Echoes within the Reasoning: Stealthy and Effective Watermarking via Chain of Thought
Pith reviewed 2026-06-29 11:39 UTC · model grok-4.3
The pith
BiCoT embeds watermarks into chain-of-thought reasoning geometry by aligning high-saliency anchors with a private subspace to survive removal while keeping reasoning accurate.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
BiCoT embeds ownership signals into the internal geometry of reasoning traces by aligning high-saliency structural anchors with a private signature subspace while regularizing ordinary control tokens to preserve semantic capacity. This design couples the watermark with reasoning-relevant representations, making removal difficult without disrupting the features that support coherent reasoning. Robust Subspace Registration provides a top-logprob-based black-box verifier that uses sentinel tokens to calibrate systematic shifts in the output distribution.
What carries the argument
BiCoT framework, which aligns high-saliency structural anchors in reasoning traces with a private signature subspace to embed and protect the ownership signal.
If this is right
- Reasoning fidelity stays intact across diverse complex reasoning tasks after watermark insertion.
- Detection holds under fine-tuning, quantization, model-level perturbations, and adaptive output attacks.
- Verification succeeds in both in-domain and out-of-distribution settings via Robust Subspace Registration.
- The watermark resists removal because it is tied directly to representations required for coherent reasoning.
Where Pith is reading between the lines
- Similar anchor alignment might protect other internal model properties such as safety or factuality constraints.
- This points toward watermarking that becomes part of the core computation path rather than an add-on at output time.
- Models trained with built-in subspace registration could make ownership verification a standard deployment step.
- Scaling the approach to larger models or multimodal reasoning could expose limits in subspace stability.
Load-bearing premise
Aligning high-saliency structural anchors with a private signature subspace while regularizing ordinary control tokens will not disrupt the semantic capacity or coherence needed for correct reasoning.
What would settle it
An experiment showing an adaptive attack that removes detectable traces of the watermark while the model retains identical accuracy on the same set of complex reasoning tasks.
Figures
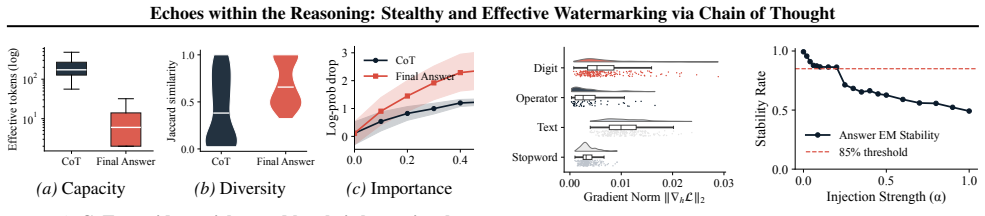
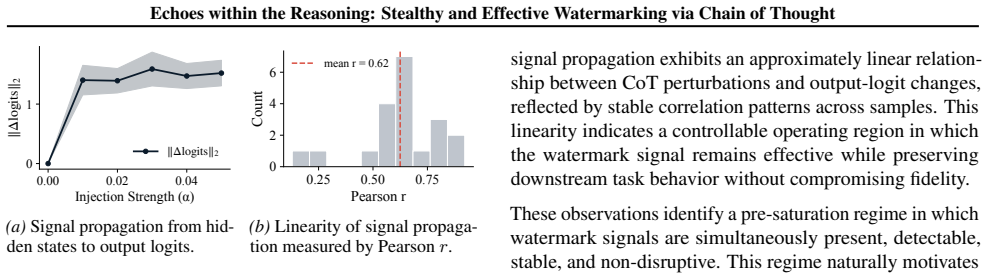
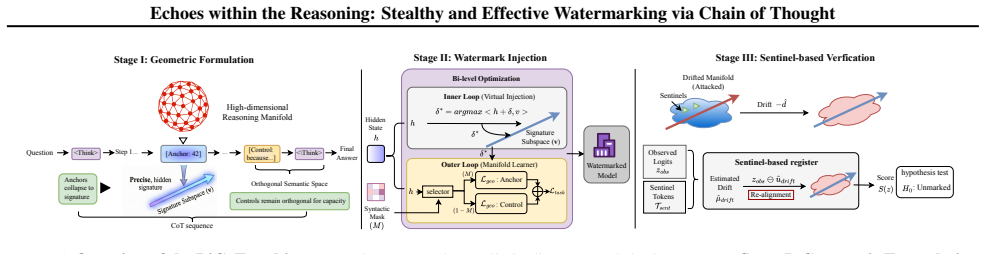
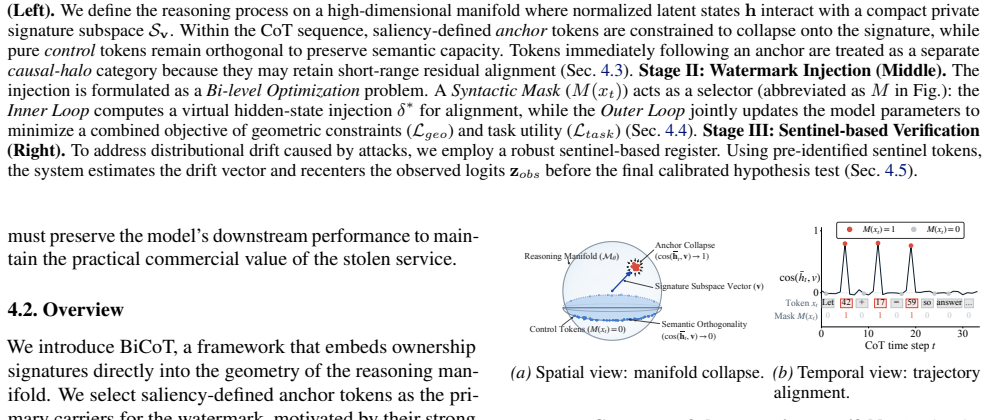


read the original abstract
