian, H. Zhan, N. Wang, T.-J. Chin, C. Shen, and I. Reid, “Auto- rectify network for unsupervised indoor depth estimation,”IEEE TPAMI, vol. 44, no. 12, pp. 9802–9813, 2021
2021
-
[38]
Visual odometry revisited: What should be learnt?
H. Zhan, C. S. Weerasekera, J.-W. Bian, and I. Reid, “Visual odometry revisited: What should be learnt?” inICRA. IEEE, 2020, pp. 4203– 4210
2020
-
[39]
Unsupervised scale-consistent depth and ego-motion learning from monocular video,
J. Bian, Z. Li, N. Wang, H. Zhan, C. Shen, M.-M. Cheng, and I. Reid, “Unsupervised scale-consistent depth and ego-motion learning from monocular video,”NeurIPS, vol. 32, 2019
2019
-
[40]
Grounding image matching in 3d with mast3r,
V . Leroy, Y . Cabon, and J. Revaud, “Grounding image matching in 3d with mast3r,” inECCV. Springer, 2024, pp. 71–91
2024
-
[41]
Depthcrafter: Generating consistent long depth sequences for open- world videos,
W. Hu, X. Gao, X. Li, S. Zhao, X. Cun, Y . Zhang, L. Quan, and Y . Shan, “Depthcrafter: Generating consistent long depth sequences for open- world videos,” inCVPR, 2025, pp. 2005–2015
2025
-
[42]
Video depth anything: Consistent depth estimation for super-long videos,
S. Chen, H. Guo, S. Zhu, F. Zhang, Z. Huang, J. Feng, and B. Kang, “Video depth anything: Consistent depth estimation for super-long videos,” inCVPR, 2025, pp. 22 831–22 840. 9 APPENDIX A. ROBUSTNESS AGAINSTDEPTHESTIMATIONNOISE We present quantitative results of new experiments in Tab. VII to investigate the robustness of the joint train- ing framework ag...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.