Multi-Adapter Representation Interventions via Energy Calibration
Pith reviewed 2026-06-29 11:56 UTC · model grok-4.3
The pith
MARI replaces uniform representation interventions with per-sample adaptive corrections from competing adapters and energy gating to raise alignment scores without degrading general capabilities.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
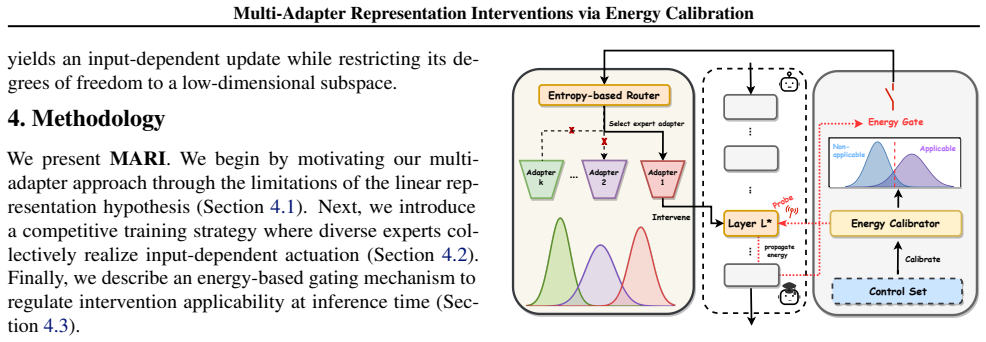
MARI introduces a competitive multi-adapter mechanism in which specialized experts capture non-linear correction patterns and adaptively determine the appropriate intervention direction and strength for different samples, combined with an energy-based gating module that leverages internal propagation dynamics to distinguish inputs that are applicable for intervention, thereby achieving state-of-the-art alignment performance across diverse model families and parameter scales while maintaining and even improving general capabilities.
What carries the argument
competitive multi-adapter mechanism guided by an energy-based gating module on internal propagation dynamics
If this is right
- MARI improves performance on TruthfulQA, BBQ, and safety benchmarks relative to prior representation-intervention methods.
- MARI maintains or improves accuracy on MMLU and ARC across tested models.
- The method scales to different model families and parameter counts without weight modification.
- Sample-adaptive intervention avoids the capability degradation observed with fixed uniform corrections.
Where Pith is reading between the lines
- The energy-gating logic may transfer to other representation-editing techniques that currently rely on fixed vectors.
- Per-sample adaptation could reduce unintended side effects when alignment is applied in production settings.
- The same competitive-adapter structure might be tested on tasks outside safety, such as style or factuality control.
Load-bearing premise
Internal propagation dynamics reliably indicate which inputs need intervention and the multi-adapter system can pick the correct direction and strength for each without harming normal performance.
What would settle it
Running MARI and a uniform-intervention baseline on the same models and observing lower TruthfulQA scores or reduced MMLU accuracy under MARI would falsify the claimed advantage.
Figures



read the original abstract
Representation intervention has emerged as a promising paradigm for aligning large language models toward desired behaviors without modifying model weights. Existing methods typically apply a fixed intervention uniformly across all inputs. However, we find that the appropriate intervention direction and strength vary substantially across samples, and such indiscriminate intervention leads to degradation of general capabilities on benign inputs. To address these challenges, we propose Multi-Adapter Representation Interventions via Energy Calibration (MARI). Specifically, we introduce a competitive multi-adapter mechanism in which specialized experts capture non-linear correction patterns and adaptively determine the appropriate intervention direction and strength for different samples. Furthermore, we design an energy-based gating module that leverages internal propagation dynamics to distinguish inputs that are applicable for intervention. Extensive experiments across diverse model families and parameter scales demonstrate that MARI achieves state-of-the-art alignment performance. Our method significantly improves performance on TruthfulQA, BBQ, and safety benchmarks, while maintaining and even improving general capabilities on tasks such as MMLU and ARC. Our code is available at https://github.com/V1centNevwake/MARI.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Multi-Adapter Representation Interventions via Energy Calibration (MARI) to address limitations of fixed representation interventions in LLMs. It introduces a competitive multi-adapter mechanism with specialized experts to adaptively set intervention direction and strength per sample, plus an energy-based gating module that uses internal propagation dynamics to decide when intervention is applicable. The central claim is that this yields SOTA alignment results on TruthfulQA, BBQ, and safety benchmarks across model families and scales, while maintaining or improving general capabilities on MMLU and ARC.
