Self-Improving Language Models with Bidirectional Evolutionary Search
Pith reviewed 2026-06-29 12:54 UTC · model grok-4.3
The pith
Bidirectional evolutionary search lets language models generate better candidates by recombining partial trajectories and decomposing tasks into checkable subgoals.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
BES couples forward candidate evolution with backward goal decomposition. In the forward direction, standard expansion is augmented by evolution operators that recombine partial trajectories to generate candidates difficult to obtain from a single model rollout. In the backward direction, the original task is recursively decomposed into checkable subgoals that supply dense intermediate feedback to guide the forward search. This setup is motivated by the claim that expansion-only search remains confined to a narrow entropy shell while evolutionary operators can escape it, and that backward search can exponentially reduce the number of required samples to find a correct answer.
What carries the argument
Bidirectional Evolutionary Search (BES) that augments forward expansion with recombination operators on partial trajectories and pairs it with recursive backward decomposition into checkable subgoals for dense verification signals.
If this is right
- BES produces consistent gains on challenging post-training tasks where mainstream post-training algorithms fail to improve.
- On three open problem solving benchmarks at inference time, BES outperforms existing open-source frameworks in both average and best-case performance.
- Evolutionary operators generate candidates that lie outside regions with substantial model probability mass.
- Backward search exponentially reduces the number of samples required to reach a correct answer.
Where Pith is reading between the lines
- The same recombination and decomposition steps could be tested on agentic tasks that involve external tools or multi-step planning beyond the paper's language-model setting.
- If subgoal verification is noisy or incomplete, the density advantage of backward search would shrink and overall sample efficiency would drop.
- The entropy-shell argument suggests that similar recombination operators might help in other generative domains where autoregressive sampling is the default.
Load-bearing premise
The proposed evolution operators can reliably recombine partial trajectories into useful new candidates and the model can produce checkable subgoals whose verification signals meaningfully guide the forward search.
What would settle it
An experiment on the post-training tasks or the three benchmarks in which BES produces no gains over standard methods, or in which recombined candidates remain inside the same probability-mass region as autoregressive rollouts.
Figures


read the original abstract
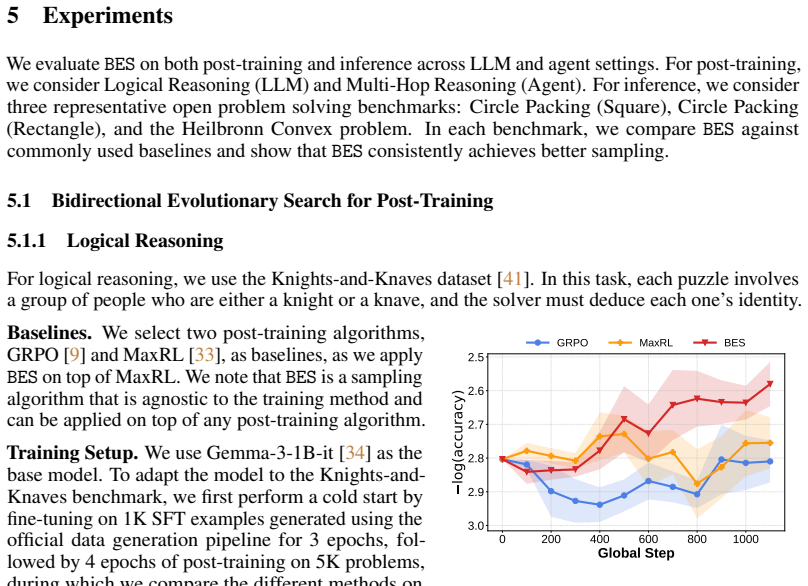
Search has been proposed as an effective method for self-improving language models and agentic systems, both for post-training sample generation and for inference. However, widely used methods such as best-of-N sampling and tree search face two fundamental limitations: they are guided by sparse verification signals, and they construct candidates primarily through autoregressive expansion, restricting exploration to regions with substantial model probability mass. To address these, we propose Bidirectional Evolutionary Search (BES), a search framework that couples forward candidate evolution with backward goal decomposition. In the forward search, BES augments standard expansion with evolution operators that recombine partial trajectories to generate candidates that are difficult to obtain from a single model rollout. In the backward search, BES recursively decomposes the original task into checkable subgoals, producing dense intermediate feedback that guides forward search. We provide theoretical motivation showing that candidates generated by expansion-only search are confined to a narrow entropy shell while evolutionary operators can escape it, and that backward search can exponentially reduce the number of required samples to find a correct answer. Experiments show that on challenging post-training tasks where mainstream post-training algorithms fail to improve, BES enables consistent gains, and on three open problem solving benchmarks at inference time, BES outperforms existing open-source frameworks in both average and best-case performance. Code and trained models are available at https://github.com/Embodied-Minds-Lab/BES.