Rethinking Software Empirical Studies with Structural Causal Models
Pith reviewed 2026-06-29 10:47 UTC · model grok-4.3
The pith
Structural causal models show that prompt engineering often lacks significant causal effect on code generation once confounding is addressed.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
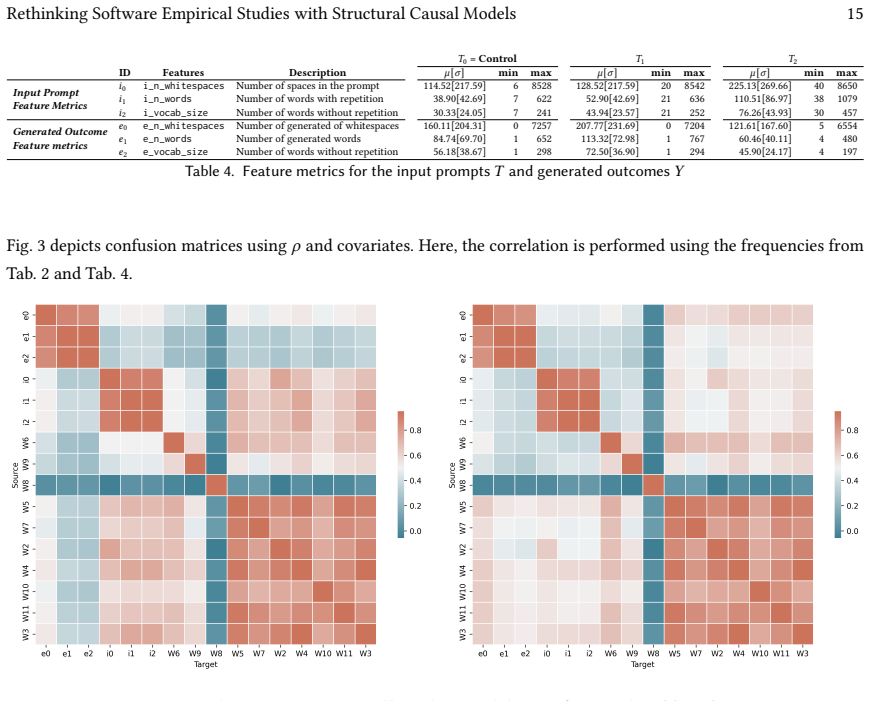
The paper claims that modeling software experiments with structural causal models and applying propensity score matching disentangles genuine causal effects from spurious associations; in the Galeras case study, associational analyses indicated that complex prompts improve GPT-3 code generation while the corresponding causal analyses found no significant treatment effect, thereby illustrating the risk of false positives when confounding variables remain unaddressed.
What carries the argument
Structural causal models (SCMs) paired with propensity score matching, which together identify confounders and estimate the average treatment effect of an intervention such as prompt engineering.
If this is right
- Empirical software engineering studies must explicitly model and adjust for confounders to avoid reporting spurious treatment effects.
- Prompt-engineering interventions that appear beneficial under simple regression may show no causal impact once confounding is controlled.
- Researchers can use the SCM-plus-matching workflow to design experiments that support actionable rather than merely associational conclusions.
- Software datasets should record potential confounders at collection time so that later causal analyses become feasible.
Where Pith is reading between the lines
- The same SCM approach could be tested on other SE tasks such as defect prediction or code review to check whether similar discrepancies between association and causation appear.
- If many existing SE findings prove non-causal under this lens, replication studies would need to collect richer covariate data rather than only outcome variables.
- The framework implies that software engineering should treat experiment design as a causal-graph construction task from the outset.
- Extending the method to observational data from version-control histories could reveal causal impacts of practices such as code-review frequency on downstream quality.
Load-bearing premise
The chosen set of confounders in the Galeras dataset SCM fully captures the relevant causal structure and propensity score matching balances the comparison groups without introducing new biases.
What would settle it
Repeating the Galeras analysis with the same SCM but a different or expanded set of confounders and obtaining a statistically significant causal effect of prompt complexity on code-generation metrics would falsify the reported pattern of non-significant causal results.
