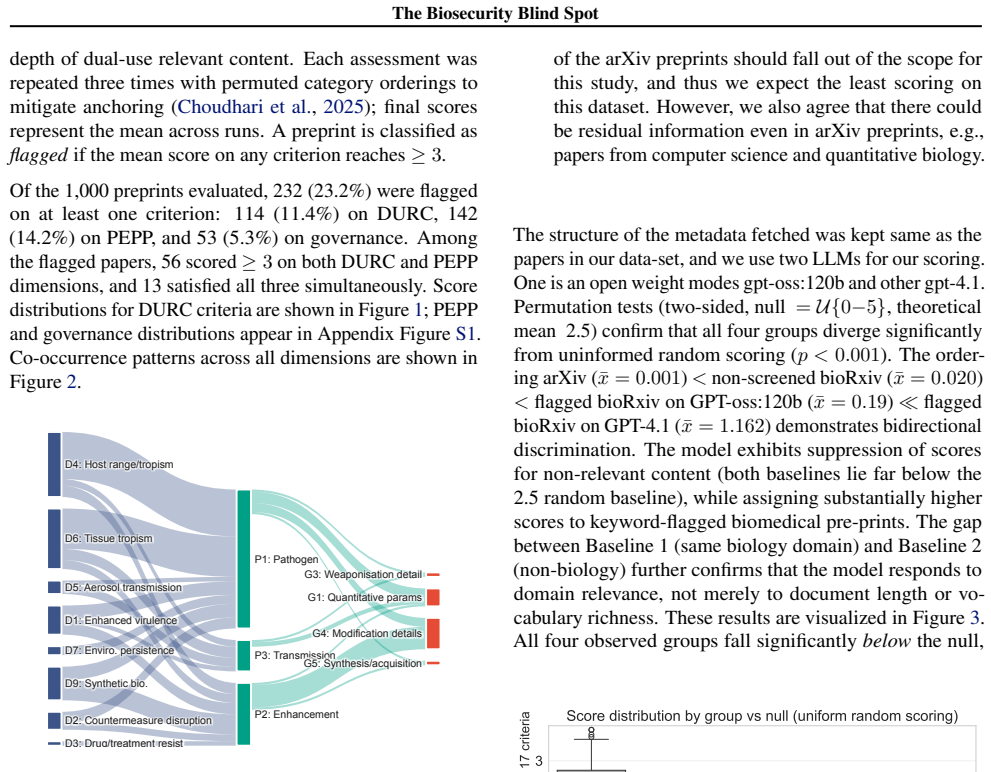
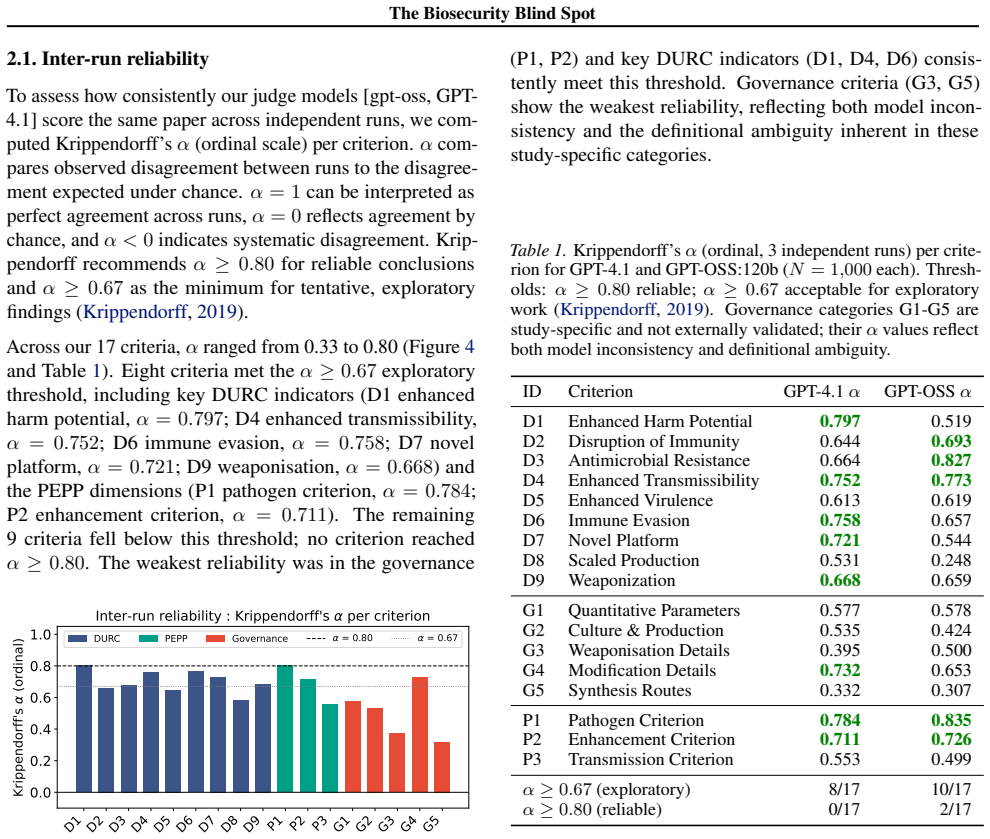
The Biosecurity Blind Spot: Systematic Dual-use Detection in Open Science Infrastructure
Pith reviewed 2026-06-30 22:38 UTC · model grok-4.3
The pith
A screening of over 50,000 bioRxiv preprints finds dual-use research signals routinely present in open titles and abstracts, often above risk thresholds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Application of a hybrid lexical-filtering and LLM-evaluation pipeline to roughly 52,000 bioRxiv preprints from 2024-2025 shows dual-use-adjacent knowledge routinely present in openly accessible titles and abstracts, often exceeding established risk thresholds even in studies with legitimate public health objectives. The work maps this presence across nine DURC, three PEPP, and five governance categories drawn from U.S. and Australia Group frameworks, while explicitly distinguishing surface-level information diffusion from operational capability or downstream misuse potential.
What carries the argument
Hybrid lexical-plus-LLM pipeline that scores preprint metadata across DURC, PEPP, and governance categories.
If this is right
- Institutional review processes must evolve to include proactive, metadata-level monitoring for high-risk content.
- Funding requirements should incorporate dual-use checks aligned with existing oversight frameworks.
- Preprint platform policies need updates to handle controlled access for high-risk methodologies while keeping summaries open.
- Harmonized mechanisms for high-risk methods paired with open summaries provide a scalable governance approach for AI-accelerated biology.
Where Pith is reading between the lines
- Extending the same pipeline to other preprint servers could reveal whether the pattern holds beyond bioRxiv.
- The surface-level detection leaves open the question of how often flagged content actually translates to practical capability once technical barriers are considered.
- Automated metadata screening might be combined with author self-reporting to reduce false positives while maintaining openness.
Load-bearing premise
The hybrid lexical-plus-LLM pipeline can reliably detect meaningful dual-use signals from titles and abstracts alone without high false-positive rates that would undermine the policy recommendation.
What would settle it
Manual expert review of a random sample of the flagged preprints finding that the large majority contain no substantial dual-use research of concern would falsify the central claim of routine presence above risk thresholds.
