Interpretability-Guided Layer Selection over Subspace Projection: SAEs as Stethoscopes, Not Scalpels, for Raw Task Vector Model Editing
Pith reviewed 2026-06-29 13:57 UTC · model grok-4.3
The pith
Using SAEs only to select layers for raw task vector injection improves math reasoning accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SAEs function as stethoscopes that identify the right layers rather than scalpels that filter task vectors; injecting the raw vectors into those layers alone produces net gains in mathematical reasoning without the energy loss of subspace projection.
What carries the argument
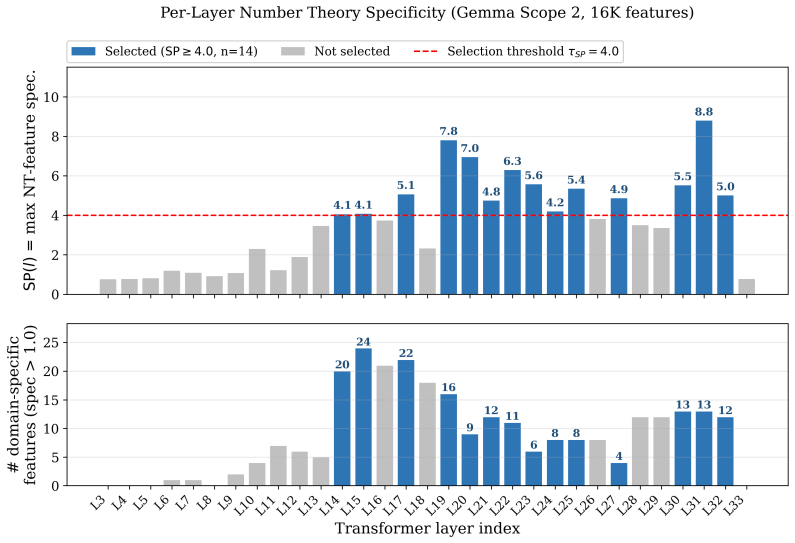
The SAE-derived specificity score, which ranks layers by how well they align with the task for unfiltered vector injection.
If this is right
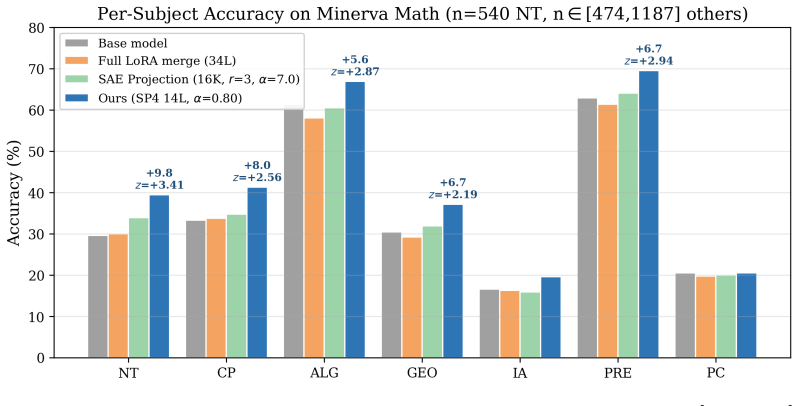
- Five of seven math subjects show statistically significant gains.
- No subject experiences significant degradation.
- The procedure adds no inference cost and remains fully deterministic.
Where Pith is reading between the lines
- The same layer-selection logic could be tested on non-mathematical editing tasks to check generality.
- The reported geometric misalignment between SAE directions and task vectors may limit other subspace-based editing approaches.
- Combining the specificity score with other layer-ranking methods might further refine the selection.
Load-bearing premise
The specificity score from the SAE correctly flags layers where the raw task vector will improve the target capability without causing degradation or forgetting elsewhere.
What would settle it
Re-running the Minerva Math evaluation on Gemma-3-4B-IT and finding no accuracy change or a drop when task vectors are injected only into the SAE-selected layers would disprove the central result.