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Bidirectional Evolutionary Search (BES), a search framework for self-improving language models that couples forward candidate evolution (using recombination operators on partial trajectories) with backward goal decomposition (producing checkable subgoals for dense feedback). It motivates the approach theoretically by arguing that expansion-only search is confined to a narrow entropy shell while evolutionary operators allow escape and that backward decomposition can exponentially reduce required samples. Experiments are reported to show consistent gains on challenging post-training tasks where mainstream algorithms fail to improve, and superior average and best-case performance versus existing open-source frameworks on three open problem-solving benchmarks at inference time. Code and trained models are released.
Significance. If the empirical claims hold under matched compute and verification conditions, the work could meaningfully advance search-based self-improvement methods by addressing sparse signals and limited exploration in current approaches. The combination of theoretical motivation for entropy-shell escape and sample-complexity reduction, together with the public release of code and models, strengthens potential impact for both post-training and inference-time agentic systems.
minor comments (2)
- [Abstract] The abstract states high-level experimental outcomes but does not report effect sizes, exact baselines, or control conditions; adding one or two quantitative sentences would improve clarity without altering the central claims.
- The description of the evolution operators and subgoal verification would benefit from an explicit statement of how partial-trajectory recombination is implemented and how verification signals are aggregated in the forward search.
Simulated Author's Rebuttal
We thank the referee for the constructive summary and for recommending minor revision. The assessment correctly captures the core contributions of Bidirectional Evolutionary Search, including the coupling of forward evolutionary recombination with backward subgoal decomposition, the theoretical arguments on entropy-shell escape and sample-complexity reduction, and the empirical results on post-training and inference-time tasks. We are pleased that the public release of code and models is viewed as strengthening potential impact.
Circularity Check
No significant circularity in derivation chain
full rationale
The provided abstract and context contain no equations, fitted parameters, or self-citations that reduce any claimed prediction or theoretical result to its inputs by construction. Theoretical motivations (entropy shell confinement, exponential sample reduction) are presented as independent derivations rather than re-expressions of prior fitted quantities or author-specific uniqueness theorems. Empirical claims rest on proposed operators and benchmarks without evidence of self-definitional loops or renaming of known results. This is the expected self-contained case.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Language models can generate partial trajectories that are recombineable into useful new candidates and can produce checkable subgoals.
Reference graph
Works this paper leans on
-
[1]
GEPA: Reflective prompt evolution can outperform reinforcement learning
Lakshya A Agrawal, Shangyin Tan, Dilara Soylu, Noah Ziems, Rishi Khare, Krista Opsahl-Ong, Arnav Singhvi, Herumb Shandilya, Michael J Ryan, Meng Jiang, Christopher Potts, Koushik Sen, Alex Dimakis, Ion Stoica, Dan Klein, Matei Zaharia, and Omar Khattab. GEPA: Reflective prompt evolution can outperform reinforcement learning. InThe Fourteenth International...
2026
-
[2]
W. Banzhaf, J.R. Koza, C. Ryan, L. Spector, and C. Jacob. Genetic programming.IEEE Intelligent Systems and their Applications, 15(3):74–84, 2000. doi: 10.1109/5254.846288. 10
-
[3]
Maciej Besta, Nils Blach, Ales Kubicek, Robert Gerstenberger, Michal Podstawski, Lukas Gianinazzi, Joanna Gajda, Tomasz Lehmann, Hubert Niewiadomski, Piotr Nyczyk, and Torsten Hoefler. Graph of thoughts: Solving elaborate problems with large language models.Pro- ceedings of the AAAI Conference on Artificial Intelligence, 38(16):17682–17690, March 2024. IS...