Figures


read the original abstract
AI is transforming life sciences research at unprecedented speed, accelerating discovery across protein structure prediction, genome modeling, and drug development (Jumper et al., 2021; Mak et al., 2024). Yet this rapid advancement, coupled with the open science movement, introduces significant dual-use research concerns that have received limited empirical scrutiny. Here we present the first systematic analysis of dual-use research of concern (DURC) content on open preprint servers. We screened ~52,000 bioRxiv preprints (2024-2025) using a hybrid pipeline of lexical filtering and large language model (LLM) evaluation, scoring metadata across nine DURC, three PEPP, and five governance categories aligned with U.S. and Australia Group oversight frameworks. Our analysis reveals that dual-use-adjacent knowledge is routinely present in openly accessible titles and abstracts, often exceeding established risk thresholds even in studies with legitimate public health objectives. While this mapping captures surface-level information diffusion, it does not measure operational capability, downstream misuse potential, or the substantial technical and biosafety barriers that constrain harmful application. We argue that institutional review processes, funding requirements, and preprint platform policies must evolve to incorporate proactive, metadata-level monitoring without compromising scientific transparency. Ultimately, harmonizing controlled-access mechanisms for high-risk methodologies with open summaries of scientific contributions offers a pragmatic framework for governing AI-accelerated biology at scale.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents the first systematic screening of ~52,000 bioRxiv preprints (2024-2025) for dual-use research of concern (DURC) using a hybrid lexical-filtering plus LLM pipeline. It scores metadata against nine DURC, three PEPP, and five governance categories drawn from U.S. and Australia Group frameworks, concluding that dual-use-adjacent content is routinely present in titles and abstracts, frequently exceeds established risk thresholds even in legitimate public-health studies, and therefore requires new metadata-level monitoring by institutions, funders, and preprint platforms while preserving open summaries.
Significance. If the classifier were shown to be reliable, the work would supply the first large-scale empirical map of surface-level DURC diffusion in open preprints and would directly inform policy debates on proactive governance of AI-accelerated biology. The explicit disclaimer that the study measures only surface diffusion (not operational capability or misuse potential) is a strength that keeps the claims proportionate.
major comments (3)
- [Abstract / Methods] Abstract and Methods: the central prevalence and 'exceeding thresholds' claims rest entirely on the hybrid lexical-plus-LLM pipeline, yet no validation metrics (precision, recall, F1 on a held-out human-annotated set), inter-rater agreement, prompt details, temperature settings, or baseline comparisons are reported. Titles and abstracts contain highly ambiguous terms ('pathogen', 'virulence', 'high-throughput screening') that appear in both routine and high-risk contexts; without quantified error rates the reported counts cannot be distinguished from classifier artifacts.
- [Results] Results (threshold-exceedance statements): the paper asserts that content 'often exceeding established risk thresholds' but does not define the numerical thresholds, the scoring scale used by the LLM, or the decision rule that maps scores to 'exceedance.' This directly undermines the quantitative mapping to policy recommendations.
- [Discussion] Discussion: the recommendation for 'proactive, metadata-level monitoring' is load-bearing on the assumption that the pipeline produces low false-positive rates; the absence of any error analysis leaves the policy claim unsupported even if the surface-level observation is directionally correct.
minor comments (2)
- [Methods] The manuscript should include a table or appendix listing the exact lexical filters and the nine DURC category definitions used.
- [Methods] Clarify whether the ~52,000 preprints represent the full 2024-2025 corpus or a filtered subset, and report the exact date range and retrieval method.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed review. We address each major comment point by point below, indicating where revisions will be made to improve clarity and rigor.
read point-by-point responses
-
Referee: [Abstract / Methods] Abstract and Methods: the central prevalence and 'exceeding thresholds' claims rest entirely on the hybrid lexical-filtering plus LLM pipeline, yet no validation metrics (precision, recall, F1 on a held-out human-annotated set), inter-rater agreement, prompt details, temperature settings, or baseline comparisons are reported. Titles and abstracts contain highly ambiguous terms ('pathogen', 'virulence', 'high-throughput screening') that appear in both routine and high-risk contexts; without quantified error rates the reported counts cannot be distinguished from classifier artifacts.
Authors: We agree that the absence of validation metrics, prompt details, and error quantification is a significant limitation in the submitted version. In the revised manuscript we will add a new Methods subsection that reports: (1) the exact prompt templates and temperature setting (0 for determinism), (2) results from a held-out set of 500 human-annotated abstracts with precision, recall, and F1 scores, and (3) inter-rater agreement (Cohen’s kappa) between two independent annotators. We will also describe how the hybrid lexical-plus-LLM design mitigates ambiguity for terms such as 'pathogen' and 'virulence'. revision: yes
-
Referee: [Results] Results (threshold-exceedance statements): the paper asserts that content 'often exceeding established risk thresholds' but does not define the numerical thresholds, the scoring scale used by the LLM, or the decision rule that maps scores to 'exceedance.' This directly undermines the quantitative mapping to policy recommendations.
