Representation Signatures and Risk-Feedback Alignment in LLM Trading Agents
Pith reviewed 2026-06-30 18:59 UTC · model grok-4.3
The pith
LLM trading agents exhibit planning embedding drift and effective-rank contraction before drawdowns, with structured risk feedback acting as an external alignment signal.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
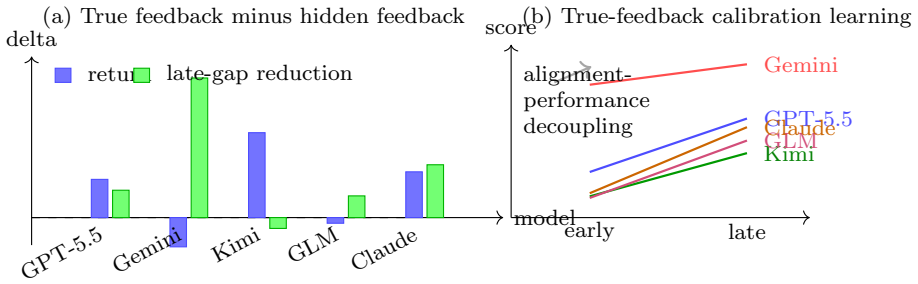
Across 80 rolling failure anchors and eight LLM trajectories, planning embeddings drift from normal centroids, fused plan-risk representations separate normal from pre-drawdown states, and local manifolds exhibit effective-rank contraction. This pattern holds across different probe types. Structured risk feedback serves as an external alignment signal without fine-tuning, but true audit feedback improves calibration or returns selectively, while placebo feedback sometimes yields higher short-horizon returns. LLM rationales can justify exposure to coupled assets despite risk clipping.
What carries the argument
Pre-failure representation signatures, including embedding drift from centroids, separation in fused plan-risk space, and effective-rank contraction in local manifolds, detected via hash, LSA, Transformer, and hidden-state probes.
If this is right
- Structured risk feedback enables alignment of LLM financial reasoning without model fine-tuning.
- Pre-drawdown states are detectable through representation trajectories in planning and risk spaces.
- Rationale-level contraction disappears without rationales, but intent-space signatures persist.
- LLM agents may over-justify exposures to correlated assets that risk mechanisms limit.
- Audit-focused evaluation reveals whether models respect execution boundaries and avoid overreach.
Where Pith is reading between the lines
- These signatures could potentially be monitored in real-time for deployed LLM agents in other sequential tasks.
- External feedback loops might serve as a general method to align LLMs in high-stakes domains without retraining.
- The correlation blind spot points to a need for improved multi-variable reasoning in agent architectures.
- If the patterns prove robust, they could inform safety mechanisms for autonomous decision systems.
Load-bearing premise
The representation patterns observed are reliable indicators of impending failure rather than artifacts specific to the simulation dynamics or chosen probes.
What would settle it
Running the same experiments with different market generators or execution rules and finding that the signatures disappear would falsify the claim that they indicate impending failure.
Figures

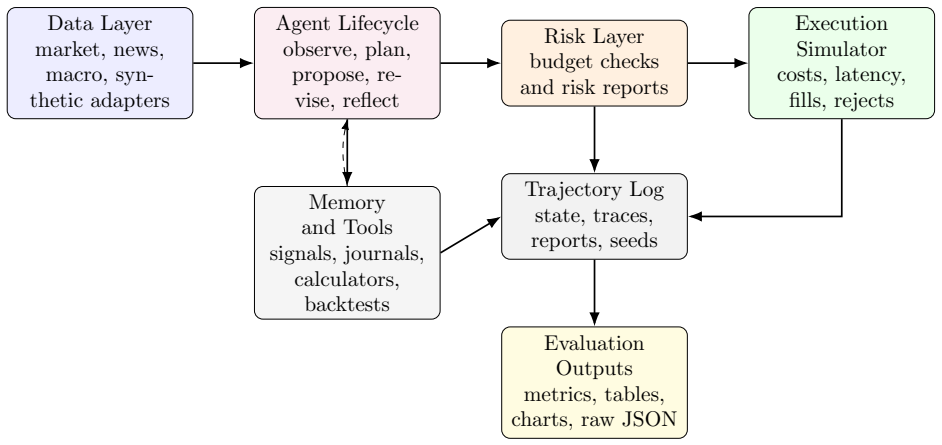
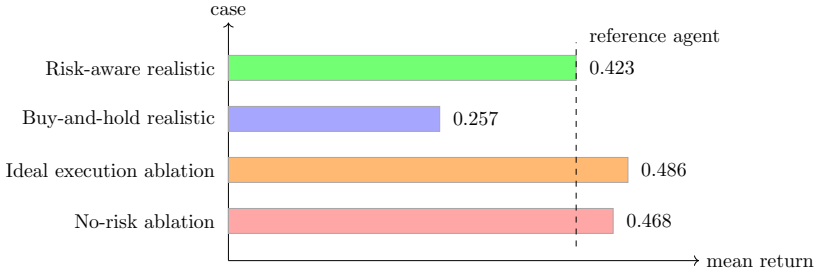
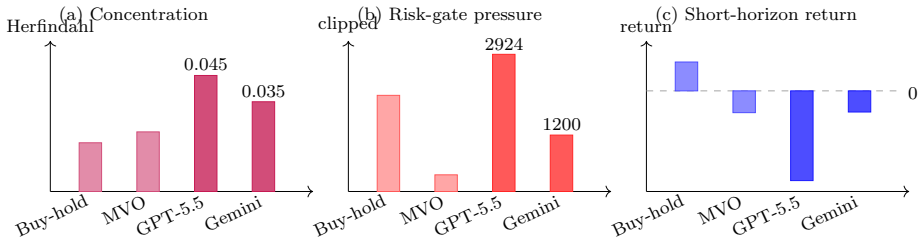
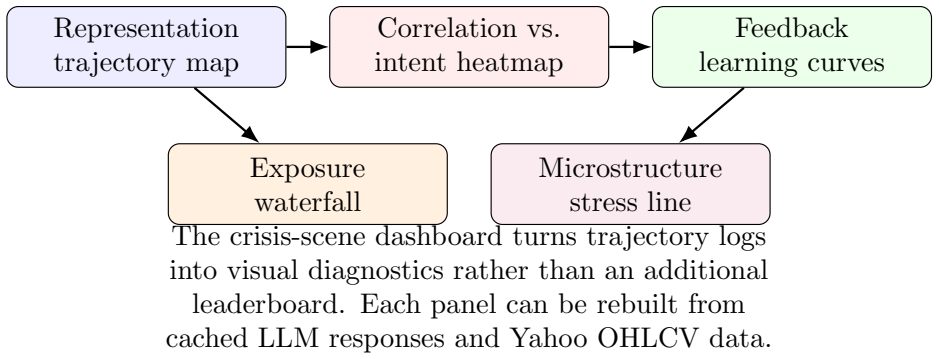

read the original abstract
