Imitation Learning for Robot Assistance in Open Surgery: A Multi-Policy Evaluation on Suture Following
Pith reviewed 2026-06-29 11:34 UTC · model grok-4.3
The pith
Imitation learning policies achieve 50-75% success on suture following and 92% stitch completion in surgeon-robot trials.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
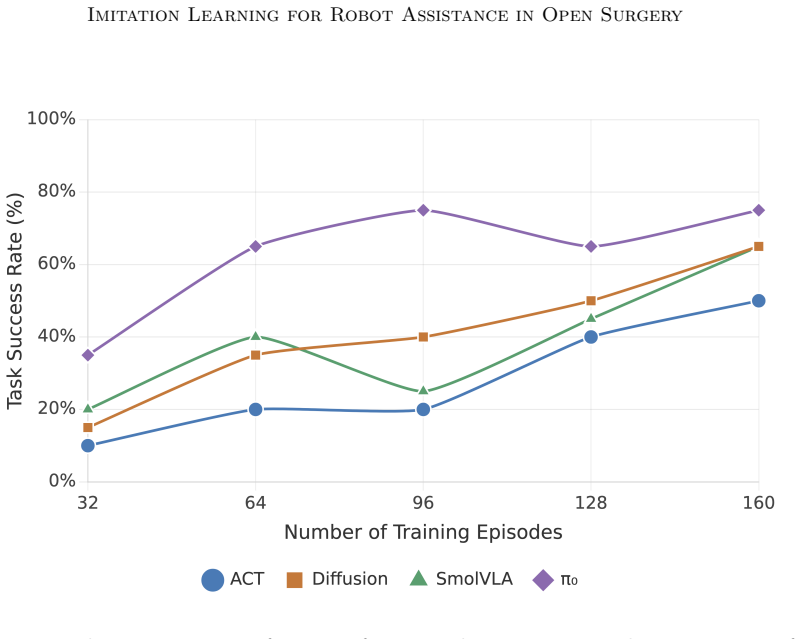
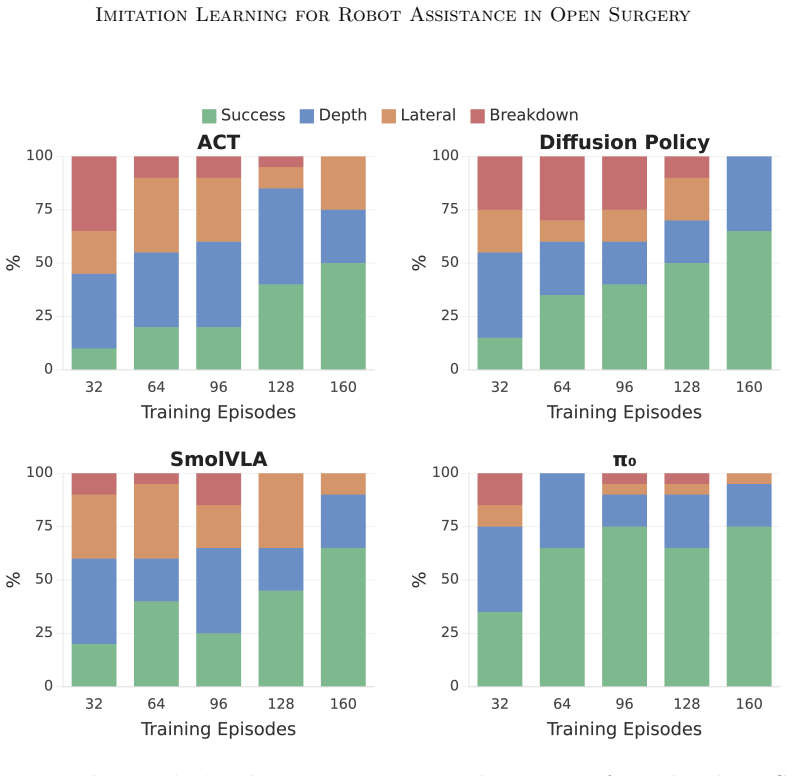
This study presents the first evaluation of general-purpose imitation learning for surgeon-robot collaborative assistance in open surgery, targeting suture following. Under ideal conditions the four policies achieve 50-75% task success, with depth error as the dominant failure mode across all architectures. Among all policies, π0 achieves the strongest results with a pretrained vision-language backbone, demonstrating superior data efficiency, greater robustness to background variation, and smoother trajectories compatible with surgical workflow. When deployed in a surgeon-robot suturing trial, π0 yields a 92% stitch completion rate.
What carries the argument
Benchmarking of four imitation learning policies (ACT, Diffusion Policy, SmolVLA, π0) trained on 160 teleoperated demonstrations (32,374 frames) and evaluated on the suture-following task across dataset size, viewpoint, and background variation.
If this is right
- Depth perception must be improved because it is the dominant failure mode across every policy tested.
- End-effector hardware changes are required for reliable clinical translation.
- Pretrained vision-language backbones deliver better data efficiency and robustness than the other three architectures.
- Smoother trajectories from the best policy align with existing surgical workflow.
