Looking Farther with Confidence: Uncertainty-Guided Future Learning for Sequential Recommendation
Pith reviewed 2026-06-29 09:47 UTC · model grok-4.3
The pith
Sequential recommendation improves when uncertainty in the next-item prediction decides how much future data to use during training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
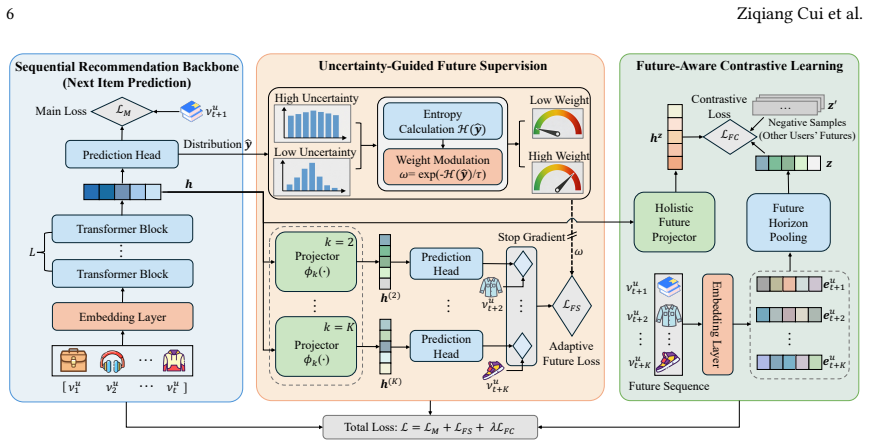
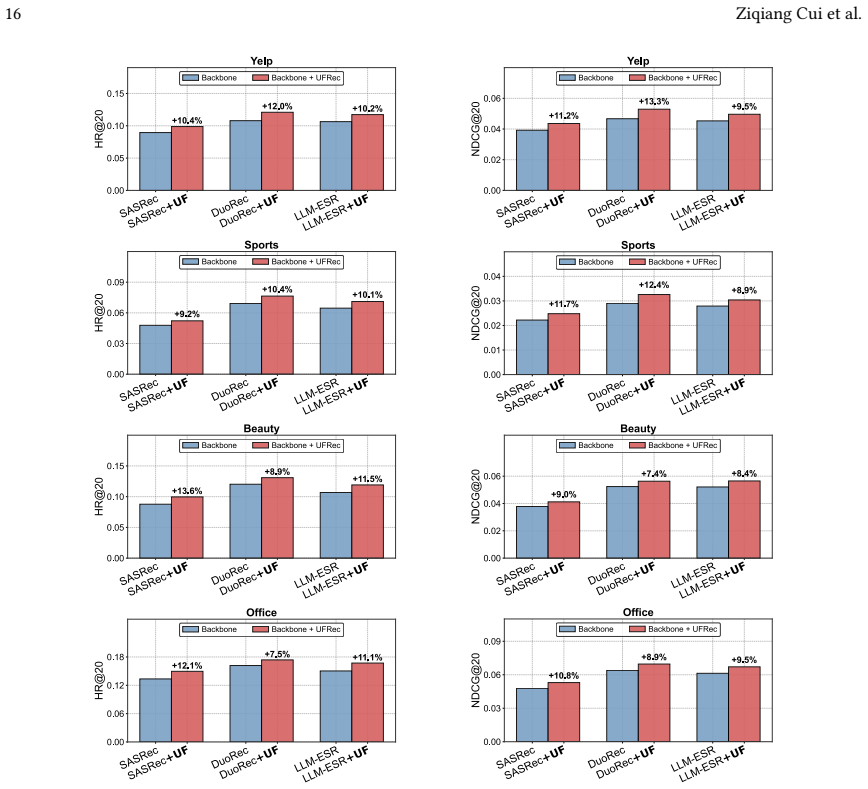
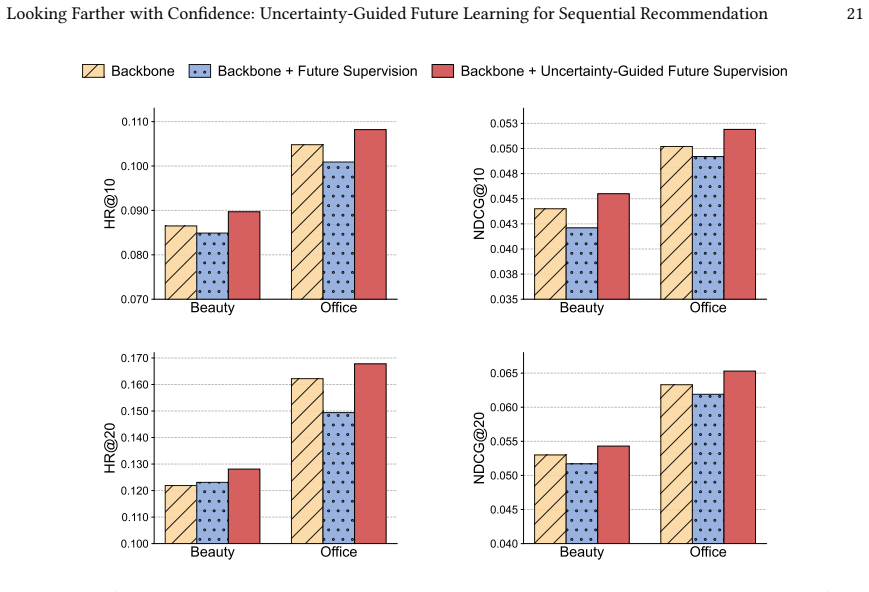
We propose UFRec, an adaptive future learning framework which encourages the model to look further ahead when it is confident in the current state, while focusing on the immediate task when it is uncertain. UFRec incorporates an Uncertainty-Guided Future Supervision module that dynamically modulates the weight of multi-step future supervision based on the model's confidence in the primary next-item prediction task. Furthermore, we complement step-wise future supervision with a Future-Aware Contrastive Learning module that treats the future trajectory as a holistic entity. Both auxiliary modules are utilized exclusively during training and incur no inference overhead.
What carries the argument
Uncertainty-Guided Future Supervision module that scales the loss weight of multi-step future predictions according to the model's in its immediate next-item prediction.
If this is right
- Future data can be exploited without applying the same intensity to every training sample.
- Training-time auxiliary signals can improve accuracy while leaving inference latency unchanged.
- Contrastive objectives that operate on entire future trajectories complement step-wise supervision.
- Data-sparsity problems in sequential recommendation can be mitigated by selective use of longer interaction histories.
Where Pith is reading between the lines
- The same uncertainty signal might be useful for deciding when to apply other auxiliary tasks in sequential models.
- If uncertainty estimates are noisy, the method could be extended with ensemble or calibration techniques to stabilize the weighting.
- The framework may transfer to other sequential prediction domains such as next-action forecasting in reinforcement learning.
Load-bearing premise
The model's uncertainty score on the next-item task reliably signals when future supervision will help rather than hurt performance.
What would settle it