Figures

read the original abstract
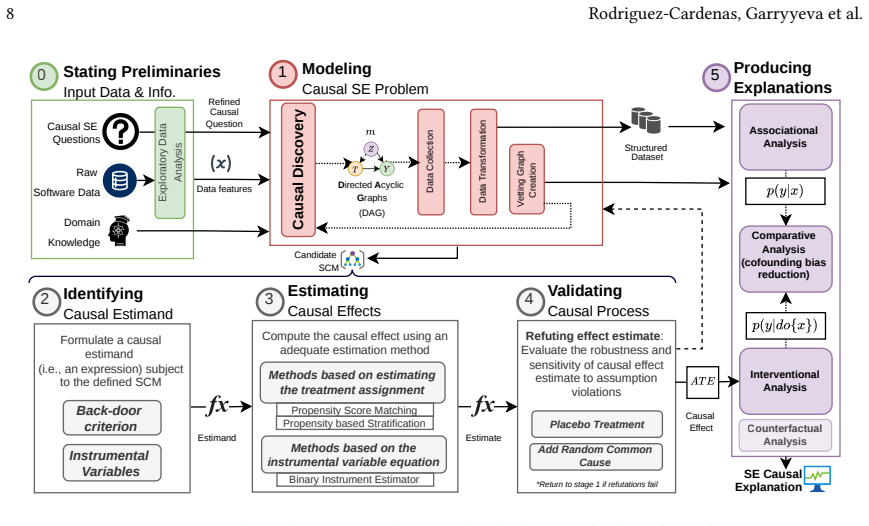
Causal Inference offers a fundamental approach for advancing empirical software engineering (ESE) beyond traditional statistical association, enabling researchers to rigorously identify and quantify causal relationships in software experiments. This paper introduces CausalSE, a framework that operationalizes Judea Pearl's causal inference paradigm in ESE context. The paper focuses on Structural Causal Models (SCMs) to address the limitations of classical statistical methods in mitigating confounding bias. Through a case study using the Galeras dataset and propensity score matching, we demonstrate how CausalSE disentangles the effect of prompt engineering strategies on code generation outcomes in a popular LLM (i.e., GPT-3). The results reveal that while associational analyses can suggest improvements in certain interventions (e.g., more complex prompts), causal analysis often does not find a significant treatment effect, highlighting the risk of false positives when confounding is not addressed. By providing a tutorial-based methodology and a real-world case study, this work equips software researchers with practical tools to design, analyze, and interpret software experiments with methodological rigor, ultimately enabling more informed and actionable conclusions in both research and practice.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CausalSE, a framework that applies Judea Pearl's structural causal models (SCMs) and techniques such as propensity score matching to empirical software engineering (ESE) to mitigate confounding bias. It contrasts associational analyses with causal estimates in a case study on the Galeras dataset, showing that prompt-engineering interventions (e.g., more complex prompts) appear beneficial under standard statistics but often yield no significant average treatment effect once confounding is addressed via the SCM for GPT-3 code generation outcomes.
Significance. If the SCM construction, confounder selection, and matching diagnostics are shown to be robust, the framework could meaningfully reduce false-positive claims in ESE by shifting from associational to causal inference; the tutorial-style presentation and real-world dataset application are practical strengths.
major comments (2)
- [Section 4 (Galeras case study)] Galeras case study (Section 4): the central claim that causal analysis 'often does not find a significant treatment effect' depends on the completeness of the enumerated confounders in the SCM and on successful balance after propensity score matching, yet no sensitivity analysis for omitted variables (e.g., code complexity or project-level factors) or post-matching balance diagnostics (standardized mean differences, variance ratios) are reported; without these, the result cannot be confidently attributed to confounding removal rather than model misspecification.
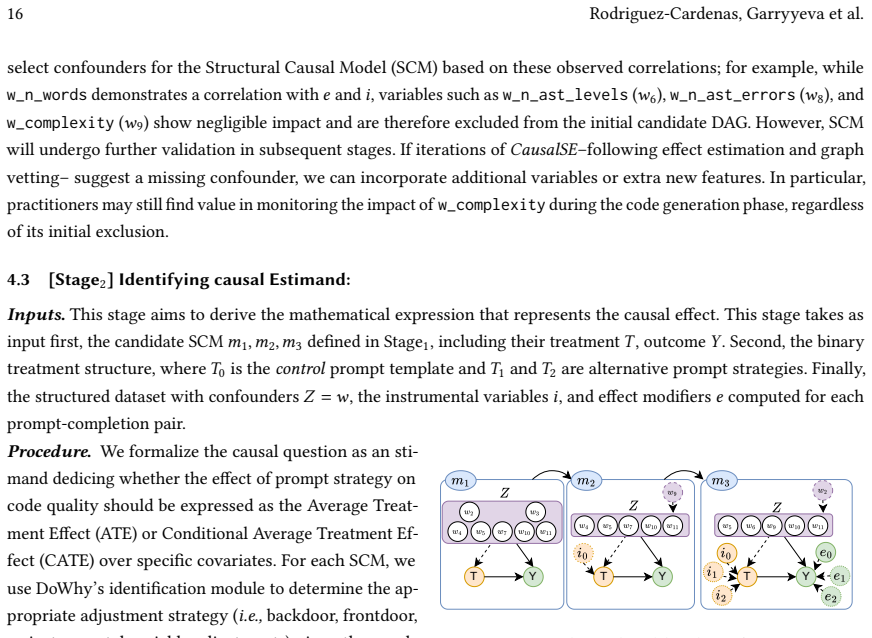
- [Section 3 (Methodology)] Methodology section (Section 3): the description of SCM construction and variable selection for the prompt-engineering treatment provides no explicit list of observed confounders, no justification for their causal sufficiency, and no power analysis for the subsequent ATE estimation; this leaves the 'no significant effect' finding vulnerable to the weakest-assumption concern that relevant confounders were omitted.