Large Language Models with Chain-of-Thought reasoning capabilities represent valuable intellectual property, yet existing black-box watermarking methods often trade robustness for reasoning fidelity by perturbing final answers or relying on fragile trigger patterns. We propose BiCoT, a watermarking framework that embeds ownership signals into the internal geometry of reasoning traces by aligning high-saliency structural anchors with a private signature subspace while regularizing ordinary control tokens to preserve semantic capacity. This design couples the watermark with reasoning-relevant representations, making removal difficult without disrupting the features that support coherent reasoning. To enable verification under model theft and representation drift, we introduce Robust Subspace Registration (RSR), a Top- logprob-based black-box verifier that uses sentinel tokens to calibrate systematic shifts in the output distribution. Experiments show that BiCoT preserves reasoning fidelity across diverse complex reasoning tasks while achieving robust detection under fine-tuning, quantization, model-level perturbations, and adaptive output-level attacks across in-domain and out-of-distribution settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes BiCoT, a watermarking framework for Chain-of-Thought reasoning in LLMs. It embeds ownership signals into the internal geometry of reasoning traces by aligning high-saliency structural anchors with a private signature subspace while regularizing ordinary control tokens to preserve semantic capacity. It further introduces Robust Subspace Registration (RSR), a top-logprob-based black-box verifier that uses sentinel tokens to calibrate output distribution shifts. The authors claim that BiCoT preserves reasoning fidelity across diverse complex reasoning tasks while achieving robust detection under fine-tuning, quantization, model-level perturbations, and adaptive output-level attacks in both in-domain and out-of-distribution settings.
Significance. If the experimental claims hold with appropriate quantitative support, this would constitute a meaningful advance in black-box watermarking for reasoning-capable LLMs by coupling the watermark to reasoning-relevant representations rather than perturbing final answers. The RSR verifier could address a practical gap in verification under model theft and representation drift.
major comments (3)
- [Abstract] Abstract: the abstract asserts positive experimental outcomes on fidelity and robustness but supplies no quantitative results, baselines, error bars, or dataset details; central claims cannot be evaluated from the provided text alone.