We study behavioral alignment and representation dynamics of large language model (LLM) agents in financial decision environments. TradeArena, an auditable trading-agent testbed with risk reports, execution simulation, memory, and replayable trajectories, lets us analyze how rationales, positions, and interventions evolve under market stress. Code and data artifacts are available through the \href{https://github.com/weich97/TradeArena.git}{TradeArena repository}. We find pre-failure signatures: planning embeddings drift from normal centroids, fused plan-risk representations separate normal from pre-drawdown states, and local manifolds exhibit effective-rank contraction. Across 80 rolling failure anchors and eight LLM trajectories, this pattern persists across hash, LSA, Transformer, and white-box hidden-state probes. Stress tests with CoT-free target weights, lexical controls, OHLCV noise, and false audits show that rationale-level contraction can vanish without rationales, while intent-space and fused signatures remain informative. Structured risk feedback can act as an external alignment signal without fine-tuning, but not as a universal performance enhancer: true audit feedback improves calibration for some models, returns for others, and exposes cases where placebo or hidden feedback has higher short-horizon return but weaker alignment diagnostics. A 51-stock intraday experiment reveals a correlation blind spot: LLM rationales justify exposure to coupled assets that the risk layer clips. Finally, a financial-audit task suite shifts comparison from ``which model trades best'' to whether models can audit trajectories, respect execution boundaries, reproduce artifacts, and avoid claim overreach. These results support a research claim, not a profitability claim: auditable risk feedback and representation trajectories reveal when LLM financial reasoning is aligning, drifting, or failing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports an empirical investigation of representation dynamics in LLM trading agents using the TradeArena testbed, which includes risk reports, execution simulation, and replayable trajectories. Across 80 rolling failure anchors and eight LLM trajectories, it identifies pre-failure signatures including planning-embedding drift from normal centroids, separation in fused plan-risk representations between normal and pre-drawdown states, and effective-rank contraction in local manifolds. These patterns are probed via hash, LSA, Transformer, and white-box hidden-state methods and persist under stress tests involving CoT-free weights, lexical controls, OHLCV noise, and false audits. The work further examines structured risk feedback as an external alignment signal without fine-tuning, notes differential effects on calibration and returns, highlights a correlation blind spot in a 51-stock intraday experiment, and introduces a financial-audit task suite focused on trajectory auditing, boundary respect, artifact reproduction, and claim restraint. Code and data are released via GitHub.