Figures



read the original abstract
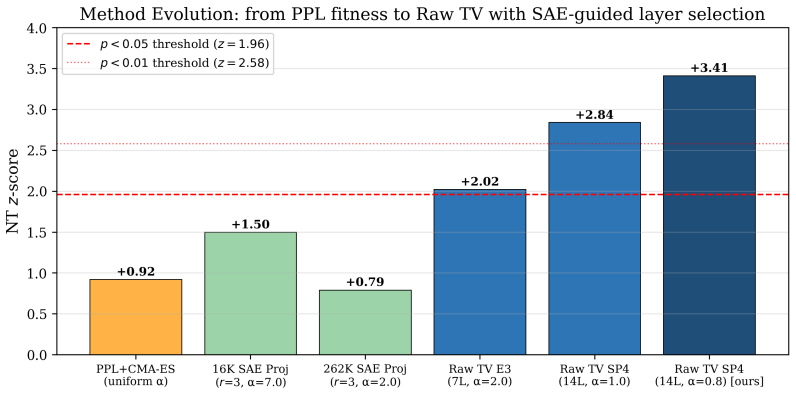
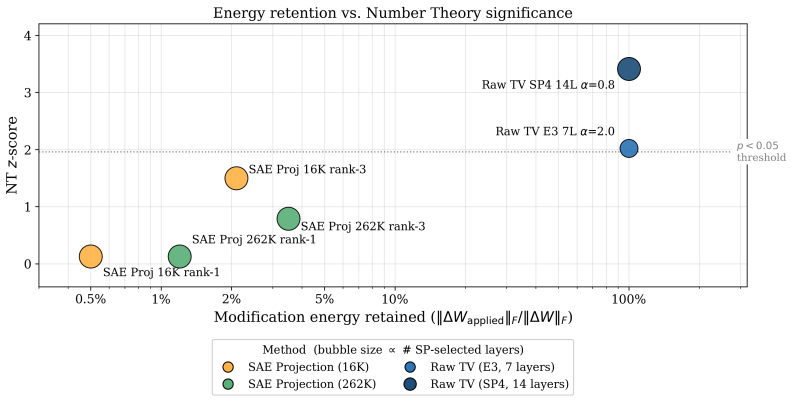
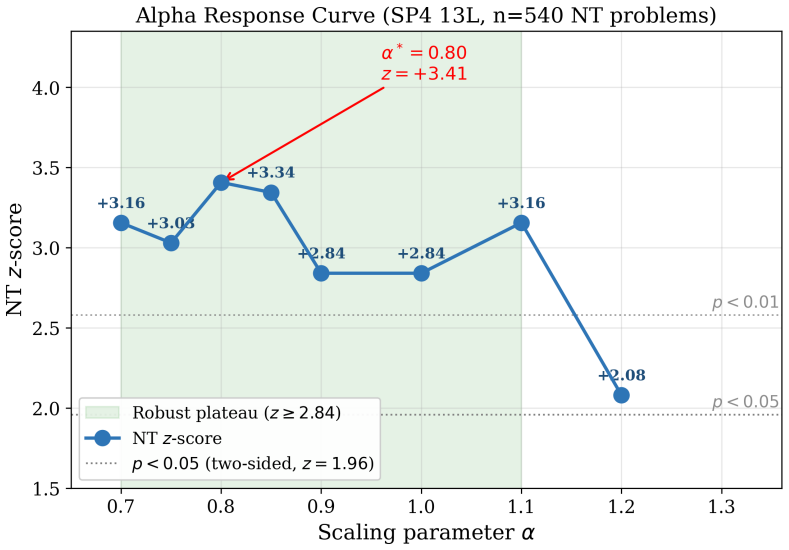
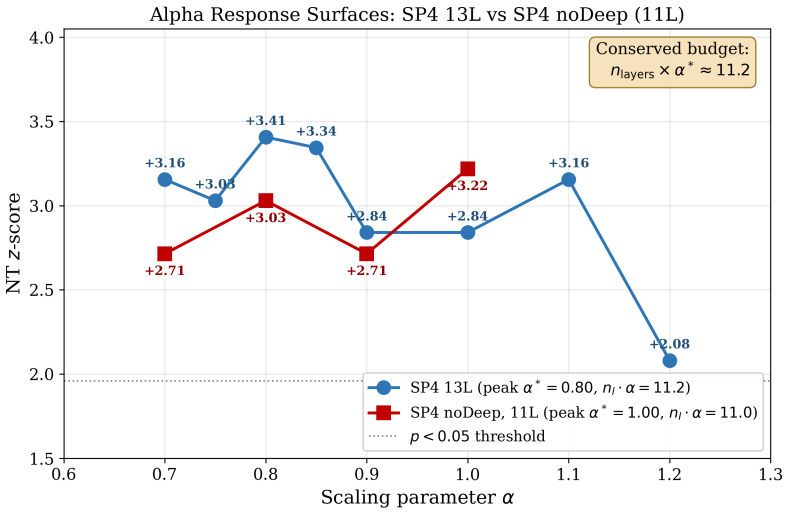
LLMs increasingly require surgical model editing to enhance domain-specific capabilities without incurring the computational cost or catastrophic forgetting associated with full fine-tuning. Sparse Autoencoders (SAEs) have emerged as a promising tool in this setting, in principle allowing for feature-level identification of where to intervene. In this work, we rigorously evaluate an SAE-guided editing pipeline for mathematical reasoning on Gemma-3-4B-IT and uncover a fundamental failure mode: the intuitively appealing approach of projecting task vectors onto SAE feature subspaces acts as an information bottleneck that discards approximately 97% of the modification energy, yielding no statistically significant improvements across seven math subjects. We show that this failure stems from a geometric misalignment between activation-space SAE directions and weight-space task vectors. We then propose a shift in perspective: SAE as a Stethoscope, Not a Scalpel, where SAEs are used for layer-level diagnosis rather than intervention-level filtering. By injecting unfiltered raw task vectors only into layers identified by an SAE-derived specificity score, we improve Number Theory accuracy from 29.6% to 39.4% (z=+3.41, p=0.0007) on the Minerva Math benchmark; 5 of 7 math subjects significantly improved and none significantly degraded. Our method is fully deterministic, requires no additional inference cost, and provides a principled framework for interpretability-guided model editing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates SAE-based model editing for mathematical reasoning on Gemma-3-4B-IT. It reports that projecting task vectors onto SAE feature subspaces discards ~97% of modification energy and produces no significant gains across seven math subjects. It then shows that using an SAE-derived specificity score solely to select layers for injecting unfiltered raw task vectors improves Number Theory accuracy from 29.6% to 39.4% (z=+3.41, p=0.0007) on Minerva Math, with significant gains in 5 of 7 subjects and none degraded. The method is presented as deterministic and inference-free.
