Internally Referenced Low-Light Enhancement
Pith reviewed 2026-06-29 13:19 UTC · model grok-4.3
The pith
A single low-light image can supply its own physical and structural references to guide self-supervised enhancement.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
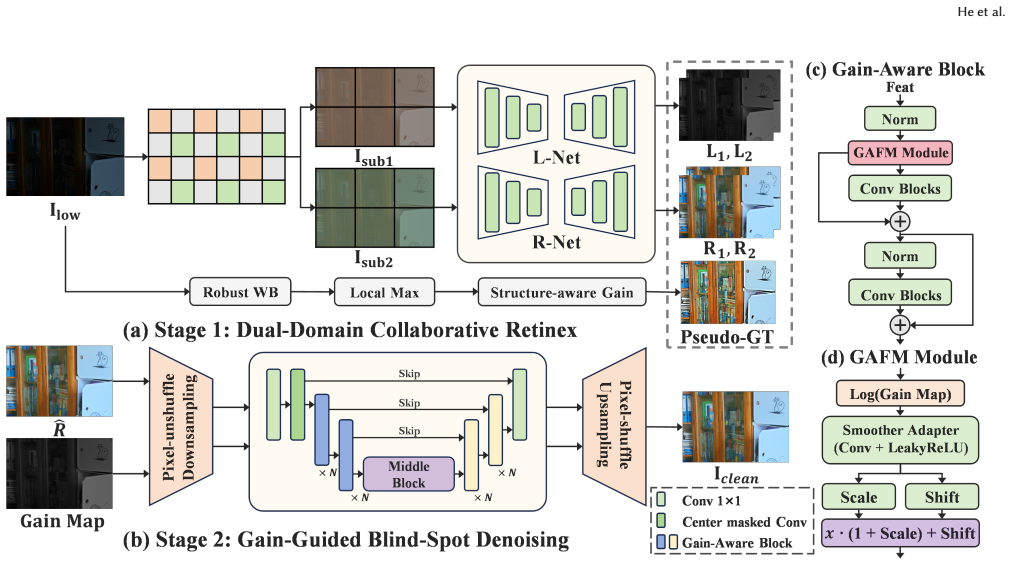
The Internally Referenced LLIE framework derives a low-frequency pseudo ground-truth via local exposure simulation to serve as an internal physical reference for illumination correction, constructs dual-domain structural references through an Illumination-Aligned Perceptual loss and a Shift-Invariant Spectral Correlation loss, and applies Gain-Adaptive Feature Modulation that turns the self-estimated illumination map into a spatial gain prior for blind-spot denoising, all without external paired supervision.
What carries the argument
Internal physical reference (low-frequency pseudo ground-truth) and dual-domain structural references extracted from the single input, together with the Gain-Adaptive Feature Modulation mechanism that converts the illumination map into a spatial gain prior.
If this is right
- Training and inference become possible using only single degraded images, removing the cost of collecting paired low-light and normal-light datasets.
- Global illumination and color cast correction can be driven directly by the low-frequency components of the input itself.
- Fine local structures are protected by combining spatial perceptual alignment with shift-invariant spectral correlation.
- Spatially varying residual noise is addressed by turning the illumination estimate into an adaptive gain prior for blind-spot denoising.
Where Pith is reading between the lines
- The same internal-reference pattern could be tested on related tasks such as single-image dehazing or underwater restoration where paired data is also scarce.
- If the pseudo ground-truth extraction proves stable across camera models, it may reduce dependence on large annotated corpora for low-light pipelines.
- Real-world deployment would benefit from checking whether the extracted references remain consistent when input noise statistics deviate sharply from the training distribution.
Load-bearing premise
The low-frequency pseudo ground-truth and dual-domain structural references extracted from one degraded image are reliable enough to guide illumination correction, structure preservation, and spatially variant denoising without any paired external data.