-
[4]
Large Language Monkeys: Scaling Inference Compute with Repeated Sampling
Bradley Brown, Jordan Juravsky, Ryan Ehrlich, Ronald Clark, Quoc V . Le, Christopher Ré, and Azalia Mirhoseini. Large language monkeys: Scaling inference compute with repeated sampling, 2024. URLhttps://arxiv.org/abs/2407.21787. 2 10
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Oxford University Press, 1999
Ronald Aylmer Fisher.The genetical theory of natural selection: a complete variorum edition. Oxford University Press, 1999. 2
1999
-
[6]
FrontierMath: A Benchmark for Evaluating Advanced Mathematical Reasoning in AI
Elliot Glazer, Ege Erdil, Tamay Besiroglu, Diego Chicharro, Evan Chen, Alex Gunning, Caroline Falkman Olsson, Jean-Stanislas Denain, Anson Ho, Emily de Oliveira Santos, Olli Järviniemi, Matthew Barnett, Robert Sandler, Matej Vrzala, Jaime Sevilla, Qiuyu Ren, Elizabeth Pratt, Lionel Levine, Grant Barkley, Natalie Stewart, Bogdan Grechuk, Tetiana Grechuk, S...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ah- mad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sravankumar, Artem Korenev, Arthur Hinsvark, Arun Rao, Aston Zhang, Aurelien Rodriguez, Austen Gregerson, Ava...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
rstar-math: Small LLMs can master math reasoning with self-evolved deep thinking
Xinyu Guan, Li Lyna Zhang, Yifei Liu, Ning Shang, Youran Sun, Yi Zhu, Fan Yang, and Mao Yang. rstar-math: Small LLMs can master math reasoning with self-evolved deep thinking. InForty-second International Conference on Machine Learning, 2025. URL https://openreview.net/forum?id=5zwF1GizFa. 1, 10
2025
-
[9]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, Bing Xue, Bingxuan Wang, Bochao Wu, Bei Feng, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chong Ruan, Damai Dai, Deli Chen, Dongjie Ji, ...
-
[10]
Reasoning with language model is planning with world model
Shibo Hao, Yi Gu, Haodi Ma, Joshua Hong, Zhen Wang, Daisy Wang, and Zhiting Hu. Reasoning with language model is planning with world model. In Houda Bouamor, Juan Pino, and Kalika Bali, editors,Proceedings of the 2023 Conference on Empirical Meth- ods in Natural Language Processing, pages 8154–8173, Singapore, December 2023. As- sociation for Computationa...
-
[11]
Peter E. Hart, Nils J. Nilsson, and Bertram Raphael. A formal basis for the heuristic determi- nation of minimum cost paths.IEEE Transactions on Systems Science and Cybernetics, 4(2): 100–107, 1968. doi: 10.1109/TSSC.1968.300136. 10
-
[12]
John H. Holland.Adaptation in Natural and Artificial Systems: An Introductory Analysis with Applications to Biology, Control, and Artificial Intelligence. The MIT Press, 04 1992. ISBN 9780262275552. doi: 10.7551/mitpress/1090.001.0001. URL https://doi.org/10.7551/ mitpress/1090.001.0001. 10
-
[13]
TreeRL: LLM reinforcement learning with on-policy tree search
Zhenyu Hou, Ziniu Hu, Yujiang Li, Rui Lu, Jie Tang, and Yuxiao Dong. TreeRL: LLM reinforcement learning with on-policy tree search. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 12355– 12369, Vien...