Where Pith is reading between the lines
- The same data-collection approach could be applied to other repetitive assistant motions such as tissue retraction or instrument passing.
- Reducing the number of demonstrations needed would make the method practical for new procedures or hospitals.
- Combining the policy with real-time depth sensors might directly address the main failure mode observed.
Load-bearing premise
The 160 teleoperated demonstrations collected on an open-source robot arm are representative of the motions, variability, and conditions encountered in actual open surgery.
What would settle it
If real open-surgery trials produce success rates below the reported 50-75% range or stitch-completion rates well below 92%, the claim that these policies transfer to clinical collaborative assistance would not hold.
Figures


read the original abstract
This study presents the first evaluation of general-purpose imitation learning for surgeon-robot collaborative assistance in open surgery, targeting suture following: the grab-pull-release motion an assistant performs at every stitch. We collect 160 teleoperated demonstrations (32,374 frames) on an open-source robot arm, benchmark four architecturally diverse imitation learning policies (ACT, Diffusion Policy, SmolVLA, $\pi_0$) across 28 trained models evaluated in 32 configurations along three clinically motivated dimensions: dataset size, camera viewpoint, and background variation. Our results demonstrate that under ideal conditions, the four policies achieve $50$-$75\%$ task success, with depth error as the dominant failure mode across all architectures. Among all policies, $\pi_0$ achieves the strongest results with a pretrained vision-language backbone, demonstrating superior data efficiency, greater robustness to background variation, and smoother trajectories compatible with surgical workflow. When deployed in a surgeon-robot suturing trial, $\pi_0$ yields a $92\%$ stitch completion rate. These findings establish collaborative robotic assistance in open surgery as a feasible target for imitation learning and highlight depth perception and end-effector design as key priorities for clinical translation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to present the first evaluation of general-purpose imitation learning for surgeon-robot collaborative assistance in open surgery on the suture following task. It collects 160 teleoperated demonstrations (32,374 frames) on an open-source robot arm and benchmarks four architecturally diverse policies (ACT, Diffusion Policy, SmolVLA, π0) across 28 models in 32 configurations varying dataset size, camera viewpoint, and background. Under ideal conditions the policies reach 50-75% task success with depth error as the dominant failure mode; π0 with a pretrained vision-language backbone performs best in data efficiency, robustness, and trajectory smoothness. Deployment of π0 in a surgeon-robot suturing trial yields a 92% stitch completion rate, establishing collaborative robotic assistance in open surgery as a feasible target for imitation learning while identifying depth perception and end-effector design as translation priorities.
Significance. If the empirical results hold, the work provides the first systematic multi-policy benchmark of imitation learning on a clinically motivated open-surgery assistance task together with a real surgeon-robot trial. The concrete success rates, identification of depth error as the primary failure mode, and demonstration of π0’s advantages in data efficiency and background robustness constitute a useful reference point for the surgical robotics and imitation learning communities. The explicit call-out of end-effector design as a remaining barrier supplies a concrete direction for follow-on engineering.
major comments (2)
- [Abstract] Abstract: The headline claim of a 92% stitch completion rate in the surgeon-robot trial, and the broader conclusion that collaborative assistance is a feasible target for imitation learning, rests on the untested assumption that the 160 teleoperated demonstrations already encode the motion statistics, depth ranges, background statistics, and tissue-interaction variability of actual open surgery. No quantitative evidence (trajectory distribution overlap, force profiles, or OR lighting/sterility variation) is supplied to support distributional coverage between the demo set and the trial conditions.
- [Abstract] Abstract / Results: The reported 50-75% success rates and the statement that depth error is the dominant failure mode across all architectures are presented without accompanying definitions of task success, details on train/test splits, or statistical tests for the cross-configuration comparisons; these omissions make it difficult to assess whether the superiority claims for π0 are robust to selection or evaluation choices.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. Below we provide point-by-point responses to the two major comments. We agree that additional clarity is needed in the abstract and results sections and will revise the manuscript accordingly to address the concerns without overstating the scope of the current experiments.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline claim of a 92% stitch completion rate in the surgeon-robot trial, and the broader conclusion that collaborative assistance is a feasible target for imitation learning, rests on the untested assumption that the 160 teleoperated demonstrations already encode the motion statistics, depth ranges, background statistics, and tissue-interaction variability of actual open surgery. No quantitative evidence (trajectory distribution overlap, force profiles, or OR lighting/sterility variation) is supplied to support distributional coverage between the demo set and the trial conditions.
Authors: We acknowledge the validity of this observation. The 160 demonstrations were collected via teleoperation in a controlled lab setting designed to approximate suture following, and the surgeon-robot trial was performed under matching controlled conditions rather than in a live operating room. The manuscript does not include quantitative analyses such as trajectory distribution overlap, force profiles, or comparisons of OR-specific variations (lighting, sterility, tissue variability) because such data were outside the scope of the collected dataset. We will revise the abstract and add a dedicated limitations paragraph in the discussion to explicitly qualify the 92% result as applying to the controlled trial conditions, note the distributional assumptions, and identify real-OR variability as an important direction for future work. revision: yes
-
Referee: [Abstract] Abstract / Results: The reported 50-75% success rates and the statement that depth error is the dominant failure mode across all architectures are presented without accompanying definitions of task success, details on train/test splits, or statistical tests for the cross-configuration comparisons; these omissions make it difficult to assess whether the superiority claims for π0 are robust to selection or evaluation choices.