Significance. If the central empirical result holds after controls, the work supplies concrete evidence that interpretability tools can guide layer selection for task-vector editing without the energy-loss bottleneck of feature projection, yielding measurable accuracy gains on held-out math benchmarks with reported p-values and an energy-loss quantification.
major comments (1)
- [Results on Minerva Math benchmark (as described in abstract and experimental evaluation)] The central claim attributes performance gains to the SAE specificity score for layer selection, yet the manuscript reports results only for the SAE-chosen layers and does not include ablations that apply the identical raw task vectors to the same number of layers chosen at random, by depth, or by activation magnitude. Without these controls, the improvement cannot be distinguished from the general benefit of selective (rather than full-model) editing.
minor comments (2)
- [Abstract] The abstract states concrete accuracy gains and p-values but provides no details on the number of runs, exact task-vector construction procedure, or baseline controls, which limits immediate verification.
- Notation for the specificity score and its computation from SAE activations should be defined explicitly with an equation or pseudocode to allow reproduction.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the need for controls to isolate the contribution of the SAE specificity score. We address the major comment below.
read point-by-point responses
-
Referee: [Results on Minerva Math benchmark (as described in abstract and experimental evaluation)] The central claim attributes performance gains to the SAE specificity score for layer selection, yet the manuscript reports results only for the SAE-chosen layers and does not include ablations that apply the identical raw task vectors to the same number of layers chosen at random, by depth, or by activation magnitude. Without these controls, the improvement cannot be distinguished from the general benefit of selective (rather than full-model) editing.
