Single-Rollout Hidden-State Dynamics for Training-Free RLVR Data Selection
Pith reviewed 2026-06-29 14:05 UTC · model grok-4.3
The pith
The magnitude of hidden-state change from one reasoning rollout acts as a proxy to select useful RLVR data without training or labels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SHIFT is a selector that, for each candidate, performs one deterministic reasoning rollout, computes the reasoning-induced representation shift as the start-to-end hidden-state delta, ranks instances by the magnitude of this delta as a utility proxy, and applies a quality-weighted farthest-first CoreSet procedure in the RIRS-augmented space to form compact subsets.
What carries the argument
The reasoning-induced representation shift (RIRS), defined as the start-to-end hidden-state delta from a single deterministic rollout, used as a proxy for instance utility.
If this is right
- SHIFT produces subsets that improve in-domain accuracy on mathematical reasoning and medical QA benchmarks under very low data budgets.
- Selected data leads to better transfer performance on harder evaluation settings compared to baselines.
- RIRS-based selection combined with quality-weighted coverage provides gains that neither component achieves alone.
- RIRS captures information not reducible to simple input or output length statistics.
Where Pith is reading between the lines
- This suggests internal dynamics during inference may encode signals about learning potential that could apply to other selection tasks.
- Extending the single-rollout approach to models of different scales or architectures might reveal whether the proxy generalizes broadly.
- Testing the method on additional domains with expensive verification could show its limits in practice.
Load-bearing premise
The magnitude of the reasoning-induced representation shift from a single deterministic rollout functions as a reliable proxy for instance utility without access to verifiable rewards or ground-truth answers.
What would settle it
Measuring whether subsets chosen by highest RIRS values produce larger RLVR performance gains than low-RIRS subsets on the same benchmarks would test the claim; absence of a positive correlation would falsify it.
Figures

read the original abstract
Reinforcement learning with verifiable rewards (RLVR) can yield large reasoning gains from very few training instances, yet its strong sensitivity to which instances are used makes data selection a central bottleneck. Most existing selection pipelines rely on training-time optimization signals and/or require access to verifiable rewards or ground-truth answers over large candidate pools, which is costly and often infeasible in specialized domains. We study RLVR data selection in a setting where selection must be performed before any RL training and without labels or reward evaluation on the full pool. We propose SHIFT, a one-shot, training-free selector based solely on inference-time hidden-state dynamics. For each candidate instance, SHIFT runs a single deterministic reasoning rollout and computes a reasoning-induced representation shift (RIRS) as the start-to-end hidden-state delta. SHIFT uses the RIRS magnitude as a lightweight proxy for instance utility and enforces coverage via a quality-weighted farthest-first CoreSet procedure in an RIRS-augmented feature space, producing compact subsets that scale to large unlabeled pools. Across mathematical reasoning and medical QA benchmarks under ultra-low budgets, SHIFT consistently outperforms training-free diversity and difficulty/uncertainty baselines, improving both in-domain accuracy and transfer to harder evaluation settings. Ablations show that RIRS-based coverage and quality-weighting contribute complementary gains, and analyses indicate that RIRS is not explained by simple input/output length statistics. Code is available at github.com/JianghaoWu/SHIFT.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SHIFT, a training-free data selection method for RLVR that computes a reasoning-induced representation shift (RIRS) as the start-to-end hidden-state delta from a single deterministic rollout per candidate instance, then applies quality-weighted farthest-first traversal in an RIRS-augmented space to produce compact subsets. It claims that this yields subsets that consistently outperform training-free diversity and difficulty/uncertainty baselines on mathematical reasoning and medical QA benchmarks under ultra-low budgets, with gains in both in-domain accuracy and transfer to harder settings; ablations attribute complementary benefits to RIRS coverage and quality weighting, while analyses indicate RIRS is independent of input/output length.
Significance. If the central results hold, SHIFT would provide a practical, label-free approach to instance selection for RLVR in domains where reward evaluation is costly, potentially lowering the barrier to applying RLVR in specialized settings. The public code release is a clear strength that supports reproducibility and further testing of the hidden-state proxy.
major comments (3)
- [Abstract] Abstract: the claim of 'consistent outperformance' and 'improving both in-domain accuracy and transfer' is asserted without any reported accuracy deltas, error bars, dataset sizes, number of runs, or statistical tests, so the magnitude and reliability of the gains cannot be assessed from the provided text.