Running the same model with future-supervision weights set uniformly or set to zero and observing whether the uncertainty-modulated version still shows statistically significant gains on the four benchmark datasets.
Figures




read the original abstract
Sequential recommendation effectively models dynamic user interests but continues to face challenges related to data sparsity. While self-supervised learning has alleviated this issue to some extent, most existing methods focus exclusively on immediate next-item prediction during training, thereby neglecting the rich information embedded in longer-term future interactions. Although a few studies have explored the utilization of future data, existing attempts typically apply future supervision signals with uniform intensity across all samples, which may lead to suboptimal solutions. In this paper, we propose an adaptive future learning framework, UFRec, which encourages the model to look further ahead when it is confident in the current state, while focusing on the immediate task when it is uncertain. Specifically, UFRec incorporates an Uncertainty-Guided Future Supervision module that dynamically modulates the weight of multi-step future supervision based on the model's confidence in the primary next-item prediction task. Furthermore, we complement step-wise future supervision with a Future-Aware Contrastive Learning module that treats the future trajectory as a holistic entity. Notably, both auxiliary modules are utilized exclusively during training and incur no inference overhead. Extensive experiments on four benchmark datasets demonstrate that our method significantly outperforms state-of-the-art approaches by effectively leveraging future data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces UFRec, an adaptive future learning framework for sequential recommendation. It features an Uncertainty-Guided Future Supervision module that dynamically modulates the weight of multi-step future supervision according to the model's confidence in the primary next-item prediction, plus a Future-Aware Contrastive Learning module treating future trajectories holistically. Both modules are training-only with no inference cost. The central claim is that this uncertainty-guided approach enables effective use of longer-term future data, yielding significant outperformance over state-of-the-art methods on four benchmark datasets.