- [Abstract] Abstract (design description): the core assumption that aligning high-saliency structural anchors with a private signature subspace while regularizing ordinary control tokens preserves semantic capacity and coherence is stated without definition of saliency measurement, analysis of subspace projection geometry relative to CoT representations, or ablation isolating the alignment step's effect on trace fidelity.
- [Abstract] Abstract: no equations, derivations, or formal definitions of the private signature subspace or sentinel tokens appear, preventing assessment of whether the method introduces free parameters or whether verification reduces to fitted quantities.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback focused on the abstract. We agree that the abstract should enable better evaluation of the central claims and will revise it to incorporate key quantitative results and brief technical clarifications while preserving conciseness. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the abstract asserts positive experimental outcomes on fidelity and robustness but supplies no quantitative results, baselines, error bars, or dataset details; central claims cannot be evaluated from the provided text alone.
Authors: The abstract serves as a high-level summary; full quantitative results including baselines, error bars, and dataset details appear in Sections 4 and 5. We will revise the abstract to include representative quantitative outcomes (e.g., fidelity preservation percentages and detection accuracies under attacks) to make the claims more evaluable from the abstract alone. revision: yes
-
Referee: [Abstract] Abstract (design description): the core assumption that aligning high-saliency structural anchors with a private signature subspace while regularizing ordinary control tokens preserves semantic capacity and coherence is stated without definition of saliency measurement, analysis of subspace projection geometry relative to CoT representations, or ablation isolating the alignment step's effect on trace fidelity.
Authors: Saliency measurement, subspace projection geometry relative to CoT representations, and the isolating ablation are defined and analyzed in Sections 3.2 and 4.3. We will revise the abstract to include a brief definition of saliency measurement and reference the ablation results supporting the design. revision: yes
-
Referee: [Abstract] Abstract: no equations, derivations, or formal definitions of the private signature subspace or sentinel tokens appear, preventing assessment of whether the method introduces free parameters or whether verification reduces to fitted quantities.
Authors: Formal definitions, equations for the private signature subspace, and sentinel tokens are provided in Section 3.1 and 3.3, with parameter counts and verification procedure detailed there. The abstract omits equations for accessibility. We will add concise formal descriptions of the subspace and sentinel tokens to the revised abstract. revision: partial
Circularity Check
No significant circularity in derivation chain
full rationale
The provided text consists of an abstract and high-level method description for BiCoT without any equations, derivations, predictions, or first-principles results. No load-bearing steps are shown that reduce by construction to inputs, self-definitions, fitted parameters renamed as predictions, or self-citation chains. The design is presented as a set of choices for embedding signals and verification, with no mathematical reductions or uniqueness theorems invoked. This is the common case of a self-contained proposal without circularity in the enumerated patterns.