Authors: We acknowledge that the scoring scale and decision rules were not explicitly stated. The revised manuscript will define the LLM scoring scale (0–5 per category), the aggregation across the 17 categories, and the precise rule for 'exceedance' (any single category score ≥4). These details will be placed in both Methods and Results so that the quantitative claims are fully reproducible and the mapping to policy discussion is transparent. revision: yes
-
Referee: [Discussion] Discussion: the recommendation for 'proactive, metadata-level monitoring' is load-bearing on the assumption that the pipeline produces low false-positive rates; the absence of any error analysis leaves the policy claim unsupported even if the surface-level observation is directionally correct.
Authors: The policy recommendations are framed as a call for institutions and platforms to develop validated monitoring tools rather than a direct claim that our current pipeline is ready for deployment. The manuscript already contains an explicit disclaimer that only surface-level diffusion is measured. Nevertheless, we accept that a dedicated error-analysis subsection is needed. We will add this subsection, discuss likely sources of false positives, and qualify the recommendations to stress that any operational monitoring must first demonstrate acceptable error rates on domain-specific validation data. revision: partial
Circularity Check
No circularity: empirical screening with no derivations or self-referential reductions
full rationale
The paper performs an empirical screen of ~52,000 bioRxiv preprints using a hybrid lexical-LLM pipeline across fixed DURC/PEPP/governance categories drawn from external U.S. and Australia Group frameworks. No equations, fitted parameters, predictions derived from inputs, or self-citations appear in the load-bearing steps. The central claim rests on the pipeline's classifications of titles and abstracts, which are not defined in terms of the outputs themselves and do not reduce to any of the enumerated circularity patterns. The work is therefore self-contained as a descriptive mapping exercise.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption DURC, PEPP, and governance categories are aligned with U.S. and Australia Group oversight frameworks and can be applied to preprint metadata
Reference graph
Works this paper leans on
-
[1]
Chemberta-2: towards chemical foundation models.arXiv preprint arXiv:2209.01712,
Ahmad, W., Simon, E., Chithrananda, S., Grand, G., and Rosen, B. Chemberta-2: towards chemical foundation models.arXiv preprint arXiv:2209.01712,
-
[2]
Common control list handbook, volume II: Biological weapons-related common control lists
Australia Group. Common control list handbook, volume II: Biological weapons-related common control lists. URL https://www.dfat.gov.au/sites/defaul t/files/australia- group- common- con trol-list-handbook-volume-ii.pdf . Ac- cessed: 2026-04-30. Baek, M., DiMaio, F., Anishchenko, I., Dauparas, J., Ovchinnikov, S., Lee, G. R., Wang, J., Cong, Q., Kinch, L. ...
2026
-
[3]
Bagal, V ., Aggarwal, R., Vinod, P., and Priyakumar, U
doi: 10.1126/science.abj8754. Bagal, V ., Aggarwal, R., Vinod, P., and Priyakumar, U. D. Molgpt: molecular generation using a transformer- decoder model.Journal of Chemical Information and Modeling, 62(9):2064–2076,
-
[4]
doi: 10.1021/acs.jc im.1c00600. Brundage, M., Avin, S., Clark, J., Toner, H., Eckersley, P., Garfinkel, B., Dafoe, A., Scharre, P., Zeitzoff, T., Filar, B., et al. The malicious use of artificial intelligence: Forecasting, prevention, and mitigation.arXiv preprint arXiv:1802.07228,
-
[5]