What would settle it
Run the method on a collection of real low-light images that also have corresponding well-lit ground-truth captures; if the outputs show visibly worse noise or texture loss than a paired-data baseline on those same images, the internal-reference premise fails.
Figures




read the original abstract
Self-supervised low-light image enhancement (LLIE) is highly appealing as it eliminates the reliance on external paired data. However, the lack of external references causes networks to struggle with decoupling entangled illumination, delicate textures, and amplified noise. To resolve this challenge, we propose an Internally Referenced LLIE framework that extracts reliable physical and structural references from the degraded input image itself. First, we introduce a local exposure-simulated scheme to extract a low-frequency pseudo ground-truth. This serves as an internal physical reference to guide global illumination estimation and correct color casts. Second, we propose a dual-domain preservation strategy with spatial and spectral constraints to construct internal structural references. Specifically, an Illumination-Aligned Perceptual loss preserves global structures under illumination shifts, while a Shift-Invariant Spectral Correlation loss captures fine-grained local structures and suppresses high-frequency noise. Finally, we propose a Gain-Adaptive Feature Modulation (GAFM) mechanism to address highly spatially-variant residual noise. By transforming the self-estimated illumination map into an internal spatial gain prior, GAFM dynamically guides a blind-spot network for spatially-aware denoising. Extensive experiments demonstrate that our method achieves state-of-the-art performance, delivering superior noise suppression and textural fidelity. Code will be publicly released at https://visonj.github.io/IRLE/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a self-supervised low-light image enhancement (LLIE) method called Internally Referenced LLIE. It extracts a low-frequency pseudo ground-truth from the input via local exposure simulation to guide illumination correction and color cast removal, constructs dual-domain structural references using an Illumination-Aligned Perceptual loss and a Shift-Invariant Spectral Correlation loss, and introduces Gain-Adaptive Feature Modulation (GAFM) that converts the self-estimated illumination map into a spatial gain prior for blind-spot denoising. The central claim is that this internal-reference approach achieves state-of-the-art noise suppression and textural fidelity without paired external data.
Significance. If the internal references are shown to be reliable and the SOTA claim holds under rigorous evaluation, the work would be significant for self-supervised LLIE by demonstrating a practical way to derive supervision signals directly from single degraded inputs, potentially improving generalization and reducing dataset collection costs. The planned code release supports reproducibility.
major comments (3)
- Abstract: the claim that 'extensive experiments demonstrate that our method achieves state-of-the-art performance' is unsupported because the manuscript provides no quantitative tables, ablation studies, or error analysis, rendering the central performance claim unverifiable from the text.
- Method description (low-frequency pseudo ground-truth extraction): the assumption that the local exposure-simulated low-frequency component extracted from a single noisy input is sufficiently free of residual illumination, color casts, and spatially varying noise to serve as a reliable physical reference is load-bearing for the self-supervised claim, yet no validation or sensitivity analysis against artifact retention is described.
- GAFM mechanism: the transformation of the self-estimated illumination map into an internal spatial gain prior for guiding the blind-spot network is presented procedurally without equations or ablation showing that this prior avoids propagating errors from imperfect illumination estimates in severely degraded inputs.
minor comments (1)
- The abstract introduces several new terms (GAFM, Illumination-Aligned Perceptual loss, Shift-Invariant Spectral Correlation loss) without immediate cross-references to their defining equations or algorithmic steps, which reduces readability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below, indicating where revisions will be made to improve clarity and support for the claims.
read point-by-point responses
-
Referee: Abstract: the claim that 'extensive experiments demonstrate that our method achieves state-of-the-art performance' is unsupported because the manuscript provides no quantitative tables, ablation studies, or error analysis, rendering the central performance claim unverifiable from the text.