-
[14]
Ash, and Akshay Krishnamurthy
Audrey Huang, Adam Block, Dylan J Foster, Dhruv Rohatgi, Cyril Zhang, Max Simchowitz, Jordan T. Ash, and Akshay Krishnamurthy. Self-improvement in language models: The sharp- ening mechanism. InThe Thirteenth International Conference on Learning Representations,
-
[15]
URLhttps://openreview.net/forum?id=WJaUkwci9o. 9
-
[16]
Thomas Hubert, Rishi Mehta, Laurent Sartran, Miklós Z. Horváth, Goran Žuži´c, Eric Wieser, Aja Huang, Julian Schrittwieser, Yannick Schroecker, Hussain Masoom, Ottavia Bertolli, Tom Zahavy, Amol Mandhane, Jessica Yung, Iuliya Beloshapka, Borja Ibarz, Vivek Veeriah, Lei Yu, Oliver Nash, Paul Lezeau, Salvatore Mercuri, Calle Sönne, Bhavik Mehta, Alex Davies...
-
[17]
Tree search for LLM agent reinforcement learning
Yuxiang Ji, Ziyu Ma, Yong Wang, Guanhua Chen, Xiangxiang Chu, and Liaoni Wu. Tree search for LLM agent reinforcement learning. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum?id=ZpQwAFhU13. 2, 3, 8, 10
2026
-
[18]
FaithScore: Fine-grained evaluations of hallucina- tions in large vision-language models
Marek Kadlˇcík and Michal Štefánik. Self-training language models for arithmetic reasoning. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors,Findings of the Association for Computational Linguistics: EMNLP 2024, pages 12378–12386, Miami, Florida, USA, Novem- ber 2024. Association for Computational Linguistics. doi: 10.18653/v1/2024.findings-emnlp
-
[19]
URLhttps://aclanthology.org/2024.findings-emnlp.721/. 9
2024
-
[20]
Bandit based monte-carlo planning
Levente Kocsis and Csaba Szepesvari. Bandit based monte-carlo planning. InEuropean Confer- ence on Machine Learning, 2006. URL https://api.semanticscholar.org/CorpusID: 15184765. 1, 3
2006
-
[21]
ShinkaEvolve: Towards Open-Ended And Sample-Efficient Program Evolution
Robert Tjarko Lange, Yuki Imajuku, and Edoardo Cetin. Shinkaevolve: Towards open-ended and sample-efficient program evolution, 2025. URL https://arxiv.org/abs/2509.19349. 1, 2, 8, 10
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Lawler and D
Eugene L. Lawler and D. E. Wood. Branch-and-bound methods: A survey.Oper. Res., 14: 699–719, 1966. URLhttps://api.semanticscholar.org/CorpusID:36099120. 10
1966
-
[23]
Li et al., ”Competition-Level Code Gen- eration with AlphaCode,”Science, vol
Yujia Li, David Choi, Junyoung Chung, Nate Kushman, Julian Schrittwieser, Rémi Leblond, Tom Eccles, James Keeling, Felix Gimeno, Agustin Dal Lago, Thomas Hubert, Peter Choy, Cyprien de Masson d’Autume, Igor Babuschkin, Xinyun Chen, Po-Sen Huang, Johannes Welbl, Sven Gowal, Alexey Cherepanov, James Molloy, Daniel J. Mankowitz, Esme Sutherland Robson, Pushm...
-
[24]
Dimakis, Matei Zaharia, and Ion Stoica
Shu Liu, Mert Cemri, Shubham Agarwal, Alexander Krentsel, Ashwin Naren, Qiuyang Mang, Zhifei Li, Akshat Gupta, Monishwaran Maheswaran, Audrey Cheng, Melissa Pan, Ethan Boneh, Kannan Ramchandran, Koushik Sen, Alexandros G. Dimakis, Matei Zaharia, and Ion Stoica. Skydiscover: A flexible framework for ai-driven scientific and algorithmic discovery, 2026. URL...
2026
-
[25]
Self-refine: Iterative refinement with self-feedback
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, Shashank Gupta, Bodhisattwa Prasad Majumder, Katherine Hermann, Sean Welleck, Amir Yazdanbakhsh, and Peter Clark. Self-refine: Iterative refinement with self-feedback. InThirty-seventh Conference on Neural Informati...