minor comments (2)
- [Abstract] The abstract and introduction use 'often' without quantifying how many of the examined interventions showed null causal effects versus how many were tested; adding counts or a table would improve precision.
- [Section 3] Notation for the SCM (e.g., the graph and structural equations) is introduced but not shown with the specific variables used in the Galeras example; including the explicit DAG or equation set would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive comments on our manuscript. The feedback emphasizes the importance of robustness checks in causal inference, which we agree are essential. We will revise the paper to incorporate the suggested analyses and clarifications. Our point-by-point responses follow.
read point-by-point responses
-
Referee: Galeras case study (Section 4): the central claim that causal analysis 'often does not find a significant treatment effect' depends on the completeness of the enumerated confounders in the SCM and on successful balance after propensity score matching, yet no sensitivity analysis for omitted variables (e.g., code complexity or project-level factors) or post-matching balance diagnostics (standardized mean differences, variance ratios) are reported; without these, the result cannot be confidently attributed to confounding removal rather than model misspecification.
Authors: We concur that additional diagnostics are necessary to bolster confidence in the findings. In the revised version, we will report post-matching balance diagnostics, including standardized mean differences and variance ratios for the matched samples. We will also conduct a sensitivity analysis for omitted variable bias, for instance by assessing the robustness of the ATE estimates to potential unmeasured confounders like code complexity or project-specific factors. This will help demonstrate that the lack of significant treatment effects is indeed due to proper confounding adjustment rather than misspecification. revision: yes
-
Referee: Methodology section (Section 3): the description of SCM construction and variable selection for the prompt-engineering treatment provides no explicit list of observed confounders, no justification for their causal sufficiency, and no power analysis for the subsequent ATE estimation; this leaves the 'no significant effect' finding vulnerable to the weakest-assumption concern that relevant confounders were omitted.
Authors: We appreciate this observation and will enhance the methodology section accordingly. The revised manuscript will include an explicit list of the observed confounders incorporated into the SCM, along with justifications for why these are sufficient under the causal assumptions (e.g., based on domain knowledge in software engineering and the Galeras dataset characteristics). We will also perform and report a power analysis for the ATE estimation to confirm that the study has adequate power to detect meaningful effects, thereby addressing concerns about the reliability of the non-significant findings. revision: yes
Circularity Check
No circularity: standard causal methods applied to external dataset
full rationale
The paper introduces CausalSE by operationalizing Pearl's SCM framework and propensity score matching on the external Galeras dataset. No equations, derivations, or self-citations are shown that reduce any result to fitted parameters or prior author work by construction. The central demonstration (associational vs. causal effect differences) rests on application of established external methods rather than internal self-definition or renaming.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The selected variables in the SCM for the prompt engineering case study capture all relevant confounders.
Reference graph
Works this paper leans on
-
[1]
Andrea Arcuri and Lionel Briand. 2011. A practical guide for using statistical tests to assess randomized algorithms in software engineering. InProceedings of the 33rd International Conference on Software Engineering(Waikiki, Honolulu, HI, USA)(ICSE ’11). Association for Computing Machinery, New York, NY, USA, 1–10. https://doi.org/10.1145/1985793.1985795
-
[2]
Andrea Arcuri and Lionel Briand. 2014. A Hitchhiker’s guide to statistical tests for assessing randomized algorithms in software engineering.Softw. Test. Verif. Reliab.24, 3 (May 2014), 219–250. https://doi.org/10.1002/stvr.1486
-
[3]
Baah, Andy Podgurski, and Mary Jean Harrold
George K. Baah, Andy Podgurski, and Mary Jean Harrold. [n. d.]. Causal inference for statistical fault localization. InProceedings of the 19th international symposium on Software testing and analysis(Trento Italy, 2010-07-12). ACM, 73–84. https://doi.org/10.1145/1831708.1831717
-
[4]
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin...