- [Method and Experiments] Method description and experimental results: the load-bearing claim that RIRS magnitude ranks instances by downstream RLVR utility (rather than tracking generic representation change or length) lacks a direct test such as rank correlation between RIRS and per-instance policy improvement under RLVR; without this, it remains possible that the reported gains are explained by the CoreSet component alone.
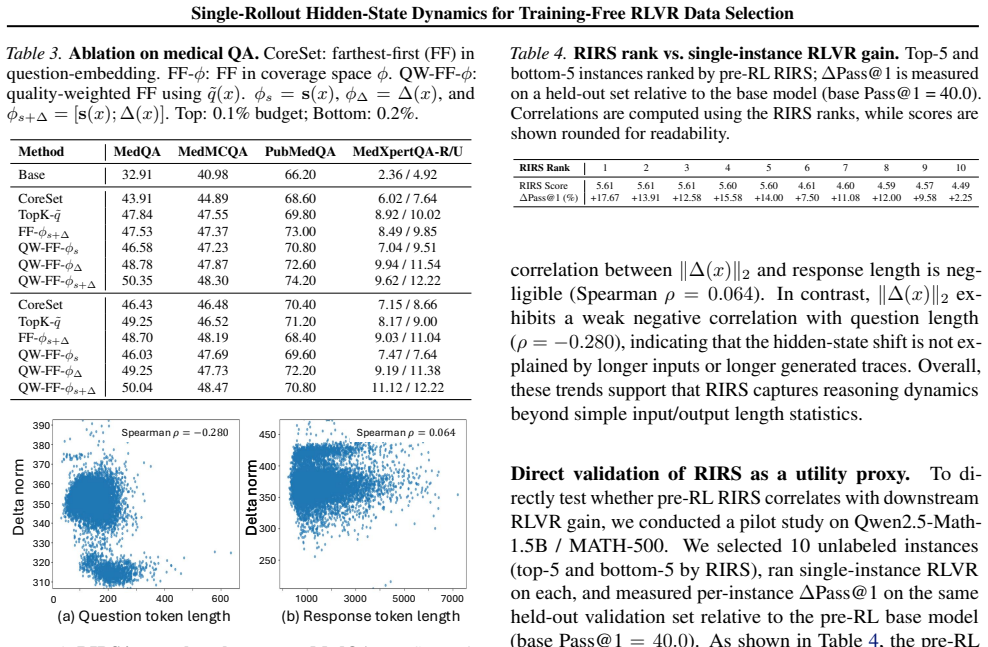
- [Ablations and Analyses] Ablations and analyses: the statement that 'RIRS is not explained by simple input/output length statistics' is presented without the specific correlation coefficient, regression result, or controlled ablation that would quantify the residual predictive power after length is accounted for.
minor comments (2)
- [Method] The definition of the hidden-state delta (norm, cosine similarity, or layer choice) should be stated explicitly with an equation for reproducibility.
- [Experiments] Figure captions and table headers would benefit from explicit mention of the number of seeds and exact budget sizes used in each comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below, indicating planned revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of 'consistent outperformance' and 'improving both in-domain accuracy and transfer' is asserted without any reported accuracy deltas, error bars, dataset sizes, number of runs, or statistical tests, so the magnitude and reliability of the gains cannot be assessed from the provided text.
Authors: We agree that the abstract would benefit from quantitative grounding. In revision we will insert representative accuracy deltas (e.g., average gains of 4–8 points over the strongest training-free baseline), state that all results are means over three independent runs with standard deviations, and note the candidate-pool and evaluation sizes. Full tables with error bars and significance tests remain in the experimental section. revision: yes
-
Referee: [Method and Experiments] Method description and experimental results: the load-bearing claim that RIRS magnitude ranks instances by downstream RLVR utility (rather than tracking generic representation change or length) lacks a direct test such as rank correlation between RIRS and per-instance policy improvement under RLVR; without this, it remains possible that the reported gains are explained by the CoreSet component alone.