Authors: We agree that the manuscript currently lacks these ablations, which are required to establish that gains arise specifically from the SAE-derived layer selection rather than from selective editing in general. In the revised manuscript we will add the requested controls using the identical raw task vectors: random selection of the same number of layers, depth-based selection (e.g., earliest or latest layers), and selection by activation magnitude. Results will be reported on the Minerva Math benchmark with the same statistical tests to allow direct comparison. revision: yes
Circularity Check
No significant circularity
full rationale
The manuscript reports an empirical pipeline in which an SAE-derived layer specificity score is used to select injection sites for raw task vectors, with performance gains measured on held-out Minerva Math benchmarks (e.g., Number Theory 29.6% → 39.4%). No equations, fitted parameters, or self-citations are shown to define the target metric by construction; the central result is an external benchmark comparison rather than a quantity that reduces to its own inputs. The derivation chain therefore remains self-contained against external measurements.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
LoRA: Low-rank adaptation of large language models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shengyu Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. In International Conference on Learning Representations (ICLR), 2022
2022
-
[2]
Editing models with task arithmetic
Gabriel Ilharco, Marco Tulio Ribeiro, Mitchell Wortsman, Suchin Gururangan, Ludwig Schmidt, Hannaneh Hajishirzi, and Ali Farhadi. Editing models with task arithmetic. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[3]
Towards monosemanticity: Decomposing language models with dictionary learning.Transformer Circuits Thread, 2023
Trenton Bricken, Adly Templeton, Joshua Batson, Brian Chen, Adam Jermyn, Tom Conerly, Nick Turner, Cem Anil, Carson Denison, Amanda Askell, et al. Towards monosemanticity: Decomposing language models with dictionary learning.Transformer Circuits Thread, 2023
2023
-
[4]
Sparse autoencoders find highly interpretable directions in language models.International Conference on Learning Representations (ICLR), 2024
Hoagy Cunningham, Aidan Ewart, Logan Riggs, Robert Huben, and Lee Sharkey. Sparse autoencoders find highly interpretable directions in language models.International Conference on Learning Representations (ICLR), 2024
2024
-
[5]
Gemma Scope: Open Sparse Autoencoders Everywhere All At Once on Gemma 2
Tom Lieberum, Senthooran Rajamanoharan, Arthur Conmy, Lewis Smith, Nicolas Sonnerat, Vikrant Varma, János Kramár, Amos Drori, and Neel Nanda. Gemma scope: Open sparse autoencoders everywhere all at once on gemma 2.arXiv preprint arXiv:2408.05147, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Gemma scope 2: Sparse autoencoders and transcoders for gemma 3
Google DeepMind. Gemma scope 2: Sparse autoencoders and transcoders for gemma 3. Technical report, 2025.https://deepmind.google/models/gemma/gemma-scope/
2025
-
[7]
Gemma Team. Gemma 3 technical report.arXiv preprint arXiv:2503.19786, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Open Problems in Mechanistic Interpretability
Lee Sharkey, Bilal Chughtai, Dan Braun, Beren Millidge, et al. Open problems in mechanistic interpretability.Transactions on Machine Learning Research, 2025. arXiv:2501.16496
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Are sparse autoencoders useful? a case study in sparse probing
Subhash Kantamneni, Joshua Engels, Senthooran Rajamanoharan, Max Tegmark, and Neel Nanda. Are sparse autoencoders useful? a case study in sparse probing. InProceedings of the 42nd International Conference on Machine Learning (ICML), volume 267, pages 29018–29049. PMLR, 2025
2025
-
[10]
Thomas Heap, Tim Lawson, Lucy Farnik, and Laurence Aitchison. Sparse autoencoders can interpret randomly initialized transformers.arXiv preprint arXiv:2501.17727, 2025
-
[11]
Where to edit? complementary protein property control from weight and activation spaces