2023
-
[26]
Wider or deeper? scaling LLM inference-time compute with adaptive branching tree search
Kou Misaki, Yuichi Inoue, Yuki Imajuku, So Kuroki, Taishi Nakamura, and Takuya Akiba. Wider or deeper? scaling LLM inference-time compute with adaptive branching tree search. In ICLR 2025 Workshop on Foundation Models in the Wild, 2025. URLhttps://openreview. net/forum?id=3HF6yogDEm. 10
2025
-
[27]
Some genetic aspects of sex.The American Naturalist, 66(703): 118–138, 1932
Hermann Joseph Muller. Some genetic aspects of sex.The American Naturalist, 66(703): 118–138, 1932. 2
1932
-
[28]
Alexander Novikov, Ngân V˜u, Marvin Eisenberger, Emilien Dupont, Po-Sen Huang, Adam Zsolt Wagner, Sergey Shirobokov, Borislav Kozlovskii, Francisco J. R. Ruiz, Abbas Mehrabian, M. Pawan Kumar, Abigail See, Swarat Chaudhuri, George Holland, Alex Davies, Sebastian Nowozin, Pushmeet Kohli, and Matej Balog. Alphaevolve: A coding agent for scientific and algor...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Self-improving language models for evolutionary program synthesis: A case study on arc-agi, 2026
Julien Pourcel, Cédric Colas, and Pierre-Yves Oudeyer. Self-improving language models for evolutionary program synthesis: A case study on arc-agi, 2026. URL https://arxiv.org/ abs/2507.14172. 10 14
-
[30]
Mutual reasoning makes smaller LLMs stronger problem-solver
Zhenting Qi, Mingyuan MA, Jiahang Xu, Li Lyna Zhang, Fan Yang, and Mao Yang. Mutual reasoning makes smaller LLMs stronger problem-solver. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum? id=6aHUmotXaw. 1
2025
-
[31]
Mathematical discoveries from program search with large language models
Bernardino Romera-Paredes, Mohammadamin Barekatain, Alexander Novikov, Matej Balog, M Pawan Kumar, Emilien Dupont, Francisco JR Ruiz, Jordan S Ellenberg, Pengming Wang, Omar Fawzi, et al. Mathematical discoveries from program search with large language models. Nature, 625(7995):468–475, 2024. 10
2024
-
[32]
Openevolve: an open-source evolutionary coding agent, 2025
Asankhaya Sharma. Openevolve: an open-source evolutionary coding agent, 2025. URL https://github.com/algorithmicsuperintelligence/openevolve. 2, 8
2025
-
[33]
Reflexion: language agents with verbal reinforcement learning
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik R Narasimhan, and Shunyu Yao. Reflexion: language agents with verbal reinforcement learning. InThirty-seventh Conference on Neural Information Processing Systems, 2023. URL https://openreview.net/forum? id=vAElhFcKW6. 9
2023
-
[34]
Rainer Storn and Kenneth Price. Differential evolution – a simple and efficient heuristic for global optimization over continuous spaces.J. of Global Optimization, 11(4):341–359, December 1997. ISSN 0925-5001. doi: 10.1023/A:1008202821328. URL https://doi.org/ 10.1023/A:1008202821328. 10
-
[35]
Maximum likelihood reinforcement learning, 2026
Fahim Tajwar, Guanning Zeng, Yueer Zhou, Yuda Song, Daman Arora, Yiding Jiang, Jeff Schneider, Ruslan Salakhutdinov, Haiwen Feng, and Andrea Zanette. Maximum likelihood reinforcement learning, 2026. URLhttps://arxiv.org/abs/2602.02710. 2, 7
-
[36]
Gemma Team, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ramé, Morgane Rivière, Louis Rouillard, Thomas Mesnard, Geoffrey Cideron, Jean bastien Grill, Sabela Ramos, Edouard Yvinec, Michelle Casbon, Etienne Pot, Ivo Penchev, Gaël Liu, Francesco Visin, Kathleen Kenealy, Lucas Bey...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. MuSiQue: Multihop questions via single-hop question composition.Transactions of the Association for Computational Linguistics, 10:539–554, 2022. doi: 10.1162/tacl_a_00475. URL https: //aclanthology.org/2022.tacl-1.31/. 7