Authors: We agree that the abstract claim requires visible substantiation in the manuscript. The experimental section of the full paper contains quantitative comparisons (PSNR/SSIM on LOL and other benchmarks) against recent self-supervised LLIE methods, plus component ablations and error analysis. We will revise the manuscript to prominently include and reference these tables and studies so the performance claim is directly verifiable from the text. revision: yes
-
Referee: Method description (low-frequency pseudo ground-truth extraction): the assumption that the local exposure-simulated low-frequency component extracted from a single noisy input is sufficiently free of residual illumination, color casts, and spatially varying noise to serve as a reliable physical reference is load-bearing for the self-supervised claim, yet no validation or sensitivity analysis against artifact retention is described.
Authors: The local exposure simulation isolates the low-frequency component through patch-wise averaging under simulated exposures, which is intended to suppress high-frequency noise while retaining structural illumination information. We acknowledge that the current manuscript lacks explicit validation of this assumption. In revision we will add a dedicated sensitivity analysis subsection with quantitative metrics and visual examples showing artifact retention rates across noise levels and illumination variations. revision: yes
-
Referee: GAFM mechanism: the transformation of the self-estimated illumination map into an internal spatial gain prior for guiding the blind-spot network is presented procedurally without equations or ablation showing that this prior avoids propagating errors from imperfect illumination estimates in severely degraded inputs.
Authors: GAFM converts the illumination map into a normalized spatial gain prior that modulates blind-spot features to achieve spatially adaptive denoising. We agree the description is procedural and lacks formal equations plus targeted ablations. We will insert the exact mathematical definition of the gain modulation and add an ablation study that measures performance degradation when the illumination estimate contains controlled errors, demonstrating that the prior does not propagate those errors under severe degradation. revision: yes
Circularity Check
No circularity; internal references extracted procedurally from input without reduction to fitted parameters or self-citations.
full rationale
The paper defines its self-supervised framework by procedurally extracting a low-frequency pseudo ground-truth via local exposure simulation and dual-domain structural references via spatial/spectral constraints from the single input image. These guide the Illumination-Aligned Perceptual loss, Shift-Invariant Spectral Correlation loss, and GAFM mechanism. No equations, derivations, or self-citations are present that reduce the SOTA performance claim or the reliability assumption to the inputs by construction. The central premise is a methodological choice of internal supervision signals, not a self-definitional loop or fitted-input prediction. This matches the expectation of a self-contained derivation with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
free parameters (1)
- loss weighting coefficients
axioms (1)
- domain assumption A low-frequency version of the input can serve as a reliable internal physical reference for illumination estimation.
invented entities (1)
-
Gain-Adaptive Feature Modulation (GAFM)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Eirikur Agustsson and Radu Timofte. 2017. NTIRE 2017 Challenge on Single Image Super-Resolution: Dataset and Study. InIEEE Conference on Computer Vision and Pattern Recognition Workshops
2017
-
[2]