Axiom & Free-Parameter Ledger
invented entities (2)
-
private signature subspace
no independent evidence
-
sentinel tokens
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Dashscope api reference, 2026
Alibaba Cloud Model Studio . Dashscope api reference, 2026. URL https://help.aliyun.com/zh/model-studio/qwen-api-via-dashscope
2026
-
[2]
DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
Bi, X., Chen, D., Chen, G., Chen, S., Dai, D., Deng, C., Ding, H., Dong, K., Du, Q., Fu, Z., et al. Deepseek llm: Scaling open-source language models with longtermism. arXiv preprint arXiv:2401.02954, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
L., Gao, J., and Choi, Y
Bisk, Y., Zellers, R., Bras, R. L., Gao, J., and Choi, Y. Piqa: Reasoning about physical commonsense in natural language. In AAAI, 2020
2020
-
[4]
Can we edit multimodal large language models? In EMNLP, 2023
Cheng, S., Tian, B., Liu, Q., Chen, X., Wang, Y., Chen, H., and Zhang, N. Can we edit multimodal large language models? In EMNLP, 2023
2023
-
[5]
Boolq: Exploring the surprising difficulty of natural yes/no questions
Clark, C., Lee, K., Chang, M.-W., Kwiatkowski, T., Collins, M., and Toutanova, K. Boolq: Exploring the surprising difficulty of natural yes/no questions. In NAACL, 2019
2019
-
[6]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Clark, P., Cowhey, I., Etzioni, O., Khot, T., Sabharwal, A., Schoenick, C., and Tafjord, O. Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv preprint arXiv:1803.05457, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[7]
glm-4.7-flash, 2026 a
Cloudflare Workers AI . glm-4.7-flash, 2026 a . URL https://developers.cloudflare.com/workers-ai/models/glm-4.7-flash/
2026
-
[8]
kimi-k2.5, 2026 b
Cloudflare Workers AI . kimi-k2.5, 2026 b . URL https://developers.cloudflare.com/workers-ai/models/kimi-k2.5/
2026
-
[9]
Training Verifiers to Solve Math Word Problems
Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[10]
Seal: Subspace-anchored watermarks for llm ownership
Dai, Y., Li, Z., Ji, Z., and Wang, S. Seal: Subspace-anchored watermarks for llm ownership. arXiv preprint arXiv:2511.11356, 2025
-
[11]
Create chat completion, 2026
DeepSeek . Create chat completion, 2026. URL https://api-docs.deepseek.com/api/create-chat-completion
2026
-
[12]
Model equality testing: Which model is this api serving? In ICLR, 2025
Gao, I., Liang, P., and Guestrin, C. Model equality testing: Which model is this api serving? In ICLR, 2025
2025
-
[13]
When backdoors speak: Understanding llm backdoor attacks through model-generated explanations
Ge, H., Li, Y., Wang, Q., Zhang, Y., and Tang, R. When backdoors speak: Understanding llm backdoor attacks through model-generated explanations. In ACL, 2025
2025
-
[14]
Towards watermarking of open-source llms
Gloaguen, T., Jovanovi \'c , N., Staab, R., and Vechev, M. Towards watermarking of open-source llms. arXiv preprint arXiv:2502.10525, 2025
-
[15]
Generating content, 2026
Google AI for Developers . Generating content, 2026. URL https://ai.google.dev/api/generate-content
2026
-
[16]
BadNets: Identifying Vulnerabilities in the Machine Learning Model Supply Chain
Gu, T., Dolan-Gavitt, B., and Garg, S. Badnets: Identifying vulnerabilities in the machine learning model supply chain. arXiv preprint arXiv:1708.06733, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[17]
Zeromark: Towards dataset ownership verification without disclosing watermark
Guo, J., Li, Y., Chen, R., Wu, Y., Liu, C., and Huang, H. Zeromark: Towards dataset ownership verification without disclosing watermark. In NeurIPS, 2024
2024
-
[18]