-
[38]
V oyager: An open-ended embodied agent with large language models.Transactions on Machine Learning Research, 2024
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. V oyager: An open-ended embodied agent with large language models.Transactions on Machine Learning Research, 2024. ISSN 2835-8856. URL https: //openreview.net/forum?id=ehfRiF0R3a. 9
2024
-
[39]
Efficient evolutionary search over chemical space with large language models
Haorui Wang, Marta Skreta, Cher Tian Ser, Wenhao Gao, Lingkai Kong, Felix Strieth-Kalthoff, Chenru Duan, Yuchen Zhuang, Yue Yu, Yanqiao Zhu, Yuanqi Du, Alan Aspuru-Guzik, Kirill Neklyudov, and Chao Zhang. Efficient evolutionary search over chemical space with large language models. InThe Thirteenth International Conference on Learning Representations,
-
[40]
URLhttps://openreview.net/forum?id=awWiNvQwf3. 10
-
[41]
Thetaevolve: Test-time learning on open problems,
Yiping Wang, Shao-Rong Su, Zhiyuan Zeng, Eva Xu, Liliang Ren, Xinyu Yang, Zeyi Huang, Xuehai He, Luyao Ma, Baolin Peng, Hao Cheng, Pengcheng He, Weizhu Chen, Shuohang Wang, Simon Shaolei Du, and Yelong Shen. Thetaevolve: Test-time learning on open problems,
-
[42]
URLhttps://arxiv.org/abs/2511.23473. 10
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
Chi, Quoc V Le, and Denny Zhou
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, brian ichter, Fei Xia, Ed H. Chi, Quoc V Le, and Denny Zhou. Chain of thought prompting elicits reasoning in large language models. In Alice H. Oh, Alekh Agarwal, Danielle Belgrave, and Kyunghyun Cho, editors, Advances in Neural Information Processing Systems, 2022. URL https://openreview.net/ forum?...
2022
-
[44]
Inference scaling laws: An empirical analysis of compute-optimal inference for LLM problem-solving
Yangzhen Wu, Zhiqing Sun, Shanda Li, Sean Welleck, and Yiming Yang. Inference scaling laws: An empirical analysis of compute-optimal inference for LLM problem-solving. In The Thirteenth International Conference on Learning Representations, 2025. URL https: //openreview.net/forum?id=VNckp7JEHn. 1
2025
-
[45]
Large language interpolators can learn logical reasoning: A study on knights and knaves puzzles
Chulin Xie, Yangsibo Huang, Chiyuan Zhang, Da Yu, Xinyun Chen, Bill Yuchen Lin, Bo Li, Badih Ghazi, and Ravi Kumar. Large language interpolators can learn logical reasoning: A study on knights and knaves puzzles. InThe 4th Workshop on Mathematical Reasoning and AI at NeurIPS’24, 2024. URLhttps://openreview.net/forum?id=mxX8WdPCx9. 7
2024
-
[46]
Monte carlo tree search boosts reasoning via iterative preference learning
Yuxi Xie, Anirudh Goyal, Wenyue Zheng, Min-Yen Kan, Timothy P Lillicrap, Kenji Kawaguchi, and Michael Shieh. Monte carlo tree search boosts reasoning via iterative preference learning. InThe First Workshop on System-2 Reasoning at Scale, NeurIPS’24, 2024. URL https: //openreview.net/forum?id=s004OmYP2P. 10
2024
-
[47]
Griffiths, Yuan Cao, and Karthik R Narasimhan
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik R Narasimhan. Tree of thoughts: Deliberate problem solving with large language models. InThirty-seventh Conference on Neural Information Processing Systems, 2023. URL https://openreview.net/forum?id=5Xc1ecxO1h. 2, 3, 10
2023
-
[48]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Wang Zhang, Hang Zhu, Jinhua Zhu, Jiaze Chen, Jiangjie Chen, Chengyi Wang, Hongli Yu, Yuxuan Song, Xiangpeng Wei, Hao Zhou, Jingjing Liu, W...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
Self-rewarding language models