Joshua Batson and Loic Royer. 2019. Noise2self: Blind denoising by self- supervision. InInternational conference on machine learning. PMLR, 524–533
2019
-
[3]
Yuanhao Cai, Hao Bian, Jing Lin, Haoqian Wang, Radu Timofte, and Yulun Zhang
-
[4]
InProceedings of the IEEE/CVF international conference on computer vision
Retinexformer: One-stage retinex-based transformer for low-light image enhancement. InProceedings of the IEEE/CVF international conference on computer vision. 12504–12513
-
[5]
Guangyao Chen, Peixi Peng, Li Ma, Jia Li, Lin Du, and Yonghong Tian. 2021. Amplitude-phase recombination: Rethinking robustness of convolutional neural networks in frequency domain. InProceedings of the IEEE/CVF international conference on computer vision. 458–467
2021
-
[6]
Rethinking data augmentation for robust LiDAR semantic segmentation in adverse weather,
Tomáš Chobola, Yu Liu, Hanyi Zhang, Julia A. Schnabel, and Tingying Peng. 2024.Fast Context-Based Low-Light Image Enhancement via Neural Implicit Representations. Springer Nature Switzerland, 413–430. doi:10.1007/978-3-031- 73016-0_24
-
[7]
Ben Fei, Zhaoyang Lyu, Liang Pan, Junzhe Zhang, Weidong Yang, Tianyue Luo, Bo Zhang, and Bo Dai. 2023. Generative diffusion prior for unified image restora- tion and enhancement. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 9935–9946
2023
-
[8]
Alessandro Foi, Mejdi Trimeche, Vladimir Katkovnik, and Karen Egiazarian
-
[9]
Practical Poissonian-Gaussian noise modeling and fitting for single-image raw-data.IEEE transactions on image processing17, 10 (2008), 1737–1754
2008
-
[10]
Zhenqi Fu, Yan Yang, Xiaotong Tu, Yue Huang, Xinghao Ding, and Kai-Kuang Ma. 2023. Learning a simple low-light image enhancer from paired low-light instances. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 22252–22261
2023
-
[11]
Chunle Guo, Chongyi Li, Jichang Guo, Chen Change Loy, Junhui Hou, Sam Kwong, and Runmin Cong. 2020. Zero-reference deep curve estimation for low- light image enhancement. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 1780–1789
2020
-
[12]
Xiaojie Guo, Yu Li, and Haibin Ling. 2016. LIME: Low-light image enhancement via illumination map estimation.IEEE Transactions on image processing26, 2 (2016), 982–993
2016
-
[13]
Jiang Hai, Zhu Xuan, Ren Yang, Yutong Hao, Fengzhu Zou, Fang Lin, and Songchen Han. 2023. R2rnet: Low-light image enhancement via real-low to real-normal network.Journal of Visual Communication and Image Representation 90 (2023), 103712
2023
- [14]
-
[15]
Jie Huang, Yajing Liu, Feng Zhao, Keyu Yan, Jinghao Zhang, Yukun Huang, Man Zhou, and Zhiwei Xiong. 2022. Deep fourier-based exposure correction network with spatial-frequency interaction. InEuropean conference on computer vision. Springer, 163–180
2022
-
[16]
Tao Huang, Songjiang Li, Xu Jia, Huchuan Lu, and Jianzhuang Liu. 2021. Neigh- bor2Neighbor: Self-Supervised Denoising From Single Noisy Images. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 14781–14790
2021
-
[17]
Hyemi Jang, Junsung Park, Dahuin Jung, Jaihyun Lew, Ho Bae, and Sungroh Yoon. 2023. PUCA: Patch-unshuffle and channel attention for enhanced self- supervised image denoising.Advances in Neural Information Processing Systems 36 (2023), 19217–19229
2023
-
[18]
Liming Jiang, Bo Dai, Wayne Wu, and Chen Change Loy. 2021. Focal frequency loss for image reconstruction and synthesis. InProceedings of the IEEE/CVF international conference on computer vision. 13919–13929
2021
-
[19]
Yifan Jiang, Xinyu Gong, Ding Liu, Yu Cheng, Chen Fang, Xiaohui Shen, Jian- chao Yang, Pan Zhou, and Zhangyang Wang. 2021. Enlightengan: Deep light enhancement without paired supervision.IEEE transactions on image processing 30 (2021), 2340–2349
2021
-
[20]
Donggoo Jung, Daehyun Kim, and Tae Hyun Kim. 2025. Continuous exposure learning for low-light image enhancement using Neural ODEs. InThe Thirteenth International Conference on Learning Representations
