Soft-SVeRL: Self-Verified Reinforcement Learning with Soft Rewards
Pith reviewed 2026-06-29 13:06 UTC · model grok-4.3
The pith
Checklist-based soft rewards from item-by-item verification improve instruction-following RL by up to 11.1 points.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Soft-RLVR converts each prompt into a checklist of atomic requirements, scores candidate responses item by item with an LLM verifier to form soft rewards, and trains the policy on those signals; the self-verifying Soft-SVeRL variant is prone to reward inflation unless stabilized, and checklist-based verification yields a more reliable RL signal than holistic verification under the formalized conditions.
What carries the argument
Checklist-based soft rewards produced by item-by-item LLM verification that supply partial-credit training signals for RL in partially verifiable tasks.
If this is right
- Checklist decomposition supplies denser training signals than sparse pass/fail rewards for instruction-following tasks.
- Self-verification in Soft-SVeRL collapses without explicit stabilization against permissive self-judgments.
- Downstream RL gains depend on both the quality of the verifier and the quality of the generated checklists.
- The framework applies to any setting where prompts contain multiple independent requirements that can be checked separately.
- Formal conditions identify when averaging item-level scores outperforms holistic verification for RL.
Where Pith is reading between the lines
- The same checklist decomposition could be tested in domains like open-ended question answering where partial satisfaction is common but no rule-based ground truth exists.
- Pairing the soft-reward approach with an external fixed verifier might reduce the need for the stabilization techniques required in self-verification.
- Varying checklist granularity could be used to tune the noise-reduction versus partial-credit tradeoff in future experiments.
Load-bearing premise
Decomposing prompts into atomic checklist items lets an LLM verifier generate item judgments whose average is more reliable for RL training than a single holistic judgment on the full response.
What would settle it
A direct comparison on the same tasks and verifier model in which holistic verification produces equal or higher RL performance than checklist-based verification would falsify the claim of more reliable signals from item-level scoring.
Figures

read the original abstract
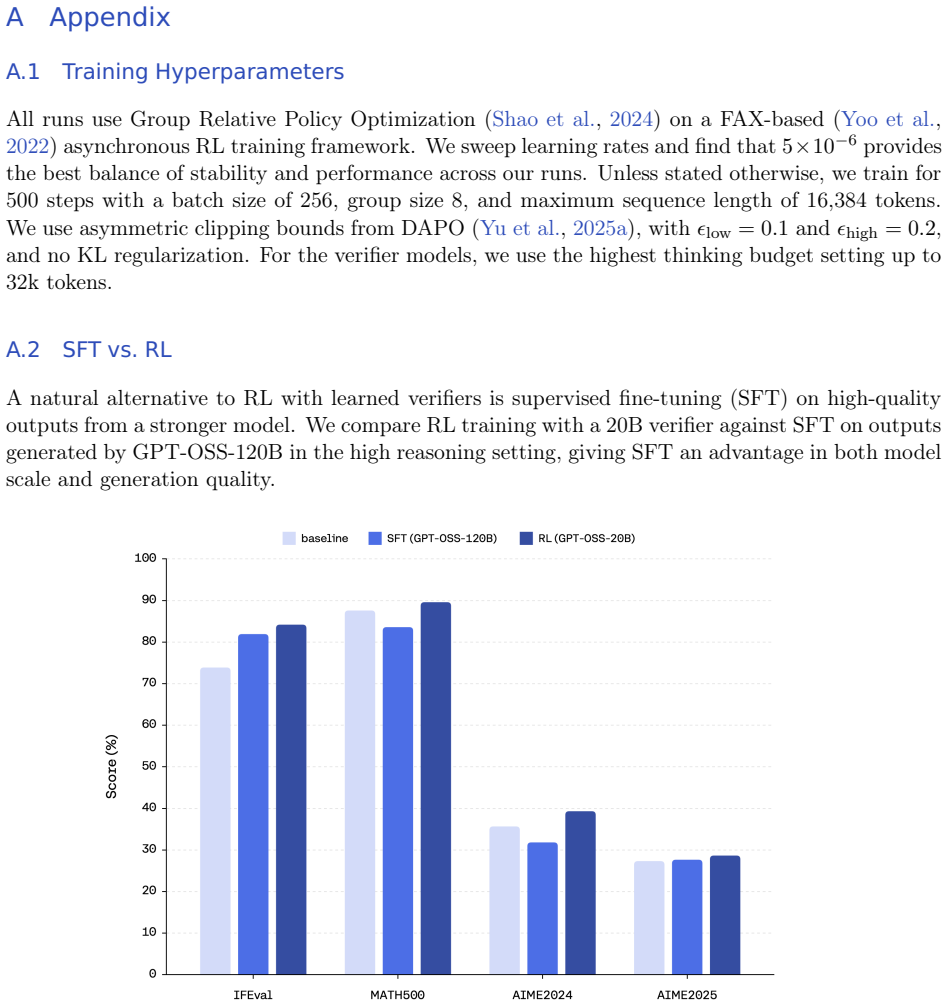
Reinforcement Learning from Verifiable Rewards (RLVR) has improved language models in domains such as mathematics and code, where correctness can be checked automatically. However, many important tasks are only partially verifiable: prompts contain multiple requirements, responses may satisfy some but not all of them, or no single reference answer might exist. We introduce Soft-RLVR, a framework for reinforcement learning from decomposed, learned verification signals. Soft-RLVR converts each prompt into a checklist of atomic requirements, scores candidate responses item by item with an LLM verifier, and trains on the resulting soft reward. Checklist-based rewards turn sparse pass/fail supervision into a denser partial-credit signal, but they also introduce a tradeoff: averaging item-level judgments can reduce verifier noise, while partial credit can reward incomplete responses. We formalize this tradeoff and identify conditions under which checklist-based verification gives a more reliable RL training signal than holistic verification. We further introduce Soft-SVeRL, a self-verifying variant of Soft-RLVR in which the policy also acts as the verifier. We show that self-verification is prone to reward inflation from overly permissive self-judgments, and that explicit stabilization is needed to prevent this collapse. In a controlled instruction-following setting with rule-based ground-truth evaluation, checklist-based Soft-RLVR improves IFEval by up to 11.1 points using only learned verifier rewards. Our experiments further show that verifier quality and checklist quality both affect downstream RL outcomes, and that explicit stabilization is essential for effective self-verification.