ClinicalEncoder26AM: A Multlilingual Diagnosable ColBERT Model; Evidences from the MultiClinNER Shared Task
Pith reviewed 2026-06-29 13:13 UTC · model grok-4.3
The pith
A ColBERT model post-trained on clinical texts reaches state-of-the-art multilingual entity recall on the MultiClinNER task while using less data than its base model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ClinicalEncoder26AM is a multilingual Diagnosable ColBERT model whose token-level semantics are aligned with ClinicalMap25 via a post-training recipe on BGE-M3 that combines synthetic clinical notes, patient-doctor conversations, annotated resources such as MedMentions, multi-adapter distillation at named-entity and sentence levels, and a ColBERT-style retrieval objective; when fine-tuned as a BIO tagger for symptoms, disorders, and procedures using a lightweight two-layer CNN head, the model achieves state-of-the-art multilingual entity recall, places in the top five overall across entity types and languages on character-weighted F1, and demonstrates markedly higher data efficiency than the
What carries the argument
Multi-adapter distillation that aligns both named-entity-level and sentence-level representations to ClinicalMap25 while retaining a ColBERT-style retrieval objective.
If this is right
- The model processes the majority of clinical documents inside one 8192-token context window without truncation.
- Entity recall improves across multiple languages when the post-trained encoder is used instead of the unmodified base model.
- Training curves reach target performance with fewer annotated examples than the base model requires.
- A simple two-layer CNN head suffices to turn the encoder into an effective BIO tagger for symptoms, disorders, and procedures.
- The same post-training recipe can be applied to other retrieval-oriented clinical information-extraction tasks.
Where Pith is reading between the lines
- If the data-efficiency pattern holds, clinical post-training could lower the annotation burden for new languages or entity types in medical NLP.
- The diagnosable ColBERT design may allow inspection of which clinical concepts drive particular retrieval or tagging decisions.
- Extending the same multi-level alignment approach to other narrow domains, such as legal or scientific text, could be tested by swapping the synthetic and annotated supervision sources.
- Because the model remains a single 8192-token encoder plus a small head, it could be deployed on modest hardware for real-time clinical note processing.
Load-bearing premise
The observed gains in recall and data efficiency are caused by the clinical post-training recipe rather than by differences in fine-tuning procedure, head architecture, or shared-task evaluation setup.
What would settle it
Re-running the identical fine-tuning procedure and two-layer CNN head on the base BGE-M3 model and comparing the resulting recall curves and final F1 scores on the same MultiClinNER test sets would show whether the clinical post-training contributes anything beyond the shared fine-tuning steps.
Figures
read the original abstract
ClinicalEncoder26AM is a multilingual Diagnosable ColBERT for clinical and biomedical texts, which aligns at multiple levels its token-level semantic with ClinicalMap25, a clinical latent space inspired by BioLORD-2023 and enriched with synthetic and annotated supervision. The post-training recipe builds upon BGE-M3, and combines synthetic clinical notes, patient--doctor conversations, and annotated resources such as MedMentions, while considering both named-entity-level and sentence-level representations in a multi-adapter distillation, along with a ColBERT-style retrieval objective. In this system demonstration paper, we evaluate the model in the MultiClinNER shared task by finetuning it as a BIO tagger for patient symptoms, disorders, and procedure spans, using a lightweight two-layer CNN head to improve local boundary detection. The resulting system remains simple, processes most documents in a single 8192-token window, and achieves state-of-the-art multilingual entity recall, while achieving Top 5 overall across all entity types and languages in Character-weighted F1 scores. Training curves further show that ClinicalEncoder26AM is markedly more data-efficient than the base M3 model, supporting the usefulness of its clinical post-training for downstream information extraction. The model can be downloaded on https://huggingface.co/Parallia/ClinicalEncoder26AM-Diagnosable-Colbert-L2-for-multilingual-medical-texts
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ClinicalEncoder26AM, a multilingual ColBERT model obtained by post-training BGE-M3 on synthetic clinical notes, patient-doctor conversations, MedMentions, and related resources via multi-adapter distillation and a ColBERT-style objective. It evaluates the model on the MultiClinNER shared task by fine-tuning it as a BIO tagger for symptoms, disorders, and procedures using a lightweight two-layer CNN head, claiming state-of-the-art multilingual entity recall, top-5 character-weighted F1 overall, and markedly superior data efficiency relative to the base M3 model.