Significance. If the reported representation signatures prove robust, the study would offer concrete, probe-based diagnostics for detecting alignment drift in LLM agents during sequential decision tasks under stress, moving beyond aggregate performance metrics toward mechanistic monitoring. The open release of code, data, and the audit task suite supports reproducibility and community extension. The distinction between alignment diagnostics and short-horizon returns, along with the explicit non-claim of profitability, strengthens the framing as a research contribution rather than an applied trading system.
major comments (2)
- [Stress tests] Stress tests section (as described in the abstract and results): The listed stress tests (CoT-free target weights, lexical controls, OHLCV noise, false audits) vary prompt style and feedback content but hold the underlying market generator, volatility process, liquidity model, and order-matching mechanics fixed. Because the central claim requires that planning-embedding drift, fused separation, and manifold contraction are reliable indicators of impending failure rather than simulation artifacts, the absence of controls that alter the stochastic process or execution engine leaves the attribution to LLM reasoning untested. Experiments with alternative generators (different volatility models or real tick-data replay) are needed to establish that the signatures are not TradeArena-specific.
- [Results on failure anchors] Results on 80 rolling failure anchors and eight trajectories: The manuscript states that the pattern 'persists across' multiple probes but supplies no quantitative effect sizes, confidence intervals, or statistical controls for multiple comparisons in the provided description. Without these, it is not possible to assess whether the separation and contraction exceed what would be expected under the null of no pre-failure structure, weakening the load-bearing empirical claim.
minor comments (2)
- [Abstract] The abstract would benefit from a single sentence summarizing the magnitude of the reported separations or rank contractions to give readers an immediate sense of effect size.
- [Methods] Notation for 'effective-rank contraction' and 'fused plan-risk representations' should be defined explicitly on first use with reference to the specific probe or embedding layer employed.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We respond to each major point below.
read point-by-point responses
-
Referee: [Stress tests] Stress tests section (as described in the abstract and results): The listed stress tests (CoT-free target weights, lexical controls, OHLCV noise, false audits) vary prompt style and feedback content but hold the underlying market generator, volatility process, liquidity model, and order-matching mechanics fixed. Because the central claim requires that planning-embedding drift, fused separation, and manifold contraction are reliable indicators of impending failure rather than simulation artifacts, the absence of controls that alter the stochastic process or execution engine leaves the attribution to LLM reasoning untested. Experiments with alternative generators (different volatility models or real tick-data replay) are needed to establish that the signatures are not TradeArena-specific.
Authors: We agree that the stress tests isolate prompt and feedback variations while keeping the market generator fixed. This design choice means the reported signatures cannot be fully attributed to LLM reasoning independent of TradeArena's stochastic process and execution mechanics. We will add an explicit limitations paragraph in the revised Discussion section acknowledging that the signatures are demonstrated within this testbed and that tests with alternative generators (e.g., different volatility models or tick-data replay) remain necessary to establish broader robustness. New experiments of this scope are not feasible in the current revision cycle. revision: partial
-
Referee: [Results on failure anchors] Results on 80 rolling failure anchors and eight trajectories: The manuscript states that the pattern 'persists across' multiple probes but supplies no quantitative effect sizes, confidence intervals, or statistical controls for multiple comparisons in the provided description. Without these, it is not possible to assess whether the separation and contraction exceed what would be expected under the null of no pre-failure structure, weakening the load-bearing empirical claim.