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Soft-RLVR, a reinforcement learning framework that decomposes prompts into checklists of atomic requirements, scores responses item-by-item via an LLM verifier to produce soft (partial-credit) rewards, and trains policies on the resulting dense signal. It formalizes the noise-reduction versus partial-credit tradeoff between checklist-based and holistic verification, introduces the self-verifying Soft-SVeRL variant, and demonstrates that explicit stabilization is required to prevent reward inflation. In a controlled instruction-following setting evaluated against rule-based ground truth, checklist-based Soft-RLVR yields up to 11.1-point gains on IFEval using only learned verifier rewards; experiments also examine the effects of verifier and checklist quality.
Significance. If the empirical gains and the formalization of the partial-credit tradeoff hold under the reported controls, the work would provide a concrete, reproducible method for obtaining denser training signals in partially verifiable domains such as instruction following. The explicit use of external rule-based ground truth for evaluation and the acknowledgment that both verifier and checklist quality affect outcomes strengthen the result; the self-verification analysis with required stabilization also supplies a useful cautionary finding for future RLVR variants.
major comments (2)
- [§3] §3 (Formalization of the tradeoff): the manuscript states that conditions are identified under which checklist-based verification yields a more reliable RL signal than holistic verification, yet the provided description does not include an explicit statement or proof of those conditions (e.g., a bound relating item-level noise variance to the expected partial-credit bias). A direct statement or derivation is needed to make the formal claim load-bearing for the method.
- [§4.3] §4.3 (Self-verification experiments): the claim that explicit stabilization prevents collapse is central to Soft-SVeRL, but the manuscript should report the quantitative effect of the stabilization mechanism on reward inflation (e.g., mean self-judgment score before/after stabilization across training steps) to substantiate that the reported 11.1-point gain is not an artifact of the stabilization hyper-parameters.
minor comments (2)
- [§1] The abstract and §1 refer to “learned verifier rewards” without initially clarifying that the verifier is an external LLM (distinct from the policy) until later sections; a single sentence in the introduction would improve readability.
- [Results section] Table or figure captions for the IFEval results should explicitly state the number of runs and whether the 11.1-point figure is the maximum or mean improvement.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below.
read point-by-point responses
-
Referee: [§3] §3 (Formalization of the tradeoff): the manuscript states that conditions are identified under which checklist-based verification yields a more reliable RL signal than holistic verification, yet the provided description does not include an explicit statement or proof of those conditions (e.g., a bound relating item-level noise variance to the expected partial-credit bias). A direct statement or derivation is needed to make the formal claim load-bearing for the method.
Authors: We agree that the formalization would be strengthened by an explicit derivation. In the revised manuscript we will add a direct statement of the conditions together with a derivation relating item-level noise variance to expected partial-credit bias. revision: yes
-
Referee: [§4.3] §4.3 (Self-verification experiments): the claim that explicit stabilization prevents collapse is central to Soft-SVeRL, but the manuscript should report the quantitative effect of the stabilization mechanism on reward inflation (e.g., mean self-judgment score before/after stabilization across training steps) to substantiate that the reported 11.1-point gain is not an artifact of the stabilization hyper-parameters.