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[5]
1959.Causality: The Place of the Causal Principle in Modern Science
Mario Bunge. 1959.Causality: The Place of the Causal Principle in Modern Science. Harvard University Press
1959
-
[6]
2003.Emergence and Convergence: Qualitative Novelty and the Unity of Knowledge
Mario Bunge. 2003.Emergence and Convergence: Qualitative Novelty and the Unity of Knowledge. University of Toronto Press
2003
-
[7]
2011.Philosophy of Science: Volume 1 and 2
Mario Bunge. 2011.Philosophy of Science: Volume 1 and 2. Routledge
2011
-
[8]
1989.Nature’s Capacities and Their Measurement
Nancy Cartwright. 1989.Nature’s Capacities and Their Measurement. Oxford University Press
1989
-
[9]
1999.The Dappled World: A Study of the Boundaries of Science
Nancy Cartwright. 1999.The Dappled World: A Study of the Boundaries of Science. Cambridge University Press
1999
-
[10]
2007.Hunting Causes and Using Them: Approaches in Philosophy and Economics
Nancy Cartwright. 2007.Hunting Causes and Using Them: Approaches in Philosophy and Economics. Cambridge University Press
2007
-
[11]
Patrick Chadbourne and Nasir U. Eisty. [n. d.]. Applications of Causality and Causal Inference in Software Engineering. In2023 IEEE/ACIS 21st International Conference on Software Engineering Research, Management and Applications (SERA)(Orlando, FL, USA, 2023-05-23). IEEE, 47–52. https://doi.org/10.1109/SERA57763.2023.10197835
- [12]
-
[13]
Carlo Alberto Furia, Robert Feldt, and Richard Torkar. 2019. Bayesian Data Analysis in Empirical Software Engineering Research.IEEE Transactions on Software Engineering(2019), 1–1. https://doi.org/10.1109/tse.2019.2935974
-
[14]
Carlo A. Furia and Richard Torkar. [n. d.]. Mitigating Omitted Variable Bias in Empirical Software Engineering. arXiv:2501.17026 [cs] http: //arxiv.org/abs/2501.17026
-
[15]
Furia, Richard Torkar, and Robert Feldt
Carlo A. Furia, Richard Torkar, and Robert Feldt. [n. d.]. Towards Causal Analysis of Empirical Software Engineering Data: The Impact of Programming Languages on Coding Competitions. 33, 1 ([n. d.]), 1–35. https://doi.org/10.1145/3611667 arXiv:2301.07524 [cs]
- [16]
-
[17]
Miguel A Hernán and James M Robins. [n. d.]. Causal Inference: What If. ([n. d.])
-
[18]
Jeremy Hulse, Nasir U Eisty, and Tim Menzies. 2025. Shaky structures: The wobbly world of causal graphs in software analytics.Empirical Software Engineering(2025)
2025
- [19]
-
[20]
Rick Kazman, Robert Stoddard, David Danks, and Yuanfang Cai. [n. d.]. Causal Modeling, Discovery, & Inference for Software Engineering. In2017 IEEE/ACM 39th International Conference on Software Engineering Companion (ICSE-C)(Buenos Aires, 2017-05). IEEE, 172–174. https: //doi.org/10.1109/ICSE-C.2017.138
-
[21]
Yigit Kucuk, Tim A. D. Henderson, and Andy Podgurski. [n. d.]. Improving Fault Localization by Integrating Value and Predicate Based Causal Inference Techniques. In2021 IEEE/ACM 43rd International Conference on Software Engineering (ICSE)(Madrid, ES, 2021-05). IEEE, 649–660. https://doi.org/10.1109/ICSE43902.2021.00066
-
[22]
Aleksander Molak and Ajit Jaokar. [n. d.].Causal inference and discovery in Python: unlock the secrets of modern causal machine learning with DoWhy, EconML, PyTorch and more. Packt Publishing Limited
-
[23]
David Nader Palacio, Alejandro Velasco, Nathan Cooper, Alvaro Rodriguez, Kevin Moran, and Denys Poshyvanyk. 2024. Toward a Theory of Causation for Interpreting Neural Code Models.IEEE Transactions on Software Engineering50, 5 (May 2024), 1215–1243. https://doi.org/10.1109/ TSE.2024.3379943
-
[24]
Francisco Gomes de Oliveira Neto, Richard Torkar, Robert Feldt, Lucas Gren, Carlo A. Furia, and Ziwei Huang. [n. d.]. Evolution of statistical analysis in empirical software engineering research: Current state and steps forward. 156 ([n. d.]), 246–267. https://doi.org/10.1016/j.jss.2019.07.002 arXiv:1706.00933 [cs]
-
[25]
Judea Pearl. [n. d.]. The seven tools of causal inference, with reflections on machine learning. 62, 3 ([n. d.]), 54–60. https://doi.org/10.1145/3241036
-
[26]
Judea Pearl. 2009. Causal Inference in Statistics: An Overview.Statistics Surveys3 (2009), 96–146. https://doi.org/10.1214/09-SS057
-
[27]
2009.Causality: models, reasoning, and inference
Judea Pearl. 2009.Causality: models, reasoning, and inference. Manuscript submitted to ACM 22 Rodriguez-Cardenas, Garryyeva et al
2009
-
[28]
Judea Pearl. 2018. Theoretical Impediments to Machine Learning With Seven Sparks from the Causal Revolution. InProceedings of the Eleventh ACM International Conference on Web Search and Data Mining(Marina Del Rey, CA, USA)(WSDM ’18). Association for Computing Machinery, New York, NY, USA, 3. https://doi.org/10.1145/3159652.3176182
-
[29]
2016.Causal Inference in Statistics, A Primer
Judea Pearl, Madelyn Glymour, and Nicholas P.Jewell. 2016.Causal Inference in Statistics, A Primer
2016
-
[30]
2018.The Book of Why: The New Science of Cause and Effect(1st ed.)