Significance. If the energy-based gating reliably identifies intervention needs without false positives on benign inputs and the multi-adapter mechanism correctly calibrates without net capability loss, the work would advance adaptive, input-dependent alignment techniques beyond uniform interventions. Code release supports reproducibility and is a clear strength.
major comments (2)
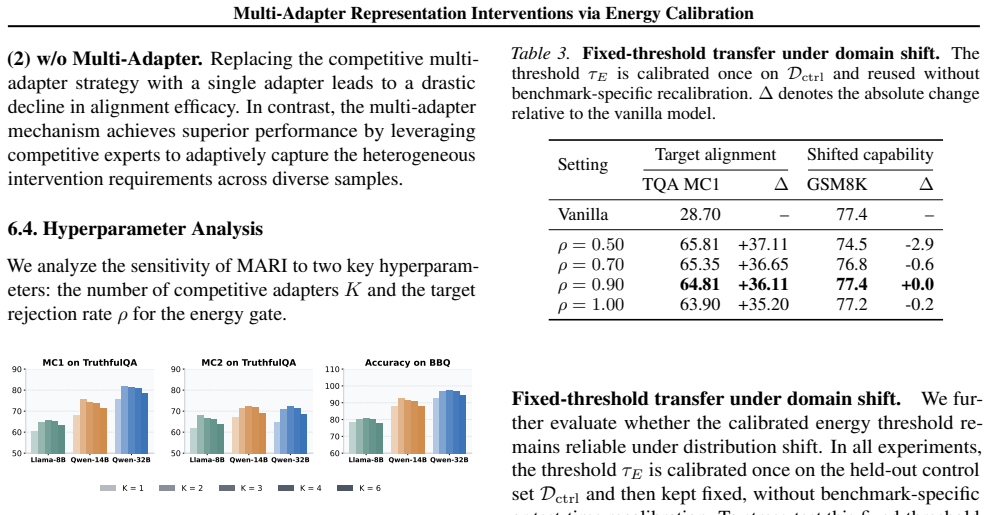
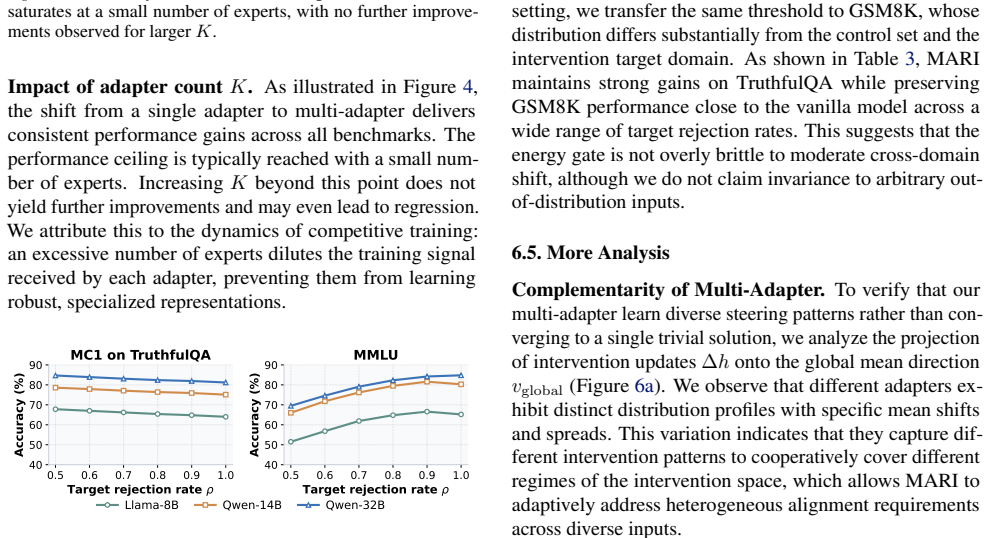
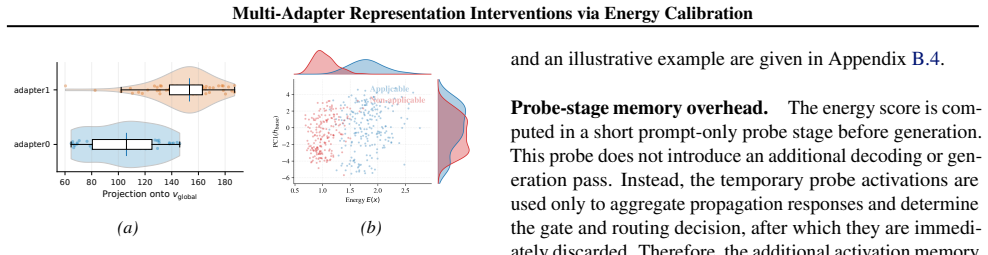
- [§3.2] §3.2 (Energy-based Gating Module): The manuscript provides no correlation analysis, ablation, or quantitative validation demonstrating that the internal propagation dynamics signal reliably distinguishes samples requiring intervention from benign inputs. This is load-bearing for the central claim, as gating errors on capability-preserving samples would be expected to produce the very degradation on MMLU/ARC that the results purport to avoid.