Guo, J., Li, Y., Chen, R., Wu, Y., Liu, C., Chen, Y., and Huang, H. Towards copyright protection for knowledge bases of retrieval-augmented language models via reasoning. arXiv preprint arXiv:2502.10440, 2025
-
[19]
Measuring massive multitask language understanding
Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., and Steinhardt, J. Measuring massive multitask language understanding. In ICLR, 2021
2021
-
[20]
On the weaknesses of backdoor-based model watermarking: An information-theoretic perspective
Hu, A., Chen, Y., Xie, R., and Weller, A. On the weaknesses of backdoor-based model watermarking: An information-theoretic perspective. arXiv preprint arXiv:2409.06130, 2024
-
[21]
Text-generation-launcher arguments, 2026
Hugging Face Text Generation Inference . Text-generation-launcher arguments, 2026. URL https://huggingface.co/docs/text-generation-inference/basic_tutorials/launcher
2026
-
[22]
Jiang, A. Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D. S., de las Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L. R., Lachaux, M.-A., Stock, P., Scao, T. L., Lavril, T., Wang, T., Lacroix, T., and Sayed, W. E. Mistral 7b, 2023. URL https://arxiv.org/abs/2310.06825
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
B., Chandra, B., and Yejin, C
Keisuke, S., Ronan, L. B., Chandra, B., and Yejin, C. Winogrande: An adversarial winograd schema challenge at scale. In AAAI, 2020
2020
-
[24]
The winograd schema challenge
Levesque, H., Davis, E., and Morgenstern, L. The winograd schema challenge. In KR, 2012
2012
-
[25]
Rema: A unified reasoning manifold framework for interpreting large language model
Li, B., Deng, G., Chen, R., Yue, J., Zhang, S., Zhao, Q., Song, L., and Wen, L. Rema: A unified reasoning manifold framework for interpreting large language model. arXiv preprint arXiv:2509.22518, 2025 a
-
[26]
Turning your strength into watermark: Watermarking large language model via knowledge injection
Li, S., Chen, K., Tang, K., Zhang, J., Zhang, W., Yu, N., and Zeng, K. Turning your strength into watermark: Watermarking large language model via knowledge injection. arXiv preprint arXiv:2311.09535, 2023
-
[27]
Editmark: Watermarking large language models based on model editing
Li, S., Chen, K., Jiang, J., Zhang, J., Yao, Q., Zeng, K., Zhang, W., and Yu, N. Editmark: Watermarking large language models based on model editing. arXiv preprint arXiv:2510.16367, 2025 b
-
[28]
Backdoor learning: A survey
Li, Y., Jiang, Y., Li, Z., and Xia, S.-T. Backdoor learning: A survey. IEEE transactions on neural networks and learning systems, 35 0 (1): 0 5--22, 2022
2022
-
[29]
Rethinking data protection in the (generative) artificial intelligence era,
Li, Y., Shao, S., He, Y., Guo, J., Zhang, T., Qin, Z., Chen, P.-Y., Backes, M., Torr, P., Tao, D., et al. Rethinking data protection in the (generative) artificial intelligence era. arXiv preprint arXiv:2507.03034, 2025 c
-
[30]
Move: Effective and harmless ownership verification via embedded external features
Li, Y., Zhu, L., Jia, X., Bai, Y., Jiang, Y., Xia, S.-T., Cao, X., and Ren, K. Move: Effective and harmless ownership verification via embedded external features. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025 d
2025
-
[31]
Differentiation-based extraction of proprietary data from fine-tuned llms
Li, Z., Wu, D., Wang, S., and Su, Z. Differentiation-based extraction of proprietary data from fine-tuned llms. In CCS, 2025 e
2025
-
[32]
Liang, Y., Xiao, J., Gan, W., and Yu, P. S. Watermarking techniques for large language models: A survey. Artificial Intelligence Review, 59 0 (2): 0 74, 2026
2026
-
[33]
Abs: Scanning neural networks for back-doors by artificial brain stimulation
Liu, Y., Lee, W.-C., Tao, G., Ma, S., Aafer, Y., and Zhang, X. Abs: Scanning neural networks for back-doors by artificial brain stimulation. In CCS, 2019