Chen, J., Hu, Z., Sun, S., Tan, Q., Wang, Y ., Yu, Q., Zong, L., Hong, L., Xiao, J., King, I., et al. Interpretable rna foundation model from unannotated data for highly accu- rate rna structure and function predictions.arXiv preprint arXiv:2204.00300,
-
[6]
K., McIlwraith, D., and Nair, S
Choudhari, J., Singh, P. K., McIlwraith, D., and Nair, S. Prompt smart, pay less: Cost-aware apo for real-world applications.arXiv preprint arXiv:2507.15884,
-
[7]
Accessed: 2026-04-30
URL https://ou rworldindata.org/historical-pandemics . Accessed: 2026-04-30. Dauparas, J., Anishchenko, I., Bennett, N., Bai, H., Ragotte, R. J., Milles, L. F., Wicky, B. I., Courbet, A., de Haas, R. J., Bethel, N., et al. Robust deep learning–based pro- tein sequence design using proteinmpnn.Science, 378 (6615):49–56,
2026
-
[8]
Ferruz, N., Schmidt, S., and H¨ocker, B
doi: 10.1126/science.add2187. Ferruz, N., Schmidt, S., and H¨ocker, B. Protgpt2 is a deep unsupervised language model for protein design.Nature Communications, 13(1):4348,
-
[9]
doi: 10.1038/s414 67-022-32007-7. Gracias, S., Le Seac’h, E., Donaire-Carpio, S., Vuillier, F., Vendramini, L., Moundib, A., Temmam, S., Rutkowska, M., Donati, F., Cupic, A., et al. Entry, replication and innate immunity evasion of banal-236, a sars-cov- 2-related bat virus, in rhinolophus and human cells.PLoS pathogens, 22(4):e1013573,
-
[10]
doi: 10.4135/9781071878781. URL https://methods.sagepub.com/book /mono/content-analysis-4e/toc. Lin, Z., Akin, H., Rao, R., Hie, B., Zhu, Z., Lu, W., Smetanin, N., Verkuil, R., Kabeli, O., Shmueli, Y ., et al. Language models of protein sequences at the scale of evo- lution enable accurate structure prediction.Science, 379 (6637):eade2574,
-
[11]
Evolutionary-scale prediction of atomic-level protein structure with a language model , volume =
doi: 10.1126/science.ade2574. Madani, A., Krause, B., Greene, E. R., Subramanian, S., Mohr, B. P., Holton, J. M., Olmos Jr, J. L., Xiong, C., Sun, Z. Z., Socher, R., et al. Large language models generate functional protein sequences across diverse fam- ilies.Nature Biotechnology, 41(8):1099–1106,
-
[12]
doi: 10.1038/s41587-022-01618-2
doi: 10.1038/s41587-022-01618-2. Mak, K.-K., Wong, Y .-H., and Pichika, M. R. Artificial intelligence in drug discovery and development.Drug discovery and evaluation: safety and pharmacokinetic assays, pp. 1461–1498,
-
[13]
O’Brien, K., Casper, S., Anthony, Q., Korbak, T., Kirk, R., Davies, X., Mishra, I., Irving, G., Gal, Y ., and Biderman, S. Deep ignorance: Filtering pretraining data builds tamper-resistant safeguards into open-weight llms.arXiv preprint arXiv:2508.06601,
-
[14]
doi: 10.4049/jimm unol.1800708. Shuai, R. W., Ruffolo, J. A., and Gray, J. J. Generative language modeling for antibody design.Cell Systems, 13 (12):934–944,
-
[15]
doi: 10.1016/j.cels.2021.11.003. United States Government. United states government pol- icy for oversight of dual use research of concern and pathogens with enhanced pandemic potential, May
-
[16]
Accessed: 2026-04-30
URL https://worksinprogress.co/issue /pandemic-prevention-as-fire-fightin g/. Accessed: 2026-04-30. World Health Organization.Global guidance framework for the responsible use of the life sciences: mitigating biorisks and governing dual-use research. World Health Organization, Geneva,
2026
-
[17]
we enhanced aerosol transmissibility in ferrets
URL https://www.who.int/publicatio ns/b/65594 . Available under Creative Commons Attribution-NonCommercial-ShareAlike 3.0 IGO license. 7 The Biosecurity Blind Spot A. List of Keywords Pandemic Pathogens Influenza A virus, SARS-CoV-2, SARS-CoV-1, MERS-CoV , Monkeypox virus, Ebola virus, Marburg virus, Nipah virus, Hendra virus, Crimean-Congo hemorrhagic fe...
1918
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.