- [§4] §4 (Experiments) and associated tables: No ablation studies isolate the contribution of the energy-based gating module versus the competitive multi-adapter experts, nor do they report per-sample gating accuracy or false-positive rates on benign inputs. Without these, attribution of the reported SOTA performance on both alignment and capability benchmarks to the proposed components remains unsubstantiated.
minor comments (1)
- [Abstract and §3] The abstract and method sections would benefit from explicit equations defining the energy calibration and gating function, as the current prose description leaves the precise computation of the intervention signal unclear.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which identifies key areas where additional evidence would strengthen the manuscript. We address each major comment below and will incorporate the requested analyses and ablations in the revision.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Energy-based Gating Module): The manuscript provides no correlation analysis, ablation, or quantitative validation demonstrating that the internal propagation dynamics signal reliably distinguishes samples requiring intervention from benign inputs. This is load-bearing for the central claim, as gating errors on capability-preserving samples would be expected to produce the very degradation on MMLU/ARC that the results purport to avoid.
Authors: We agree that explicit quantitative validation of the energy-based gating module is necessary to support the central claim. In the revised manuscript we will add correlation analyses linking internal propagation dynamics to intervention needs, plus direct measurements of false-positive rates on benign inputs from MMLU/ARC-style data. These results will be presented alongside the existing benchmark numbers to demonstrate that gating errors do not explain the observed capability preservation. revision: yes
-
Referee: [§4] §4 (Experiments) and associated tables: No ablation studies isolate the contribution of the energy-based gating module versus the competitive multi-adapter experts, nor do they report per-sample gating accuracy or false-positive rates on benign inputs. Without these, attribution of the reported SOTA performance on both alignment and capability benchmarks to the proposed components remains unsubstantiated.
Authors: We concur that component-wise ablations and per-sample gating metrics are required for clear attribution. The revision will include new ablation tables that separately disable the energy-based gate and the competitive multi-adapter experts, together with reported per-sample gating accuracy and false-positive rates on held-out benign inputs. These experiments will quantify the marginal contribution of each element to the reported gains on TruthfulQA, BBQ, safety benchmarks, MMLU, and ARC. revision: yes
Circularity Check
No circularity; empirical method validated by experiments, no derivation chain present
full rationale
The manuscript proposes an empirical intervention method (MARI) consisting of a competitive multi-adapter mechanism and an energy-based gating module, with performance claims resting entirely on benchmark experiments across model families. No equations, derivations, or first-principles results are described that reduce any prediction or claim to fitted inputs, self-definitions, or self-citation chains. The abstract and available text contain no load-bearing mathematical steps, uniqueness theorems, or ansatzes that could trigger the enumerated circularity patterns. This is the standard case of a self-contained empirical paper whose central claims are externally falsifiable via replication on the cited benchmarks.
Axiom & Free-Parameter Ledger
invented entities (1)
-
energy-based gating module
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Ferrando, A., Suau, X., Gonz `alez, J., and Rodriguez, P
https://transformer-circuits.pub/ 2021/framework/index.html. Ferrando, A., Suau, X., Gonz `alez, J., and Rodriguez, P. Dynamically scaled activation steering.arXiv preprint arXiv:2512.03661, 2025. Grattafiori, A. et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024. Guo, Z., Xu, X., Xiang, P., Yang, S., Han, X., Wang, D., and Hu, L. Ben...
-
[2]
URL https://aclanthology.org/2022. acl-long.229/. Marks, S. and Tegmark, M. The geometry of truth: Emergent linear structure in large language model representations of true/false datasets.arXiv preprint arXiv:2310.06824, 2023. Mikolov, T., Sutskever, I., Chen, K., Corrado, G., and Dean, J. Distributed representations of words and phrases and their composi...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2022.findings-acl 2022
-
[3]
URL https://aclanthology.org/2022. findings-acl.165/. Patel, R. and Pavlick, E. Mapping language models to grounded conceptual spaces. InInternational Conference on Learning Representations (ICLR), 2022. Rimsky, N., Gabrieli, N., Schulz, J., Tong, M., Hubinger, E., and Turner, A. Steering llama 2 via contrastive activation addition. InProceedings of the 6...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.