2025
-
[21]
Alexander Krull, Tim-Oliver Buchholz, and Florian Jug. 2019. Noise2void- learning denoising from single noisy images. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2129–2137
2019
-
[22]
Samuli Laine, Tero Karras, Jaakko Lehtinen, and Timo Aila. 2019. High-quality self-supervised deep image denoising.Advances in neural information processing systems32 (2019)
2019
-
[23]
Wooseok Lee, Sanghyun Son, and Kyoung Mu Lee. 2022. Ap-bsn: Self-supervised denoising for real-world images via asymmetric pd and blind-spot network. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 17725–17734
2022
-
[24]
Jaakko Lehtinen, Jacob Munkberg, Jon Hasselgren, Samuli Laine, Tero Karras, Miika Aittala, and Timo Aila. 2018. Noise2Noise: Learning image restoration without clean data.arXiv preprint arXiv:1803.04189(2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[25]
Chongyi Li, Chunle Guo, and Chen Change Loy. 2021. Learning to enhance low-light image via zero-reference deep curve estimation.IEEE transactions on pattern analysis and machine intelligence44, 8 (2021), 4225–4238
2021
- [27]
- [28]
-
[29]
Zhexin Liang, Chongyi Li, Shangchen Zhou, Ruicheng Feng, and Chen Change Loy. 2023. Iterative prompt learning for unsupervised backlit image enhancement. InProceedings of the IEEE/CVF International Conference on Computer Vision. 8094– 8103
2023
-
[30]
Bee Lim, Sanghyun Son, Heewon Kim, Seungjun Nah, and Kyoung Mu Lee
-
[31]
In Proceedings of the IEEE conference on computer vision and pattern recognition workshops
Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE conference on computer vision and pattern recognition workshops. 136–144
-
[32]
Risheng Liu, Long Ma, Jiaao Zhang, Xin Fan, and Zhongxuan Luo. 2021. Retinex- inspired unrolling with cooperative prior architecture search for low-light image enhancement. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 10561–10570
2021
-
[33]
Kin Gwn Lore, Adedotun Akintayo, and Soumik Sarkar. 2017. LLNet: A deep au- toencoder approach to natural low-light image enhancement.Pattern Recognition 61 (2017), 650–662
2017
-
[34]
Feifan Lv, Feng Lu, Jianhua Wu, and Chongsoon Lim. 2018. MBLLEN: Low- light image/video enhancement using cnns.. InBmvc, Vol. 220. Northumbria University, 4
2018
-
[35]
Xiaoqian Lv, Shengping Zhang, Chenyang Wang, Yichen Zheng, Bineng Zhong, Chongyi Li, and Liqiang Nie. 2024. Fourier priors-guided diffusion for zero-shot joint low-light enhancement and deblurring. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 25378–25388
2024
-
[36]
Long Ma, Tengyu Ma, Risheng Liu, Xin Fan, and Zhongxuan Luo. 2022. Toward fast, flexible, and robust low-light image enhancement. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 5637–5646
2022
-
[37]
Hue Nguyen, Diep Tran, Khoi Nguyen, and Rang Nguyen. 2023. Psenet: Pro- gressive self-enhancement network for unsupervised extreme-light image en- hancement. InProceedings of the IEEE/CVF winter conference on applications of computer vision. 1756–1765
2023
-
[38]
Emanuel Parzen. 1962. On estimation of a probability density function and mode. The annals of mathematical statistics33, 3 (1962), 1065–1076
1962
-
[39]
Yossi Rubner, Carlo Tomasi, and Leonidas J Guibas. 2000. The earth mover’s distance as a metric for image retrieval.International journal of computer vision 40, 2 (2000), 99–121
2000
-
[40]
Donghun Ryou, Inju Ha, Hyewon Yoo, Dongwan Kim, and Bohyung Han. 2024. Robust image denoising through adversarial frequency mixup. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2723–2732
2024
-
[41]
Yiqi Shi, Duo Liu, Liguo Zhang, Ye Tian, Xuezhi Xia, and Xiaojing Fu. 2024. ZERO- IG: Zero-shot illumination-guided joint denoising and adaptive enhancement for low-light images. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 3015–3024