Authors: We will add quantitative reporting of the stabilization effect, including mean self-judgment scores before and after stabilization across training steps, in the revised manuscript. revision: yes
Circularity Check
No significant circularity; empirical gains measured against external rule-based ground truth
full rationale
The paper's central claims are empirical improvements (e.g., +11.1 IFEval points) in a controlled setting with explicit rule-based ground-truth evaluation. The abstract describes converting prompts to checklists, LLM item-level scoring, and training on soft rewards, with formalization of a partial-credit tradeoff and stabilization for self-verification. No equations, derivations, or 'predictions' are shown that reduce by construction to fitted parameters or self-referential definitions. Verifier quality and checklist quality are acknowledged as affecting outcomes, but results are externally benchmarked rather than internally forced. This matches the default expectation of a non-circular empirical paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM verifiers produce usable item-level scores that average to a more reliable signal than holistic verification
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2505.00949 , year=
URLhttps://arxiv.org/abs/2505.00949. Haolin Chen, Yihao Feng, Zuxin Liu, Weiran Yao, Akshara Prabhakar, Shelby Heinecke, Ricky Ho, Phil Mui, Silvio Savarese, Caiming Xiong, and Huan Wang. Language models are hidden reasoners: Unlocking latent reasoning capabilities via self-rewarding, 2024. URLhttps://arxi v.org/abs/2411.04282. DeepSeek-AI. DeepSeek-R1: I...
-
[2]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
URLhttps://arxiv.org/abs/2501.12948. Anisha Gunjal, Anthony Wang, Elaine Lau, Vaskar Nath, Yunzhong He, Bing Liu, and Sean Hendryx. Rubrics as rewards: Reinforcement learning beyond verifiable domains, 2025. URL https://arxiv.org/abs/2507.17746. Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinh...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
URLhttps://arxiv.org/abs/2506.00103. Kimi Team, Angang Du, Bofei Gao, Bowei Xing, Changjiu Jiang, Cheng Chen, et al. Kimi k1.5: Scaling reinforcement learning with LLMs, 2025. URLhttps://arxiv.org/abs/2501.12599. Harrison Lee, Samrat Phatale, Hassan Mansoor, Thomas Mesnard, Johan Ferret, Kellie Lu, Colton Bishop, Ethan Hall, Victor Carbune, Abhinav Rastog...
work page doi:10.64434/tml.20250929.https://thinkingmachines.ai/blog/lora/ 2025
-
[4]
yes" or
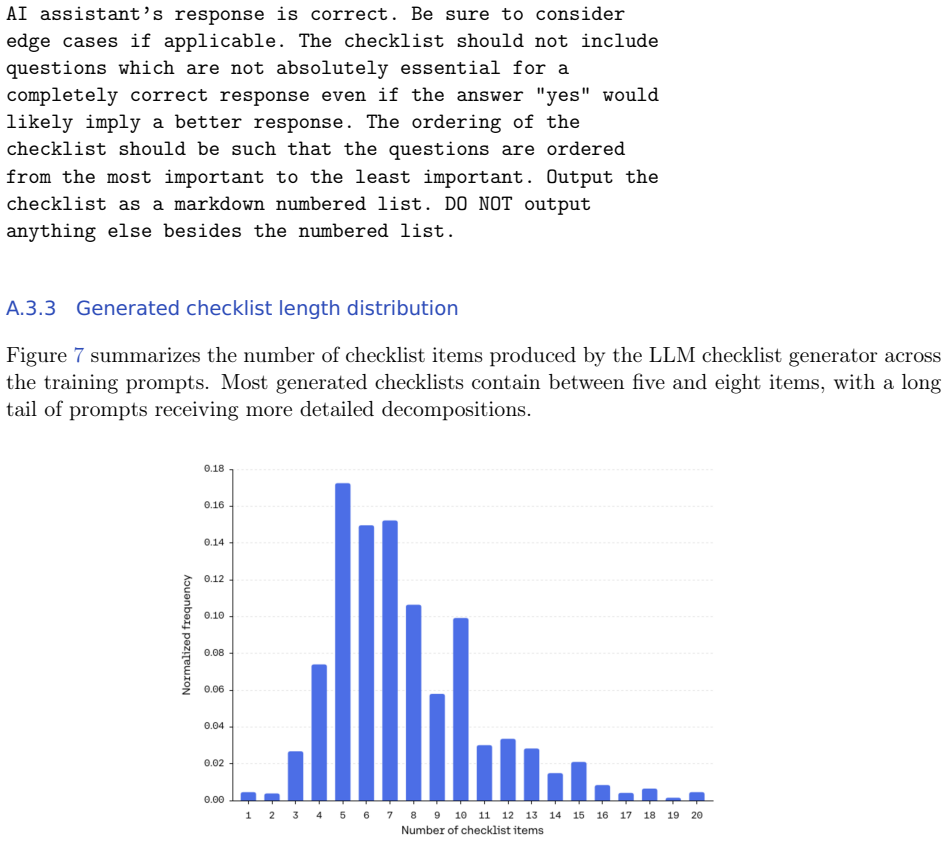
asynchronous RL training framework. We sweep learning rates and find that5×10−6 provides the best balance of stability and performance across our runs. Unless stated otherwise, we train for 500 steps with a batch size of 256, group size 8, and maximum sequence length of 16,384 tokens. We use asymmetric clipping bounds from DAPO (Yu et al., 2025a), withϵlo...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.