Authors: A direct per-instance rank correlation would indeed be informative. However, computing per-instance policy improvement requires separate RLVR training runs on each candidate, which is computationally prohibitive for pools of thousands of instances and incompatible with the training-free premise. Our current evidence is that SHIFT (RIRS + quality-weighted CoreSet) outperforms both plain CoreSet and other diversity baselines in the reported experiments; we will add an explicit discussion of this limitation and the indirect nature of the proxy. revision: partial
-
Referee: [Ablations and Analyses] Ablations and analyses: the statement that 'RIRS is not explained by simple input/output length statistics' is presented without the specific correlation coefficient, regression result, or controlled ablation that would quantify the residual predictive power after length is accounted for.
Authors: We will augment the analyses section with the Pearson correlation coefficients between RIRS magnitude and (i) input length, (ii) output length, and (iii) total tokens. We will also report a controlled ablation in which length is regressed out of the RIRS feature before CoreSet selection, showing that the residual RIRS signal still contributes measurable gains. revision: yes
Circularity Check
No significant circularity; direct heuristic computation
full rationale
The paper defines RIRS explicitly as the magnitude of the start-to-end hidden-state delta computed from a single deterministic rollout on each candidate instance, then applies a standard quality-weighted farthest-first traversal in the resulting augmented feature space. No equations, parameters, or selection criteria are fitted to the target utility metric; the proxy is used as-is without reduction to a self-referential quantity or prior self-citation. The method is therefore self-contained as a training-free heuristic whose validity is assessed empirically rather than by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption RIRS magnitude from a single deterministic rollout correlates with downstream RLVR utility
invented entities (1)
-
RIRS (reasoning-induced representation shift)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Influence scores at scale for efficient language data sampling.arXiv preprint arXiv:2311.16298,
Anand, N., Tan, J., and Minakova, M. Influence scores at scale for efficient language data sampling.arXiv preprint arXiv:2311.16298,
-
[2]
Alpagasus: Training a better alpaca with fewer data.arXiv preprint arXiv:2307.08701,
Chen, L., Li, S., Yan, J., Wang, H., Gunaratna, K., Yadav, V ., Tang, Z., Srinivasan, V ., Zhou, T., Huang, H., et al. Alpagasus: Training a better alpaca with fewer data.arXiv preprint arXiv:2307.08701,
-
[3]
Chen, X., Liao, M., Chen, G., Li, C., Fu, B., Fan, K., and Liu, X. From data-centric to sample-centric: Enhanc- ing llm reasoning via progressive optimization.arXiv preprint arXiv:2507.06573,
-
[4]
Learning without training: The implicit dynamics of in-context learning
Dherin, B., Munn, M., Mazzawi, H., Wunder, M., and Gonzalvo, J. Learning without training: The im- plicit dynamics of in-context learning.arXiv preprint arXiv:2507.16003,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
TinyStories: How Small Can Language Models Be and Still Speak Coherent English?