Authors: We agree that the abstract is too concise to include these details and that the results section would benefit from explicit statistical support. The full manuscript defines task success (completion of the grab-pull-release cycle without dropping the thread or exceeding force thresholds), describes the train/test splits (random 80/20 split per configuration with held-out evaluation episodes), and reports per-configuration success rates. However, to improve accessibility and rigor, we will (1) insert a one-sentence definition of task success into the abstract, (2) add a short methods subsection summarizing splits and evaluation protocol, and (3) include 95% confidence intervals or paired statistical tests for the architecture comparisons in the results. These additions will be made in the revised manuscript. revision: yes
Circularity Check
No circularity: purely empirical evaluation on newly collected data
full rationale
The paper reports collection of 160 new teleoperated demonstrations (32,374 frames) on an open-source arm, training of four imitation-learning policies, and direct measurement of task success (50-75% under ideal conditions, 92% in surgeon-robot trial). No equations, first-principles derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. All reported outcomes are experimental measurements on held-out or trial data; the central claims do not reduce to prior fitted quantities or author-defined inputs by construction. This is the expected non-finding for an empirical robotics evaluation paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Imitation learning policies trained on teleoperated demonstrations can generalize to perform suture following in varied conditions.
Reference graph
Works this paper leans on
-
[1]
A dataset and benchmarks for segmentation and recognition of gestures in robotic surgery.IEEE Trans- actions on Biomedical Engineering, 64(9):2025–2041,
Narges Ahmidi, Lingling Tao, Shahin Sefati, Yixin Gao, Colin Lea, Benjamin Bejar Haro, Luca Zappella, Sanjeev Khudanpur, Rene Vidal, and Gregory D Hager. A dataset and benchmarks for segmentation and recognition of gestures in robotic surgery.IEEE Trans- actions on Biomedical Engineering, 64(9):2025–2041,
2025
-
[2]
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al.π 0: A vision-language- action flow model for general robot control.arXiv preprint arXiv:2410.24164,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
doi: 10.1136/bmjsit-2024-000338. Ji Woong Kim, Tony Z Zhao, Samuel Schmidgall, Anton Deguet, Marin Kobilarov, Chelsea Finn, and Axel Krieger. Surgical robot transformer (SRT): Imitation learning for surgical tasks.arXiv preprint arXiv:2407.12998,
-
[4]
RoboNurse-VLA: Robotic scrub nurse system based on vision-language-action model
Shunlei Li, Jin Wang, Rui Dai, Wanyu Ma, Wing Yin Ng, Yingbai Hu, and Zheng Li. RoboNurse-VLA: Robotic scrub nurse system based on vision-language-action model. arXiv preprint arXiv:2409.19590,
-
[5]
Minimally invasive surgery in the united states, 2022: Understanding its value using new datasets.Journal of Surgical Research, 281:33–36,
Aviva S Mattingly, Michelle M Chen, Vasu Divi, F Christopher Holsinger, and Anirudh Saraswathula. Minimally invasive surgery in the united states, 2022: Understanding its value using new datasets.Journal of Surgical Research, 281:33–36,
2022
-
[6]
Supervised Mixture-of-Experts for Surgical Grasping and Retraction
Lorenzo Mazza, Ariel Rodriguez, Rayan Younis, Martin Lelis, Ortrun Hellig, Chenpan Li, Sebastian Bodenstedt, Martin Wagner, and Stefanie Speidel. MoE-ACT: Improving surgical imitation learning policies through supervised mixture-of-experts.arXiv preprint arXiv:2601.21971,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Global surgery 2030: Evidence and solutions for achieving health, welfare, and economic development.The Lancet, 386(9993):569–624,
John G Meara, Andrew JM Leather, Lars Hagander, Blake C Alkire, Winnie Yip, et al. Global surgery 2030: Evidence and solutions for achieving health, welfare, and economic development.The Lancet, 386(9993):569–624,
2030
-
[8]
SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics
16 Imitation Learning for Robot Assistance in Open Surgery Mustafa Shukor, Dana Aubakirova, Francesco Capuano, Pepijn Kooijmans, Steven Palma, Adil Zouitine, Michel Aractingi, Caroline Pascal, Martino Russi, Andres Marafioti, Simon Alibert, Matthieu Cord, Thomas Wolf, and Remi Cadene. SmolVLA: A vision-language- action model for affordable and efficient r...
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Qinxi Yu, Masoud Moghani, Karthik Dharmarajan, Vincent Schorp, William Chung-Ho Panitch, Jingzhou Liu, Kush Hari, Huang Huang, Mayank Mittal, Ken Goldberg, and Animesh Garg. ORBIT-Surgical: An open-simulation framework for learning surgical augmented dexterity.arXiv preprint arXiv:2404.16027,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.