Armaity Katki, Nathan Choi, Son Sophak Otra, George Flint, and Kevin Zhu. Where to edit? complementary protein property control from weight and activation spaces. InNeurIPS 2025 Workshop on Biosecurity Safeguards for Generative AI (BioSafe GenAI), 2025. URL https://openreview.net/forum?id=KiZxvtn3JE
2025
-
[12]
Measuring mathematical problem solving with the MATH dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the MATH dataset. NeurIPS Datasets and Benchmarks, 2021
2021
-
[13]
TIES-merging: Resolving interference when merging models
Prateek Yadav, Derek Tam, Leshem Choshen, Colin Raffel, and Mohit Bansal. TIES-merging: Resolving interference when merging models. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[14]
Le Yu, Bowen Yu, Haiyang Yu, Fei Huang, and Yongbin Li. Language models are super mario: Absorbing abilities from homologous models as a free lunch.arXiv preprint arXiv:2311.03099, 2024
-
[15]
Localize-and-stitch: Efficient model merging via sparse task arithmetic
Yifei He, Yuzheng Hu, Yong Lin, Tong Zhang, and Han Zhao. Localize-and-stitch: Efficient model merging via sparse task arithmetic. InTransactions on Machine Learning Research (TMLR), 2025. arXiv:2408.13656
-
[16]
Subspace-boosted model merging.arXiv preprint arXiv:2506.16506, 2025
Ronald Skorobogat, Karsten Roth, and Mariana-Iuliana Georgescu. Subspace-boosted model merging.arXiv preprint arXiv:2506.16506, 2025
-
[17]
Locating and editing factual associations in GPT.Advances in Neural Information Processing Systems (NeurIPS), 2022
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. Locating and editing factual associations in GPT.Advances in Neural Information Processing Systems (NeurIPS), 2022
2022
-
[18]
Mass- editing memory in a transformer
Kevin Meng, Arnab Sen Sharma, Alex Andonian, Yonatan Belinkov, and David Bau. Mass- editing memory in a transformer. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[19]
Task arithmetic in the tangent space: Improved editing of pre-trained models
Guillermo Ortiz-Jiménez, Alessandro Favero, and Pascal Frossard. Task arithmetic in the tangent space: Improved editing of pre-trained models. InAdvances in Neural Information Processing Systems (NeurIPS), 2023. 12
2023
-
[20]
Zhengfu He, Wentao Shu, Xuyang Ge, Lingjie Chen, Junxuan Wang, Yunhua Zhou, Frances Liu, Qipeng Guo, Xuanjing Huang, Zuxuan Wu, Yu-Gang Jiang, and Xipeng Qiu. Llama scope: Extracting millions of features from Llama-3.1-8B with sparse autoencoders.arXiv preprint arXiv:2410.20526, 2024
-
[21]
Into the Rabbit Hull: From Task-Relevant Concepts in DINO to Minkowski Geometry
Thomas Fel, Binxu Wang, et al. Into the rabbit hull: From task-relevant concepts in DINO to minkowski geometry. InInternational Conference on Learning Representations (ICLR), 2026. arXiv:2510.08638
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[22]
Ekdeep Singh Lubana et al. Priors in time: Missing inductive biases for language model interpretability.arXiv preprint arXiv:2511.01836, 2025. ICLR 2026 poster
-
[23]
Joint localization and activation editing for low- resource fine-tuning
Wen Lai, Alexander Fraser, and Ivan Titov. Joint localization and activation editing for low- resource fine-tuning. InProceedings of the 42nd International Conference on Machine Learning (ICML), volume 267, pages 32206–32227. PMLR, 2025
2025
-
[24]
A framework for few-shot language model evaluation.Zenodo, 2024
Leo Gao, Jonathan Tow, Baber Abbasi, Stella Biderman, Sid Black, Anthony DiPofi, Charles Foster, Laurence Golding, Jeffrey Hsu, Alain Le Noac’h, et al. A framework for few-shot language model evaluation.Zenodo, 2024
2024
-
[25]
The CMA evolution strategy: A comparing review.Towards a New Evolu- tionary Computation, pages 75–102, 2006
Nikolaus Hansen. The CMA evolution strategy: A comparing review.Towards a New Evolu- tionary Computation, pages 75–102, 2006
2006
-
[26]
Takuya Akiba, Makoto Shing, Yujin Tang, Qi Sun, and David Ha. Evolutionary optimization of model merging recipes.arXiv preprint arXiv:2403.13187, 2024. 13 A Reproduction Commands # Step 1: LoRA fine-tuning (produces task vector v2) python experiments/nt_train_lora_v2.py \ --gpu 0 --name lora_v2 --epochs 5 --lora_r 16 # Step 2: Compute task vector and appl...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.