Eldan, R. and Li, Y . Tinystories: How small can lan- guage models be and still speak coherent english?arXiv preprint arXiv:2305.07759,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Vaughan, A., et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Gunasekar, S., Zhang, Y ., Aneja, J., Mendes, C. C. T., Del Giorno, A., Gopi, S., Javaheripi, M., Kauffmann, P., de Rosa, G., Saarikivi, O., et al. Textbooks are all you need.arXiv preprint arXiv:2306.11644,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., and Bi, X. DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforce- ment learning.arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Measuring Mathematical Problem Solving With the MATH Dataset
Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., and Steinhardt, J. Measuring math- ematical problem solving with the math dataset.arXiv preprint arXiv:2103.03874,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
PubMedQA: A Dataset for Biomedical Research Question Answering
Jin, Q., Dhingra, B., Liu, Z., Cohen, W. W., and Lu, X. PubMedQA: A dataset for biomedical research question answering.arXiv preprint arXiv:1909.06146,
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[11]
Limr: Less is more for rl scaling
Li, X., Zou, H., and Liu, P. Limr: Less is more for rl scaling. arXiv preprint arXiv:2502.11886,
-
[12]
Li, Y ., Huang, Z., Wu, Y ., Wang, W., Li, X., Luo, Y ., Su, W., Zheng, B., and Liu, P. One sample to rule them all: Extreme data efficiency in multidiscipline reasoning with reinforcement learning.arXiv preprint arXiv:2601.03111,
-
[13]
Liang, Z., Li, R., Zhou, Y ., Song, L., Yu, D., Du, X., Mi, H., and Yu, D. Clue: Non-parametric verification from experience via hidden-state clustering.arXiv preprint arXiv:2510.01591,
-
[14]
10 Single-Rollout Hidden-State Dynamics for Training-Free RLVR Data Selection Marion, M., ¨Ust¨un, A., Pozzobon, L., Wang, A., Fadaee, M., and Hooker, S. When less is more: Investigating data pruning for pretraining LLMs at scale.arXiv preprint arXiv:2309.04564,
-
[15]
Naharas, N., Nguyen, D., Bulut, N., Bateni, M., Mirrokni, V ., and Mirzasoleiman, B. Data selection for fine-tuning vision language models via cross modal alignment trajec- tories.arXiv preprint arXiv:2510.01454,
-
[16]
Olmo, T., Ettinger, A., Bertsch, A., Kuehl, B., Graham, D., Heineman, D., Groeneveld, D., Brahman, F., Tim- bers, F., Ivison, H., et al. Olmo 3.arXiv preprint arXiv:2512.13961,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Difficulty-Based Preference Data Selection by DPO Implicit Reward Gap
Qi, X., Xu, R., and Jin, Z. Difficulty-based preference data selection by dpo implicit reward gap.arXiv preprint arXiv:2508.04149,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Active Learning for Convolutional Neural Networks: A Core-Set Approach
Sener, O. and Savarese, S. Active learning for convolutional neural networks: A core-set approach.arXiv preprint arXiv:1708.00489,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Wang, J., Lin, X., Qiao, R., Koh, P. W., Foo, C.-S., and Low, B. K. H. Nice data selection for instruction tun- ing in LLMs with non-differentiable evaluation metric. International Conference on Machine Learning, 2025a. Wang, P.-Y ., Liu, T.-S., Wang, C., Li, Z., Wang, Y ., Yan, S., Jia, C., Liu, X.-H., Chen, X., Xu, J., et al. A survey on large language ...
-
[20]
Wang, Y ., Yang, Q., Zeng, Z., Ren, L., Liu, L., Peng, B., Cheng, H., He, X., Wang, K., Gao, J., Chen, W., Wang, S., Du, S. S., and Shen, Y . Reinforcement learning for reasoning in large language models with one training example.Advances in Neural Information Processing Systems, 2025c. Wen, X., Liu, Z., Zheng, S., Ye, S., Wu, Z., Wang, Y ., Xu, Z., Liang...
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Less: Selecting influential data for targeted instruction tuning.arXiv preprint arXiv:2402.04333,
Xia, M., Malladi, S., Gururangan, S., Arora, S., and Chen, D. Less: Selecting influential data for targeted instruction tuning.arXiv preprint arXiv:2402.04333,
-
[22]
Qwen2.5-Math Technical Report: Toward Mathematical Expert Model via Self-Improvement
Yang, A., Zhang, B., Hui, B., Gao, B., Yu, B., Li, C., Liu, D., Tu, J., Zhou, J., Lin, J., et al. Qwen2.5-Math techni- cal report: Toward mathematical expert model via self- improvement.arXiv preprint arXiv:2409.12122,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
11 Single-Rollout Hidden-State Dynamics for Training-Free RLVR Data Selection Yue, Y ., Chen, Z., Lu, R., Zhao, A., Wang, Z., Song, S., and Huang, G. Does reinforcement learning really incentivize reasoning capacity in LLMs beyond the base model? arXiv preprint arXiv:2504.13837,
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
MedXpertQA: Benchmarking Expert-Level Medical Reasoning and Understanding
Zuo, Y ., Qu, S., Li, Y ., Chen, Z., Zhu, X., Hua, E., Zhang, K., Ding, N., and Zhou, B. Medxpertqa: Benchmarking expert-level medical reasoning and understanding.arXiv preprint arXiv:2501.18362,
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.