2024
-
[42]
Chenxi Wang, Hongjun Wu, and Zhi Jin. 2023. Fourllie: Boosting low-light image enhancement by fourier frequency information. InProceedings of the 31st ACM international conference on multimedia. 7459–7469
2023
-
[43]
Yufei Wang, Renjie Wan, Wenhan Yang, Haoliang Li, Lap-Pui Chau, and Alex Kot. 2022. Low-light image enhancement with normalizing flow. InProceedings of the AAAI conference on artificial intelligence, Vol. 36. 2604–2612
2022
-
[44]
Zejin Wang, Jiazheng Liu, Guoqing Li, and Hua Han. 2022. Blind2unblind: Self-supervised image denoising with visible blind spots. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2027–2036
2022
-
[45]
Chen Wei, Wenjing Wang, Wenhan Yang, and Jiaying Liu. 2018. Deep retinex de- composition for low-light enhancement.arXiv preprint arXiv:1808.04560(2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[46]
Wenhui Wu, Jian Weng, Pingping Zhang, Xu Wang, Wenhan Yang, and Jianmin Jiang. 2022. Uretinex-net: Retinex-based deep unfolding network for low-light image enhancement. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 5901–5910
2022
-
[47]
Xiaogang Xu, Ruixing Wang, Chi-Wing Fu, and Jiaya Jia. 2022. Snr-aware low- light image enhancement. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 17714–17724
2022
-
[48]
Shuzhou Yang, Moxuan Ding, Yanmin Wu, Zihan Li, and Jian Zhang. 2023. Implicit Neural Representation for Cooperative Low-light Image Enhancement. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). 12918–12927. He et al
2023
-
[49]
Wenhan Yang, Wenjing Wang, Haofeng Huang, Shiqi Wang, and Jiaying Liu
-
[50]
Sparse gradient regularized deep retinex network for robust low-light image enhancement.IEEE Transactions on Image Processing30 (2021), 2072–2086
2021
-
[51]
Yanchao Yang and Stefano Soatto. 2020. Fda: Fourier domain adaptation for semantic segmentation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 4085–4095
2020
-
[52]
Xunpeng Yi, Han Xu, Hao Zhang, Linfeng Tang, and Jiayi Ma. 2023. Diff-retinex: Rethinking low-light image enhancement with a generative diffusion model. In Proceedings of the IEEE/CVF international conference on computer vision. 12302– 12311
2023
-
[53]
Syed Waqas Zamir, Aditya Arora, Salman Khan, Munawar Hayat, Fahad Shah- baz Khan, and Ming-Hsuan Yang. 2022. Restormer: Efficient transformer for high-resolution image restoration. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 5728–5739
2022
-
[54]
Yonghua Zhang, Jiawan Zhang, and Xiaojie Guo. 2019. Kindling the darkness: A practical low-light image enhancer. InProceedings of the 27th ACM international conference on multimedia. 1632–1640
2019
-
[55]
Zunjin Zhao, Bangshu Xiong, Lei Wang, Qiaofeng Ou, Lei Yu, and Fa Kuang. 2021. RetinexDIP: A unified deep framework for low-light image enhancement.IEEE Transactions on Circuits and Systems for Video Technology32, 3 (2021), 1076–1088
2021
-
[56]
Shen Zheng and Gaurav Gupta. 2022. Semantic-guided zero-shot learning for low- light image/video enhancement. InProceedings of the IEEE/CVF Winter conference on applications of computer vision. 581–590
2022
-
[57]
Han Zhou, Wei Dong, Xiaohong Liu, Shuaicheng Liu, Xiongkuo Min, Guangtao Zhai, and Jun Chen. 2024. Glare: Low light image enhancement via generative latent feature based codebook retrieval. InEuropean Conference on Computer Vision. Springer, 36–54
2024
-
[58]
Anqi Zhu, Lin Zhang, Ying Shen, Yong Ma, Shengjie Zhao, and Yicong Zhou. 2020. Zero-shot restoration of underexposed images via robust retinex decomposition. In2020 IEEE international conference on multimedia and expo (ICME). IEEE, 1–6. Internally Referenced Low-Light Enhancement Appendix A1 Detailed Formulation of the Cross-Frequency Correlation (CFC) In...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.