Significance. If the uncertainty modulation proves load-bearing, the work could meaningfully advance self-supervised sequential recommendation by showing how to adaptively incorporate future signals without uniform weighting pitfalls, while the training-only design is a practical advantage. The idea of confidence-based future supervision is conceptually appealing for sparsity mitigation.
major comments (2)
- [Experiments] Experiments section: the central claim that uncertainty-guided weighting enables effective future supervision requires an ablation that replaces the uncertainty signal with a constant or random weight (while holding total future supervision volume fixed) to isolate its contribution; no such controlled comparison is described, leaving open whether uniform future supervision already captures most gains.
- [§3.2] §3.2 (Uncertainty-Guided Future Supervision): the definition of the modulation function and its dependence on next-item prediction confidence is not accompanied by any analysis or sensitivity study showing that the chosen uncertainty estimator is reliable rather than noisy or correlated with other factors.
minor comments (2)
- [Abstract] Abstract: no quantitative results, dataset names, or metric values are reported, which weakens the ability to gauge the scale of improvement.
- [§3] Notation for the uncertainty score and future-supervision weight should be introduced with explicit equations rather than prose descriptions alone.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important aspects for strengthening the empirical validation of our central claims. We address each major comment below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the central claim that uncertainty-guided weighting enables effective future supervision requires an ablation that replaces the uncertainty signal with a constant or random weight (while holding total future supervision volume fixed) to isolate its contribution; no such controlled comparison is described, leaving open whether uniform future supervision already captures most gains.
Authors: We agree that isolating the contribution of the uncertainty modulation requires a controlled ablation that holds the total future supervision volume fixed. In the revised manuscript, we will add this experiment: we will replace the confidence-based weights with a constant weight (set to the mean confidence across the batch) or with random weights drawn from the same distribution, while rescaling to preserve the aggregate supervision strength. Results will be reported on all four datasets alongside the original UFRec to quantify the incremental benefit of the adaptive mechanism. revision: yes
-
Referee: [§3.2] §3.2 (Uncertainty-Guided Future Supervision): the definition of the modulation function and its dependence on next-item prediction confidence is not accompanied by any analysis or sensitivity study showing that the chosen uncertainty estimator is reliable rather than noisy or correlated with other factors.
Authors: We acknowledge that additional validation of the uncertainty estimator would strengthen the methodological justification. In the revision, we will include a new subsection with (i) a sensitivity study varying the temperature and threshold parameters of the modulation function, (ii) correlation analysis between the next-item confidence scores and potential confounding factors such as sequence length and item frequency, and (iii) a comparison against alternative uncertainty proxies (entropy of the prediction distribution and Monte-Carlo dropout variance) to demonstrate that the chosen estimator is both reliable and appropriate for the modulation task. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper proposes an empirical framework UFRec with two training-only modules: uncertainty-guided weighting of multi-step future supervision and future-aware contrastive learning. No equations, derivations, or parameter-fitting steps are described in the provided text that could reduce a claimed prediction to an input by construction, self-definition, or self-citation load-bearing. The central claim rests on benchmark experiments rather than a closed mathematical chain; the uncertainty modulation is presented as a design choice whose benefit is asserted via results, not derived tautologically from the inputs themselves. This is the common case of a self-contained empirical contribution with no detectable circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
-
[2]
Yongjun Chen, Zhiwei Liu, Jia Li, Julian McAuley, and Caiming Xiong. 2022. Intent contrastive learning for sequential recommendation. In Proceedings of the ACM Web Conference 2022. 2172–2182