Weizhe Yuan, Richard Yuanzhe Pang, Kyunghyun Cho, Xian Li, Sainbayar Sukhbaatar, Jing Xu, and Jason E Weston. Self-rewarding language models. InForty-first International Conference on Machine Learning, 2024. URL https://openreview.net/forum?id=0NphYCmgua. 1, 9 16
2024
-
[50]
Does reinforcement learning really incentivize reasoning capacity in LLMs beyond the base model? InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
Yang Yue, Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Yang Yue, Shiji Song, and Gao Huang. Does reinforcement learning really incentivize reasoning capacity in LLMs beyond the base model? InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URLhttps://openreview.net/forum?id=4OsgYD7em5. 1
2026
-
[51]
Learning to Discover at Test Time
Mert Yuksekgonul, Daniel Koceja, Xinhao Li, Federico Bianchi, Jed McCaleb, Xiaolong Wang, Jan Kautz, Yejin Choi, James Zou, Carlos Guestrin, and Yu Sun. Learning to discover at test time, 2026. URLhttps://arxiv.org/abs/2601.16175. 1
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[52]
Star: Bootstrapping reasoning with reasoning
Eric Zelikman, Yuhuai Wu, Jesse Mu, and Noah Goodman. Star: Bootstrapping reasoning with reasoning. In Alice H. Oh, Alekh Agarwal, Danielle Belgrave, and Kyunghyun Cho, editors, Advances in Neural Information Processing Systems, 2022. URL https://openreview.net/ forum?id=_3ELRdg2sgI. 1, 9
2022
-
[53]
Self-taught opti- mizer (STOP): Recursively self-improving code generation
Eric Zelikman, Eliana Lorch, Lester Mackey, and Adam Tauman Kalai. Self-taught opti- mizer (STOP): Recursively self-improving code generation. InFirst Conference on Language Modeling, 2024. URLhttps://openreview.net/forum?id=46Zgqo4QIU. 1
2024
-
[54]
### Final Answer
Dan Zhang, Sining Zhoubian, Ziniu Hu, Yisong Yue, Yuxiao Dong, and Jie Tang. Rest-mcts*: Llm self-training via process reward guided tree search. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URL https://openreview.net/forum? id=8rcFOqEud5. 10 17 Appendix - Table of Contents A Pseudo Code 19 B Formal Definitions of ...
2024
-
[55]
Identify the single most distinctive trick / mechanism it uses (a particular initialization, a refinement step, a numerical formulation, a heuristic, ...)
-
[56]
attacks a different failure mode than what the current program already handles)
Decide whether that trick is compatible with the current program and is likely additive (i.e. attacks a different failure mode than what the current program already handles). Then produce a NEW full program that is the current program PLUS the compatible tricks from the inspirations stitched in. Be explicit in the <DESCRIPTION> about which trick came from...
-
[60]
Use scipy optimize, LP, or SLSQP to optimize variables given candidate structures 32 F.2.2 Deletion Deletion Iteration Prompt # Current program Here is the current program. The evolution loop has been stuck on iterations of approaches similar to this one --- incremental tweaks have not been moving the score: ```{language} {code_content} ``` Performance me...
-
[61]
Identify components of the current code that look unreasonable or that may be holding the search inside a local optimum (heuristics that don't pay off, design choices the search keeps committing to, dead branches, parameter sweeps that add little)
-
[62]
DELETE those components
-
[63]
Do not iterate on the current implementation
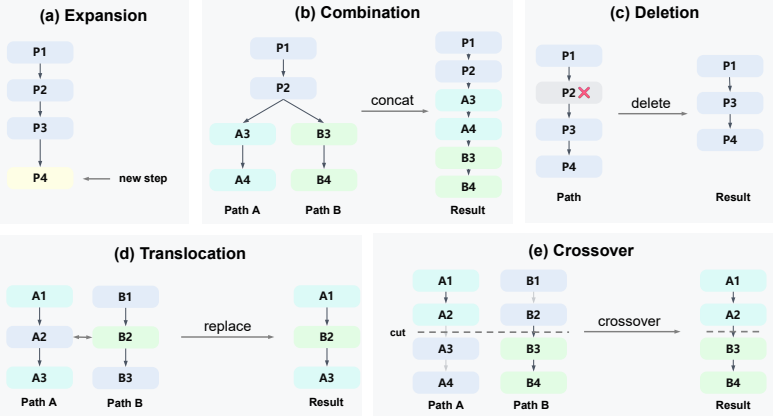
Rewrite the program from a fundamentally new perspective: pick an algorithm class, data structure, or strategy that the current program does NOT use, and commit fully to it. Do not iterate on the current implementation. Do not stitch new code onto the old skeleton. Commit fully to a different approach. A fundamental change replaces the solution representa...