Judea Pearl and Dana Mackenzie. 2018.The Book of Why: The New Science of Cause and Effect(1st ed.). Basic Books, Inc., USA
2018
-
[31]
Luan Pham, Huong Ha, and Hongyu Zhang. [n. d.]. Root Cause Analysis for Microservice System based on Causal Inference: How Far Are We?. In Proceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering(Sacramento CA USA, 2024-10-27). ACM, 706–715. https://doi.org/10.1145/3691620.3695065
-
[32]
Md Mahbubur Rahman, Ira Ceka, Chengzhi Mao, Saikat Chakraborty, Baishakhi Ray, and Wei Le. [n. d.]. Towards Causal Deep Learning for Vulnerability Detection. InProceedings of the IEEE/ACM 46th International Conference on Software Engineering(2024-04-12). 1–11. arXiv:2310.07958 [cs, stat] http://arxiv.org/abs/2310.07958
-
[33]
Daniel Rodriguez-Cardenas, Aya Garryyeva, and David N. Palacio. 2026. Causal4SE: Causal Inference for Software Engineering. https://github.com/ WM-SEMERU/Causal4SE. GitHub repository
2026
-
[34]
Palacio, Dipin Khati, Henry Burke, and Denys Poshyvanyk
Daniel Rodríguez-Cárdenas, David N. Palacio, Dipin Khati, Henry Burke, and Denys Poshyvanyk. 2023. Benchmarking Causal Study to Interpret Large Language Models for Source Code. InIEEE International Conference on Software Maintenance and Evolution, ICSME 2023, Bogotá, Colombia, October 1-6, 2023. IEEE, 329–334. https://doi.org/10.1109/ICSME58846.2023.00040
-
[35]
Daniel Rodríguez-Cárdenas, Alejandro Velasco, and Denys Poshyvanyk. 2025. SnipGen: A Mining Repository Framework for Evaluating LLMs for Code.CoRRabs/2502.07046 (2025). https://doi.org/10.48550/ARXIV.2502.07046 arXiv:2502.07046
-
[36]
Paul R. Rosenbaum. [n. d.]. Choice as an Alternative to Control in Observational Studies. 14, 3 ([n. d.]). https://doi.org/10.1214/ss/1009212410
-
[37]
Julien Siebert. [n. d.]. Applications of statistical causal inference in software engineering. 159 ([n. d.]), 107198. https://doi.org/10.1016/j.infsof.2023. 107198 arXiv:2211.11482 [cs]
-
[38]
D.I.K. Sjoeberg, J.E. Hannay, O. Hansen, V.B. Kampenes, A. Karahasanovic, N.-K. Liborg, and A.C. Rekdal. [n. d.]. A survey of controlled experiments in software engineering. 31, 9 ([n. d.]), 733–753. https://doi.org/10.1109/TSE.2005.97
- [39]
- [40]
- [41]
-
[42]
Liuyi Yao, Zhixuan Chu, Sheng Li, Yaliang Li, Jing Gao, and Aidong Zhang. [n. d.]. A Survey on Causal Inference. 15, 5 ([n. d.]), 1–46. https: //doi.org/10.1145/3444944 Received 20 February 2007; revised 12 March 2009; accepted 5 June 2009 Manuscript submitted to ACM
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.