2022
-
[3]
Ziqiang Cui, Yunpeng Weng, Xing Tang, Xiaokun Zhang, Shiwei Li, Peiyang Liu, Bowei He, Dugang Liu, Weihong Luo, Chen Ma, et al . 2025. Semantic retrieval augmented contrastive learning for sequential recommendation. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
2025
-
[4]
Ziqiang Cui, Haolun Wu, Bowei He, Ji Cheng, and Chen Ma. 2024. Context Matters: Enhancing Sequential Recommendation with Context-aware Diffusion-based Contrastive Learning. InProceedings of the 33rd ACM International Conference on Information and Knowledge Management. 404–414
2024
-
[5]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. Bert: Pre-training of deep bidirectional transformers for language understanding.arXiv preprint arXiv:1810.04805(2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[6]
Ruining He and Julian McAuley. 2016. Fusing similarity models with markov chains for sparse sequential recommendation. In2016 IEEE 16th international conference on data mining (ICDM). IEEE, 191–200
2016
-
[7]
Xiangnan He, Kuan Deng, Xiang Wang, Yan Li, Yongdong Zhang, and Meng Wang. 2020. Lightgcn: Simplifying and powering graph convolution network for recommendation. InProceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval. 639–648
2020
-
[8]
Balázs Hidasi and Alexandros Karatzoglou. 2018. Recurrent neural networks with top-k gains for session-based recommendations. InProceedings of the 27th ACM international conference on information and knowledge management. 843–852
2018
-
[9]
Balázs Hidasi, Alexandros Karatzoglou, Linas Baltrunas, and Domonkos Tikk. 2015. Session-based recommendations with recurrent neural networks. arXiv preprint arXiv:1511.06939(2015)
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[10]
Yu-Hsuan Huang, Ling Lo, Hongxia Xie, Hong-Han Shuai, and Wen-Huang Cheng. 2025. Future Sight and Tough Fights: Revolutionizing Sequential Recommendation with FENRec. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 11826–11834
2025
-
[11]
Ashish Jaiswal, Ashwin Ramesh Babu, Mohammad Zaki Zadeh, Debapriya Banerjee, and Fillia Makedon. 2020. A survey on contrastive self-supervised learning.Technologies9, 1 (2020), 2
2020
-
[12]
Yangqin Jiang, Yuhao Yang, Lianghao Xia, and Chao Huang. 2024. Diffkg: Knowledge graph diffusion model for recommendation. InProceedings of the 17th ACM international conference on web search and data mining. 313–321
2024
-
[13]
Wang-Cheng Kang and Julian McAuley. 2018. Self-attentive sequential recommendation. In2018 IEEE international conference on data mining (ICDM). IEEE, 197–206
2018
-
[14]
Lei Li, Yongfeng Zhang, and Li Chen. 2023. Prompt distillation for efficient llm-based recommendation. InProceedings of the 32nd ACM International Conference on Information and Knowledge Management. 1348–1357
2023
-
[15]
Yuanzi Li, Xuri Ge, Jingyu Zhao, Yidan Wang, Jiyuan Yang, Zhumin Chen, Zhaochun Ren, and Xin Xin. 2026. R2NS: Recall and Re-ranking of Negative Samples for Sequential Recommendation. InProceedings of the ACM Web Conference 2026. 6331–6341
2026
-
[16]
Jiayi Liao, Sihang Li, Zhengyi Yang, Jiancan Wu, Yancheng Yuan, Xiang Wang, and Xiangnan He. 2024. Llara: Large language-recommendation assistant. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. 1785–1795
2024
-
[17]
Jianghao Lin, Xinyi Dai, Yunjia Xi, Weiwen Liu, Bo Chen, Hao Zhang, Yong Liu, Chuhan Wu, Xiangyang Li, Chenxu Zhu, et al. 2025. How can recommender systems benefit from large language models: A survey.ACM Transactions on Information Systems43, 2 (2025), 1–47
2025
-
[18]
Qidong Liu, Xian Wu, Yejing Wang, Zijian Zhang, Feng Tian, Yefeng Zheng, and Xiangyu Zhao. 2024. LLM-ESR: Large Language Models Enhancement for Long-tailed Sequential Recommendation. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems
2024
- [19]
-
[20]
Jianxin Ma, Chang Zhou, Hongxia Yang, Peng Cui, Xin Wang, and Wenwu Zhu. 2020. Disentangled self-supervision in sequential recommenders. In Proceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining. 483–491
2020
-
[21]
Xiuyuan Qin, Huanhuan Yuan, Pengpeng Zhao, Junhua Fang, Fuzhen Zhuang, Guanfeng Liu, Yanchi Liu, and Victor Sheng. 2023. Meta-optimized Contrastive Learning for Sequential Recommendation. InProceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval. 89–98
2023
-
[22]
Xiuyuan Qin, Huanhuan Yuan, Pengpeng Zhao, Guanfeng Liu, Fuzhen Zhuang, and Victor S Sheng. 2024. Intent Contrastive Learning with Cross Subsequences for Sequential Recommendation. InProceedings of the 17th ACM International Conference on Web Search and Data Mining. 548–556. Manuscript submitted to ACM Looking Farther with Confidence: Uncertainty-Guided F...