2019
-
[34]
Mufm: A mamba-enhanced feedback model for micro video popularity prediction
Lu, J., Xiao, M., Wang, W., Du, Y., Cui, Y., Zhao, J., and Hua, C. Mufm: A mamba-enhanced feedback model for micro video popularity prediction. arXiv, 2024
2024
-
[35]
Can a suit of armor conduct electricity? a new dataset for open book question answering
Mihaylov, T., Clark, P., Khot, T., and Sabharwal, A. Can a suit of armor conduct electricity? a new dataset for open book question answering. In EMNLP, 2018
2018
-
[36]
Model configuration, 2026
NVIDIA Triton Inference Server . Model configuration, 2026. URL https://docs.nvidia.com/deeplearning/triton-inference-server/user-guide/docs/tensorrtllm_backend/docs/model_config.html
2026
-
[37]
Create a model response, 2026
OpenAI . Create a model response, 2026. URL https://developers.openai.com/api/reference/resources/responses/methods/create
2026
-
[38]
M., and Ateniese, G
Pasquini, D., Kornaropoulos, E. M., and Ateniese, G. LLMmap : Fingerprinting for large language models. In USENIX Security, 2025
2025
-
[39]
Pilehvar, M. T. and Camacho-Collados, J. Wic: The word-in-context dataset for evaluating context-sensitive meaning representations. In NAACL, 2019
2019
-
[40]
Puah, Y. H., Ngo, A. T., Chattopadhyay, N., and Chattopadhyay, A. Blockdoor: Blocking backdoor based watermarks in deep neural networks. arXiv preprint arXiv:2412.12194, 2024
-
[41]
Sampling parameters, 2026
SGLang . Sampling parameters, 2026. URL https://sgl-project.github.io/basic_usage/sampling_params.html
2026
-
[42]
Sok: Large language model copyright auditing via fingerprinting
Shao, S., Li, Y., He, Y., Yao, H., Yang, W., Tao, D., and Qin, Z. Sok: Large language model copyright auditing via fingerprinting. arXiv preprint arXiv:2508.19843, 2025 a
-
[43]
Explanation as a watermark: Towards harmless and multi-bit model ownership verification via watermarking feature attribution
Shao, S., Li, Y., Yao, H., He, Y., Qin, Z., and Ren, K. Explanation as a watermark: Towards harmless and multi-bit model ownership verification via watermarking feature attribution. In NDSS, 2025 b
2025
-
[44]
Reading between the lines: Towards reliable black-box llm fingerprinting via zeroth-order gradient estimation
Shao, S., Li, Y., Yao, H., Chen, Y., Yang, Y., and Qin, Z. Reading between the lines: Towards reliable black-box llm fingerprinting via zeroth-order gradient estimation. In WWW, 2026
2026
-
[45]
Taori, R., Gulrajani, I., Zhang, T., Dubois, Y., Li, X., Guestrin, C., Liang, P., and Hashimoto, T. B. Stanford alpaca: An instruction-following llama model, 2023
2023
-
[46]
sampling\_params, 2026
vLLM . sampling\_params, 2026. URL https://docs.vllm.ai/en/latest/api/vllm/sampling_params/
2026
-
[47]
Wang, A., Singh, A., Michael, J., Hill, F., Levy, O., and Bowman, S. R. GLUE : A multi-task benchmark and analysis platform for natural language understanding. In ICLR, 2019 a
2019
-
[48]
Wang, B., Yao, Y., Shan, S., Li, H., Viswanath, B., Zheng, H., and Zhao, B. Y. Neural cleanse: Identifying and mitigating backdoor attacks in neural networks. In IEEE S&P, 2019 b
2019
-
[49]
Say no to freeloader: Protecting intellectual property of your deep model
Wang, L., Wang, M., Fu, H., and Zhang, D. Say no to freeloader: Protecting intellectual property of your deep model. IEEE Transactions on Pattern Analysis and Machine Intelligence, 46 0 (12): 0 11073--11086, 2024 a
2024
-
[50]
Knowledge editing for large language models: A survey
Wang, S., Zhu, Y., Liu, H., Zheng, Z., Chen, C., and Li, J. Knowledge editing for large language models: A survey. ACM Computing Surveys, 2024 b
2024
-
[51]
S., and Wen, Q