-
[67]
Aim to combine the best parts of both code implementations that improves the score
Use scipy optimize, LP, or SLSQP to optimize variables given candidate structures F.2.3 Crossover Crossover Iteration Prompt # Current program Here is the current program we are trying to improve (you will need to propose a new program with the same inputs and outputs as the original program, but with improved internal implementation): ```{language} {code...
-
[70]
The optimization routine is critical - use models with carefully tuned parameters 34
-
[71]
distant relative
Use scipy optimize, LP, or SLSQP to optimize variables given candidate structures F.2.4 Translocation Translocation Iteration Prompt # Current program (the "near" parent --- keep its skeleton) ```{language} {code_content} ``` Performance metrics: {performance_metrics}{text_feedback_section} # Task: trick translocation from a distant relative Below you wil...
-
[72]
Be concrete; name it
Read it and pick the ONE trick that is most likely to help the current program --- a specific initialization, refinement step, constraint formulation, numerical detail, or heuristic. Be concrete; name it
-
[73]
Keep the rest of the current program intact
Transplant ONLY that trick into the current program. Keep the rest of the current program intact. Do NOT also fold in other ideas from the donor and do NOT broadly rewrite the recipient
-
[74]
Argue in the <DESCRIPTION>: which trick, why this one, and why grafting it onto the current skeleton is more promising than full crossover
Adapt naming / signatures so the transplant compiles, but do not refactor surrounding code beyond what the transplant strictly requires. Argue in the <DESCRIPTION>: which trick, why this one, and why grafting it onto the current skeleton is more promising than full crossover. Key directions to explore:
-
[75]
The optimal arrangement may involve heterogeneous or variable-sized elements
-
[76]
Strong solutions often use hybrid global-local patterns
-
[77]
The optimization routine is critical - use models with carefully tuned parameters
-
[78]
G.1 Circle Packing (Square) The best program for the n=26 unit-square instance is a hybrid global optimiser
Use scipy optimize, LP, or SLSQP to optimize variables given candidate structures G Identified Programs for Open Problem Solving Tasks This appendix summarizes, for each open-problem benchmark, the structure of the best program discovered byBES. G.1 Circle Packing (Square) The best program for the n=26 unit-square instance is a hybrid global optimiser. It...
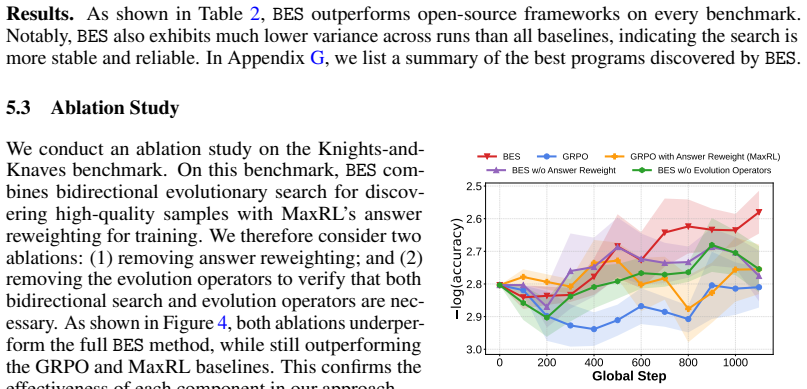
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.