Significance. If the performance and efficiency gains are verifiably due to the clinical post-training rather than fine-tuning differences, the work would supply concrete evidence that targeted post-training can improve data efficiency for multilingual clinical NER, which is relevant for resource-constrained biomedical information extraction.
major comments (2)
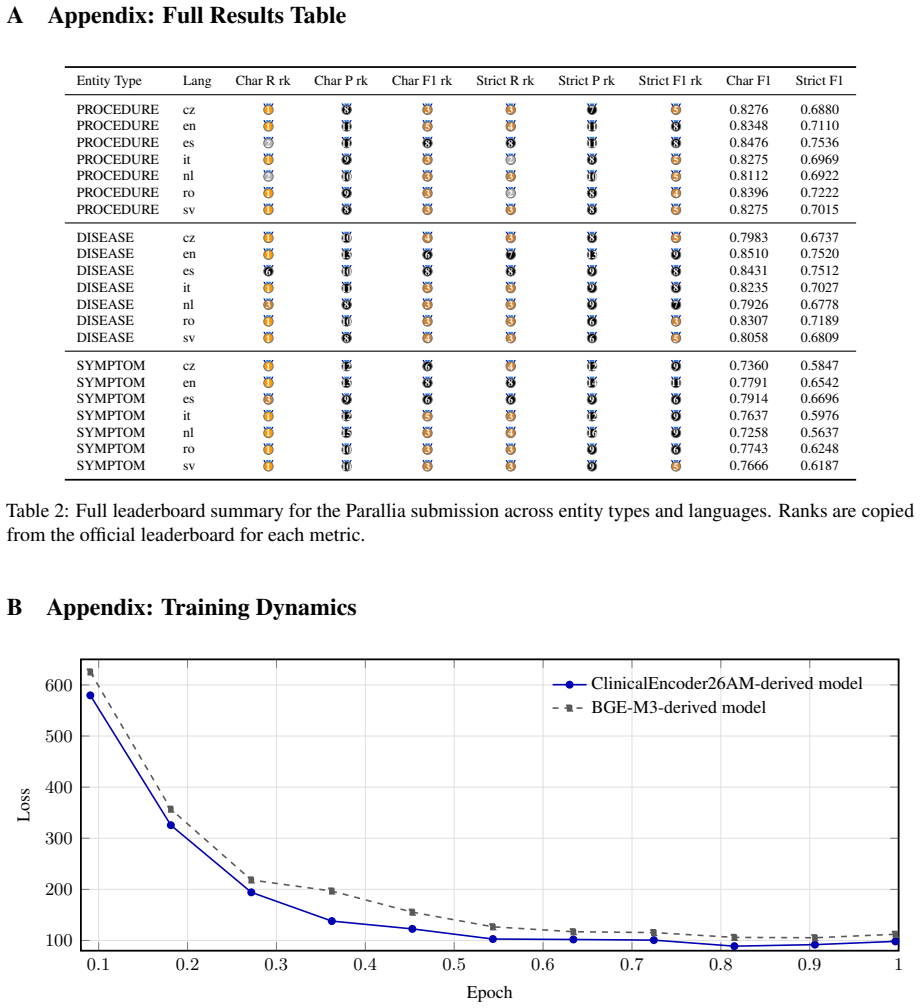
- [Training curves / evaluation description] The training-curve comparison asserts that ClinicalEncoder26AM is markedly more data-efficient than the base M3 model, yet the manuscript does not state that the base M3 received the identical two-layer CNN head, adapter configuration, or exact fine-tuning procedure. Without this control, the efficiency gap cannot be attributed to the post-training recipe.