Authors: The referee is correct that quantitative effect sizes, confidence intervals, and multiple-comparison controls are not reported in the current text. We will revise the Results section to include these statistics (e.g., effect sizes for embedding drift and manifold contraction, with Bonferroni-adjusted p-values across probes) computed from the existing 80-anchor dataset. This addition will be made without new data collection. revision: yes
Circularity Check
Observational study with no derivation chain or fitted predictions.
full rationale
The paper reports empirical observations from TradeArena simulations, including embedding drifts, representation separations, and manifold contractions across 80 anchors, eight trajectories, and multiple probes. No equations, first-principles derivations, parameter fits, or predictions that reduce to inputs by construction appear in the provided text. Claims rest on experimental patterns and stress tests rather than self-definitional loops, self-citation load-bearing premises, or renamed known results. The work is self-contained as an observational analysis without any load-bearing step that equates outputs to inputs by definition.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Markowitz
H. Markowitz. Portfolio selection.The Journal of Finance, 7(1):77–91, 1952
1952
-
[2]
W. F. Sharpe. Mutual fund performance.The Journal of Business, 39(1):119–138, 1966
1966
-
[3]
Kahneman and A
D. Kahneman and A. Tversky. Prospect theory: an analysis of decision under risk.Economet- rica, 47(2):263–292, 1979
1979
-
[4]
R. Almgren and N. Chriss. Optimal execution of portfolio transactions.Journal of Risk, 3(2):5– 39, 2001. doi:10.21314/JOR.2001.041
-
[5]
D. H. Bailey, J. M. Borwein, M. Lopez de Prado, and Q. J. Zhu. The probability of backtest overfitting.Journal of Computational Finance, 20(4):39–69, 2017. doi:10.21314/JCF.2016.322
-
[6]
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y. Cao. ReAct: Synergizing rea- soning and acting in language models.International Conference on Learning Representations, 2023
2023
-
[7]
Schick, J
T. Schick, J. Dwivedi-Yu, R. Dess` ı, R. Raileanu, M. Lomeli, E. Hambro, L. Zettlemoyer, N. Cancedda, and T. Scialom. Toolformer: Language models can teach themselves to use tools. Advances in Neural Information Processing Systems, 2023
2023
-
[8]
J. S. Park, J. O’Brien, C. J. Cai, M. R. Morris, P. Liang, and M. S. Bernstein. Generative agents: Interactive simulacra of human behavior.ACM Symposium on User Interface Software and Technology, 2023
2023
-
[9]
Ethayarajh
K. Ethayarajh. How contextual are contextualized word representations? Comparing the ge- ometry of BERT, ELMo, and GPT-2 embeddings.Proceedings of EMNLP-IJCNLP, pages 55–65, 2019
2019
-
[10]
Papyan, X
V. Papyan, X. Y. Han, and D. L. Donoho. Prevalence of neural collapse during the ter- minal phase of deep learning training.Proceedings of the National Academy of Sciences, 117(40):24652–24663, 2020
2020
-
[11]
X.-Y. Liu, H. Yang, Q. Chen, R. Zhang, L. Yang, B. Xiao, and C. D. Wang. FinRL: A deep reinforcement learning library for automated stock trading in quantitative finance.NeurIPS Workshop on Deep Reinforcement Learning, 2020
2020
-
[12]
X.-Y. Liu, Z. Xia, J. Rui, J. Gao, H. Yang, M. Zhu, C. D. Wang, Z. Wang, and J. Guo. FinRL- Meta: Market environments and benchmarks for data-driven financial reinforcement learning. Advances in Neural Information Processing Systems Datasets and Benchmarks, 2022
2022
- [13]
-
[14]
FinGPT: Open-source financial large lan- guage models,
H. Yang, X.-Y. Liu, and C. D. Wang. FinGPT: Open-source financial large language models. arXiv preprint arXiv:2306.06031, 2023
- [15]
-
[16]
J. Chen, S. Xiao, P. Zhang, K. Luo, D. Lian, and Z. Liu. M3-Embedding: Multi-Linguality, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distilla- tion.arXiv preprint arXiv:2402.03216, 2024. Model card:https://huggingface.co/BAAI/ bge-m3. Accessed May 17, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
A. Yang et al. Qwen2.5 technical report.arXiv preprint arXiv:2412.15115, 2024. Model card: https://huggingface.co/Qwen/Qwen2.5-0.5B-Instruct. Accessed May 17, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
R. Aroussi. yfinance documentation.https://ranaroussi.github.io/yfinance/. Accessed May 17, 2026. 34
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.