Wang, S., Xu, T., Li, H., Zhang, C., Liang, J., Tang, J., Yu, P. S., and Wen, Q. Large language models for education: A survey and outlook. IEEE Signal Processing Magazine, 42 0 (6): 0 51--63, 2026
2026
-
[52]
A pathology foundation model for cancer diagnosis and prognosis prediction
Wang, X., Zhao, J., Marostica, E., Yuan, W., Jin, J., Zhang, J., Li, R., Tang, H., Wang, K., Li, Y., et al. A pathology foundation model for cancer diagnosis and prognosis prediction. Nature, 634 0 (8035): 0 970--978, 2024 c
2024
-
[53]
S., Deng, Y., Dunn, S., and Zhang, L
Xia, C. S., Deng, Y., Dunn, S., and Zhang, L. Demystifying llm-based software engineering agents. Proceedings of the ACM on Software Engineering, 2 0 (FSE): 0 801--824, 2025
2025
-
[54]
D., Yao, L., Pan, M., Du, X., and Wang, H
Xiong, Z., Wu, G., Yu, Q., Ma, M. D., Yao, L., Pan, M., Du, X., and Wang, H. iseal: Encrypted fingerprinting for reliable llm ownership verification. In AAAI, 2026
2026
-
[55]
W., Xiao, C., and Chen, M
Xu, J., Wang, F., Ma, M., Koh, P. W., Xiao, C., and Chen, M. Instructional fingerprinting of large language models. In NAACL, 2024 a
2024
-
[56]
Towards reliable and efficient backdoor trigger inversion via decoupling benign features
Xu, X., Huang, K., Li, Y., Qin, Z., and Ren, K. Towards reliable and efficient backdoor trigger inversion via decoupling benign features. In ICLR, 2024 b
2024
-
[57]
K., Takahashi, T., and Wataoka, K
Yamabe, S., Waseda, F. K., Takahashi, T., and Wataoka, K. Mergeprint: Merge-resistant fingerprints for robust black-box ownership verification of large language models. In ACL, 2025
2025
-
[58]
Yang, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Li, C., Liu, D., Huang, F., Wei, H., Lin, H., Yang, J., Tu, J., Zhang, J., Yang, J., Yang, J., Zhou, J., Lin, J., Dang, K., Lu, K., Bao, K., Yang, K., Yu, L., Li, M., Xue, M., Zhang, P., Zhu, Q., Men, R., Lin, R., Li, T., Xia, T., Ren, X., Ren, X., Fan, Y., Su, Y., Zhang, Y., Wan, Y., Liu, Y., Cui...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[59]
SWAP: Towards Copyright Auditing of Soft Prompts via Sequential Watermarking
Yang, W., Sun, Y., Chen, C., Chu, Z., Zhang, J., Li, Y., and Tao, D. Swap: Towards copyright auditing of soft prompts via sequential watermarking. arXiv preprint arXiv:2511.04711, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[60]
Promptcos: Towards content-only system prompt copyright auditing for llms
Yang, Y., Li, Y., Yao, H., Huang, E., Shao, S., Wang, Y., Wang, Z., Tao, D., and Qin, Z. Promptcos: Towards content-only system prompt copyright auditing for llms. In IEEE S&P, 2026
2026
-
[61]
An efficient white-box llm watermarking for ip protection on online market platforms
Yuan, S., Su, X., Lv, P., Xue, W., Yu, J., Zhu, X., and Chen, C. An efficient white-box llm watermarking for ip protection on online market platforms. In KDD, 2025
2025
-
[62]
Pree: Towards harmless and adaptive fingerprint editing in large language models via knowledge prefix enhancement
Yue, X., Xu, Z., Xing, W., Yu, J., Li, M., and Han, M. Pree: Towards harmless and adaptive fingerprint editing in large language models via knowledge prefix enhancement. In Findings of EMNLP, 2025
2025
-
[63]
Z., Zhao, Y., and Dong, Y
Zhao, K., Li, L., Ding, K., Gong, N. Z., Zhao, Y., and Dong, Y. A survey on model extraction attacks and defenses for large language models. In KDD, 2025
2025
-
[64]
Zhu, L., Li, Y., Weng, H., Liu, Y., Zhang, T., Xia, S.-T., and Wang, Z. Holmes: Towards effective and harmless model ownership verification to personalized large vision models via decoupling common features. arXiv preprint arXiv:2507.00724, 2025
-
[65]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.