- [Abstract / results] The abstract and results claim state-of-the-art multilingual entity recall and top-5 character-weighted F1 without reporting any numerical scores, baselines from other shared-task participants, error bars, or ablation results that would allow assessment of the magnitude or robustness of the gains.
minor comments (1)
- [Title] The title contains a typographical error ('Multlilingual' instead of 'Multilingual').
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important areas for clarification in our system demonstration paper. We address each major comment below and will revise the manuscript accordingly to improve transparency and support for our claims.
read point-by-point responses
-
Referee: The training-curve comparison asserts that ClinicalEncoder26AM is markedly more data-efficient than the base M3 model, yet the manuscript does not state that the base M3 received the identical two-layer CNN head, adapter configuration, or exact fine-tuning procedure. Without this control, the efficiency gap cannot be attributed to the post-training recipe.
Authors: We agree that the manuscript does not explicitly state that the base M3 model was evaluated under identical conditions (same two-layer CNN head, adapter setup, and fine-tuning procedure). This omission prevents clear attribution of the efficiency gains. In the revised manuscript, we will add a dedicated subsection detailing the shared fine-tuning protocol applied to both models, including hyperparameters and configuration, to allow proper interpretation of the training curves. revision: yes
-
Referee: The abstract and results claim state-of-the-art multilingual entity recall and top-5 character-weighted F1 without reporting any numerical scores, baselines from other shared-task participants, error bars, or ablation results that would allow assessment of the magnitude or robustness of the gains.
Authors: The referee is correct that the abstract and results lack specific numerical values, direct comparisons to other MultiClinNER participants, error bars, or ablations. As a system demonstration paper, the emphasis was on the model architecture and qualitative advantages, but we recognize this limits assessment of the claims. We will revise the abstract and results sections to include the key performance metrics, shared-task baselines, and any available statistical details. Ablations may be added if they fit within length constraints. revision: yes
Circularity Check
No circularity; empirical results on external shared task
full rationale
The paper reports empirical performance (SOTA recall, top-5 char-weighted F1, data-efficiency curves) on the external MultiClinNER shared task after fine-tuning as a BIO tagger. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. Claims rest on external benchmark outcomes rather than reducing to internal definitions or ansatzes. The comparison to base M3 is an experimental-design question, not a circular reduction.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
ClinicalAligner26AM: A Cross-Lingual Aligner for Dataset Translation; Evidences from the MultiClinCorpus Shared Task
ClinicalAligner26AM tops the MultiClinCorpus shared task by distilling Sinkhorn-sharpened multi-level alignments into a clinical encoder for projecting Spanish entity annotations to six target languages with F1 above 0.95.
Reference graph
Works this paper leans on
-
[1]
InFindings of the Asso- ciation for Computational Linguistics: ACL 2024, pages 2318–2335, Bangkok, Thailand
M3- embedding: Multi-linguality, multi-functionality, multi-granularity text embeddings through self- knowledge distillation. InFindings of the Asso- ciation for Computational Linguistics: ACL 2024, pages 2318–2335, Bangkok, Thailand. Association for Computational Linguistics. Kevin Donnelly
2024
-
[2]
InProceedings of the 2019 Conference on Au- tomated Knowledge Base Construction (AKBC 2019), Amherst, Massachusetts, USA
Medmentions: A large biomedical corpus annotated with umls con- cepts. InProceedings of the 2019 Conference on Au- tomated Knowledge Base Construction (AKBC 2019), Amherst, Massachusetts, USA. [Preprint]. François Remy
2019
-
[3]
Diagnosable colbert: Debugging late-interaction retrieval models using a learned latent space as reference.Preprint, arXiv:2604.19566. François Remy, Kris Demuynck, and Thomas De- meester
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
BioLORD-2023: Semantic tex- tual representations fusing large language models and clinical knowledge graph insights.Journal of the American Medical Informatics Association, 31(9):1844–1855. A Appendix: Full Results Table Entity Type Lang Char R rk Char P rk Char F1 rk Strict R rk Strict P rk Strict F1 rk Char F1 Strict F1 PROCEDURE cz 1 8 3 3 7 5 0.8276 0...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.