2024
-
[23]
Ruihong Qiu, Zi Huang, Hongzhi Yin, and Zijian Wang. 2022. Contrastive learning for representation degeneration problem in sequential recommendation. InProceedings of the fifteenth ACM international conference on web search and data mining. 813–823
2022
-
[24]
Xubin Ren, Wei Wei, Lianghao Xia, and Chao Huang. 2025. A comprehensive survey on self-supervised learning for recommendation.Comput. Surveys58, 1 (2025), 1–38
2025
-
[25]
Yankun Ren, Zhongde Chen, Xinxing Yang, Longfei Li, Cong Jiang, Lei Cheng, Bo Zhang, Linjian Mo, and Jun Zhou. 2024. Enhancing sequential recommenders with augmented knowledge from aligned large language models. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. 345–354
2024
-
[26]
Steffen Rendle, Christoph Freudenthaler, and Lars Schmidt-Thieme. 2010. Factorizing personalized markov chains for next-basket recommendation. InProceedings of the 19th international conference on World wide web. 811–820
2010
-
[27]
Claude E Shannon. 1948. A mathematical theory of communication.The Bell system technical journal27, 3 (1948), 379–423
1948
-
[28]
Yixin Su, Wei Jiang, Fangquan Lin, Cheng Yang, Sarah M Erfani, Junhao Gan, Yunxiang Zhao, Ruixuan Li, and Rui Zhang. 2025. Intrinsic and Extrinsic Factor Disentanglement for Recommendation in Various Context Scenarios.ACM Transactions on Information Systems43, 3 (2025), 1–32
2025
-
[29]
Fei Sun, Jun Liu, Jian Wu, Changhua Pei, Xiao Lin, Wenwu Ou, and Peng Jiang. 2019. BERT4Rec: Sequential recommendation with bidirectional encoder representations from transformer. InProceedings of the 28th ACM international conference on information and knowledge management. 1441–1450
2019
-
[30]
Jiaxi Tang and Ke Wang. 2018. Personalized top-n sequential recommendation via convolutional sequence embedding. InProceedings of the eleventh ACM international conference on web search and data mining. 565–573
2018
-
[31]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need.Advances in neural information processing systems30 (2017)
2017
-
[32]
Hao Wang, Wei Guo, Luankang Zhang, Jin Yao Chin, Yufei Ye, Huifeng Guo, Yong Liu, Defu Lian, Ruiming Tang, and Enhong Chen. 2025. Generative large recommendation models: emerging trends in llms for recommendation. InCompanion Proceedings of the ACM on Web Conference 2025. 49–52
2025
-
[33]
Yanling Wang, Yuchen Liu, Qian Wang, Cong Wang, and Chenliang Li. 2023. Poisoning self-supervised learning based sequential recommendations. InProceedings of the 46th international ACM SIGIR conference on research and development in information retrieval. 300–310
2023
-
[34]
Yuling Wang, Changxin Tian, Binbin Hu, Yanhua Yu, Ziqi Liu, Zhiqiang Zhang, Jun Zhou, Liang Pang, and Xiao Wang. 2024. Can Small Language Models be Good Reasoners for Sequential Recommendation?. InProceedings of the ACM on Web Conference 2024. 3876–3887
2024
-
[35]
Jiancan Wu, Xiang Wang, Fuli Feng, Xiangnan He, Liang Chen, Jianxun Lian, and Xing Xie. 2021. Self-supervised graph learning for recommendation. InProceedings of the 44th international ACM SIGIR conference on research and development in information retrieval. 726–735
2021
-
[36]
Jiafeng Xia, Dongsheng Li, Hansu Gu, Tun Lu, Peng Zhang, Li Shang, and Ning Gu. 2025. Oracle-guided Dynamic User Preference Modeling for Sequential Recommendation. InProceedings of the Eighteenth ACM International Conference on Web Search and Data Mining. 363–372
2025
-
[37]
Lianghao Xia, Chao Huang, Chunzhen Huang, Kangyi Lin, Tao Yu, and Ben Kao. 2023. Automated Self-Supervised Learning for Recommendation. InProceedings of the ACM Web Conference 2023. 992–1002
2023
-
[38]
Lianghao Xia, Chao Huang, Yong Xu, and Jian Pei. 2022. Multi-behavior sequential recommendation with temporal graph transformer.IEEE Transactions on Knowledge and Data Engineering(2022)
2022
-
[39]
Xu Xie, Fei Sun, Zhaoyang Liu, Shiwen Wu, Jinyang Gao, Jiandong Zhang, Bolin Ding, and Bin Cui. 2022. Contrastive learning for sequential recommendation. In2022 IEEE 38th international conference on data engineering (ICDE). IEEE, 1259–1273
2022
-
[40]
Jingcao Xu, Chaokun Wang, Cheng Wu, Yang Song, Kai Zheng, Xiaowei Wang, Changping Wang, Guorui Zhou, and Kun Gai. 2023. Multi-behavior self-supervised learning for recommendation. InProceedings of the 46th international ACM SIGIR conference on research and development in information retrieval. 496–505
2023
-
[41]
Shenghao Yang, Weizhi Ma, Peijie Sun, Qingyao Ai, Yiqun Liu, Mingchen Cai, and Min Zhang. 2024. Sequential recommendation with latent relations based on large language model. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. 335–344
2024
-
[42]
Yuhao Yang, Chao Huang, Lianghao Xia, and Chenliang Li. 2022. Knowledge graph contrastive learning for recommendation. InProceedings of the 45th international ACM SIGIR conference on research and development in information retrieval. 1434–1443
2022
-
[43]
Yihang Yin, Qingzhong Wang, Siyu Huang, Haoyi Xiong, and Xiang Zhang. 2022. Autogcl: Automated graph contrastive learning via learnable view generators. InProceedings of the AAAI conference on artificial intelligence, Vol. 36. 8892–8900
2022
-
[44]
Junliang Yu, Hongzhi Yin, Xin Xia, Tong Chen, Lizhen Cui, and Quoc Viet Hung Nguyen. 2022. Are graph augmentations necessary? simple graph contrastive learning for recommendation. InProceedings of the 45th international ACM SIGIR conference on research and development in information retrieval. 1294–1303
2022
-
[45]
Junliang Yu, Hongzhi Yin, Xin Xia, Tong Chen, Jundong Li, and Zi Huang. 2023. Self-supervised learning for recommender systems: A survey.IEEE Transactions on Knowledge and Data Engineering36, 1 (2023), 335–355
2023
-
[46]
Dan Zhang, Yangliao Geng, Wenwen Gong, Zhongang Qi, Zhiyu Chen, Xing Tang, Ying Shan, Yuxiao Dong, and Jie Tang. 2024. RecDCL: Dual Contrastive Learning for Recommendation. InProceedings of the ACM on Web Conference 2024. 3655–3666
2024
-
[47]
Mengqi Zhang, Shu Wu, Xueli Yu, Qiang Liu, and Liang Wang. 2022. Dynamic graph neural networks for sequential recommendation.IEEE Transactions on Knowledge and Data Engineering35, 5 (2022), 4741–4753
2022
-
[48]
Xiaokun Zhang, Bo Xu, Zhaochun Ren, Xiaochen Wang, Hongfei Lin, and Fenglong Ma. 2024. Disentangling id and modality effects for session-based recommendation. InProceedings of the 47th international ACM SIGIR conference on research and development in information retrieval. 1883–1892. Manuscript submitted to ACM 24 Ziqiang Cui et al
2024
-
[49]
Xiaokun Zhang, Bo Xu, Youlin Wu, Yuan Zhong, Hongfei Lin, and Fenglong Ma. 2024. FineRec: Exploring Fine-grained Sequential Recommendation. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. 1599–1608
2024
-
[50]
Yuyue Zhao, Jiancan Wu, Xiang Wang, Wei Tang, Dingxian Wang, and Maarten de Rijke. 2024. Let me do it for you: Towards llm empowered recommendation via tool learning. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. 1796–1806
2024
-
[51]
Ziwen Zhao, Yixin Su, Yuhua Li, Yixiong Zou, Ruixuan Li, and Rui Zhang. 2025. A Survey on Self-Supervised Graph Foundation Models: Knowledge- Based Perspective.IEEE Transactions on Knowledge and Data Engineering(2025)
2025
-
[52]
Kun Zhou, Hui Wang, Wayne Xin Zhao, Yutao Zhu, Sirui Wang, Fuzheng Zhang, Zhongyuan Wang, and Ji-Rong Wen. 2020. S3-rec: Self-supervised learning for sequential recommendation with mutual information maximization. InProceedings of the 29th ACM international conference on information & knowledge management. 1893–1902
2020
-
[53]
Xin Zhou, Aixin Sun, Yong Liu, Jie Zhang, and Chunyan Miao. 2023. Selfcf: A simple framework for self-supervised collaborative filtering.ACM Transactions on Recommender Systems1, 2 (2023), 1–25. Manuscript submitted to ACM
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.